In diesem Tutorial lernen Sie, wie Sie das sehr wichtige grep verwenden Befehl unter Linux. Wir werden erläutern, warum es wichtig ist, diesen Befehl zu beherrschen, und wie Sie ihn bei Ihren täglichen Aufgaben an der Befehlszeile verwenden können.
Lassen Sie uns gleich mit einigen Erklärungen und Beispielen eintauchen.
Warum verwenden wir grep?
Grep ist ein Befehlszeilentool, mit dem Linux-Benutzer nach Textzeichenfolgen suchen. Sie können es verwenden, um eine Datei nach einem bestimmten Wort oder einer bestimmten Wortkombination zu durchsuchen, oder Sie können die Ausgabe anderer Linux-Befehle an grep weiterleiten, sodass grep Ihnen nur die Ausgabe anzeigen kann, die Sie sehen müssen.
Schauen wir uns einige wirklich gängige Beispiele an. Angenommen, Sie müssen den Inhalt eines Verzeichnisses überprüfen, um festzustellen, ob dort eine bestimmte Datei vorhanden ist. Dafür würden Sie den Befehl „ls“ verwenden.
Aber um diesen ganzen Prozess der Überprüfung des Inhalts des Verzeichnisses noch schneller zu machen, können Sie die Ausgabe des Befehls ls an den Befehl grep weiterleiten. Suchen wir in unserem Home-Verzeichnis nach einem Ordner namens Documents.
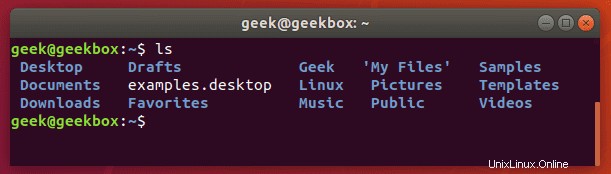
Und jetzt versuchen wir noch einmal, das Verzeichnis zu überprüfen, aber diesmal mit grep, um speziell nach dem Ordner „Dokumente“ zu suchen.
$ ls | grep Documents
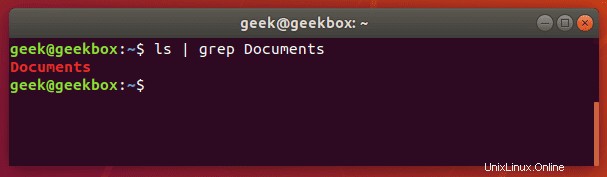
Wie Sie im obigen Screenshot sehen können, haben wir durch die Verwendung des grep-Befehls Zeit gespart, indem wir das gesuchte Wort schnell vom Rest der unnötigen Ausgabe isoliert haben, die der ls-Befehl erzeugt hat.
Wenn der Ordner Documents nicht vorhanden wäre, würde grep keine Ausgabe zurückgeben. Wenn also grep nichts zurückgibt, bedeutet das, dass es das gesuchte Wort nicht finden konnte.
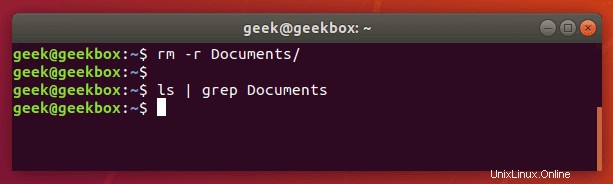
Suche eine Zeichenfolge
Wenn Sie nach einer Textzeichenfolge und nicht nur nach einem einzelnen Wort suchen müssen, müssen Sie die Zeichenfolge in Anführungszeichen setzen. Was wäre zum Beispiel, wenn wir nach dem Verzeichnis „Eigene Dokumente“ statt nach dem Verzeichnis „Dokumente“ mit nur einem Wort suchen müssten?
