Der Befehl tr in Linux übersetzt einen Zeichensatz in einen anderen. Es kann ein Zeichen oder eine Gruppe von Zeichen durch ein anderes Zeichen oder eine Gruppe von Zeichen ersetzen. tr liest die Eingabe von der Standardeingabe und zeigt die Ausgabe auf der Standardausgabe an. Die Eingabe kann auch in einer Datei oder mit dem echo-Befehl erfolgen.
tr ist die Abkürzung für übersetzen .
Das Standardformat für den Befehl tr ist :
$ tr [option] [char_set 1] [char_set 2]
Basierend auf der/den angegebenen Option(en) ersetzt der Befehl tr den Zeichensatz in „Satz 1“ durch „Satz 2“.
Zeichen ersetzen
Um Zeichen mit dem Befehl tr zu ersetzen, geben Sie einfach die Zeichen an, die im 1. Satz ersetzt werden sollen, und Zeichen, die nach dem Ersetzen im 2. Satz an ihre Stelle gesetzt werden sollen.
$ tr 'a' '1'
Dieser Befehl wartet auf die Eingabe von STDIN. Nachdem Sie die Eingabe erhalten haben, erscheint die Ausgabe auf dem Bildschirm, wobei alle Instanzen von „a“ durch „1“ ersetzt werden.

1. Verwenden von echo mit dem tr-Befehl
Das obige Beispiel liest Eingaben von STDIN. Der echo-Befehl kann zusammen mit dem tr-Befehl Eingaben bereitstellen. Verwenden Sie den Pipe(|)-Operator, um die Befehle zusammen auszuführen.
$ echo "apples and bananas" | tr 'a' '1'

2. Eingaben aus einer Datei übernehmen
tr kann seine Eingabe auch aus einer Datei beziehen. Dies ist nützlich, wenn die Übersetzung über eine umfangreiche Textsammlung erfolgen soll. Der Umleitungsoperator (<) wird verwendet, um Eingaben aus einer Datei zu machen.
$ tr 'a' '1' < input.txt

input.txt enthält denselben Text wie das obige Beispiel.
Um den Text in einer Datei zu speichern, verwenden Sie den Operator Umleitung (>), um die Ausgabe in eine Datei umzuleiten.
$ tr 'a' '1' < input.txt > output.txt
Ändern der Schreibweise von Text mit dem Befehl tr
Eine der häufigsten Anwendungen des Befehls tr ist die Übersetzung von Text von Kleinbuchstaben in Großbuchstaben oder umgekehrt.
Da tr mit Zeichensätzen arbeitet, können wir den Satz der Kleinbuchstaben explizit als Satz 1 und den Satz der Großbuchstaben als Satz 2 erwähnen, um den Wechsel vorzunehmen.
$ echo "apples and bananas" | tr a-z A-Z
Stellen Sie a-z ein repräsentiert die Menge der Kleinbuchstaben und die Menge A-Z steht für die Menge der Großbuchstaben.
Eine andere Möglichkeit, dasselbe zu tun, ist:
$ echo "apples and bananas" | tr [:lower:] [:upper:]
Hier, [:lower:] steht für die Menge der Kleinbuchstaben und [:upper:] steht für die Menge der Großbuchstaben.

Zeichen löschen mit tr
tr hat die Fähigkeit, eine Reihe von Zeichen aus dem Text zu löschen. Dies wird durch die Verwendung von tr zusammen mit -d erreicht Befehl.
$ echo "apples and bananas" | tr -d 'n'
Dieser Befehl eliminiert alle Vorkommen von ‘n‘ im Text.

Um Vorkommen mehrerer Zeichen zu entfernen, geben Sie alle Zeichen in einfachen Anführungszeichen an.
$ echo "apples and bananas" | tr -d 'na'
Dieser Befehl entfernt Vorkommen von ‘n‘ und 'a'

Da tr auf Zeichenebene arbeitet, werden alle einzelnen Vorkommen von ‘n’ und 'a' werden entfernt. Es ist leicht, sich zu irren und zu glauben, dass der Befehl nur Vorkommen von ‘na‘ entfernt in dieser Reihenfolge auftreten. Das ist jedoch nicht der Fall.
Mehrere Vorkommen in einem zusammenfassen
Das Zusammendrücken mehrerer Vorkommen zu einem kann nützlich sein, um den Text zu komprimieren. Es wird oft verwendet, um mehrere Leerzeichen zwischen Zeilen zu entfernen.
-s Option wird mit tr verwendet, um zu quetschen.
$ echo "apples and bananas" | tr -s 'p'

Das mehrfache Vorkommen von „p“ in Apfel wurde auf ein einziges Vorkommen reduziert.
$ echo "apples and bananas" | tr -s 'na' '1'
Die Ausgabe dieses Befehls entspricht der ersten Ersetzung der Zeichen ‘n‘ und ‘a ' mit '1' , gefolgt von einem Squeeze-Vorgang. Sehen Sie sich zum Vergleich den zweiten Befehl in der Ausgabe an. Das Ergebnis des zweiten Befehls ist eine einfache Zeichenersetzung.
Lassen Sie uns alle Einsen in der Ausgabe des zweiten Befehls zusammendrücken, um zu sehen, ob wir die gleiche Ausgabe wie beim ersten erhalten.

