Um erfolgreich mit dem Linux-sed-Editor und dem awk-Befehl in Ihren Shell-Skripten zu arbeiten, müssen Sie reguläre Ausdrücke oder kurz Regex verstehen. Da es viele Engines für Regex gibt, werden wir die Shell-Regex verwenden und die Bash-Macht beim Arbeiten mit Regex sehen.
Zuerst müssen wir verstehen, was Regex ist; dann werden wir sehen, wie man es benutzt.
Was ist Regex
Wenn manche Leute die regulären Ausdrücke zum ersten Mal sehen, sagen sie, was sind das für ASCII-Kotze !!
Nun, ein regulärer Ausdruck oder Regex ist im Allgemeinen ein Textmuster, das Sie definieren und das ein Linux-Programm wie sed oder awk verwendet, um Text zu filtern.
Wir haben einige dieser Muster bei der Einführung grundlegender Linux-Befehle gesehen und gesehen, wie der ls-Befehl Platzhalterzeichen verwendet, um die Ausgabe zu filtern.
Regex-Typen
Viele verschiedene Anwendungen verwenden unterschiedliche Regex-Typen in Linux, wie z. B. Regex, der in Programmiersprachen (Java, Perl, Python) und Linux-Programmen wie (sed, awk, grep) und vielen anderen Anwendungen enthalten ist.
Ein Regex-Muster verwendet eine Engine für reguläre Ausdrücke, die diese Muster übersetzt.
Linux hat zwei Engines für reguläre Ausdrücke:
- Der grundlegende reguläre Ausdruck (BRE) Motor.
- Der erweiterte reguläre Ausdruck (ERE) Motor.
Die meisten Linux-Programme funktionieren gut mit den BRE-Engine-Spezifikationen, aber einige Tools wie sed verstehen einige der BRE-Engine-Regeln.
Die POSIX ERE-Engine wird mit einigen Programmiersprachen geliefert. Es bietet mehr Muster, wie z. B. das Abgleichen von Ziffern und Wörtern. Der awk-Befehl verwendet die ERE-Engine, um seine regulären Ausdrucksmuster zu verarbeiten.
Da es viele Regex-Implementierungen gibt, ist es schwierig, Muster zu schreiben, die auf allen Engines funktionieren. Daher konzentrieren wir uns auf die am häufigsten vorkommenden regulären Ausdrücke und demonstrieren, wie man sie in sed und awk verwendet.
BRE-Muster definieren
Sie können ein Muster definieren, um Text wie folgt abzugleichen:
$ echo "Testing regex using sed" | sed -n '/regex/p'
$ echo "Testing regex using awk" | awk '/regex/{print $0}'

Sie werden vielleicht bemerken, dass es der Regex egal ist, wo das Muster vorkommt oder wie oft im Datenstrom.
Die erste Regel, die Sie kennen sollten, ist, dass bei regulären Ausdrucksmustern zwischen Groß- und Kleinschreibung unterschieden wird.
$ echo "Welcome to LikeGeeks" | awk '/Geeks/{print $0}' $ echo "Welcome to Likegeeks" | awk '/Geeks/{print $0}'

Die erste Regex ist erfolgreich, weil das Wort „Geeks“ in Großbuchstaben vorhanden ist, während die zweite Zeile fehlschlägt, weil sie Kleinbuchstaben verwendet.
Sie können Leerzeichen oder Zahlen wie folgt in Ihrem Muster verwenden:
$ echo "Testing regex 2 again" | awk '/regex 2/{print $0}'

Sonderzeichen
Regex-Muster verwenden einige Sonderzeichen. Und Sie können sie nicht in Ihre Muster aufnehmen, und wenn Sie dies tun, erhalten Sie nicht das erwartete Ergebnis.
Diese Sonderzeichen werden von Regex erkannt:
.*[]^${}\+?|() Sie müssen diese Sonderzeichen mit dem Backslash-Zeichen (\) maskieren.
Wenn Sie beispielsweise ein Dollarzeichen ($) finden möchten, maskieren Sie es mit einem umgekehrten Schrägstrich wie diesem:
$ cat myfile There is 10$ on my pocket
$ awk '/\$/{print $0}' myfile
Wenn Sie den umgekehrten Schrägstrich (\) selbst abgleichen müssen, müssen Sie ihn folgendermaßen maskieren:
$ echo "\ is a special character" | awk '/\\/{print $0}'