$ ls | grep 'My Documents'
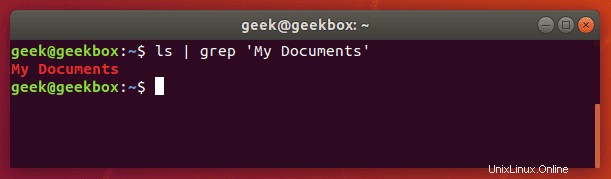
Grep akzeptiert sowohl einfache als auch doppelte Anführungszeichen, also schließen Sie Ihre Textzeichenfolge mit beiden ein.
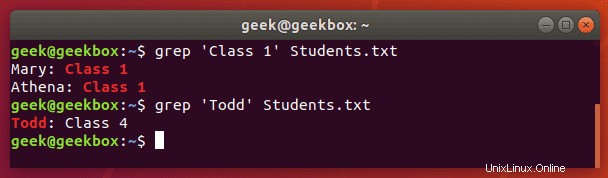
Während Sie mit grep die von anderen Befehlszeilentools weitergeleitete Ausgabe durchsuchen können, können Sie damit auch Dokumente direkt durchsuchen. Hier ist ein Beispiel, wo wir ein Textdokument nach einer Zeichenfolge durchsuchen.
$ grep 'Class 1' Students.txt
Mehrere Zeichenfolgen finden
Sie können auch grep verwenden, um mehrere Wörter oder Zeichenfolgen zu finden. Sie können mehrere Muster angeben, indem Sie den Schalter -e verwenden. Versuchen wir, ein Textdokument nach zwei verschiedenen Zeichenfolgen zu durchsuchen:
$ grep -e 'Class 1' -e Todd Students.txt
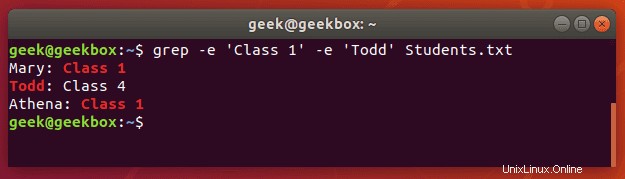
Beachten Sie, dass wir nur die Zeichenfolgen in Anführungszeichen setzen mussten, die Leerzeichen enthielten.
Unterschied zwischen grep, egrep fgrep, pgrep, zgrep
Verschiedene grep-Schalter waren in der Vergangenheit in verschiedenen Binärdateien enthalten. Auf modernen Linux-Systemen sind diese Schalter im Basisbefehl grep verfügbar, aber es ist üblich, dass Distributionen auch die anderen Befehle unterstützen.
Aus der Manpage für grep:
egrep ist das Äquivalent zu grep -E
Dieser Schalter interpretiert ein Muster als erweiterten regulären Ausdruck. Es gibt eine Menge verschiedener Dinge, die Sie damit machen können, aber hier ist ein Beispiel dafür, wie es aussieht, einen regulären Ausdruck mit grep zu verwenden.
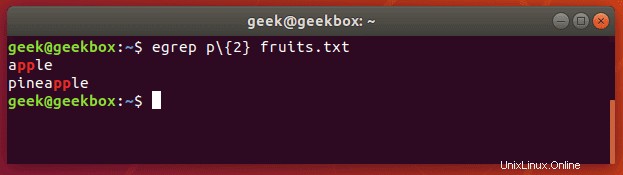
Lassen Sie uns ein Textdokument nach Zeichenfolgen durchsuchen, die zwei aufeinanderfolgende „p“-Buchstaben enthalten:
$ egrep p\{2} fruits.txt oder
$ grep -E p\{2} fruits.txt
fgrep ist das Äquivalent zu grep -F
Dieser Schalter interpretiert ein Muster als eine Liste fester Zeichenfolgen und versucht, mit einer davon übereinzustimmen. Es ist nützlich, wenn Sie nach Zeichen für reguläre Ausdrücke suchen müssen. Das bedeutet, dass Sie keine Sonderzeichen maskieren müssen, wie Sie es beim regulären grep tun würden.
