Kürzlich sah ich eine Frage, die diesen Gedanken auslöste. Konnte hier oder über die Google-Maschine keine wirkliche Antwort finden. Grundsätzlich interessiert mich, wie die I/O-Architektur des Kernels geschichtet ist. Beispiel:kjournald Versand an pdflush oder umgekehrt? Meine Vermutung ist, dass pdflush (generischer für Massenspeicher-E/A) würde sich auf einer niedrigeren Ebene befinden und die SCSI/ATA/was auch immer-Befehle auslösen, die erforderlich sind, um die Schreibvorgänge tatsächlich auszuführen, und kjournald verarbeitet Dateisystemdatenstrukturen auf höherer Ebene vor dem Schreiben. Ich könnte es aber auch umgekehrt sehen, mit kjournald direkte Schnittstelle mit den Dateisystem-Datenstrukturen und pdflush hin und wieder aufwachen, um unsaubere Pagecache-Seiten über kjournald auf das Gerät zu schreiben . Es ist auch möglich, dass die beiden aus anderen Gründen überhaupt nicht interagieren.
Grundsätzlich: Ich brauche eine Möglichkeit, um die grundlegende Architektur zu visualisieren (Grafik oder nur eine Erklärung), die zum Verteilen von E / A an Massenspeicher innerhalb des Linux-Kernels verwendet wird.
Akzeptierte Antwort:
Bevor wir die Besonderheiten von pdflush besprechen , kjournald, and kswapd`, lassen Sie uns zunächst ein wenig Hintergrundwissen zum Kontext dessen bekommen, worüber wir genau in Bezug auf den Linux-Kernel sprechen.
Die GNU/Linux-Architektur
Die Architektur von GNU/Linux kann man sich als 2 Räume vorstellen:
- Benutzer
- Kernel
Zwischen dem User Space und Kernel Space sitzt die GNU-C-Bibliothek (glibc ). Dies stellt die Systemaufrufschnittstelle bereit, die den Kernel mit den Benutzerbereichsanwendungen verbindet.
Der Kernel Space kann weiter in 3 Ebenen unterteilt werden:
- Systemaufrufschnittstelle
- Architekturunabhängiger Kernel-Code
- Architekturabhängiger Code
Systemanrufschnittstelle Stellen Sie, wie der Name schon sagt, eine Schnittstelle zwischen glibc bereit und der Kern. Der Architectural Independent Kernel Code besteht aus den logischen Einheiten wie dem VFS (Virtual File System) und dem VMM (Virtual Memory Management). Der architektonisch abhängige Code sind die Komponenten, die prozessor- und plattformspezifischer Code für eine bestimmte Hardwarearchitektur sind.
Diagramm der GNU/Linux-Architektur
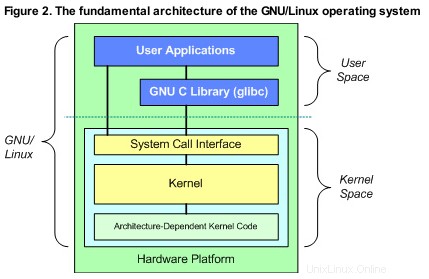
Für den Rest dieses Artikels konzentrieren wir uns auf die logischen VFS- und VMM-Einheiten im Kernel Space.
Subsysteme des GNU/Linux-Kernels
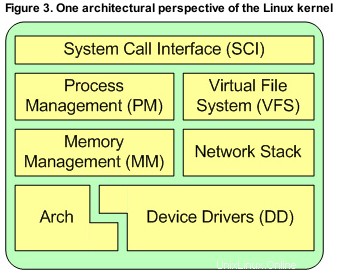
VFS-Subsystem
Mit einem allgemeinen Konzept darüber, wie der GNU/Linux-Kernel strukturiert ist, können wir etwas tiefer in das VFS-Subsystem eintauchen. Diese Komponente ist für die Bereitstellung des Zugriffs auf die verschiedenen Blockspeichergeräte verantwortlich, die letztendlich einem Dateisystem (ext3/ext4/etc.) auf einem physischen Gerät (HDD/etc.) zugeordnet werden.