Obwohl der Schrägstrich kein Sonderzeichen ist, erhalten Sie dennoch eine Fehlermeldung, wenn Sie ihn direkt verwenden.
$ echo "3 / 2" | awk '///{print $0}'

Sie müssen es also folgendermaßen entkommen:
$ echo "3 / 2" | awk '/\//{print $0}'

Ankerzeichen
Um den Anfang einer Zeile in einem Text zu finden, verwenden Sie das Caret-Zeichen (^).
Sie können es wie folgt verwenden:
$ echo "welcome to likegeeks website" | awk '/^likegeeks/{print $0}' $ echo "likegeeks website" | awk '/^likegeeks/{print $0}'

Das Caret-Zeichen (^) entspricht dem Anfang des Textes:
$ awk '/^this/{print $0}' myfile

Was ist, wenn Sie es mitten im Text verwenden?
$ echo "This ^ caret is printed as it is" | sed -n '/s ^/p'

Es wird wie ein normales Zeichen gedruckt.
Wenn Sie awk verwenden, müssen Sie es folgendermaßen maskieren:
$ echo "This ^ is a test" | awk '/s \^/{print $0}'

Hier geht es darum, den Anfang des Textes zu betrachten, was ist mit dem Betrachten des Endes?
Das Dollarzeichen ($) prüft auf das Ende einer Zeile:
$ echo "Testing regex again" | awk '/again$/{print $0}'

Sie können sowohl das Caret- als auch das Dollarzeichen in derselben Zeile wie folgt verwenden:
$ cat myfile this is a test This is another test And this is one more
$ awk '/^this is a test$/{print $0}' myfile
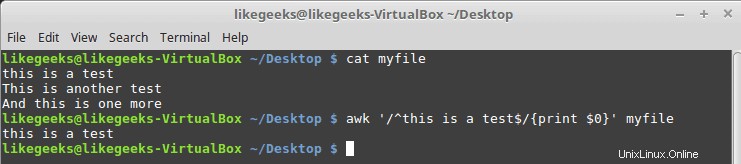
Wie Sie sehen können, wird nur die Zeile gedruckt, die nur das passende Muster hat.
Sie können Leerzeilen mit folgendem Muster filtern:
$ awk '!/^$/{print $0}' myfile Hier führen wir die Verneinung ein, die Sie mit dem Ausrufezeichen !
ausführen könnenDas Muster sucht nach leeren Zeilen, in denen nichts zwischen dem Anfang und dem Ende der Zeile liegt, und negiert dies, um nur die Zeilen mit Text zu drucken.
Das Punktzeichen
Wir verwenden das Punktzeichen, um alle Zeichen außer dem Zeilenumbruch (\n) abzugleichen.
Schauen Sie sich das folgende Beispiel an, um eine Idee zu bekommen:
$ cat myfile this is a test This is another test And this is one more start with this
$ awk '/.st/{print $0}' myfile
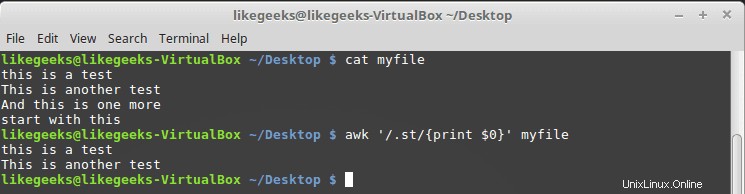
Sie können dem Ergebnis entnehmen, dass nur die ersten beiden Zeilen gedruckt werden, weil sie das M-Muster enthalten, während die dritte Zeile dieses Muster nicht hat, und die vierte Zeile mit M beginnt, sodass dies auch nicht mit unserem Muster übereinstimmt. P>
Zeichenklassen
Sie können jedes Zeichen mit dem Punkt-Sonderzeichen abgleichen, aber wenn Sie nur einen Satz von Zeichen abgleichen, können Sie eine Zeichenklasse verwenden.
Die Zeichenklasse stimmt mit einer Menge von Zeichen überein, wenn eines davon gefunden wird, stimmt das Muster überein.
Wir können die Zeichenklassen mit eckigen Klammern [] wie folgt definieren:
$ awk '/[oi]th/{print $0}' myfile
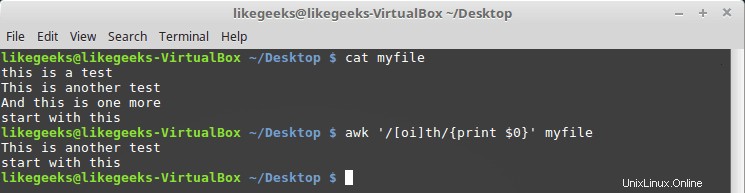
Hier suchen wir nach allen th-Zeichen, denen das Zeichen o oder i vorangestellt ist.
Dies ist praktisch, wenn Sie nach Wörtern suchen, die möglicherweise Groß- oder Kleinbuchstaben enthalten, und Sie sich dessen nicht sicher sind.
$ echo "testing regex" | awk '/[Tt]esting regex/{print $0}' $ echo "Testing regex" | awk '/[Tt]esting regex/{print $0}'