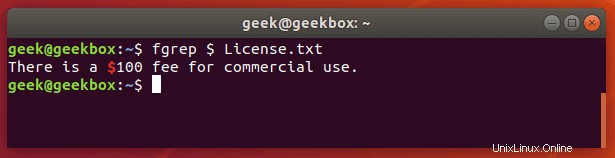
pgrep ist ein Befehl, um nach dem Namen eines laufenden Prozesses auf Ihrem System zu suchen und die entsprechenden Prozess-IDs zurückzugeben. Beispielsweise könnten Sie es verwenden, um die Prozess-ID des SSH-Daemons zu finden:
$ pgrep sshd
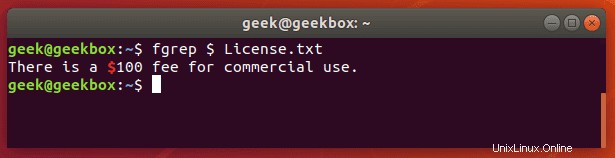
Dies ähnelt in der Funktion dem einfachen Weiterleiten der Ausgabe des Befehls „ps“ an grep.
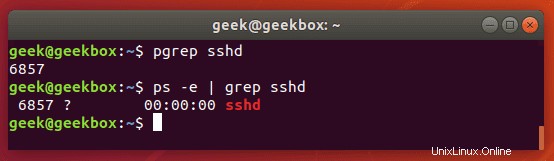
Sie können diese Informationen verwenden, um einen laufenden Prozess zu beenden oder Probleme mit den auf Ihrem System ausgeführten Diensten zu beheben.
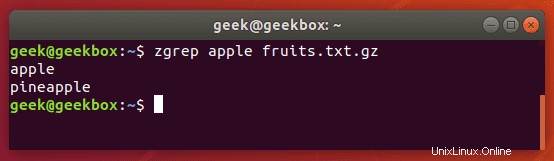
Sie können zgrep verwenden, um komprimierte Dateien nach einem Muster zu durchsuchen. Es ermöglicht Ihnen, die Dateien in einem komprimierten Archiv zu durchsuchen, ohne dieses Archiv zuerst dekomprimieren zu müssen, wodurch Sie im Grunde ein oder zwei zusätzliche Schritte sparen.
$ zgrep apple fruits.txt.gz
zgrep funktioniert auch mit tar-Dateien, scheint aber nur so weit zu gehen, Ihnen zu sagen, ob es eine Übereinstimmung gefunden hat oder nicht.
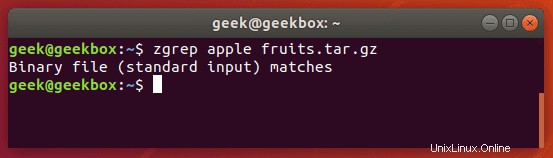
Wir erwähnen dies, weil mit gzip komprimierte Dateien sehr häufig tar-Archive sind.
Unterschied zwischen find und grep
Für diejenigen, die gerade erst mit der Linux-Befehlszeile beginnen, ist es wichtig, sich daran zu erinnern, dass find und grep zwei Befehle mit zwei sehr unterschiedlichen Funktionen sind, obwohl wir beide verwenden, um etwas zu „finden“, das der Benutzer angibt.
Es ist praktisch, grep zu verwenden, um eine Datei zu finden, wenn Sie damit die Ausgabe des Befehls ls durchsuchen, wie wir in den ersten Beispielen des Tutorials gezeigt haben.
Wenn Sie jedoch rekursiv nach dem Namen einer Datei suchen müssen – oder nach einem Teil des Dateinamens, wenn Sie einen Platzhalter (Sternchen) verwenden – sind Sie mit dem Befehl „Suchen“ weit voraus.
$ find /path/to/search -name name-of-file
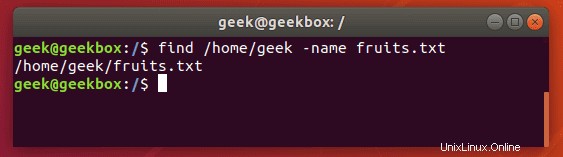
Die obige Ausgabe zeigt, dass der find-Befehl die gesuchte Datei erfolgreich finden konnte.
