Dieser Artikel befasst sich mit dem Mount Namespace und ist der dritte in der Linux-Namespace-Reihe. Im ersten Artikel habe ich eine Einführung in die sieben am häufigsten verwendeten Namensräume gegeben und damit die Grundlage für die praktische Arbeit gelegt, die im Artikel über Benutzernamensräume begonnen wurde. Mein Ziel ist es, grundlegende Kenntnisse darüber aufzubauen, wie die Grundlagen von Linux-Containern funktionieren. Wenn Sie daran interessiert sind, wie Linux die Ressourcen auf einem System steuert, sehen Sie sich die CGroup-Serie an, die ich zuvor geschrieben habe. Wenn Sie mit der praktischen Arbeit an den Namespaces fertig sind, kann ich hoffentlich CGroups und Namespaces auf sinnvolle Weise miteinander verknüpfen und das Bild für Sie vervollständigen.
Im Moment untersucht dieser Artikel jedoch den Mount-Namespace und wie er Ihnen dabei helfen kann, die Isolation besser zu verstehen, die Linux-Container für Systemadministratoren und damit auch für Plattformen wie OpenShift und Kubernetes mit sich bringen.
[Das könnte Ihnen auch gefallen: Zusätzliche Gruppen mit Podman-Containern teilen]
Der Mount-Namespace
Der Mount-Namespace verhält sich nach dem Erstellen eines neuen Benutzer-Namespace nicht wie erwartet. Standardmäßig, wenn Sie einen neuen Mount-Namespace mit unshare -m erstellen würden , würde Ihre Sicht auf das System weitgehend unverändert und uneingeschränkt bleiben. Das liegt daran, dass jedes Mal, wenn Sie einen neuen Mount-Namespace erstellen, eine Kopie der Einhängepunkte aus dem übergeordneten Namensraum wird im neuen Einhänge-Namensraum erstellt. Das bedeutet, dass jede Aktion, die an Dateien in einem schlecht konfigurierten Mount-Namespace durchgeführt wird, erfolgt Auswirkungen auf den Host.
Einige Setup-Schritte für Mount-Namespaces
Was nützt dann der Mount-Namespace? Um dies zu demonstrieren, verwende ich einen Alpine-Linux-Tarball.
Zusammenfassend:Laden Sie es herunter, entpacken Sie es und verschieben Sie es in ein neues Verzeichnis, wobei Sie dem Verzeichnis der obersten Ebene Berechtigungen für einen nicht privilegierten Benutzer erteilen:
[root@localhost ~] export CONTAINER_ROOT_FOLDER=/container_practice
[root@localhost ~] mkdir -p ${CONTAINER_ROOT_FOLDER}/fakeroot
[root@localhost ~] cd ${CONTAINER_ROOT_FOLDER}
[root@localhost ~] wget https://dl-cdn.alpinelinux.org/alpine/v3.13/releases/x86_64/alpine-minirootfs-3.13.1-x86_64.tar.gz
[root@localhost ~] tar xvf alpine-minirootfs-3.13.1-x86_64.tar.gz -C fakeroot
[root@localhost ~] chown container-user. -R ${CONTAINER_ROOT_FOLDER}/fakeroot
Die fakeroot Verzeichnis muss dem Benutzer container-user gehören Denn sobald Sie einen neuen Benutzernamensraum erstellt haben, wird der Root Der Benutzer im neuen Namespace wird dem Container-Benutzer zugeordnet außerhalb des Namensraums. Dies bedeutet, dass ein Prozess innerhalb des neuen Namespace davon ausgeht, dass er über die erforderlichen Fähigkeiten verfügt, um seine Dateien zu ändern. Dennoch verhindern die Dateisystemberechtigungen des Hosts den Container-Benutzer Konto daran hindert, die Alpine-Dateien aus dem Tarball zu ändern (die root haben als Besitzer).
Was passiert also, wenn Sie einfach einen neuen Mount-Namensraum beginnen?
