Scrapy ist ein in Python entwickeltes Open-Source-Framework, mit dem Sie Webspider oder Crawler erstellen können, um schnell und einfach Informationen von Websites zu extrahieren.
Diese Anleitung zeigt, wie Sie mit Scrapy einen Webspider auf Ihrem Server erstellen und ausführen, um mithilfe verschiedener Techniken Informationen von Webseiten zu extrahieren.
Verbinden Sie sich zunächst über eine SSH-Verbindung mit Ihrem Server. Wenn Sie dies noch nicht getan haben, wird empfohlen, unseren Leitfaden zu befolgen, um sich sicher mit SSH zu verbinden. Im Falle eines lokalen Servers gehen Sie zum nächsten Schritt und öffnen Sie das Terminal Ihres Servers.
Virtuelle Umgebung erstellen
Bevor Sie mit der eigentlichen Installation beginnen, fahren Sie mit der Aktualisierung der Systempakete fort:
$ sudo apt-get updateFahren Sie fort, indem Sie einige für den Betrieb notwendige Abhängigkeiten installieren:
$ sudo apt-get install python-dev python-pip libxml2-dev zlib1g-dev libxslt1-dev libffi-dev libssl-devSobald die Installation abgeschlossen ist, können Sie mit der Konfiguration von virtualenv beginnen, einem Python-Paket, mit dem Sie Python-Pakete isoliert installieren können, ohne andere Software zu gefährden. Obwohl dieser Schritt optional ist, wird er von Scrapy-Entwicklern dringend empfohlen:
$ sudo pip install virtualenvBereiten Sie dann ein Verzeichnis vor, um die Scrapy-Umgebung zu installieren:
$ sudo mkdir /var/scrapy
$ cd /var/scrapyUnd initialisieren Sie eine virtuelle Umgebung:
$ sudo virtualenv /var/scrapy
New python executable in /var/scrapy/bin/python
Installing setuptools, pip, wheel...
done.Um die virtuelle Umgebung zu aktivieren, führen Sie einfach den folgenden Befehl aus:
$ sudo source /var/scrapy/bin/activateSie können jederzeit durch den Befehl "deaktivieren" beenden.
Installation von Scrapy
Installieren Sie jetzt Scrapy und erstellen Sie ein neues Projekt:
$ sudo pip install Scrapy
$ sudo scrapy startproject example
$ cd exampleIm neu angelegten Projektverzeichnis hat die Datei folgende Struktur :
example/
scrapy.cfg # configuration file
example/ # module of python project
__init__.py
items.py
middlewares.py
pipelines.py
settings.py # project settings
spiders/
__init__.pyVerwendung der Shell zu Testzwecken
Scrapy ermöglicht es Ihnen, den HTML-Inhalt von Webseiten herunterzuladen und Informationen daraus durch die Verwendung verschiedener Techniken, wie z. B. CSS-Selektoren, zu extrapolieren. Um diesen Prozess zu erleichtern, stellt Scrapy eine "Hülle" bereit, um die Informationsextraktion in Echtzeit zu testen.