Rekursiv suchen
Sie können den Schalter -r mit grep verwenden, um alle Dateien in einem Verzeichnis und seinen Unterverzeichnissen rekursiv nach einem bestimmten Muster zu durchsuchen.
$ grep -r pattern /directory/to/search
Wenn Sie kein Verzeichnis angeben, durchsucht grep nur Ihr aktuelles Arbeitsverzeichnis. Im Screenshot unten hat grep zwei Dateien gefunden, die unserem Muster entsprechen, und kehrt mit ihren Dateinamen und dem Verzeichnis zurück, in dem sie sich befinden.

Leerzeichen oder Tabulator fangen
Wie wir bereits in unserer Erklärung zur Suche nach einer Zeichenfolge erwähnt haben, können Sie Text in Anführungszeichen setzen, wenn er Leerzeichen enthält. Die gleiche Methode funktioniert für Tabs, aber wir werden gleich erklären, wie Sie einen Tab in Ihren grep-Befehl einfügen.
Setzen Sie ein Leerzeichen oder mehrere Leerzeichen in Anführungszeichen, damit grep nach diesem Zeichen sucht.
$ grep " " sample.txt
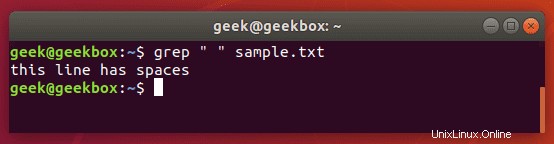
Es gibt ein paar verschiedene Möglichkeiten, wie Sie mit grep nach einem Tab suchen können, aber die meisten Methoden sind experimentell oder können über verschiedene Distributionen hinweg inkonsistent sein.
Der einfachste Weg ist, einfach nach dem Tabulatorzeichen selbst zu suchen, das Sie erzeugen können, indem Sie Strg+V auf Ihrer Tastatur drücken, gefolgt von Tab.
Normalerweise teilt das Drücken der Tabulatortaste in einem Terminalfenster dem Terminal mit, dass Sie einen Befehl automatisch vervollständigen möchten, aber wenn Sie vorher die Kombination Strg+V drücken, wird das Tabulatorzeichen so geschrieben, wie Sie es normalerweise in einem Texteditor erwarten würden .
$ grep " " sample.txt
Die Kenntnis dieses kleinen Tricks ist besonders nützlich, wenn Sie Konfigurationsdateien in Linux durchsuchen, da häufig Tabulatoren verwendet werden, um Befehle von ihren Werten zu trennen.
Reguläre Ausdrücke verwenden
Die Funktionalität von Grep wird durch die Verwendung regulärer Ausdrücke weiter erweitert, was Ihnen mehr Flexibilität bei Ihren Suchen ermöglicht. Es gibt mehrere, und wir gehen in den folgenden Beispielen auf einige der häufigsten ein:
[ ] Klammern werden verwendet, um einen beliebigen Zeichensatz abzugleichen.
$ grep "Class [123]" Students.txt
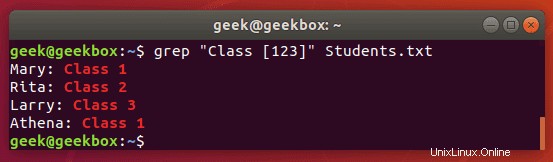
Dieser Befehl gibt alle Zeilen zurück, die „Class 1“, „Class2“ oder „Class 3“ enthalten.
[-] Klammern mit einem Bindestrich kann verwendet werden, um einen Bereich von Zeichen anzugeben, entweder numerisch oder alphabetisch.
