Das grep-Tool in Linux und anderen Unix-ähnlichen Systemen ist eines der leistungsstärksten Befehlszeilen-Tools, die jemals entwickelt wurden. Es geht auf das ed-Kommando g/re/p zurück und wurde vom legendären Ken Thompson erstellt. Wenn Sie ein erfahrener Linux-Benutzer sind, wissen Sie, wie wichtig reguläre Ausdrücke bei der Dateiverarbeitung sind. Viele Anfänger haben jedoch einfach keine Ahnung davon. Wir sehen oft, dass sich Benutzer bei der Verwendung solcher Techniken unwohl fühlen. Die meisten grep-Befehle sind jedoch nicht so komplex. Sie können grep leicht meistern, indem Sie ihm etwas Zeit geben. Wenn Sie ein Linux-Guru werden möchten, empfehlen wir Ihnen, dieses Tool im täglichen Computereinsatz zu verwenden.
Wichtige grep-Befehle für moderne Linux-Benutzer
Eines der schönsten Dinge am Linux-Befehl grep ist, dass Sie ihn mit allen möglichen Dingen verwenden können. Sie können direkt in Dateien oder von Ihrer Standardausgabe nach Mustern suchen. Es ermöglicht Benutzern, die Ausgabe anderer Befehle weiterzuleiten, um bestimmte Informationen zu grep und zu finden. Die folgenden Befehle beschreiben 50 solcher Befehle.
Demodateien zur Veranschaulichung von grep-Befehlen unter Linux
Da das Linux-Dienstprogramm grep mit Dateien arbeitet, haben wir einige Dateien skizziert, die Sie zum Üben verwenden können. Die meisten Linux-Distributionen sollten einige Wörterbuchdateien im Verzeichnis /usr/share/dict enthalten. Wir haben die hier gefundene amerikanisch-englische Datei für einige unserer Demonstrationszwecke verwendet. Wir haben auch eine einfache Textdatei erstellt, die Folgendes enthält.
this is a sample file it contains a collection of lines to demonstrate various Linux grep commands
Wir haben es test.txt genannt und haben es für viele grep-Beispiele verwendet. Sie können den Text von hier kopieren und denselben Dateinamen zum Üben verwenden. Darüber hinaus haben wir auch die /etc/passwd-Datei genutzt.
Grundlegende grep-Beispiele
Da der grep-Befehl es Benutzern ermöglicht, Informationen mit einer Fülle von Kombinationen auszugraben, werden Anfänger oft mit seiner Verwendung verwechselt. Wir demonstrieren einige grundlegende grep-Beispiele, damit Sie sich mit diesem Tool vertraut machen können. Es wird Ihnen helfen, in Zukunft fortgeschrittenere Befehle zu lernen.
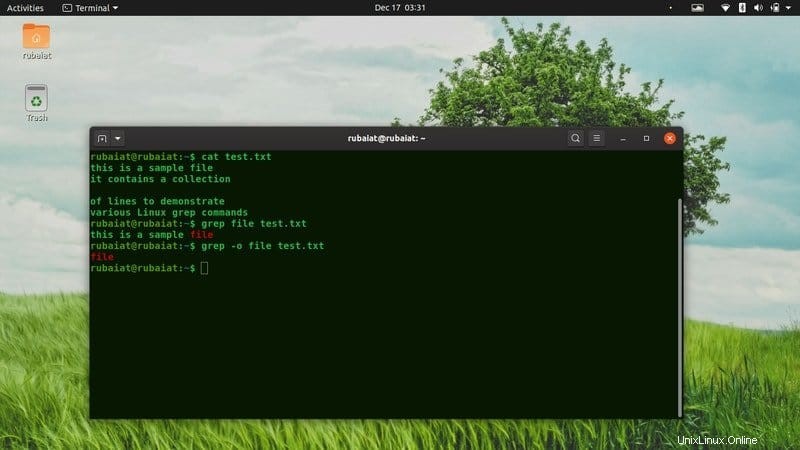
1. Suchen Sie Informationen in einer einzigen Datei
Eine der grundlegenden Anwendungen von grep in Linux besteht darin, Zeilen zu finden, die bestimmte Informationen aus Dateien enthalten. Geben Sie einfach das Muster gefolgt vom Dateinamen nach grep ein, wie unten gezeigt.
- -$ grep root /etc/passwd $ grep $USER /etc/passwd
Das erste Beispiel zeigt alle Zeilen an, die root in der Datei /etc/passwd enthalten. Der zweite Befehl zeigt alle Zeilen an, die Ihren Benutzernamen enthalten.
2. Informationen in mehreren Dateien suchen
Sie können grep verwenden, um Zeilen mit bestimmten Mustern aus mehr als einer Datei gleichzeitig zu drucken. Geben Sie einfach alle Dateinamen getrennt durch Leerzeichen nach dem Muster an. Wir haben test.txt kopiert und erstellte eine weitere Datei mit den gleichen Zeilen, aber mit dem Namen test1.txt .
$ cp test.txt test1.txt $ grep file test.txt test1.txt
Jetzt gibt grep alle Zeilen aus, die Dateien aus beiden Dateien enthalten.
