Vor nicht allzu langer Zeit habe ich einen Artikel geschrieben, der einen Überblick über die gängigsten Namespaces gibt. Es ist großartig, diese Informationen zu haben, und ich bin sicher, dass Sie bis zu einem gewissen Grad extrapolieren können, wie Sie dieses Wissen sinnvoll einsetzen können. Es ist normalerweise nicht meine Art, die Dinge so offen zu lassen. In den nächsten paar Artikeln verbringe ich also etwas Zeit damit, einige der wichtigeren Namespaces durch die Linse der Erstellung eines primitiven Linux-Containers zu demonstrieren. In gewissem Sinne schreibe ich hier meine Erfahrungen mit den Techniken auf, die ich bei der Fehlerbehebung eines Linux-Containers auf einer Client-Site verwende. Vor diesem Hintergrund beginne ich mit dem Fundament eines jeden Containers, insbesondere wenn es um Sicherheit geht.
Ein wenig über Linux-Fähigkeiten
Sicherheit auf einem Linux-System kann viele Formen annehmen. Für die Zwecke dieses Artikels befasse ich mich hauptsächlich mit der Sicherheit, wenn es um Dateiberechtigungen geht. Zur Erinnerung:Alles auf einem Linux-System ist eine Art Datei, und daher sind Dateiberechtigungen die erste Verteidigungslinie gegen eine Anwendung, die sich möglicherweise falsch verhält.
Die primäre Art und Weise, wie Linux Dateiberechtigungen handhabt, ist die Implementierung von Benutzern . Es gibt normale Benutzer für die Linux die Berechtigungsprüfung anwendet, und es gibt den Superuser das die meisten (wenn nicht alle) Prüfungen umgeht. Kurz gesagt, das ursprüngliche Linux-Modell war alles oder nichts.
Um dies zu umgehen, haben einige Programmbinärdateien die set uid Bit auf sie gesetzt. Mit dieser Einstellung kann das Programm als der Benutzer ausgeführt werden, der die Binärdatei besitzt. Das passwd Dienstprogramm ist ein gutes Beispiel dafür. Jeder Benutzer kann dieses Dienstprogramm auf dem System ausführen. Es muss erhöhte Berechtigungen auf dem System haben, um mit dem shadow zu interagieren -Datei, die die Hashes für Benutzerkennwörter auf einem Linux-System speichert. Während die passwd Binary hat eingebaute Überprüfungen, um sicherzustellen, dass ein normaler Benutzer das Passwort eines anderen Benutzers nicht ändern kann, viele Anwendungen haben nicht die gleiche Prüfungsebene, besonders wenn der Systemadministrator set uid aktiviert hat bisschen.
Linux Fähigkeiten wurden erstellt, um eine granularere Anwendung des Sicherheitsmodells bereitzustellen. Anstatt die Binärdatei als root auszuführen, können Sie nur die spezifischen Fähigkeiten anwenden, die eine Anwendung benötigt, um effektiv zu sein. Ab Linux Kernel 5.1 gibt es 38 Fähigkeiten. Die Manpages für die Fähigkeiten sind eigentlich recht gut geschrieben und beschreiben jede Fähigkeit.
Ein Fähigkeitssatz ist die Art und Weise, in der Threads Fähigkeiten zugewiesen werden können. Kurz gesagt, es gibt insgesamt fünf Fähigkeitsgruppen, aber für diese Diskussion sind nur zwei davon relevant:Effektiv und Zulässig.
Wirksam :Der Kernel überprüft jede privilegierte Aktion und entscheidet, ob ein Systemaufruf zugelassen oder nicht zugelassen wird. Wenn ein Thread oder eine Datei das effektive hat Fähigkeit, dürfen Sie die Aktion ausführen, die sich auf die effektive Fähigkeit bezieht.
Erlaubt :Erlaubte Fähigkeiten sind noch nicht aktiv. Allerdings, wenn ein Prozess zugelassen wurde Fähigkeiten, bedeutet dies, dass der Prozess selbst entscheiden kann, sein Privileg in ein effektives Privileg zu eskalieren.