$ grep "Class [1-3]" Students.txt
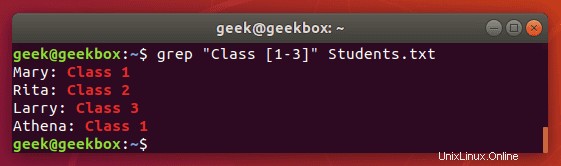
Wir erhalten die gleiche Ausgabe wie zuvor, aber der Befehl ist viel einfacher einzugeben, besonders wenn wir einen größeren Bereich von Zahlen oder Buchstaben hatten.
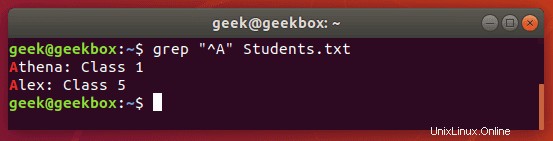
^ Caret wird verwendet, um nach einem Muster zu suchen, das nur am Anfang einer Zeile auftritt.
$ grep "^Class" Students.txt
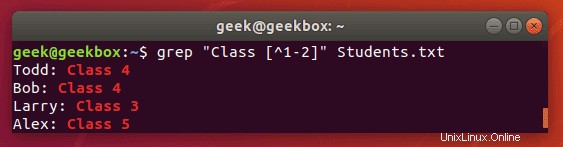
[^] Klammern mit Caret werden verwendet, um Zeichen aus einem Suchmuster auszuschließen.
$ grep "Class [^1-2]" Students.txt
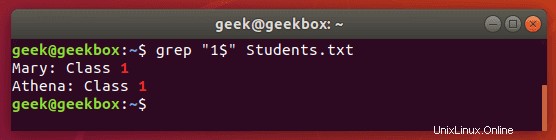
$-Dollar-Zeichen wird verwendet, um nach einem Muster zu suchen, das nur am Ende einer Zeile auftritt.
$ grep "1$" Students.txt
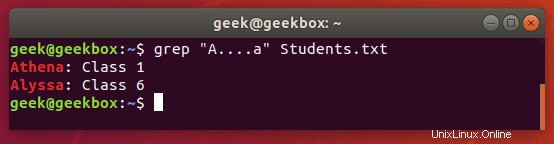
$ grep "A….a" Students.txt
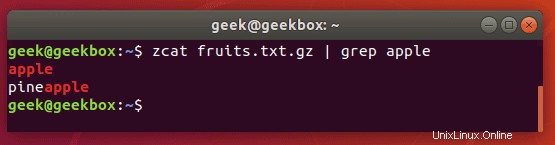
Grep gz-Dateien ohne Entpacken
Wie wir bereits gezeigt haben, können Sie den Befehl zgrep verwenden, um komprimierte Dateien zu durchsuchen, ohne sie zuerst entpacken zu müssen.
$ zgrep word-to-search /path/to/file.gz
Sie können auch den zcat-Befehl verwenden, um den Inhalt einer gz-Datei anzuzeigen und diese Ausgabe dann an grep weiterleiten, um die Zeilen zu isolieren, die Ihre Suchzeichenfolge enthalten.
$ zcat file.gz | grep word-to-search
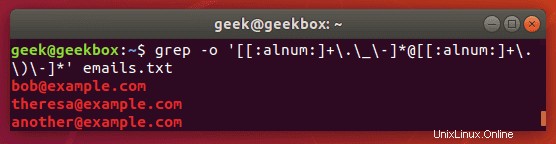
E-Mail-Adressen aus einer ZIP-Datei abrufen
Wir können einen ausgefallenen regulären Ausdruck verwenden, um alle E-Mail-Adressen aus einer ZIP-Datei zu extrahieren.
$ grep -o '[[:alnum:]+\.\_\-]*@[[:alnum:]+\.\_\-]*' emails.txt
Das Flag -o extrahiert nur die E-Mail-Adresse , anstatt die gesamte Zeile anzuzeigen, die die E-Mail-Adresse enthält. Dies führt zu einer saubereren Ausgabe.