3. Nur passenden Teil drucken
Standardmäßig zeigt grep die gesamte Zeile an, die das Muster enthält. Sie können diese Ausgabe unterdrücken und grep anweisen, nur den übereinstimmenden Teil anzuzeigen. Daher gibt grep nur die angegebenen Muster aus, falls vorhanden.
$ grep -o $USER /etc/passwd $ grep --only-matching $USER /etc/passwd
Dieser Befehl gibt den Wert von $USER aus so oft grep darauf stößt. Wenn keine Übereinstimmung gefunden wird, ist die Ausgabe leer und grep wird beendet.
4. Groß-/Kleinschreibung ignorieren
Standardmäßig sucht grep unter Berücksichtigung der Groß- und Kleinschreibung nach dem angegebenen Muster. Manchmal ist sich der Benutzer der Groß-/Kleinschreibung des Musters nicht sicher. Sie können grep anweisen, in solchen Fällen die Groß-/Kleinschreibung des Musters zu ignorieren, wie unten gezeigt.
$ grep -i $USER /etc/passwd $ grep --ignore-case $USER /etc/passwd $ grep -y $USER /etc/passwd
Dies gibt eine zusätzliche Ausgabezeile in meinem Terminal zurück. Das sollte auch bei deiner Maschine so sein. Der letzte Befehl ist veraltet, also vermeiden Sie diesen.
5. Passende grep-Muster invertieren
Das Dienstprogramm grep ermöglicht es Benutzern, den Abgleich umzukehren. Das bedeutet, dass grep alle Zeilen ausgibt, die das angegebene Muster nicht enthalten. Schauen Sie sich den folgenden Befehl für eine schnelle Ansicht an.
$ grep -v file test.txt $ grep --invert-match file test.txt
Die obigen Befehle sind gleichwertig und geben nur die Zeilen aus, die die Datei nicht enthalten.
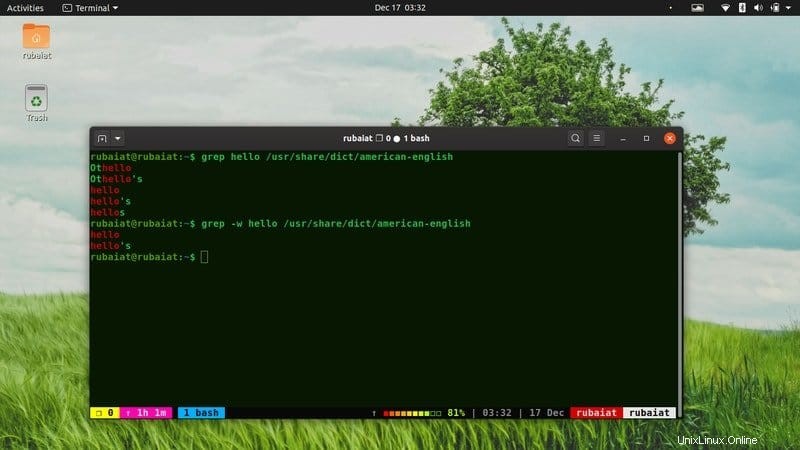
6. Nur ganze Wörter abgleichen
Das Dienstprogramm grep gibt jede Zeile aus, die das Muster enthält. Es werden also auch Zeilen gedruckt, die das Muster in beliebigen Wörtern oder Sätzen enthalten. Oft möchten Sie diese Werte verwerfen. Sie können dies ganz einfach mit der Option -w tun, wie unten gezeigt.
$ grep hello /usr/share/dict/american-english $ grep -w hello /usr/share/dict/american-english
Wenn Sie sie nacheinander ausführen, werden Sie den Unterschied sehen. In meinem System gibt der erste Befehl 5 Zeilen zurück, während der zweite Befehl nur zwei.
7. Zählen Sie die Anzahl der Übereinstimmungen
Oft möchten Sie vielleicht einfach die Anzahl der gefundenen Übereinstimmungen mit einem bestimmten Muster ermitteln. Das -c Option ist in solchen Situationen sehr praktisch. Wenn es verwendet wird, gibt grep die Anzahl der Übereinstimmungen zurück, anstatt die Zeilen auszugeben. Wir haben dieses Flag zu den obigen Befehlen hinzugefügt, damit Sie sich besser vorstellen können, wie das funktioniert.
$ grep -c hello /usr/share/dict/american-english $ grep -c -w hello /usr/share/dict/american-english
Die Befehle geben 5 bzw. 2 zurück.
8. Zeilennummer anzeigen
Sie können grep anweisen, die Zeilennummern anzuzeigen, in denen eine Übereinstimmung gefunden wurde. Es verwendet einen 1-basierten Index, wobei die erste Zeile der Datei Zeilennummer 1 und die zehnte Zeile Zeilennummer 10 ist. Sehen Sie sich die folgenden Befehle an, um zu verstehen, wie das funktioniert.
$ grep -n -w cat /usr/share/dict/american-english $ grep --line-number -w cat /usr/share/dict/american-english
Beide obigen Befehle geben die Zeilen aus, die das Wort Katze im amerikanisch-englischen Wörterbuch enthalten.
9. Dateinamenpräfixe unterdrücken
Wenn Sie die Beispiele des zweiten Befehls erneut ausführen, werden Sie feststellen, dass grep der Ausgabe die Dateinamen voranstellt. Oft möchten Sie sie ignorieren oder ganz weglassen. Die folgenden grep-Befehle von Linux veranschaulichen dies für Sie.
