Bevor wir einen ausführlichen Rundgang durch diesen Artikelleitfaden machen, müssen wir zunächst verstehen, was der Artikel aufzudecken versucht. Wir müssen die Frage „Warum ist es wichtig, Dateien in Linux zu zählen verstehen oder beantworten? ’. Es ist das Bestreben jedes Linux-Administrators, mit den Besonderheiten seiner Betriebssystemarchitektur vertraut zu sein.
Daher ist es ebenso wichtig, den Speicherort und die Anzahl der Verzeichnisdateien zu kennen, die Sie verwalten/verwalten müssen. In diesem Fall haben Sie möglicherweise Tausende von manuell oder automatisch generierten Dateien von Systembenutzern oder Programmen und möchten deren zunehmende oder endliche Anzahl verfolgen.
Es gibt mehrere eingebaute Linux-basierte Befehle, die Ihnen in solchen Fällen leicht helfen können. Wenn wir jedoch nach dem schnellsten Mittel suchen, um das Ziel dieses Artikels zu erreichen, müssen wir wählerisch sein und andere praktikable Optionen berücksichtigen.
Schneller Weg zum rekursiven Zählen von Dateien in Linux
Nur wenige Linux-Befehle zeichnen sich dadurch aus, dass sie Dateien rekursiv und schnell zählen. Lassen Sie uns die beiden beliebtesten vergleichen.
Linux-Suchbefehl versus Suchbefehl
Zu Demonstrationszwecken zielen wir auf die Anzahl der Dateien in /home/user ab Verzeichnis des Linux-Betriebssystems.
Um den Geschwindigkeitsunterschied zwischen dem find-Befehl und dem locate-Befehl zu ermitteln, verknüpfen wir ihre Ausführung mit der eingebauten Zeit von Linux Befehl, damit wir herausfinden können, welcher Ansatz des rekursiven Zählens von Dateien schneller ist.
Da der Suchbefehl bereits auf Ihrem Linux-System vorinstalliert ist, müssen wir nur noch locate installieren Befehl, bevor wir ihren Vergleich der Ausführungsgeschwindigkeit einleiten.
$ sudo apt-get install mlocate [On Debian, Ubuntu and Mint] $ sudo yum install mlocate [On RHEL/CentOS/Fedora and Rocky Linux/AlmaLinux] $ sudo emerge -a sys-apps/mlocate [On Gentoo Linux] $ sudo pacman -S mlocate [On Arch Linux] $ sudo zypper install mlocate [On OpenSUSE]
In Bezug auf diesen Artikelleitfaden ist die Hauptdatei locate Befehl [OPTION] uns interessiert ist -c , -count da wir nach einer Standardausgabe suchen, die eine abgefragte Anzahl von Dateizählern widerspiegelt.
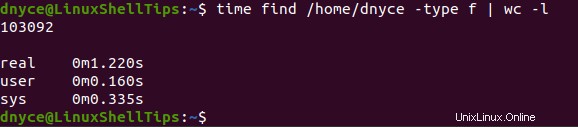
Lassen Sie uns zuerst den find-Befehl verwenden um die Anzahl der Dateien in /home/user zu zählen Verzeichnis. Ihr Befehl sollte in etwa so aussehen:
$ time find /home/dnyce -type f | wc -l
Lassen Sie uns zweitens sehen, was zu locate führt Der Befehl ergibt für das Zählen von Dateien in demselben /home/user Verzeichnis. Seine Befehlsimplementierung ist wie folgt:
$ time locate -c /home/dnyce
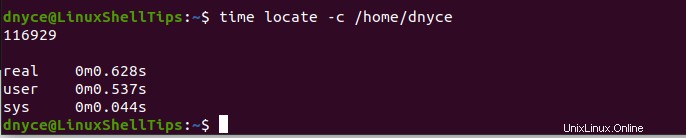
Mit der Zeit Befehl, der die Ausführungszeit dieser beiden Befehle verfolgt (find und lokalisieren ), können wir feststellen, dass die locate Der Befehl hat rekursiv tiefer gegraben, um mehr Dateien in kürzerer Zeit zu zählen.
Um die Linux-Datei locate zu verwenden Befehl, müssen Sie sich an folgende Syntaxregel halten:
$ locate [OPTION]… [PATTERN]…
Indem Sie den Ort überprüfen Befehlsseite ($ man locate) , werden Sie auch feststellen, dass dieser Befehl auch für andere brauchbare dateibezogene Funktionalitäten verwendet werden kann.
Auch wenn wir einen weiteren beliebten Befehl (ls-Befehl) zum Zählen von Dateien in einem Zielverzeichnis einführen, wird er nicht rekursiv tiefer und schneller auf die Ebene von locate gelangen Befehl.
$ time ls /home/dnyce | wc -l
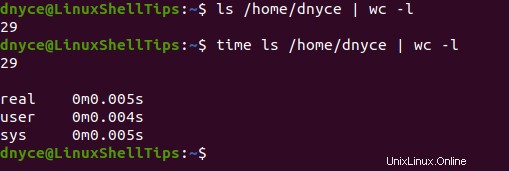
Der Ort Der Befehl ist schneller als find Befehl, weil sein Dateizählalgorithmus datenbankorientiert und nicht dateisystemorientiert ist wie sein Gegenstück.
Das standardmäßige Funktionsverhalten von locate Der Befehl besteht darin, die Existenz der abgefragten Datei(en) außerhalb der Reichweite der Datenbank zu ignorieren. Außerdem wird nach einer letzten erfolgreichen Datenbankaktualisierung für vorhandene Dateien die Datei locate Befehl meldet nicht sofort die Erstellung neuer Dateien.