In diesem Tutorial erfahren Sie, wie Sie den ersten Beitrag auf der Hauptseite des berühmten sozialen Reddit erfassen:
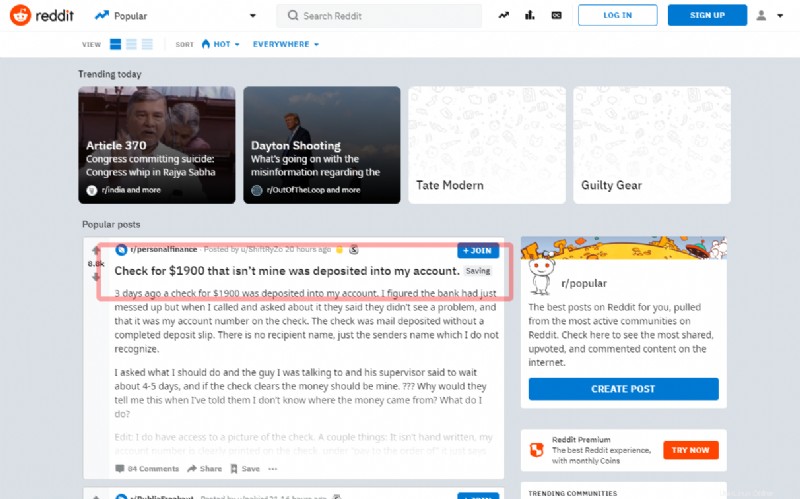
Bevor Sie mit dem Schreiben der Quelle fortfahren, versuchen Sie, den Titel durch die Shell zu extrahieren:
$ sudo scrapy shell "reddit.com"Innerhalb weniger Sekunden hat Scrapy die Hauptseite heruntergeladen. Geben Sie also Befehle mit dem Objekt „Antwort“ ein. Verwenden Sie wie im folgenden Beispiel den Selektor "article h3 ::text":, um den Titel des ersten Posts zu erhalten
>>> response.css('article h3::text')[0].get()Wenn der Selektor richtig funktioniert, wird der Titel angezeigt. Verlassen Sie dann die Shell:
>>> exit()Um einen neuen Spider zu erstellen, erstellen Sie eine neue Python-Datei im Projektverzeichnis example /spiders/reddit.py:
import scrapy
class RedditSpider(scrapy.Spider):
name = "reddit"
def start_requests(self):
yield scrapy.Request(url="https://www.reddit.com/", callback=self.parseHome)
def parseHome(self, response):
headline = response.css('article h3::text')[0].get()
with open( 'popular.list', 'ab' ) as popular_file:
popular_file.write( headline + "\n" )Alle Spider erben die Spider-Klasse des Scrapy-Moduls und starten die Anfragen mit der Methode start_requests:
yield scrapy.Request(url="https://www.reddit.com/", callback=self.parseHome)Wenn Scrapy das Laden der Seite abgeschlossen hat, ruft es die Callback-Funktion (self.parseHome) auf.
Mit dem Response-Objekt kann der Inhalt Ihres Interesses übernommen werden:
headline = response.css('article h3::text')[0].get()Und speichern Sie es zu Demonstrationszwecken in einer "popular.list"-Datei.
Starte den neu erstellten Spider mit dem Befehl:
$ sudo scrapy crawl redditNach Abschluss wird der letzte extrahierte Titel in der Datei popular.list gefunden:
$ cat popular.listScrapyd planen
Um die Ausführung Ihrer Spider zu planen, nutzen Sie den von Scrapy angebotenen Dienst „Scrapy Cloud“ (siehe https://scrapinghub.com/scrapy-cloud ) oder installieren Sie den Open-Source-Daemon direkt auf Ihrem Server .
Stellen Sie sicher, dass Sie sich in der zuvor erstellten virtuellen Umgebung befinden und installieren Sie das scrapyd-Paket über pip:
$ cd /var/scrapy/
$ sudo source /var/scrapy/bin/activate
$ sudo pip install scrapydSobald die Installation abgeschlossen ist, bereiten Sie einen Dienst vor, indem Sie die Datei /etc/systemd/system/scrapyd.service mit folgendem Inhalt erstellen:
[Unit]
Description=Scrapy Daemon
[Service]
ExecStart=/var/scrapy/bin/scrapydSpeichern Sie die neu erstellte Datei und starten Sie den Dienst über:
$ sudo systemctl start scrapydJetzt ist der Daemon konfiguriert und bereit, neue Spinnen zu akzeptieren.
Um Ihre Beispiel-Spider bereitzustellen, müssen Sie ein Tool namens „scrapyd-client“ verwenden, das von Scrapy bereitgestellt wird. Fahren Sie mit der Installation über pip fort:
$ sudo pip install scrapyd-clientFahren Sie fort, indem Sie die Datei scrapy.cfg bearbeiten und die Bereitstellungsdaten festlegen:
[settings]
default = example.settings
[deploy]
url = http://localhost:6800/
project = exampleStellen Sie jetzt bereit, indem Sie einfach den folgenden Befehl ausführen:
$ sudo scrapyd-deployUm die Spider-Ausführung zu planen, rufen Sie einfach die Scrapyd-API auf:
$ sudo curl http://localhost:6800/schedule.json -d project=example -d spider=reddit