Diagramm von VFS
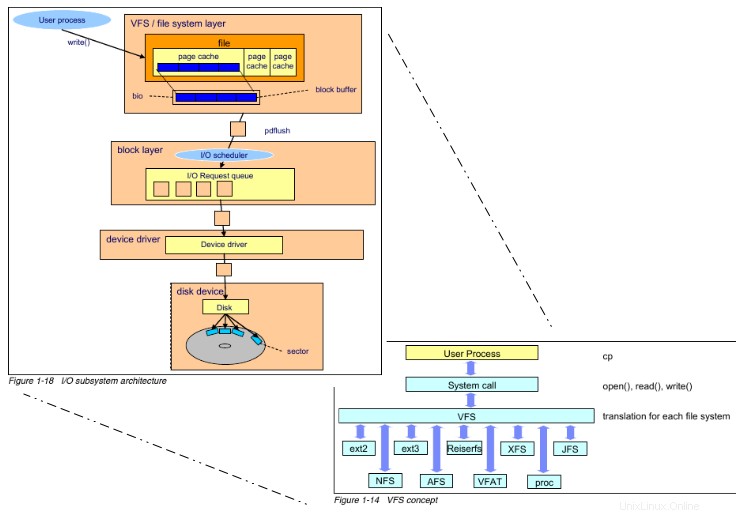
Dieses Diagramm zeigt, wie ein write() aus dem Prozess eines Benutzers durchläuft das VFS und arbeitet sich schließlich bis zum Gerätetreiber vor, wo es auf das physische Speichermedium geschrieben wird. Dies ist der erste Ort, an dem wir auf pdflush stoßen . Dabei handelt es sich um einen Daemon, der dafür verantwortlich ist, Dirty Data und Metadata Buffer Blocks im Hintergrund auf das Speichermedium zu spülen. Das Diagramm zeigt dies nicht, aber es gibt einen anderen Daemon, kjournald , das sich neben pdflush befindet , indem Sie eine ähnliche Aufgabe ausführen und Dirty-Journal-Blöcke auf die Festplatte schreiben. HINWEIS: Mit Journalblöcken verfolgen Dateisysteme wie ext4 und JFS Änderungen an der Festplatte in einer Datei, bevor diese Änderungen stattfinden.
Die obigen Details werden in diesem Dokument weiter diskutiert.
Überblick über write() Schritte
Um einen einfachen Überblick über die I/O-Operationen des Sybsystems zu geben, verwenden wir ein Beispiel, in dem die Funktion write() wird von einer User Space-Anwendung aufgerufen.
- Ein Prozess fordert das Schreiben einer Datei durch
write()an Systemaufruf. - Der Kernel aktualisiert den Seiten-Cache, der der Datei zugeordnet ist.
- Ein pdflush-Kernel-Thread sorgt dafür, dass der Seiten-Cache auf die Festplatte geleert wird.
- Die Dateisystemschicht fügt jeden Blockpuffer zu einer
bio structzusammen (siehe 1.4.3, „Blockschicht“ auf Seite 23) und sendet eine Schreibanforderung an die Blockgeräteschicht. - Die Blockgeräteschicht erhält Anforderungen von höheren Schichten und führt eine E/A-Aufzugsoperation durch und stellt die Anforderungen in die E/A-Anforderungswarteschlange.
- Ein Gerätetreiber wie SCSI oder andere gerätespezifische Treiber kümmern sich um den Schreibvorgang.
- Eine Plattengerät-Firmware führt Hardwareoperationen wie Suchkopf, Drehung und Datenübertragung zum Sektor auf der Platte durch.
VMM-Subsystem
Wir setzen unseren tieferen Tauchgang fort und können uns nun das VMM-Subsystem ansehen. Diese Komponente ist für die Aufrechterhaltung der Konsistenz zwischen Hauptspeicher (RAM), Swap und dem physischen Speichermedium verantwortlich. Der primäre Mechanismus zum Aufrechterhalten der Konsistenz ist bdflush . Da Speicherseiten als schmutzig gelten, müssen sie mit den Daten auf dem Speichermedium synchronisiert werden. bdflush wird mit pdflush koordiniert Daemons, um diese Daten mit dem Speichermedium zu synchronisieren.
Diagramm von VMM
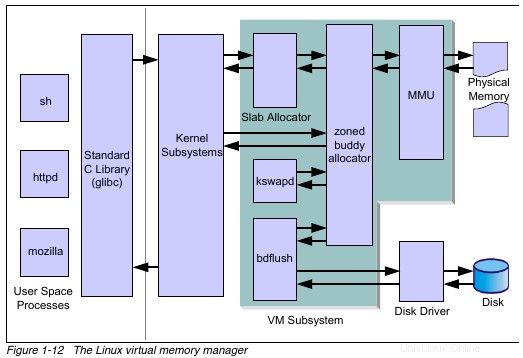
Wechseln
Wenn der Systemspeicher knapp wird oder der Kernel-Swap-Timer abläuft, wird der kswapd Daemon wird versuchen, Seiten freizugeben. Solange die Anzahl der kostenlosen Seiten über free_pages_high bleibt , kswapd wird nichts tun. Sinkt jedoch die Anzahl der freien Seiten unter, dann kswapd startet den Seitenwiederherstellungsprozess. Nach kswapd hat Seiten zum Verschieben markiert, bdflush wird sich darum kümmern, alle ausstehenden Änderungen mit dem Speichermedium über pdflush zu synchronisieren Dämonen.
Referenzen und weiterführende Literatur
- Konzeptionelle Architektur des Linux-Kernels
- Das Linux-E/A-Stapeldiagramm – Ver. 0.1, 06.03.2012 – skizziert den Linux-I/O-Stack ab Kernel 3.3
- Aktualisierung des lokalen Dateisystems – insbesondere Folie Nr. 7
- Interaktive Linux-Kernel-Map
- Virtuellen Speicher in Red Hat Enterprise Linux 4 verstehen
- Linux Performance and Tuning Guidelines – speziell Seiten 19-24
- Anatomie des Linux-Kernels
- Der Fall für eine semantikbewusste Remote-Replikation