Wir erhalten dieselbe Ausgabe wie der erste Befehl in der Ausgabe.
Um aufeinanderfolgende Leerzeichen im Text zu entfernen, verwenden Sie :
$ echo "apples and bananas" | tr -s " "

Alternativ [:space:] kann anstelle von “ „ verwendet werden
$ echo "apples and bananas" | tr -s [:space:]
Ziffern aus Text extrahieren
Um Operationen durchzuführen, bei denen nur ein bestimmter Satz von Zeichen beibehalten werden muss. Verwenden Sie am besten -c Möglichkeit. -c dient zur Ergänzung des Sets.
Komplement eines Sets bedeutet alles andere als das, was in diesem Set enthalten ist.
$ echo " Home : 011 1234 4321" | tr -cd [:digit:],'\n'

Erwähnung von ‘\n’ (newline) ist wichtig, da sonst die Ausgabe keinen Zeilenumbruch hat und im Terminal mit der nächsten Zeile verwechselt wird. Ein weiterer Grund, Zeilenumbrüche beim Löschen von Zeichen nicht zu ignorieren, ist, dass Ihre Datei mehrere Ziffern in mehreren Zeilen enthalten könnte. Wenn das Zeilenumbruchzeichen gelöscht wird, erscheinen alle Zahlen zusammen ohne Leerzeichen.

Wörter aus Text extrahieren
Dieser Vorgang ist das genaue Gegenteil des oben durchgeführten. Hier ignorieren wir die Ziffern und konzentrieren uns nur auf Wörter, die aus Buchstaben bestehen.
$ echo " Home : 011 1234 4321" | tr -d [:digit:]

In diesem Beispiel haben wir einfach alle Ziffern aus unserem Text gelöscht.
Eine kontrolliertere Möglichkeit, dasselbe zu tun, wäre die Komplementierung.
$ echo " Home : 011 1234 4321" | tr -cd [:alpha:],'\n'

[:alpha:] stellt die Menge der Alphabete dar. Betrachten Sie es als eine Sammlung der beiden Sätze, des unteren und des oberen.
[:alpha:] = [:lower:] + [:upper:]
Zählen der Anzahl der Vorkommen von Wörtern
Das Zählen, wie oft ein Wort in einem Text vorkommt, kann nützlich sein, um Histogramme zu erstellen. Es ist auch sehr nützlich beim Erstellen von Wahrscheinlichkeitsmodellen für die Erkennung von E-Mail-Spam.
Lassen Sie uns zunächst eine Datei mit einigen wiederkehrenden Wörtern erstellen.

Manchmal kann es sinnvoll sein, jedes Wort des Textes in einer neuen Zeile anzuzeigen.
$ tr -cs "[:alpha:]" "\n" < input.txt
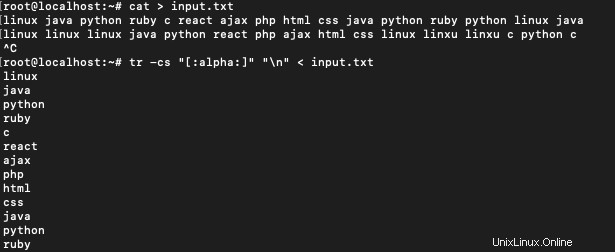
Um die Anzahl der Vorkommen für jedes Wort zu erhalten, verwenden Sie:
$ tr -cs "[:alpha:]" "\n" < input.txt | sort | uniq -c
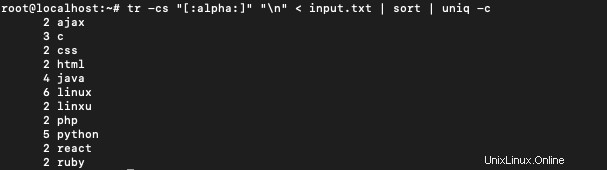
Sortieren wird verwendet, um die Liste lexikografisch zu sortieren. uniq -c zählt die einzelnen Vorkommen jedes Wortes und gibt das Ergebnis als Liste von Wörtern mit einer Anzahl aus.
Schlussfolgerung
Der Befehl tr ist nützlich, um zeichenbasierte Übersetzungen durchzuführen. In Kombination mit anderen Befehlen wie sort oder uniq kann sich der Befehl tr als sehr mächtig erweisen. Lesen Sie mehr über den Befehl tr auf seiner Manpage. Beim Anwenden von Transformationen auf eine ganze Zeile kann der Befehl sed verwendet werden.