Grep oder Global Regular Expression Print wird verwendet, um in einem Linux-System nach Text oder Mustern zu suchen. Es kann in Dateien, Verzeichnissen und sogar Ausgaben anderer Befehle suchen.
Reguläre Ausdrücke sind Muster, die Text gemäß den Anforderungen des Benutzers abgleichen können. Dies sind wie Regeln für den Musterabgleich.
Grep wird oft zusammen mit regulären Ausdrücken verwendet, um nach Mustern im Text zu suchen. Sehen wir uns einige praktische Beispiele für Regex mit grep an.
1. Übereinstimmung mit einem Wort unabhängig von der Groß-/Kleinschreibung
Manchmal kann in einem Text dasselbe Wort auf unterschiedliche Weise geschrieben werden. Dies ist am häufigsten bei Eigennamen der Fall. Anstatt mit einem Großbuchstaben zu beginnen, werden sie manchmal nur in Kleinbuchstaben geschrieben.
$ grep "[Jj]ayant"

Beide Versionen des Wortes wurden unabhängig von ihrer Groß-/Kleinschreibung abgeglichen.
Ein weiterer interessanter Fall lässt sich beim Wort „IoT“ beobachten. Ein solches Wort kann mehrmals im Text mit unterschiedlichen Variationen vorkommen. Um alle Wörter unabhängig von der Groß-/Kleinschreibung zu finden, verwenden Sie :
$ grep "[iI][oO][tT]"

2. Abgleich der Handynummer mit Regex mit grep
Reguläre Ausdrücke können verwendet werden, um die Handynummer aus einem Text zu extrahieren.
Das Format der Handynummer muss vorher bekannt sein. Beispielsweise funktioniert ein regulärer Ausdruck, der für den Abgleich von Mobiltelefonnummern entwickelt wurde, nicht für private Telefonnummern.
In diesem Beispiel wird eine Mobiltelefonnummer im folgenden Format abgeglichen:91-1234567890 (d. h. zweistellig-zehnstellig).
$ grep "[[:digit:]]\{2\}[ -]\?[[:digit:]]\{10\}"

Wie ersichtlich, wird nur die Mobilnummer im oben genannten Format abgeglichen.
3. E-Mail-Adresse abgleichen
Das Extrahieren von E-Mail-Adressen aus einem Text ist sehr nützlich und kann mit grep erreicht werden.
Eine E-Mail-Adresse hat ein bestimmtes Format. Der Teil vor dem „@“ ist der Benutzername, der das Postfach identifiziert. Dann gibt es noch eine Domain wie gmail.com oder yahoo.in.
Der reguläre Ausdruck kann unter Berücksichtigung dieser Dinge entworfen werden.
$ grep -E "[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,6}"


- [A-Za-z0-9._%+-]+ erfasst den Benutzernamen vor „@“
- [A-Za-z0-9.-]+ erfasst den Namen der Domain ohne den „.com“-Teil
- .[A-Za-z]{2,6} erfasst die „.com“ oder „.in“ usw.
4. URL-Prüfer
Eine URL hat ein bestimmtes Darstellungsformat. Es kann eine Regex erstellt werden, die überprüft, ob eine URL die richtige Form hat oder nicht.
Eine URL muss mit http/https/ftp beginnen, gefolgt von „://“. Dann gibt es noch den Domainnamen, der auf „.com“, „.in“, „.org“ usw. enden kann.
$ grep -E "^(http|https|ftp):[\/]{2}([a-zA-Z0-9\-\.]+\.[a-zA-Z]{2,4})"


-E, das in diesem Beispiel und im vorherigen Beispiel verwendet wird, bedeutet erweitertes grep, das den erweiterten regulären Ausdruckssatz anstelle des einfachen regulären Ausdruckssatzes verwendet. Das bedeutet, dass bestimmte Sonderzeichen nicht maskiert werden müssen. Es macht das Schreiben einer komplexen Regex weniger ermüdend. Lesen Sie hier mehr darüber.
5. Dateien mit einer bestimmten Erweiterung finden
Der Befehl ls zeigt alle Dateien im aktuellen Verzeichnis an.
Wenn Sie ls -l ausführen, erhalten Sie zusätzliche Informationen zu den Dateien. Grep kann zusammen mit dem Befehl ls -l verwendet werden, um Muster in seiner Ausgabe abzugleichen.
Um Dateien abzurufen, die mit der Erweiterung „.txt“ gespeichert sind, verwenden Sie:
$ ls -l | grep '.txt$'
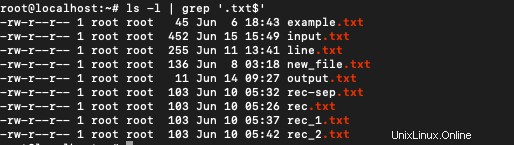
6. Inhalte in Klammern finden
Oft haben Textdateien Inhalte in Klammern. Wir können diese mithilfe von Regex mit grep extrahieren.
$ grep "([A-Za-z ]*)"