Natürlich ist es nicht auf Zeichen beschränkt; Sie können Zahlen verwenden oder was auch immer Sie wollen. Sie können es verwenden, wie Sie wollen, solange Sie die Idee dazu haben.
Zeichenklassen negieren
Was ist mit der Suche nach einem Zeichen, das nicht in der Zeichenklasse ist?
Um dies zu erreichen, stellen Sie dem Zeichenklassenbereich ein Caret wie dieses voran:
$ awk '/[^oi]th/{print $0}' myfile
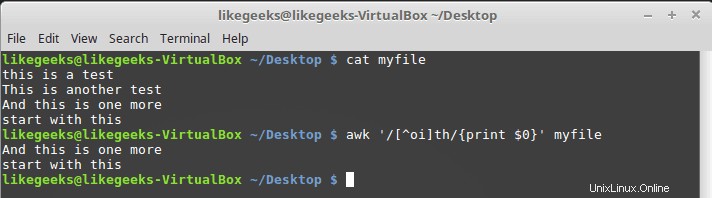
Also ist alles akzeptabel außer o und i.
Bereiche verwenden
Um einen Zeichenbereich anzugeben, können Sie das Symbol (-) wie folgt verwenden:
$ awk '/[e-p]st/{print $0}' myfile
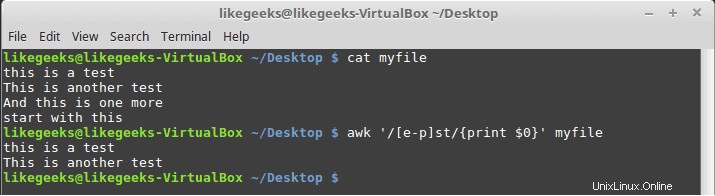
Dies entspricht allen Zeichen zwischen e und p, gefolgt von st, wie gezeigt.
Sie können auch Bereiche für Zahlen verwenden:
$ echo "123" | awk '/[0-9][0-9][0-9]/'
$ echo "12a" | awk '/[0-9][0-9][0-9]/'

Sie können mehrere und getrennte Bereiche wie folgt verwenden:
$ awk '/[a-fm-z]st/{print $0}' myfile
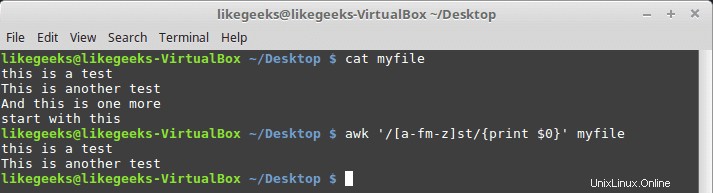
Das Muster bedeutet hier von a bis f, und m bis z müssen vor dem st-Text stehen.
Sonderzeichenklassen
Die folgende Liste enthält die Sonderzeichenklassen, die Sie verwenden können:
| [[:alnum:]] | Muster für 0–9, A–Z oder a–z. |
| [[:blank:]] | Muster nur für Leerzeichen oder Tab. |
| [[:Ziffer:]] | Muster für 0 bis 9. |
| [[:lower:]] | Muster nur für Kleinbuchstaben a–z. |
| [[:print:]] | Muster für jedes druckbare Zeichen. |
| [[:punct:]] | Muster für beliebige Satzzeichen. |
| [[:Leerzeichen:]] | Muster für beliebige Leerzeichen:Leerzeichen, Tabulator, NL, FF, VT, CR. |
| [[:upper:]] | Muster nur für Großbuchstaben A–Z. |
Sie können sie wie folgt verwenden:
$ echo "abc" | awk '/[[:alpha:]]/{print $0}' $ echo "abc" | awk '/[[:digit:]]/{print $0}' $ echo "abc123" | awk '/[[:digit:]]/{print $0}'