Um zu sehen, welche Fähigkeiten ein bestimmter Prozess haben kann, können Sie getpcaps ${PID} ausführen Befehl. Die Ausgabe dieses Befehls sieht je nach Linux-Distribution unterschiedlich aus. Unter RHEL/CentOS erhalten Sie eine vollständige Liste der Funktionen:
[root@CentOS8 ~]# getpcaps $$
Capabilities for `1304': = cap_chown,cap_dac_override,cap_dac_read_search,cap_fowner,cap_fsetid,cap_kill,cap_setgid,cap_setuid,cap_setpcap,cap_linux_immutable,cap_net_bind_service,cap_net_broadcast,cap_net_admin,cap_net_raw,cap_ipc_lock,cap_ipc_owner,cap_sys_module,cap_sys_rawio,cap_sys_chroot,cap_sys_ptrace,cap_sys_pacct,cap_sys_admin,cap_sys_boot,cap_sys_nice,cap_sys_resource,cap_sys_time,cap_sys_tty_config,cap_mknod,cap_lease,cap_audit_write,cap_audit_control,cap_setfcap,cap_mac_override,cap_mac_admin,cap_syslog,cap_wake_alarm,cap_block_suspend,cap_audit_read,38,39+ep
Wenn Sie den Befehl man 7 capabilities ausführen , finden Sie eine Auflistung aller dieser Funktionen zusammen mit einer Beschreibung für jede. In einigen Distributionen wie Ubuntu oder Arch führt die Ausführung desselben Befehls einfach zu folgendem:
[root@Arch ~]# getpcaps $$
414429: =ep Vor dem = steht ein Leerzeichen Schild. Dieser Leerraum ist mit dem Schlüsselwort all austauschbar . Wie Sie vielleicht erraten haben, bedeutet dies, dass alle auf dem System verfügbaren Funktionen sowohl in E gewährt werden effektiv und P freigegebene Fähigkeitssätze.
Warum ist das wichtig? Zunächst einmal sind Capability Sets an einen Benutzernamensraum gebunden (den ich weiter unten bespreche). Für den Moment bedeutet dies, dass jeder Namespace seine eigenen Fähigkeiten hat, die nur für seinen eigenen gelten Namensraum. Angenommen, Sie haben einen Namespace namens constrained . Es ist möglich, dass eingeschränkt aussehen als ob es alle richtigen Fähigkeiten hätte, wie sie bei getpcaps zu sehen sind Befehl. Wenn jedoch eingeschränkt wurde von einem Prozess und einem Namespace erstellt, der nicht über einen vollständigen Funktionssatz verfügte (z. B. ein normaler Benutzer), eingeschränkt auf einem System können nicht mehr Berechtigungen erteilt werden als dem Erstellungsprozess.
Zusammenfassend lässt sich sagen, dass Fähigkeiten, obwohl sie keine Namensraumtechnologie sind, Hand in Hand arbeiten, um zu bestimmen, was und wie Prozesse innerhalb eines Namensraums funktionieren können.
[Vielleicht gefällt Ihnen auch: Podman ohne Rootberechtigung als Nicht-Root-Benutzer ausführen]
Der Benutzernamensraum
Bevor Sie sich mit der Erstellung eines Nutzer-Namespace befassen, hier eine kurze Zusammenfassung des Zwecks dieses Namespace. Wie ich in einem früheren Artikel besprochen habe, sind Benutzernamen und letztendlich die Benutzeridentifikationsnummer (UID) eine der Sicherheitsebenen, die ein System verwendet, um sicherzustellen, dass Personen und Prozesse nicht auf Dinge zugreifen, zu denen sie nicht berechtigt sind.
Theorie hinter dem Benutzernamensraum