Die Regex wählt den Text aus, der sich innerhalb der Parathese befindet. Die Länge des Inhalts in Klammern kann ebenfalls angegeben werden.
Um beispielsweise Klammern mit nur 10 Zeichen abzugleichen, verwenden Sie :
$ grep "([A-Za-z ]{10})"
7. Übereinstimmungszeilen, die mit einem bestimmten Wort beginnen
Wir können Regex verwenden, um Zeilen zu finden, die mit einem bestimmten Wort beginnen.

Um Zeilen zu finden, die mit dem Wort Apples beginnen, verwenden Sie :
grep '^Apples' input.txt
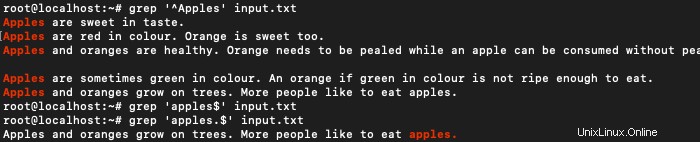
Ebenso können auch Zeilen gefunden werden, die mit jedem anderen Wort beginnen.
Wir können Zeilen abgleichen, die mit einem bestimmten Wort enden, indem wir die unten stehenden regulären Ausdrücke verwenden.
$ grep 'apples.$' input.txt

8. Mehrere Wörter gleichzeitig abgleichen
Lassen Sie uns wie unten gezeigt mehrere Wörter mit Regex abgleichen:
$ grep 'Apples\|Orange' input.txt
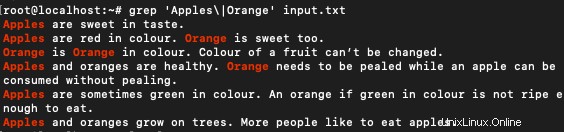
Dieser Befehl arbeitet eine ODER-Zeile zwischen den beiden Wörtern. Es stimmt mit Zeilen überein, die eines der beiden Wörter enthalten.
Um ein UND zwischen den beiden Wörtern zu machen, verwenden Sie:
$ grep 'Apple' input.txt | grep 'Orange

9. Übereinstimmungen mit demselben Wort in verschiedenen Formen
Manchmal kann ein Wort in verschiedenen Formen vorkommen. Sie können je nach Zeitform, in der sie verwendet werden, unterschiedlich sein.
Peeled und Peeling sind Beispiele dafür. In beiden Wörtern ist das Stammwort „peel“
Wir können Regex verwenden, um alle Formen eines Wortes abzugleichen.
In unserem Text haben wir peeled und peeling als peeled bzw. peeling geschrieben.
Auf ähnliche Weise können wir auch von US-Englisch in britisches Englisch übersetzen. Zum Beispiel wird das Wort Farbe zu Farbe.
$ grep 'peal\([a-z]*\)\(\.*[[:space:]]\)' input.txt

10. Benutzer in der Datei /etc/passwd finden
grep kann verwendet werden, um Benutzer aus der Datei /etc/passwd/ abzurufen. Die Datei /etc/passwd verwaltet die Liste der Benutzer auf dem System zusammen mit einigen zusätzlichen Informationen.
$ grep "Adam" /etc/passwd

Der Befehl verwendet grep für eine Systemdatei. Wenn das Wort „Adam“ gefunden wird, können wir die Zeile als Ausgabe sehen. Wir können die gleiche Suche für jedes andere Element in der Datei durchführen.
Schlussfolgerung
Regex kann zusammen mit dem grep-Befehl sehr leistungsfähig sein. Regex wird als separates Gebiet in der Informatik studiert und kann verwendet werden, um hochkomplexe Muster abzugleichen. Erfahren Sie hier mehr über Regex.