Das Sternchen
Das Sternchen bedeutet, dass das Zeichen null oder mehrmals vorkommen muss.
$ echo "test" | awk '/tes*t/{print $0}' $ echo "tessst" | awk '/tes*t/{print $0}'

Dieses Mustersymbol ist nützlich, um Rechtschreibfehler oder Sprachvariationen zu überprüfen.
$ echo "I like green color" | awk '/colou*r/{print $0}' $ echo "I like green color" | awk '/colou*r/{print $0}'

Hier in diesen Beispielen, ob Sie es Farbe oder Farbe eingeben, wird es übereinstimmen, da das Sternchen bedeutet, ob das „u“-Zeichen viele Male oder null Mal vorhanden ist, dass es übereinstimmt.
Um eine beliebige Anzahl beliebiger Zeichen zu finden, können Sie den Punkt verwenden mit dem Sternchen so:
$ awk '/this.*test/{print $0}' myfile
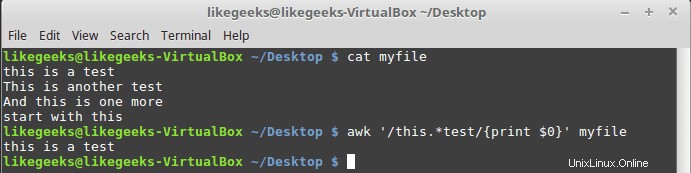
Es spielt keine Rolle, wie viele Wörter zwischen den Wörtern „this“ und „test“ stehen, alle Zeilenübereinstimmungen werden gedruckt.
Sie können das Sternchen-Zeichen mit der Zeichenklasse.
verwenden$ echo "st" | awk '/s[ae]*t/{print $0}' $ echo "sat" | awk '/s[ae]*t/{print $0}' $ echo "set" | awk '/s[ae]*t/{print $0}'
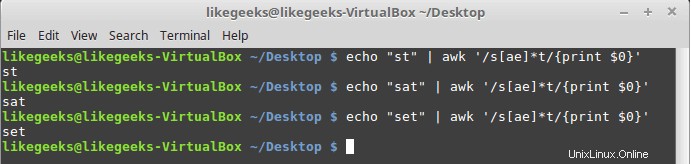
Alle drei Beispiele stimmen überein, weil das Sternchen bedeutet, wenn Sie null Mal oder öfter ein „a“-Zeichen oder „e“ finden, drucken Sie es aus.
Erweiterte reguläre Ausdrücke
Im Folgenden sind einige Muster aufgeführt, die zu Posix ERE gehören:
Das Fragezeichen
Das Fragezeichen bedeutet, dass das vorherige Zeichen einmal oder nicht vorhanden sein kann.
$ echo "tet" | awk '/tes?t/{print $0}' $ echo "tesst" | awk '/tes?t/{print $0}' $ echo "tesst" | awk '/tes?t/{print $0}'
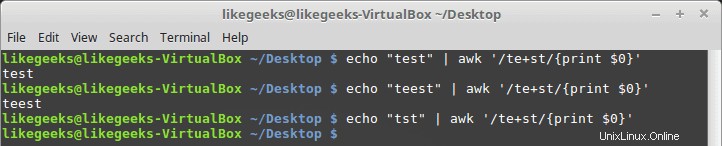
Wir können das Fragezeichen in Kombination mit einer Zeichenklasse verwenden:
$ echo "tst" | awk '/t[ae]?st/{print $0}' $ echo "test" | awk '/t[ae]?st/{print $0}' $ echo "tast" | awk '/t[ae]?st/{print $0}' $ echo "taest" | awk '/t[ae]?st/{print $0}' $ echo "teest" | awk '/t[ae]?st/{print $0}'
Wenn eines der Zeichenklassenelemente vorhanden ist, wird der Mustervergleich bestanden. Andernfalls schlägt das Muster fehl.
Das Pluszeichen
Das Pluszeichen bedeutet, dass das Zeichen vor dem Pluszeichen einmal oder mehrmals vorhanden sein soll, aber mindestens einmal vorhanden sein muss.
$ echo "test" | awk '/te+st/{print $0}' $ echo "teest" | awk '/te+st/{print $0}' $ echo "tst" | awk '/te+st/{print $0}'
Wenn das Zeichen „e“ nicht gefunden wird, schlägt es fehl.
Sie können es mit Zeichenklassen wie dieser verwenden:
$ echo "tst" | awk '/t[ae]+st/{print $0}' $ echo "test" | awk '/t[ae]+st/{print $0}' $ echo "teast" | awk '/t[ae]+st/{print $0}' $ echo "teeast" | awk '/t[ae]+st/{print $0}'
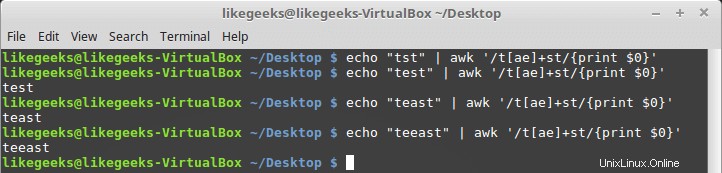
wenn irgendein Zeichen aus der Zeichenklasse existiert, ist es erfolgreich.
Geschweifte Klammern
Mit geschweiften Klammern können Sie die Anzahl der Existenz eines Musters angeben, es hat zwei Formate:
n:Die Regex kommt genau n Mal vor.
n,m:Die Regex kommt mindestens n-mal, aber nicht öfter als m-mal vor.
$ echo "tst" | awk '/te{1}st/{print $0}' $ echo "test" | awk '/te{1}st/{print $0}'