$ grep -h file test.txt test1.txt $ grep --no-filename file test.txt test1.txt
Beide oben genannten Befehle sind gleichwertig, sodass Sie auswählen können, was Sie möchten. Sie geben nur die Zeilen mit dem übereinstimmenden Muster zurück, nicht die Dateinamen.
10. Nur Dateinamenpräfixe anzeigen
Andererseits möchten Sie manchmal nur die Dateinamen, die ein Muster enthalten. Sie können das -l verwenden Möglichkeit dazu. Die Langform dieser Option ist –files-with-matches .
$ grep -l cat /usr/share/dict/*-english $ grep --files-with-matches cat /usr/share/dict/*-english
Beide obigen Befehle geben die Dateinamen aus, die das Muster cat enthalten. Es zeigt die amerikanisch-englischen und britisch-englischen Wörterbücher als Ausgabe von grep in meinem Terminal.
11. Dateien rekursiv lesen
Sie können grep mit -r anweisen, alle Dateien in einem Verzeichnis rekursiv zu lesen oder –rekursive Option . Dadurch werden alle Zeilen gedruckt, die die Übereinstimmung enthalten, und ihnen die Dateinamen vorangestellt, in denen sie gefunden wurden.
$ grep -r -w cat /usr/share/dict
Dieser Befehl gibt alle Dateien aus, die neben ihren Dateinamen das Wort Katze enthalten. Wir verwenden den Speicherort /usr/share/dict, da er bereits mehrere Wörterbuchdateien enthält. Das -R Option kann verwendet werden, um grep zu erlauben, symbolische Links zu durchlaufen.
12. Übereinstimmungen mit dem gesamten Muster anzeigen
Sie können grep auch anweisen, nur die Übereinstimmungen anzuzeigen, die die exakte Übereinstimmung in der gesamten Zeile enthalten. Der folgende Befehl erzeugt beispielsweise Zeilen, die nur das Wort cat.
enthalten$ grep -r -x cat /usr/share/dict/ $ grep -r --line-regexp cat /usr/share/dict/
Sie geben einfach die drei Zeilen zurück, die in meinen Wörterbüchern nur cat enthalten. Mein Ubuntu 19.10 hat drei Dateien im /dict-Verzeichnis, die das Wort cat in einer einzigen Zeile enthalten.
Reguläre Ausdrücke im grep-Befehl von Linux
Eines der überzeugendsten Merkmale von grep ist seine Fähigkeit, mit komplexen regulären Ausdrücken zu arbeiten. Wir haben nur einige grundlegende grep-Beispiele gesehen, die viele seiner Optionen veranschaulichen. Die Fähigkeit, Dateien basierend auf regulären Ausdrücken zu verarbeiten, ist jedoch weitaus anspruchsvoller. Da reguläre Ausdrücke ein gründliches technisches Studium erfordern, bleiben wir bei einfachen Beispielen.
13. Wählen Sie Übereinstimmungen am Anfang aus
Sie können grep verwenden, um eine Übereinstimmung nur am Anfang einer Zeile anzugeben. Dies wird als Verankerung des Musters bezeichnet. Sie müssen das Caretzeichen ‘^’ verwenden Betreiber zu diesem Zweck.
$ grep "^cat" /usr/share/dict/american-english
Der obige Befehl druckt alle Zeilen im amerikanisch-englischen Linux-Wörterbuch, die mit cat beginnen. Bis zu diesem Teil unseres Leitfadens haben wir keine Anführungszeichen verwendet, um unsere Muster anzugeben. Wir werden sie jedoch ab sofort verwenden und empfehlen Ihnen, sie ebenfalls zu verwenden.
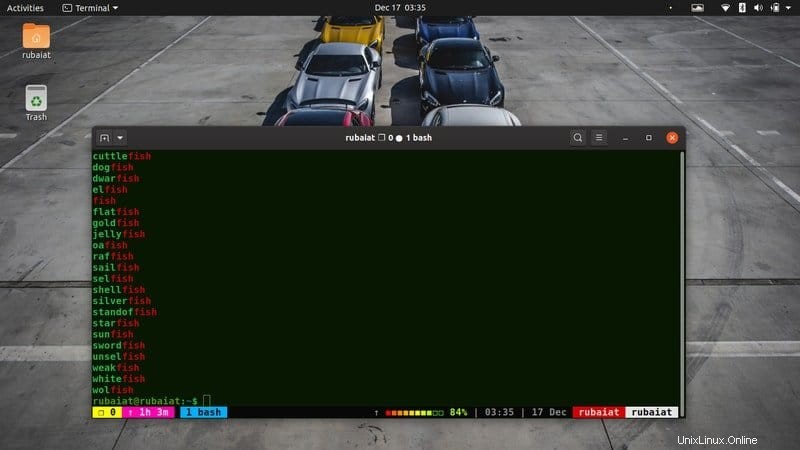
14. Wählen Sie Übereinstimmungen am Ende aus
Ähnlich wie beim obigen Befehl können Sie Ihr Muster auch so verankern, dass es mit Linien übereinstimmt, die am Ende ein Muster enthalten. Sehen Sie sich den folgenden Befehl an, um zu verstehen, wie dies in Linux grep funktioniert.
