Die Hauptaufgabe eines Webroboters besteht darin, Websites und Seiten nach Informationen zu durchsuchen oder zu scannen. Sie arbeiten unermüdlich daran, Daten für Suchmaschinen und andere Anwendungen zu sammeln. Für manche gibt es gute Gründe, Seiten von Suchmaschinen fernzuhalten. Unabhängig davon, ob Sie den Zugriff auf Ihre Website optimieren oder an einer Entwicklungswebsite arbeiten möchten, ohne in den Google-Ergebnissen angezeigt zu werden, lässt die robots.txt-Datei nach der Implementierung Web-Crawler und Bots wissen, welche Informationen sie sammeln können.
Was ist eine Robots.txt-Datei?
Eine robots.txt ist eine einfache Text-Website-Datei im Stammverzeichnis Ihrer Website, die dem Robots Exclusion Standard folgt. Beispielsweise hätte www.yourdomain.com eine robots.txt-Datei unter www.yourdomain.com/robots.txt. Die Datei besteht aus einer oder mehreren Regeln, die Crawlern den Zugriff erlauben oder blockieren und sie auf einen bestimmten Dateipfad auf der Website beschränken. Standardmäßig sind alle Dateien zum Crawlen zugelassen, sofern nicht anders angegeben.
Die robots.txt-Datei ist einer der ersten Aspekte, die von Crawlern analysiert werden. Es ist wichtig zu beachten, dass Ihre Website nur eine robots.txt-Datei haben kann. Die Datei wird auf einer oder mehreren Seiten oder einer ganzen Website implementiert, um Suchmaschinen davon abzuhalten, Details über Ihre Website anzuzeigen.
Dieser Artikel enthält fünf Schritte zum Erstellen einer robots.txt-Datei und die Syntax, die erforderlich ist, um Bots in Schach zu halten.
So richten Sie eine Robots.txt-Datei ein
1. Erstellen Sie eine Robots.txt-Datei
Sie müssen Zugriff auf das Stammverzeichnis Ihrer Domäne haben. Ihr Webhosting-Anbieter kann Ihnen dabei behilflich sein, ob Sie über die entsprechenden Zugriffsrechte verfügen.
Der wichtigste Teil der Datei ist ihre Erstellung und ihr Speicherort. Verwenden Sie einen beliebigen Texteditor, um eine robots.txt-Datei zu erstellen und zu finden unter:
- Das Stammverzeichnis Ihrer Domain:www.ihredomain.com/robots.txt.
- Ihre Subdomains:page.yourdomain.com/robots.txt.
- Nicht standardmäßige Ports:www.yourdomain.com:881/robots.txt.
Schließlich müssen Sie sicherstellen, dass Ihre robots.txt-Datei eine UTF-8-codierte Textdatei ist. Google und andere beliebte Suchmaschinen und Crawler ignorieren möglicherweise Zeichen außerhalb des UTF-8-Bereichs, wodurch Ihre robots.txt-Regeln möglicherweise ungültig werden.
2. Legen Sie Ihren Robots.txt-Benutzeragenten fest
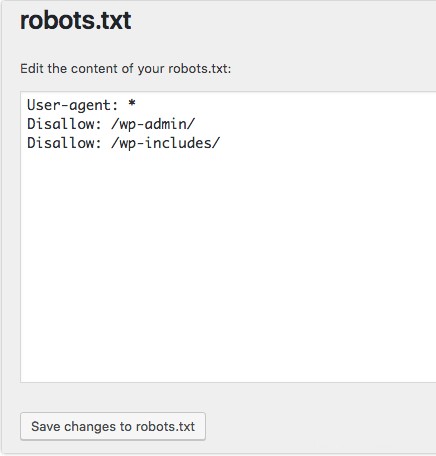
Der nächste Schritt beim Erstellen von robots.txt-Dateien besteht darin, den User-Agent festzulegen . Der User-Agent bezieht sich auf die Webcrawler oder Suchmaschinen, die Sie zulassen oder blockieren möchten. Der User-Agent könnte mehrere Entitäten sein . Nachfolgend haben wir einige Crawler sowie deren Zuordnungen aufgelistet.
Es gibt drei verschiedene Möglichkeiten, einen User-Agent einzurichten in Ihrer robots.txt-Datei.
Einen User-Agent erstellen
Die Syntax, die Sie zum Festlegen des Benutzeragenten verwenden, lautet User-agent:NameOfBot . Unten ist DuckDuckBot der einzige User-Agent eingerichtet.
# Example of how to set user-agent
User-agent: DuckDuckBotErstellen von mehr als einem User-Agent
Wenn wir mehr als einen hinzufügen müssen, gehen Sie genauso vor wie beim User-Agent von DuckDuckBot Geben Sie in einer nachfolgenden Zeile den Namen des zusätzlichen Benutzeragenten ein . In diesem Beispiel haben wir Facebot verwendet.
#Example of how to set more than one user-agent
User-agent: DuckDuckBot
User-agent: FacebotAlle Crawler als User-Agent festlegen
Um alle Bots oder Crawler zu blockieren, ersetzen Sie den Namen des Bots durch ein Sternchen (*).
#Example of how to set all crawlers as user-agent
User-agent: *3. Legen Sie Regeln für Ihre Robots.txt-Datei fest
Eine robots.txt-Datei wird in Gruppen gelesen. Eine Gruppe gibt an, wer der User-Agent ist ist und eine Regel oder Anweisung hat, um anzugeben, welche Dateien oder Verzeichnisse der Benutzeragent enthält zugreifen können oder nicht.