Wie bei den meisten Dingen in Linux gibt es dafür mehr als einen Weg. Sie könnten auch egrep und einen anderen Satz von Ausdrücken verwenden. Aber das obige Beispiel funktioniert einwandfrei und ist eine ziemlich einfache Möglichkeit, die E-Mail-Adressen zu extrahieren und alles andere zu ignorieren.
Grep-IP-Adressen
Das Greping nach IP-Adressen kann ein wenig komplex werden, da wir grep nicht einfach sagen können, dass es nach vier Zahlen suchen soll, die durch Punkte getrennt sind – nun, wir könnten aber dieser Befehl kann auch ungültige IP-Adressen zurückgeben.
Der folgende Befehl findet und isoliert nur gültige IPv4-Adressen:
$ grep -E -o "(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)" /var/log/auth.log
Wir haben dies auf unserem Ubuntu-Server verwendet, um zu sehen, woher die letzten SSH-Versuche gemacht wurden.
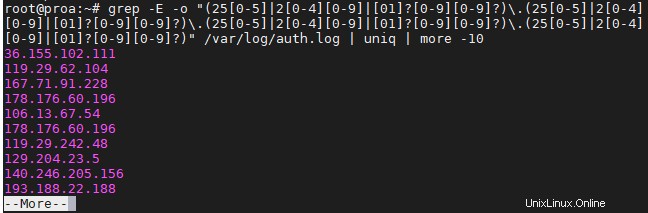
Um sich wiederholende Informationen zu vermeiden und Ihren Bildschirm nicht zu überfluten, sollten Sie Ihre grep-Befehle wie im obigen Screenshot an „uniq“ und „more“ weiterleiten.
Grep oder Bedingung
Es gibt ein paar verschiedene Möglichkeiten, wie Sie eine oder-Bedingung mit grep verwenden können, aber wir zeigen Ihnen diejenige, die die wenigsten Tastenanschläge erfordert und am einfachsten zu merken ist:
$ grep -E 'string1|string2' filename
oder technisch gesehen ist die Verwendung von egrep sogar noch weniger Tastenanschläge:
$ egrep 'string1|string2' filename
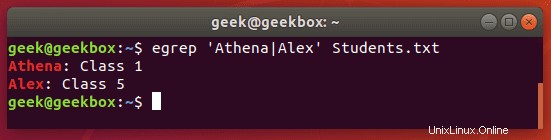
Groß-/Kleinschreibung ignorieren
Standardmäßig unterscheidet grep zwischen Groß- und Kleinschreibung, was bedeutet, dass Sie bei der Großschreibung Ihrer Suchzeichenfolge genau sein müssen. Sie können dies vermeiden, indem Sie grep mit dem Schalter -i anweisen, die Groß-/Kleinschreibung zu ignorieren.
$ grep -i string filename
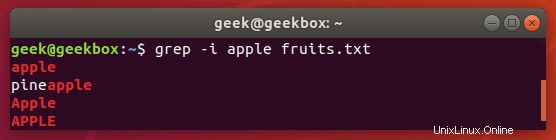
Suche mit Groß-/Kleinschreibung
Was ist, wenn wir nach einer Zeichenfolge suchen möchten, bei der die erste Groß- oder Kleinschreibung sein kann, der Rest der Zeichenfolge jedoch Kleinbuchstaben sein sollte? Das Ignorieren der Groß-/Kleinschreibung mit dem Schalter -i funktioniert in diesem Fall nicht, also wäre eine einfache Möglichkeit, es mit Klammern zu tun.
$ grep [Ss]tring filename
Dieser Befehl weist grep an, mit Ausnahme des ersten Buchstabens zwischen Groß- und Kleinschreibung zu unterscheiden.