$ grep "fish$" /usr/share/dict/american-english
Dieser Befehl gibt alle Zeilen aus, die mit Fisch enden. Beachten Sie, wie wir in diesem Fall das $-Symbol am Ende unseres Musters verwendet haben.
15. Übereinstimmung mit einem einzelnen Zeichen
Das Unix-Dienstprogramm grep ermöglicht es Benutzern, jedes einzelne Zeichen als Teil des Musters abzugleichen. Der Punkt ‘.‘ Operator wird zu diesem Zweck verwendet. Sehen Sie sich zum besseren Verständnis die folgenden Beispiele an.
$ grep -x "c.t" /usr/share/dict/american-english
Dieser Befehl druckt alle Zeilen, die Wörter mit drei Zeichen enthalten, die mit c beginnen und mit t enden. Wenn Sie das -x weglassen Option wird die Ausgabe sehr groß, da grep alle Zeilen anzeigt, die eine beliebige Kombination dieser Zeichen enthalten. Sie können doppelte .. verwenden um zwei zufällige Zeichen und dergleichen anzugeben.
16. Übereinstimmung aus einem Zeichensatz
Sie können auch einfach aus einer Reihe von Zeichen auswählen, indem Sie Klammern verwenden. Es weist grep an, Zeichen basierend auf bestimmten Kriterien auszuwählen. Normalerweise verwenden Sie reguläre Ausdrücke, um diese Kriterien anzugeben.
$ grep "c[aeiou]t" /usr/share/dict/american-english $ grep -x "m[aeiou]n" /usr/share/dict/american-english
Das erste Beispiel druckt alle Zeilen im amerikanisch-englischen Wörterbuch, die das Muster c gefolgt von einem einzelnen Vokal und dem Buchstaben t enthalten. Das nächste Beispiel gibt alle exakten Wörter aus, die m gefolgt von einem Vokal und dann n enthalten.
17. Passen Sie aus einer Reihe von Zeichen an
Die folgenden Befehle zeigen, wie Sie mit grep aus einer Reihe von Zeichen übereinstimmen können. Probieren Sie die Befehle selbst aus, um zu sehen, wie die Dinge funktionieren.
$ grep "^[A-Z]" /usr/share/dict/american-english $ grep "[A-Z]$" /usr/share/dict/american-english
Das erste Beispiel druckt alle Zeilen, die mit einem beliebigen Großbuchstaben beginnen. Der zweite Befehl zeigt nur die Zeilen an, die mit einem Großbuchstaben enden.
18. Zeichen in Mustern weglassen
Manchmal möchten Sie vielleicht nach Mustern suchen, die ein bestimmtes Zeichen nicht enthalten. Wie das mit grep geht, zeigen wir Ihnen im nächsten Beispiel.
$ grep -w "[^c]at$" /usr/share/dict/american-english $ grep -w "[^c][aeiou]t" /usr/share/dict/american-english
Der erste Befehl zeigt alle Wörter an, die mit at enden, außer cat. Die [^c] weist grep an, das Zeichen c bei der Suche wegzulassen. Das zweite Beispiel weist grep an, alle Wörter anzuzeigen, die auf einen Vokal gefolgt von t enden und kein c enthalten.
19. Zeichen innerhalb des Musters gruppieren
Mit [] können Sie nur einen einzelnen Zeichensatz angeben. Obwohl Sie mehrere Klammersätze verwenden können, um zusätzliche Zeichen anzugeben, ist dies nicht geeignet, wenn Sie bereits wissen, an welchen Zeichengruppen Sie interessiert sind. Glücklicherweise können Sie () verwenden, um mehrere Zeichen in Ihren Mustern zu gruppieren.
$ grep -E "(copy)" /usr/share/dict/american-english $ egrep "(copy)" /usr/share/dict/american-english
Der erste Befehl gibt alle Zeilen aus, die die Zeichengruppenkopie enthalten. Das-E Flagge ist erforderlich. Sie können den zweiten Befehl egrep verwenden, wenn Sie dieses Flag weglassen möchten. Es ist einfach ein erweitertes Frontend für grep.
20. Geben Sie optionale Zeichen im Muster an
Das Dienstprogramm grep ermöglicht es Benutzern auch, optionale Zeichen für ihre Muster anzugeben. Sie müssen das „?“ verwenden Sinnbild dafür. Alles, was diesem Zeichen vorausgeht, ist in Ihrem Muster optional.
$ grep -E "(commu)?nist" /usr/share/dict/american-english
Dieser Befehl druckt das Wort Kommunist neben allen Zeilen im Wörterbuch, die nist enthalten. Sehen Sie, wie das -E Option wird hier verwendet. Es ermöglicht grep, einen komplexeren oder erweiterten Musterabgleich durchzuführen.

21. Geben Sie Wiederholungen im Muster an
Sie können angeben, wie oft ein Muster für bestimmte grep-Befehle abgeglichen werden muss. Die folgenden Befehle zeigen Ihnen, wie Sie die Anzahl der Zeichen einer Klasse für Grep-Muster auswählen.
$ grep -E "[aeiou]{3}" /usr/share/dict/american-english
$ grep -E "c[aeiou]{2}t" /usr/share/dict/american-english Das erste Beispiel druckt alle Zeilen, die drei Vokale enthalten, wohingegen das letzte Beispiel alle Zeilen druckt, die c gefolgt von 2 Vokalen und dann t enthalten.