Hier sind die verwendeten Anweisungen:
- Nicht zulassen :Die Direktive, die sich auf eine Seite oder ein Verzeichnis relativ zu Ihrer Root-Domain bezieht, die Sie nicht mit dem benannten User-Agent möchten kriechen. Es beginnt mit einem Schrägstrich (/), gefolgt von der vollständigen Seiten-URL. Sie beenden es nur dann mit einem Schrägstrich, wenn es sich auf ein Verzeichnis und nicht auf eine ganze Seite bezieht. Sie können ein oder mehrere disallow verwenden Einstellungen pro Regel.
- Zulassen :Die Direktive bezieht sich auf eine Seite oder ein Verzeichnis relativ zu Ihrer Root-Domain, die Sie als benannten user-agent verwenden möchten kriechen. Sie würden beispielsweise allow verwenden Direktive zum Überschreiben des disallow Regel. Es beginnt auch mit einem Schrägstrich (/), gefolgt von der vollständigen Seiten-URL. Sie beenden es nur dann mit einem Schrägstrich, wenn es sich auf ein Verzeichnis und nicht auf eine ganze Seite bezieht. Sie können ein oder mehrere allow verwenden Einstellungen pro Regel.
- Sitemap :Die Sitemap-Direktive ist optional und gibt den Speicherort der Sitemap für die Website an. Die einzige Bedingung ist, dass es sich um eine vollqualifizierte URL handeln muss. Sie können je nach Bedarf null oder mehr verwenden.
Die Webcrawler arbeiten die Gruppen von oben nach unten ab. Wie bereits erwähnt, greifen sie auf alle Seiten oder Verzeichnisse zu, die nicht explizit auf disallow gesetzt sind . Fügen Sie daher Disallow:/ hinzu unter dem user-agent Informationen in jeder Gruppe, um diese spezifischen Benutzeragenten am Crawlen Ihrer Website zu hindern.
# Example of how to block DuckDuckBot
User-agent: DuckDuckBot
Disallow: /
#Example of how to block more than one user-agent
User-agent: DuckDuckBot
User-agent: Facebot
Disallow: /
#Example of how to block all crawlers
User-agent: *
Disallow: /Um eine bestimmte Subdomain für alle Crawler zu blockieren, fügen Sie einen Schrägstrich und die vollständige Subdomain-URL in Ihre Sperrregel ein.
# Example
User-agent: *
Disallow: /https://page.yourdomain.com/robots.txtWenn Sie ein Verzeichnis blockieren möchten, gehen Sie genauso vor, indem Sie einen Schrägstrich und Ihren Verzeichnisnamen hinzufügen, aber dann mit einem weiteren Schrägstrich enden.
# Example
User-agent: *
Disallow: /images/Wenn Sie schließlich möchten, dass alle Suchmaschinen Informationen auf allen Seiten Ihrer Website sammeln, können Sie entweder ein Zulassen erstellen oder nicht zulassen Regel, aber stellen Sie sicher, dass Sie einen Schrägstrich hinzufügen, wenn Sie allow verwenden Regel. Beispiele für beide Regeln sind unten aufgeführt.
# Allow example to allow all crawlers
User-agent: *
Allow: /
# Disallow example to allow all crawlers
User-agent: *
Disallow:4. Laden Sie Ihre Robots.txt-Datei hoch
Websites werden nicht automatisch mit einer robots.txt-Datei geliefert, da dies nicht erforderlich ist. Sobald Sie sich entschieden haben, eine zu erstellen, laden Sie die Datei in das Stammverzeichnis Ihrer Website hoch. Das Hochladen hängt von der Dateistruktur Ihrer Website und Ihrer Webhosting-Umgebung ab. Wenden Sie sich an Ihren Hosting-Provider, um Unterstützung beim Hochladen Ihrer robots.txt-Datei zu erhalten.
5. Überprüfen Sie, ob Ihre Robots.txt-Datei ordnungsgemäß funktioniert
Es gibt mehrere Möglichkeiten, Ihre robots.txt-Datei zu testen und sicherzustellen, dass sie richtig funktioniert. Mit jedem davon können Sie alle Fehler in Ihrer Syntax oder Logik sehen. Hier sind einige davon:
- Robots.txt-Tester von Google in der Search Console.
- Das robots.txt-Validierungs- und Testtool von Merkle, Inc.
- Robots.txt-Testtool von Ryte.
Bonus:Robots.txt in WordPress verwenden
Wenn Sie WordPress das Yoast SEO-Plugin verwenden, sehen Sie im Admin-Fenster einen Abschnitt zum Erstellen einer robots.txt-Datei.
Melden Sie sich im Backend Ihrer WordPress-Website an und greifen Sie auf Tools zu unter SEO Abschnitt und klicken Sie dann auf Dateieditor .
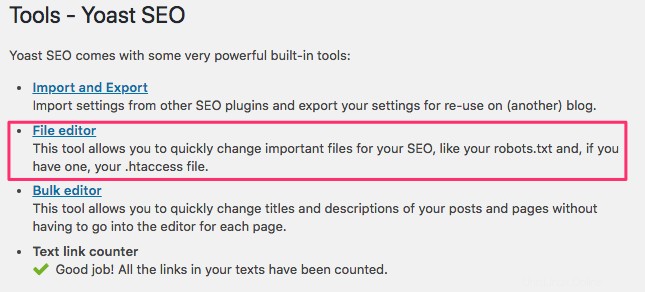
Folgen Sie der gleichen Reihenfolge wie zuvor, um Ihre Benutzeragenten und Regeln einzurichten. Unten haben wir Webcrawler aus den WordPress-Verzeichnissen wp-admin und wp-includes blockiert, während Benutzer und Bots weiterhin andere Seiten der Website sehen können. Wenn Sie fertig sind, klicken Sie auf Änderungen an robots.txt speichern um die robots.txt-Datei zu aktivieren.