In alten Versionen von awk sollten Sie die Option –re-interval für den awk-Befehl verwenden, damit er geschweifte Klammern liest, aber in neueren Versionen brauchen Sie sie nicht.
$ echo "tst" | awk '/te{1,2}st/{print $0}' $ echo "test" | awk '/te{1,2}st/{print $0}' $ echo "teest" | awk '/te{1,2}st/{print $0}' $ echo "teeest" | awk '/te{1,2}st/{print $0}'

Wenn in diesem Beispiel das Zeichen „e“ ein- oder zweimal vorhanden ist, ist es erfolgreich; andernfalls schlägt es fehl.
Sie können es mit Zeichenklassen wie dieser verwenden:
$ echo "tst" | awk '/t[ae]{1,2}st/{print $0}' $ echo "test" | awk '/t[ae]{1,2}st/{print $0}' $ echo "teest" | awk '/t[ae]{1,2}st/{print $0}' $ echo "teeast" | awk '/t[ae]{1,2}st/{print $0}'
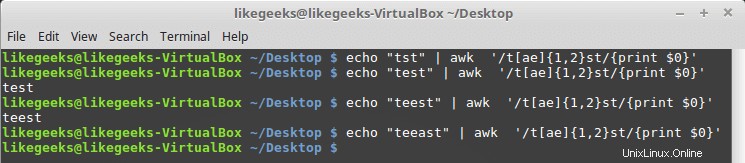
Wenn der Buchstabe „a“ oder „e“ ein- oder zweimal vorkommt, besteht das Muster; andernfalls schlägt es fehl.
Rohrsymbol
Das Pipe-Symbol bildet ein logisches ODER zwischen 2 Mustern. Wenn eines der Muster existiert, ist es erfolgreich; andernfalls schlägt es fehl, hier ist ein Beispiel:
$ echo "Testing regex" | awk '/regex|regular expressions/{print $0}' $ echo "Testing regular expressions" | awk '/regex|regular expressions/{print $0}' $ echo "This is something else" | awk '/regex|regular expressions/{print $0}'
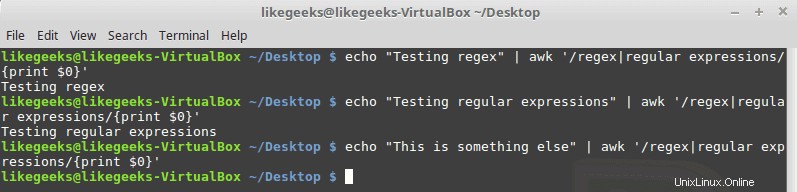
Geben Sie keine Leerzeichen zwischen dem Muster und dem Pipe-Symbol ein.
Gruppierungsausdrücke
Sie können Ausdrücke gruppieren, damit die Regex-Engines sie als ein Stück betrachten.
$ echo "Like" | awk '/Like(Geeks)?/{print $0}' $ echo "LikeGeeks" | awk '/Like(Geeks)?/{print $0}'
Die Gruppierung der „Geeks“ führt dazu, dass die Regex-Engine sie als ein Stück behandelt, wenn also „LikeGeeks“ oder das Wort „Like“ existieren, ist sie erfolgreich.
Praxisbeispiele
Wir haben einige einfache Demonstrationen der Verwendung regulärer Ausdrucksmuster gesehen. Es ist Zeit, das in die Tat umzusetzen, nur zum Üben.
Verzeichnisdateien zählen
Schauen wir uns ein Bash-Skript an, das die ausführbaren Dateien in einem Ordner aus der PATH-Umgebungsvariable zählt.
$ echo $PATH
Um eine Verzeichnisliste zu erhalten, müssen Sie jeden Doppelpunkt durch ein Leerzeichen ersetzen.
$ echo $PATH | sed 's/:/ /g'
Lassen Sie uns nun jedes Verzeichnis mit der for-Schleife wie folgt durchlaufen:
mypath=$(echo $PATH | sed 's/:/ /g') for directory in $mypath; do done