22. Geben Sie eine oder mehrere Wiederholungen an
Sie können auch das „+“ verwenden -Operator, der im erweiterten Funktionsumfang von grep enthalten ist, um eine Übereinstimmung einmal oder mehrmals anzugeben. Sehen Sie sich die folgenden Befehle an, um zu sehen, wie dies im Linux-Befehl grep funktioniert.
$ egrep -c "[aeiou]+" /usr/share/dict/american-english
$ egrep -c "[aeiou]{3}" /usr/share/dict/american-english Der erste Befehl gibt aus, wie oft grep auf einen oder mehrere aufeinanderfolgende Vokale trifft. Und der zweite Befehl zeigt, wie viele Zeilen drei aufeinanderfolgende Vokale enthalten. Es sollte eine große Differenzspanne vorhanden sein.
23. Geben Sie die Untergrenze für Wiederholungen an
Sie können sowohl eine Obergrenze als auch eine Untergrenze für die Anzahl der Match-Wiederholungen auswählen. Die nächsten Beispiele zeigen, wie Sie in Aktion Untergrenzen auswählen.
$ egrep "[aeiou]{3,}" /usr/share/dict/american-english Wir haben egrep verwendet statt grep -E für den obigen Befehl. Es wählt alle Zeilen aus, die 3 oder mehr aufeinanderfolgende Vokale enthalten.
24. Obergrenze für Wiederholungen angeben
Wie bei den unteren Grenzen können Sie grep auch mitteilen, wie oft bestimmte Zeichen höchstens übereinstimmen sollen. Das folgende Beispiel stimmt mit allen Zeilen im amerikanisch-englischen Wörterbuch überein, die bis zu 3 Vokale enthalten.
$ egrep "[aeiou]{,3}" /usr/share/dict/american-english Wir empfehlen Benutzern, egrep für diese erweiterten Funktionalitäten zu verwenden, da es etwas schneller und heutzutage eher eine Konvention ist. Beachten Sie die Platzierung des Kommas ‘,’ Symbol in den beiden oben genannten Befehlen.
25. Ober- und Untergrenze angeben
Das Dienstprogramm grep ermöglicht es Benutzern auch, gleichzeitig sowohl die Obergrenze als auch die Untergrenze für Match-Wiederholungen auszuwählen. Der folgende Befehl weist grep an, alle Wörter abzugleichen, die mindestens zwei und höchstens vier aufeinanderfolgende Vokale enthalten.
$ egrep "[aeiou]{2,4}" /usr/share/dict/american-english Auf diese Weise können Sie gleichzeitig Ober- und Untergrenzen festlegen.
26. Alle Zeichen auswählen
Sie können das Platzhalterzeichen „*“ verwenden um alle null oder mehr Vorkommen einer Zeichenklasse in Ihren grep-Mustern auszuwählen. Sehen Sie sich das nächste Beispiel an, um zu verstehen, wie das funktioniert.
$ egrep "collect*" test.txt $ egrep "c[aeiou]*t /usr/share/dict/american-english
Das erste Beispiel gibt die Wortsammlung aus, da es das einzige Wort ist, das in der test.txt einmal oder mehrmals mit „sammeln“ übereinstimmt Datei. Das letzte Beispiel passt auf alle Zeilen, die c gefolgt von einer beliebigen Anzahl von Vokalen und dann t im amerikanisch-englischen Wörterbuch von Linux enthalten.
27. Alternative reguläre Ausdrücke
Das Dienstprogramm grep ermöglicht es Benutzern, abwechselnde Muster anzugeben. Sie können das “|“ verwenden Zeichen, um grep anzuweisen, eines von zwei Mustern auszuwählen. Dieses Zeichen ist in der POSIX-Terminologie als Infix-Operator bekannt. Sehen Sie sich das folgende Beispiel an, um seine Wirkung zu verstehen.
$ egrep "[AEIOU]{2}|[aeiou]{2}" /usr/share/dict/american-english Dieser Befehl weist grep an, alle Zeilen abzugleichen, die entweder 2 aufeinanderfolgende große Vokale oder kleine Vokale enthalten.
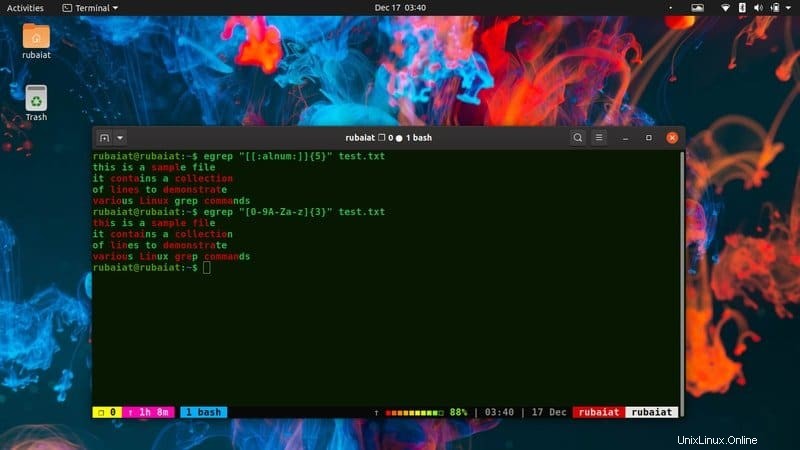
28. Wählen Sie Muster für den Abgleich alphanumerischer Zeichen aus
Alphanumerische Muster enthalten sowohl Ziffern als auch Buchstaben. Die folgenden Beispiele zeigen, wie Sie mit dem grep-Befehl alle Zeilen auswählen, die alphanumerische Zeichen enthalten.