PS1='\u@new-mnt$ ' unshare -Umr Jetzt, da Sie sich im neuen Namespace befinden, erwarten Sie möglicherweise nicht, einen der ursprünglichen Einhängepunkte des Hosts zu sehen. Dies ist jedoch nicht der Fall:
root@new-mnt$ df -h
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/cs-root 36G 5.2G 31G 15% /
tmpfs 737M 0 737M 0% /sys/fs/cgroup
devtmpfs 720M 0 720M 0% /dev
tmpfs 737M 0 737M 0% /dev/shm
tmpfs 737M 8.6M 728M 2% /run
tmpfs 148M 0 148M 0% /run/user/0
/dev/vda1 976M 197M 713M 22% /boot
root@new-mnt$ ls /
bin container_practice etc lib media opt root sbin sys usr
boot dev home lib64 mnt proc run srv tmp var
Der Grund dafür ist, dass systemd standardmäßig die rekursive gemeinsame Nutzung der Einhängepunkte mit allen neuen Namespaces. Wenn Sie ein tmpfs gemountet haben irgendwo im Dateisystem, zum Beispiel /mnt innerhalb des neuen Mount-Namensraums, kann der Host ihn sehen?
root@new-mnt$ mount -t tmpfs tmpfs /mnt
root@new-mnt$ findmnt |grep mnt
└─/mnt tmpfs tmpfs rw,relatime,seclabel,uid=1000,gid=1000 Der Host sieht dies jedoch nicht:
[root@localhost ~]# findmnt |grep mnt Sie wissen also zumindest, dass der Mount-Namespace ordnungsgemäß funktioniert. Dies ist ein guter Zeitpunkt, um einen kleinen Umweg zu machen, um die Ausbreitung von Einhängepunkten zu diskutieren. Ich fasse kurz zusammen, aber wenn Sie an einem besseren Verständnis interessiert sind, werfen Sie einen Blick auf den LWN-Artikel von Michael Kerrisk sowie die Manpage für den Mount-Namespace. Normalerweise verlasse ich mich nicht so sehr auf die Manpages, da ich oft finde, dass sie nicht leicht verdaulich sind. In diesem Fall sind sie jedoch voller Beispiele und (meistens) in einfachem Englisch.
Theorie der Einhängepunkte
Mounts werden standardmäßig aufgrund einer Funktion im Kernel weitergegeben, die als gemeinsam genutzter Unterbaum bezeichnet wird . Dadurch kann jedem Einhängepunkt ein eigener Ausbreitungstyp zugeordnet werden. Diese Metadaten bestimmen, ob neue Bereitstellungen unter einem bestimmten Pfad an andere Bereitstellungspunkte weitergegeben werden. Das in der Manpage angegebene Beispiel ist das einer optischen Platte. Wenn Ihr optisches Laufwerk automatisch unter /cdrom gemountet wird , wären die Inhalte in anderen Namespaces nur sichtbar, wenn der entsprechende Propagationstyp eingestellt ist.
Peer-Gruppen und Mount-Status
Die Kernel-Dokumentation sagt, dass eine "Peer-Gruppe ist definiert als eine Gruppe von vfsmounts, die Ereignisse aneinander weitergeben.“ Ereignisse sind Dinge wie das Mounten einer Netzwerkfreigabe oder das Unmounten eines optischen Geräts. Warum ist das wichtig, fragen Sie? Nun, wenn es um den Mount-Namespace geht, Peer-Gruppen sind oft der entscheidende Faktor, ob ein Reittier sichtbar ist und mit ihm interagiert werden kann oder nicht. Ein mount state bestimmt, ob ein Mitglied in einer Peer-Gruppe das Ereignis empfangen kann. Gemäß derselben Kernel-Dokumentation gibt es fünf Mount-Zustände:
- geteilt - Ein Mount, das zu einer Peer-Gruppe gehört. Alle auftretenden Änderungen werden durch alle Mitglieder der Peer-Gruppe weitergegeben.
- Sklave - Ausbreitung in eine Richtung. Der Master-Einhängepunkt gibt Ereignisse an einen Slave weiter, aber der Master sieht keine Aktionen, die der Slave ausführt.
- geteilt und Sklave - Gibt an, dass der Einhängepunkt einen Master, aber auch eine eigene Peer-Gruppe hat. Der Master wird nicht über Änderungen an einem Einhängepunkt benachrichtigt, aber alle Peer-Gruppenmitglieder nachgelagert werden es tun.