Toll!!
Sie können die Dateien in jedem Verzeichnis mit dem Befehl ls abrufen und in einer Variablen speichern.
#!/bin/bash path_dir=$(echo $PATH | sed 's/:/ /g') total=0 for folder in $path_dir; do files=$(ls $folder) for file in $files; do total=$(($total + 1)) done echo "$folder - $total" total=0 done
Sie werden vielleicht bemerken, dass einige Verzeichnisse nicht existieren, kein Problem damit, es ist in Ordnung.
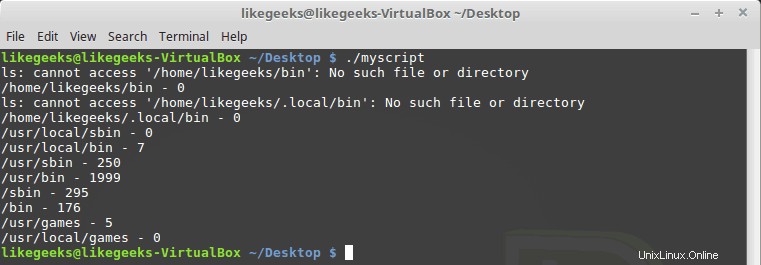
Kühl!! Das ist die Stärke von Regex – diese wenigen Codezeilen zählen alle Dateien in allen Verzeichnissen. Natürlich gibt es einen Linux-Befehl, um das sehr einfach zu machen, aber hier besprechen wir, wie man Regex für etwas verwendet, das man verwenden kann. Sie können sich weitere nützliche Ideen einfallen lassen.
Validieren der E-Mail-Adresse
Es gibt eine Menge Websites, die fertige Regex-Muster für alles anbieten, einschließlich E-Mail, Telefonnummer und vieles mehr. Das ist praktisch, aber wir möchten verstehen, wie es funktioniert.
example@unixlinux.online
Der Benutzername kann beliebige alphanumerische Zeichen in Kombination mit Punkt, Bindestrich, Pluszeichen und Unterstrich enthalten.
Der Hostname kann beliebige alphanumerische Zeichen in Kombination mit einem Punkt und einem Unterstrich enthalten.
Für den Benutzernamen passt das folgende Muster auf alle Benutzernamen:
^([a-zA-Z0-9_\-\.\+]+)@
Das Pluszeichen bedeutet, dass mindestens ein Zeichen vorhanden sein muss, gefolgt vom @-Zeichen.
Dann sollte das Muster des Hostnamens so aussehen:
([a-zA-Z0-9_\-\.]+)
Für die TLDs oder Top-Level-Domains gelten besondere Regeln, und sie dürfen nicht weniger als 2 und maximal fünf Zeichen lang sein. Das Folgende ist das Regex-Muster für die Top-Level-Domain.
\.([a-zA-Z]{2,5})$ Jetzt fügen wir sie alle zusammen:
^([a-zA-Z0-9_\-\.\+]+)@([a-zA-Z0-9_\-\.]+)\.([a-zA-Z]{2,5})$ Lassen Sie uns diesen regulären Ausdruck anhand einer E-Mail testen:
$ echo "example@unixlinux.online" | awk '/^([a-zA-Z0-9_\-\.\+]+)@([a-zA-Z0-9_\-\.]+)\.([a-zA-Z]{2,5})$/{print $0}' $ echo "example@unixlinux.online" | awk '/^([a-zA-Z0-9_\-\.\+]+)@([a-zA-Z0-9_\-\.]+)\.([a-zA-Z]{2,5})$/{print $0}'

Großartig!!
Dies war nur der Anfang der Regex-Welt, die niemals endet. Ich hoffe, Sie verstehen diese ASCII-Kotze 🙂 und verwenden sie professioneller.
Ich hoffe euch gefällt der Beitrag.
Danke.