$ egrep "[0-9A-Za-z]{3}" /usr/share/dict/american-english
$ egrep "[[:alnum:]]{3}" /usr/share/dict/american-english Beide oben genannten Befehle machen dasselbe. Wir weisen grep an, alle Zeilen abzugleichen, die drei aufeinanderfolgende Zeichenkombinationen aus 0-9, A-Z und a-z enthalten. Das zweite Beispiel erspart uns jedoch, den Musterbezeichner selbst zu schreiben. Dies wird als spezieller Ausdruck bezeichnet und grep bietet mehrere davon an.
29. Escape-Sonderzeichen
Bisher haben wir viele Sonderzeichen wie „$“, „^“ und „|“ verwendet. zur Definition erweiterter regulärer Ausdrücke. Aber was ist, wenn Sie eines dieser Zeichen in Ihrem Muster abgleichen müssen? Glücklicherweise haben die Entwickler von grep bereits daran gedacht und ermöglichen es, diese Sonderzeichen mit dem Backslash “\” zu maskieren .
$ egrep "\-" /etc/passwd
Der obige Befehl gleicht alle Zeilen von /etc/passwd ab Datei gegen den Bindestrich“-“ Zeichen und druckt sie aus. Alle anderen Sonderzeichen können Sie auf diese Weise mit einem Backslash maskieren.
30. grep-Muster wiederholen
Sie haben bereits das "*" verwendet Platzhalter, um Zeichenfolgen in Ihren Mustern auszuwählen. Der nächste Befehl zeigt Ihnen, wie Sie alle Zeilen ausgeben, die mit Klammern beginnen und nur Buchstaben und einzelne Leerzeichen enthalten. Wir verwenden „*“ um dies zu tun.
$ egrep "([A-Za-z ]*)" test.txt
Fügen Sie nun einige in Klammern eingeschlossene Zeilen in Ihre Demodatei test.txt ein und führen Sie diesen Befehl aus. Sie sollten diesen Befehl bereits beherrschen.
Linux grep-Befehle in der täglichen Computerarbeit
Eines der besten Dinge an grep ist seine universelle Anwendbarkeit. Sie können diesen Befehl verwenden, um wichtige Informationen herauszufiltern, wenn Sie wichtige Linux-Terminalbefehle ausführen. Obwohl der folgende Abschnitt Ihnen einen kurzen Einblick in einige davon bietet, können Sie die Grundprinzipien überall anwenden.
31. Alle Unterverzeichnisse anzeigen
Der folgende Befehl veranschaulicht, wie wir grep verwenden können, um alle Ordner in einem Verzeichnis abzugleichen. Wir verwenden den Befehl ls -l, um den Inhalt des Verzeichnisses in der Standardausgabe anzuzeigen und schneiden die passenden Zeilen mit grep.
ab$ ls -l ~ | grep "drw"
Da alle Verzeichnisse in Linux das Muster drw enthalten Am Anfang verwenden wir dies als unser Muster für grep.
32. Alle MP3-Dateien anzeigen
Der folgende Befehl zeigt, wie Sie grep zum Suchen von MP3-Dateien auf Ihrem Linux-Computer verwenden. Wir werden hier wieder den Befehl ls verwenden.
$ ls /path/to/music/dir/ | grep ".mp3"
Zuerst ls gibt den Inhalt Ihres Musikverzeichnisses in die Ausgabe aus und grep passt dann alle Zeilen an, die .mp3 enthalten. Sie werden die Ausgabe von ls nicht sehen, da wir diese Daten direkt an grep weitergeleitet haben.
33. Text in Dateien suchen
Sie können grep auch verwenden, um bestimmte Textmuster in einer einzelnen Datei oder einer Sammlung von Dateien zu suchen. Angenommen, Sie möchten alle C-Programmdateien finden, die den Text main enthalten in ihnen. Machen Sie sich darüber keine Sorgen, Sie können jederzeit danach greifen.
$ grep -l 'main' /path/to/files/*.c
Standardmäßig sollte grep den Übereinstimmungsteil farblich kennzeichnen, damit Sie Ihre Ergebnisse leicht visualisieren können. Wenn dies jedoch auf Ihrem Linux-Rechner nicht möglich ist, versuchen Sie, –color hinzuzufügen Option zu Ihrem Befehl.
34. Netzwerkhosts finden
Die Datei /etc/hosts enthält Informationen wie Host-IP und Hostname. Sie können grep verwenden, um bestimmte Informationen aus diesem Eintrag zu finden, indem Sie den folgenden Befehl verwenden.
$ grep -E -o "([0-9]{1,3}[\.]){3}[0-9]{1,3}" /etc/hosts Seien Sie nicht beunruhigt, wenn Sie das Muster nicht sofort verstehen. Wenn Sie es einzeln aufschlüsseln, ist es sehr einfach zu verstehen. Tatsächlich sucht dieses Muster nach allen Übereinstimmungen im Bereich 0.0.0.0 und 999.999.999.999. Sie können auch nach Hostnamen suchen.