- privat - Empfängt oder leitet keine Ausbreitungsereignisse weiter.
- unbindbar - Empfängt oder leitet keine Ausbreitungsereignisse weiter und kann nicht eingebunden werden.
Es ist wichtig zu beachten, dass der Mount-Punkt-Status pro Mount-Punkt ist . Das bedeutet, wenn Sie / haben und /boot , müssten Sie beispielsweise den gewünschten Status separat auf jeden Einhängepunkt anwenden.
Falls Sie sich über Container wundern:Die meisten Container-Engines verwenden private Ladezustände, wenn sie ein Volume in einem Container bereitstellen. Mach dir jetzt nicht zu viele Gedanken darüber. Ich möchte nur etwas Kontext bieten. Wenn Sie einige spezifische Montageszenarien ausprobieren möchten, schauen Sie sich die Manpages an, da die Beispiele recht gut sind.
Erstellen unseres Mount-Namensraums
Wenn Sie eine Programmiersprache wie Go oder C verwenden, können Sie die Kernel-Aufrufe des Rohsystems verwenden, um die geeignete Umgebung für Ihre neuen Namespaces zu erstellen. Da die Absicht dahinter jedoch darin besteht, Ihnen zu helfen, zu verstehen, wie Sie mit einem bereits vorhandenen Container interagieren, müssen Sie einige Bash-Tricks anwenden, um Ihren neuen Mount-Namespace in den gewünschten Zustand zu bringen.
Erstellen Sie zuerst den neuen Mount-Namespace als normaler Benutzer:
unshare -Urm
Sobald Sie sich im Namensraum befinden, sehen Sie sich findmnt an des Mapper-Geräts, das das Root-Dateisystem enthält (der Kürze halber habe ich die meisten Mount-Optionen aus der Ausgabe entfernt):
findmnt |grep mapper
/ /dev/mapper/cs-root xfs rw,relatime,[...] Es gibt nur einen Einhängepunkt, der den Root-Device-Mapper hat. Dies ist wichtig, da Sie unter anderem das Mapper-Gerät in das Alpine-Verzeichnis einbinden müssen:
export CONTAINER_ROOT_FOLDER=/container_practice
mount --bind ${CONTAINER_ROOT_FOLDER}/fakeroot ${CONTAINER_ROOT_FOLDER}/fakeroot
cd ${CONTAINER_ROOT_FOLDER}/fakeroot
Dies liegt daran, dass Sie ein Dienstprogramm namens pivot_root verwenden um ein chroot auszuführen -ähnliche Aktion. pivot_root nimmt zwei Argumente:new_root und old_root (manchmal auch als put_old bezeichnet ). pivot_root verschiebt das Root-Dateisystem des aktuellen Prozesses in das Verzeichnis put_old und macht new_root das neue Root-Dateisystem.
WICHTIG :Eine Anmerkung zu chroot . chroot wird oft mit zusätzlichen Sicherheitsvorteilen gerechnet. Bis zu einem gewissen Grad stimmt dies, da es einer größeren Menge an Fachwissen bedarf, um sich davon zu befreien. Eine sorgfältig aufgebaute chroot kann sehr sicher sein. Allerdings chroot ändert oder schränkt die Linux-Fähigkeiten, die ich im vorherigen Namespace-Artikel angesprochen habe, nicht ein. Es beschränkt auch nicht die Systemaufrufe auf den Kernel. Das bedeutet, dass ein ausreichend erfahrener Angreifer möglicherweise einer chroot entkommen könnte das ist nicht gut durchdacht. Die Mount- und User-Namespaces helfen, dieses Problem zu lösen.