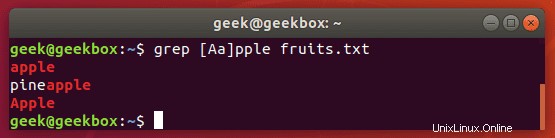
Genaue Übereinstimmung suchen
In unseren obigen Beispielen gibt grep immer dann, wenn wir unser Dokument nach der Zeichenfolge „Apfel“ durchsuchen, auch „Ananas“ als Teil der Ausgabe zurück. Um dies zu vermeiden und ausschließlich nach „Apfel“ zu suchen, können Sie diesen Befehl verwenden:
$ grep "\<apple\>" fruits.txt
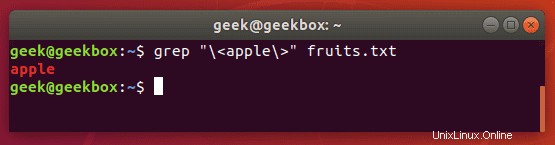
Sie können auch den Schalter -w verwenden, der grep mitteilt, dass die Zeichenfolge mit der gesamten Zeile übereinstimmen muss. Offensichtlich funktioniert dies nur in Situationen, in denen Sie nicht erwarten, dass der Rest der Zeile überhaupt Text enthält.
Muster ausschließen
Um den Inhalt einer Datei zu sehen, aber Muster von der Ausgabe auszuschließen, können Sie den Schalter -v verwenden.
$ grep -v string-to-exclude filename
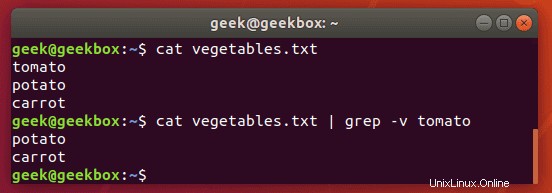
Wie Sie im Screenshot sehen können, wird die ausgeschlossene Zeichenfolge nicht mehr angezeigt, wenn wir denselben Befehl mit dem Schalter -v ausführen.
Grep und Ersetzen
Ein grep-Befehl, der an sed geleitet wird, kann verwendet werden, um alle Instanzen eines Strings in einer Datei zu ersetzen. Dieser Befehl ersetzt „string1“ durch „string2“ in allen Dateien relativ zum aktuellen Arbeitsverzeichnis:
$ grep -rl 'string1' ./ | xargs sed -i 's/string1/string2/g'
Grep mit Zeilennummer
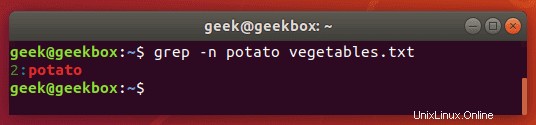
Verwenden Sie den Schalter -n, um die Zeilennummer anzuzeigen, die Ihren String enthält:
$ grep -n string filename
Zeige Zeilen davor und danach
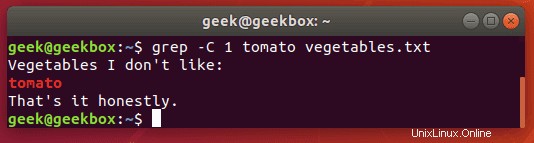
Wenn Sie etwas mehr Kontext für die grep-Ausgabe benötigen, können Sie mit dem Schalter -c eine Zeile vor und nach Ihrem angegebenen Suchstring anzeigen:
$ grep -c 1 string filename
Geben Sie die Anzahl der Zeilen an, die Sie anzeigen möchten – wir haben in diesem Beispiel nur 1 Zeile verwendet.
Sortieren Sie das Ergebnis
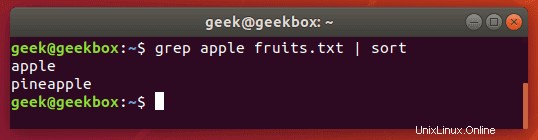
Leiten Sie die greps-Ausgabe an den sort-Befehl, um Ihre Ergebnisse in einer bestimmten Reihenfolge zu sortieren. Der Standardwert ist alphabetisch.
$ grep string filename | sort
Ich hoffe, Sie finden das Tutorial nützlich. Komm immer wieder.