35. Installierte Pakete finden
Linux sitzt auf mehreren Bibliotheken und Paketen. Mit dem Befehlszeilentool dpkg können Administratoren Pakete auf Debian-basierten Linux-Distributionen wie Ubuntu steuern. Unten sehen Sie, wie wir grep verwenden, um wichtige Informationen über ein Paket mit dpkg herauszufiltern.
$ dpkg --list | grep "chrome"
Es zeigt mehrere nützliche Informationen auf meinem Computer an, darunter die Versionsnummer, die Architektur und die Beschreibung des Google Chrome-Browsers. Sie können es auf ähnliche Weise verwenden, um Informationen für Pakete zu finden, die auf Ihrem System installiert sind.

36. Verfügbare Linux-Images finden
Wir verwenden das Dienstprogramm grep erneut mit dem Befehl dpkg, um alle verfügbaren Linux-Images zu finden. Die Ausgabe dieses Befehls wird je nach System stark variieren.
$ dpkg --list | grep linux-image
Dieser Befehl gibt einfach das Ergebnis von dpkg –list aus und übergibt es an grep. Es vergleicht dann alle Zeilen mit dem gegebenen Muster.
37. Modellinformationen für CPU finden
Der folgende Befehl zeigt, wie Sie CPU-Modellinformationen in Linux-basierten Systemen mit dem grep-Befehl finden.
$ cat /proc/cpuinfo | grep -i 'model' $ grep -i "model" /proc/cpuinfo
Im ersten Beispiel haben wir die Ausgabe von cat /proc/cpuinfo an grep weitergeleitet und alle Zeilen abgeglichen, die das Wort model enthalten. Da jedoch /proc/cpuinfo selbst eine Datei ist, können Sie grep direkt darauf anwenden, wie das letzte Beispiel zeigt.
38. Protokollinformationen finden
Linux speichert für uns Systemadministratoren alle Arten von Protokollen im /var-Verzeichnis. Sie können diesen Protokolldateien leicht nützliche Informationen entnehmen. Der folgende Befehl zeigt ein einfaches solches Beispiel.
$ grep -i "cron" /var/log/auth.log
Dieser Befehl untersucht die Datei /var/log/auth.log auf potenzielle Zeilen, die Informationen zu Linux-CRON-Jobs enthalten. Das -i flag ermöglicht es uns, flexibler zu sein. Wenn Sie diesen Befehl ausführen, werden alle Zeilen mit dem Wort CRON in der Datei auth.log angezeigt.
39. Prozessinformationen finden
Der nächste Befehl zeigt, wie wir mithilfe von grep nützliche Informationen für Systemprozesse finden können. Ein Prozess ist die laufende Instanz eines Programms auf Linux-Rechnern.
$ ps auxww | grep 'guake'
Dieser Befehl gibt alle Informationen aus, die sich auf Guake beziehen Paket. Versuchen Sie es mit einem anderen Paket, falls guake ist auf Ihrem Gerät nicht verfügbar.
40. Wählen Sie Nur gültige IPs aus
Zuvor haben wir einen relativ einfacheren regulären Ausdruck zum Abgleichen von IP-Adressen aus /etc/hosts verwendet Datei. Allerdings würde dieser Befehl auch mit vielen ungültigen IPs übereinstimmen, da gültige IPs nur die Werte aus dem Bereich (1-255) in jedem ihrer vier Quadranten annehmen können.
$ egrep '\b(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?\.){3}(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)' /etc/hosts Der obige Befehl druckt keine ungültigen IP-Adressen wie 999.999.999.999.
41. Suche in komprimierten Dateien
Das zgrep-Frontend des Linux-Befehls grep ermöglicht uns die Suche nach Mustern direkt in komprimierten Dateien. Werfen Sie zum besseren Verständnis einen kurzen Blick auf die folgenden Codeausschnitte.
$ gzip test.txt $ zgrep -i "sample" test.txt.gz
Zuerst komprimieren wir die test.txt Datei mit gzip und dann mit zgrep, um sie nach dem Wort sample.
zu durchsuchen42. Anzahl der Leerzeilen zählen
Sie können die Anzahl der leeren Zeilen in einer Datei ganz einfach mit grep zählen, wie im nächsten Beispiel gezeigt.
$ grep -c "^$" test.txt
Seit test.txt nur eine einzige leere Zeile enthält, gibt dieser Befehl 1 zurück. Die leeren Zeilen werden mit dem regulären Ausdruck “^$” abgeglichen und ihre Zählung wird durch Nutzung des -c ausgegeben Option.
43. Mehrere Muster finden
Bisher haben wir uns darauf konzentriert, ein einzelnes Muster zu finden. Das Dienstprogramm grep ermöglicht es Benutzern auch, gleichzeitig nach Linien mit mehreren Mustern zu suchen. Sehen Sie sich die folgenden Beispielbefehle an, um zu sehen, wie das funktioniert.