Wenn Sie pivot_root verwenden ohne das Bind-Mount antwortet der Befehl mit:
pivot_root: failed to change root from `.' to `old_root/': Invalid argument
Um zum Alpine-Root-Dateisystem zu wechseln, erstellen Sie zuerst ein Verzeichnis für old_root und dann in das beabsichtigte (alpine) Root-Dateisystem schwenken. Da das Root-Dateisystem von Alpine Linux keine symbolischen Links für /bin hat und /sbin , müssen Sie diese zu Ihrem Pfad hinzufügen und dann schließlich old_root aushängen :
mkdir old_root
pivot_root . old_root
PATH=/bin:/sbin:$PATH
umount -l /old_root
Sie haben jetzt eine schöne Umgebung, in der der Benutzer und einhängen Namespaces arbeiten zusammen, um eine Isolationsebene vom Host bereitzustellen. Sie haben keinen Zugriff mehr auf Binärdateien auf dem Host. Versuchen Sie, findmnt auszugeben zuvor verwendeten Befehl:
root@new-mnt$ findmnt
-bash: findmnt: command not found Sie können sich auch das Root-Dateisystem ansehen oder versuchen zu sehen, was gemountet ist:
root@new-mnt$ ls -l /
total 12
drwxr-xr-x 2 root root 4096 Jan 28 21:51 bin
drwxr-xr-x 2 root root 18 Feb 17 22:53 dev
drwxr-xr-x 15 root root 4096 Jan 28 21:51 etc
drwxr-xr-x 2 root root 6 Jan 28 21:51 home
drwxr-xr-x 7 root root 247 Jan 28 21:51 lib
drwxr-xr-x 5 root root 44 Jan 28 21:51 media
drwxr-xr-x 2 root root 6 Jan 28 21:51 mnt
drwxrwxr-x 2 root root 6 Feb 17 23:09 old_root
drwxr-xr-x 2 root root 6 Jan 28 21:51 opt
drwxr-xr-x 2 root root 6 Jan 28 21:51 proc
drwxr-xr-x 2 root root 6 Feb 17 22:53 put_old
drwx------ 2 root root 27 Feb 17 22:53 root
drwxr-xr-x 2 root root 6 Jan 28 21:51 run
drwxr-xr-x 2 root root 4096 Jan 28 21:51 sbin
drwxr-xr-x 2 root root 6 Jan 28 21:51 srv
drwxr-xr-x 2 root root 6 Jan 28 21:51 sys
drwxrwxrwt 2 root root 6 Feb 19 16:38 tmp
drwxr-xr-x 7 root root 66 Jan 28 21:51 usr
drwxr-xr-x 12 root root 137 Jan 28 21:51 var
root@new-mnt$ mount
mount: no /proc/mounts
Interessanterweise gibt es kein proc Dateisystem standardmäßig gemountet. Versuchen Sie es zu mounten:
root@new-mnt$ mount -t proc proc /proc
mount: permission denied (are you root?)
root@new-mnt$ whoami
root
Denn proc ist ein spezieller Mount-Typ, der sich auf den PID-Namespace bezieht. Sie können ihn nicht mounten, obwohl Sie sich in Ihrem eigenen Mount-Namespace befinden. Dies geht zurück auf die Capability-Vererbung, die ich zuvor besprochen habe. Ich werde diese Diskussion im nächsten Artikel aufgreifen, wenn ich den PID-Namespace behandle. Zur Erinnerung an die Vererbung werfen Sie jedoch einen Blick auf das folgende Diagramm:
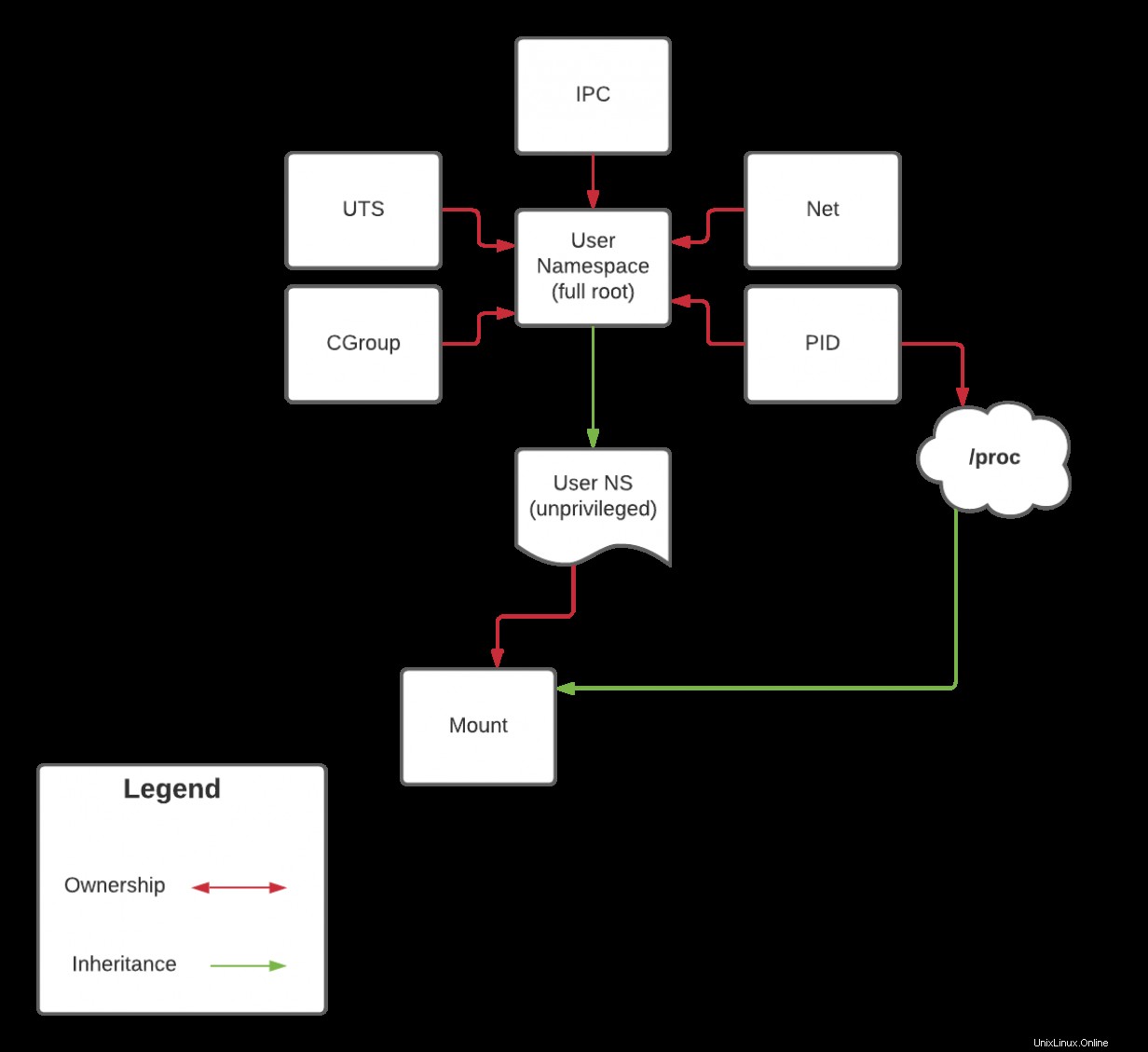
Im nächsten Artikel werde ich dieses Diagramm noch einmal aufwärmen, aber wenn Sie es von Anfang an verfolgt haben, sollten Sie schon vorher einige Schlussfolgerungen ziehen können.
[ Das API-Eigentümerhandbuch:7 Best Practices effektiver API-Programme ]
Abschluss
In diesem Artikel habe ich eine tiefere Theorie rund um den Mount-Namensraum behandelt. Ich habe Peer-Gruppen besprochen und wie sie sich auf die Mount-Zustände beziehen, die auf jeden Mount-Punkt auf einem System angewendet werden. Für den praktischen Teil haben Sie ein minimales Alpine-Linux-Dateisystem heruntergeladen und sind dann durchgegangen, wie Sie die Benutzer- und Mount-Namespaces verwenden, um eine Umgebung zu erstellen, die sehr nach chroot aussieht außer potenziell sicherer.
Testen Sie vorerst das Mounten von Dateisystemen innerhalb und außerhalb Ihres neuen Namespace. Versuchen Sie, neue Bereitstellungspunkte zu erstellen, die shared verwenden , privat , und Sklave Mount-Zustände. Im nächsten Artikel werde ich den PID-Namespace verwenden, um den primitiven Container weiter aufzubauen, um Zugriff auf den proc zu erhalten Dateisystem und Prozessisolierung.