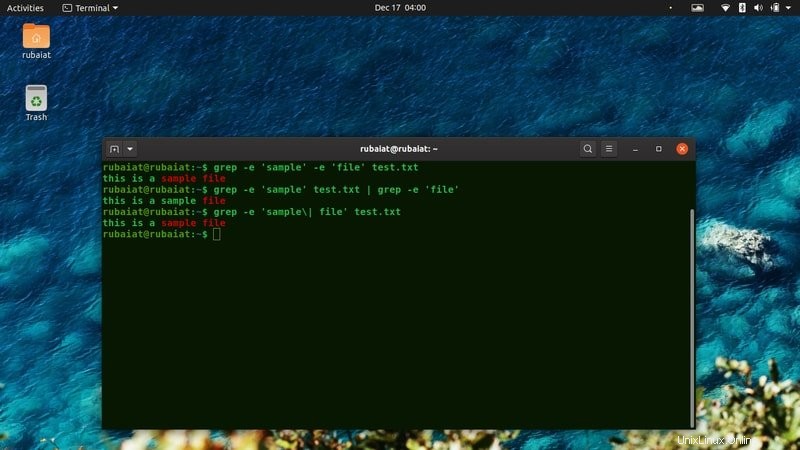
$ grep -e 'sample' -e 'file' test.txt $ grep -e 'sample' test.txt | grep -e 'file' $ grep -e 'sample\| file' test.txt
Alle oben genannten Befehle drucken die Zeilen, die sowohl „Beispiel“ als auch „Datei“ enthalten.
44. Gültige E-Mail-Adressen abgleichen
Viele erfahrene Programmierer validieren Benutzereingaben gerne selbst. Glücklicherweise ist es sehr einfach, Eingabedaten wie IP und E-Mails mit regulären grep-Ausdrücken zu validieren. Der folgende Befehl gleicht alle gültigen E-Mail-Adressen ab.
$ grep -E -o "\b[A-Za-z0-9._%+-]example@unixlinux.online[A-Za-z0-9.-]+\.[A-Za-z]{2,6}\b" /path/to/data Dieser Befehl ist äußerst effizient und passt mühelos bis zu 99 % gültige E-Mail-Adressen an. Sie können egrep verwenden, um den Prozess zu beschleunigen.
Verschiedene grep-Befehle
Das Dienstprogramm grep bietet viele weitere nützliche Befehlskombinationen, die weitere Operationen mit Daten ermöglichen. In diesem Abschnitt besprechen wir einige selten verwendete, aber wichtige Befehle.
45. Muster aus Dateien auswählen
Sie können Ihre regulären Ausdrucksmuster für grep ganz einfach aus vordefinierten Dateien auswählen. Verwenden Sie das -f Option dafür.
$ echo "sample"> file $ grep -f file test.txt
Wir erstellen mit dem echo-Befehl eine Eingabedatei, die ein Muster enthält. Der zweite Befehl demonstriert die Dateieingabe für grep.
46. Kontexte steuern
Sie können den Ausgabekontext von grep einfach mit den Optionen -A steuern , -B , und -C . Die folgenden Befehle zeigen sie in Aktion.
$ grep -A2 'file' test.txt $ grep -B2 'file' test.txt $ grep -C3 'Linux' test.txt
Das erste Beispiel zeigt die nächsten 2 Zeilen nach der Übereinstimmung, das zweite Beispiel zeigt die vorherigen 2 und das letzte Beispiel zeigt beide.
47. Fehlermeldungen unterdrücken
Das -s Diese Option ermöglicht es Benutzern, die von grep angezeigten Standardfehlermeldungen im Falle nicht vorhandener oder nicht lesbarer Dateien zu unterdrücken.
$ grep -s 'file' testing.txt $ grep −−no-messages 'file' testing.txt
Obwohl es keine Datei mit dem Namen testing.txt gibt In meinem Arbeitsverzeichnis gibt grep keine Fehlermeldung für diesen Befehl aus.
48. Versionsinformationen anzeigen
Das Dienstprogramm grep ist viel älter als Linux selbst und stammt aus den Anfängen von Unix. Verwenden Sie den nächsten Befehl, wenn Sie die Versionsinformationen von grep erhalten möchten.
$ grep -V $ grep --version
49. Hilfeseite anzeigen
Die Hilfeseite für grep enthält eine zusammengefasste Liste aller verfügbaren Funktionen. Es hilft, viele Probleme direkt vom Terminal aus zu lösen.
$ grep --help
Dieser Befehl ruft die Hilfeseite für grep auf.
50. Konsultieren Sie die Dokumentation
Die grep-Dokumentation ist äußerst detailliert und bietet eine gründliche Einführung in die verfügbaren Funktionen und die Verwendung regulärer Ausdrücke. Sie können die Handbuchseite für grep mit dem folgenden Befehl konsultieren.
$ man grep
Abschlussgedanken
Da Sie mit den robusten CLI-Optionen von grep jede beliebige Kombination von Befehlen erstellen können, ist es schwierig, alles über den grep-Befehl in einer einzigen Anleitung zusammenzufassen. Unsere Redakteure haben jedoch ihr Bestes gegeben, um fast jedes praktische grep-Beispiel zu skizzieren, damit Sie sich besser damit vertraut machen können. Wir empfehlen Ihnen, so viele dieser Befehle wie möglich zu üben und Wege zu finden, grep in Ihre tägliche Dateiverarbeitung zu integrieren. Auch wenn Sie jeden Tag auf neue Hindernisse stoßen, ist dies der einzige Weg, den Linux-Befehl grep wirklich zu meistern.