Der Benutzernamensraum ist eine Möglichkeit für einen Container (eine Reihe von isolierten Prozessen), einen anderen Satz von Berechtigungen als das System selbst zu haben. Jeder Container erbt seine Berechtigungen von dem Benutzer, der den neuen Benutzernamensraum erstellt hat. Beispielsweise beginnen in den meisten Linux-Systemen normale Benutzer-IDs bei oder über 1000. Im Rest dieser Serie verwende ich einen Benutzer namens container-user , die die folgenden IDs hat (SELinux-Kontexte werden für diese Demos weggelassen):
uid=1000(container-user) gid=1000(container-user) groups=1000(container-user) Es ist wichtig zu beachten, dass theoretisch jeder Benutzer einen neuen Benutzernamensraum erstellen kann, es sei denn, der Systemadministrator hat dies absichtlich eingeschränkt. Dies bietet jedoch keine Verschleierung durch Administratoren auf dem System selbst. Benutzernamensräume sind eine Hierarchie. Betrachten Sie das folgende Diagramm:
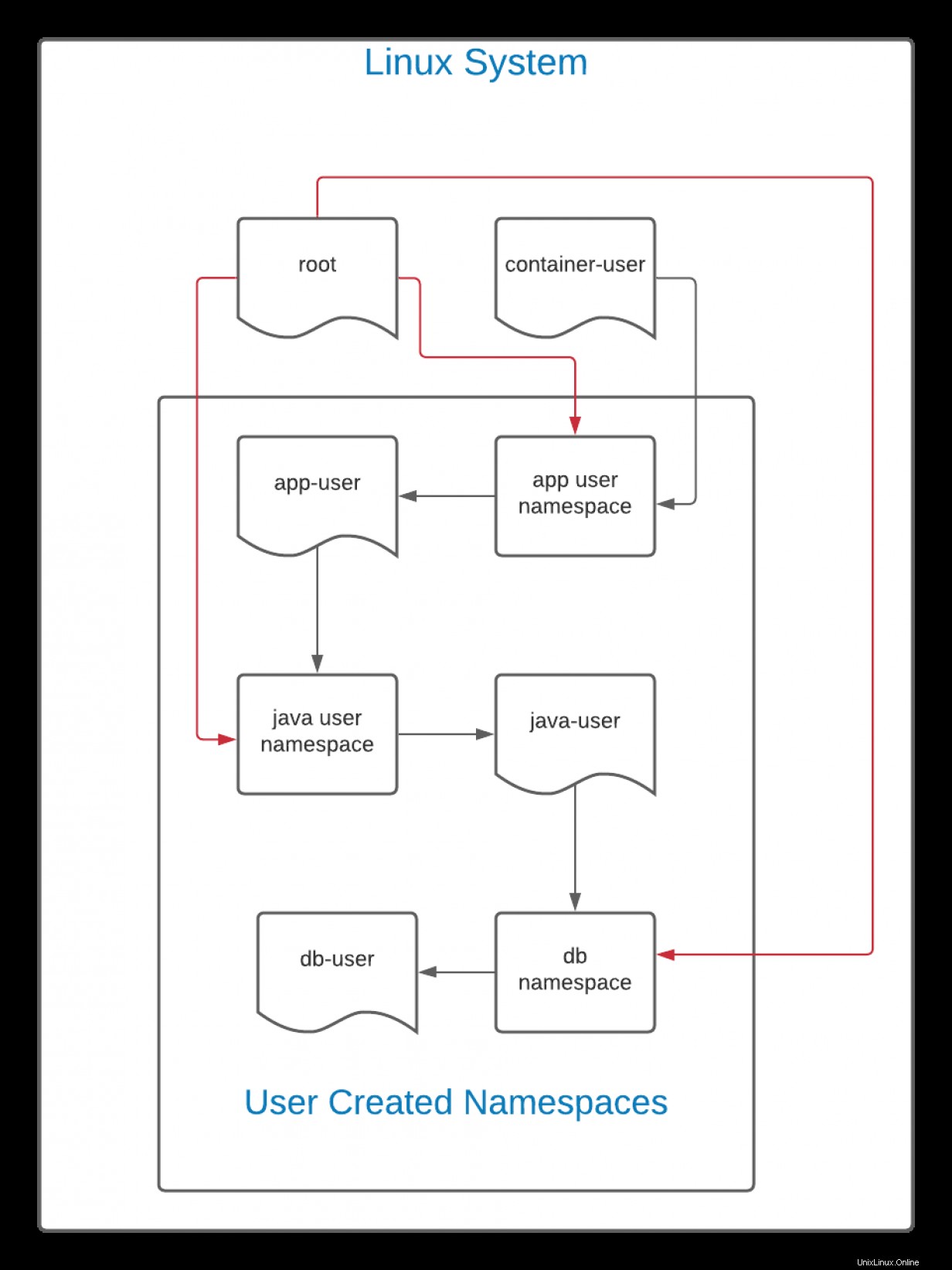
In diesem Diagramm zeigen die schwarzen Linien den Schöpfungsfluss an. Der Benutzer container-user erstellt einen Namespace für einen Benutzer namens app-user . Theoretisch wäre dies ein Web-Frontend oder eine andere Anwendung. Als nächstes App-Nutzer erstellt einen Benutzernamensraum für java-user . In diesem Namespace java-user erstellt einen Namespace für db-user .
Da dies eine Hierarchie ist, container-user kann alle Dateien sehen und darauf zugreifen, die von einem der Namespaces erstellt wurden, die von seiner UID erzeugt wurden. Ebenso, weil die root Benutzer auf dem Linux-System können alle sehen und mit ihnen interagieren Dateien auf einem System, einschließlich der von container-user erstellten , der Stamm Benutzer (dargestellt durch die rote Linie) kann vollständige Autorität über alle Namespaces haben.
Das Gegenteil ist jedoch nicht der Fall. Der db-user Der Benutzer kann in diesem Fall nichts darüber sehen oder damit interagieren. Wenn die ID-Zuordnung unverändert bleibt (die Standardrichtlinie), app-user , Java-Benutzer und db-user alle haben die gleiche UID. Obwohl sie dieselbe UID haben, db-user kann nicht mit java-user interagieren , die nicht mit app-user interagieren kann , und so weiter.
Alle Berechtigungen, die in einem Benutzernamensraum gewährt werden, gelten nur in seinem eigenen Namensraum und möglicherweise darunter liegenden Namensräumen.
Hands-on mit Benutzernamensräumen
Um einen neuen Benutzernamensraum zu erstellen, verwenden Sie einfach das unshare -U Befehl:
[container-user@localhost ~]$ PS1='\u@app-user$ ' unshare -U
nobody@app-user$ Der obige Befehl enthält eine PS1 -Variable, die einfach die Shell ändert, damit man leichter feststellen kann, in welchem Namensraum die Shell aktiv ist. Interessanterweise werden Sie feststellen, dass der Benutzer niemand ist :
nobody@app-user$ whoami
nobody
nobody@app-user$ id
uid=65534(nobody) gid=65534(nobody) groups=65534(nobody) Dies liegt daran, dass standardmäßig keine Benutzer-ID-Zuordnung stattfindet. Wenn keine Zuordnung definiert ist, verwendet der Namensraum einfach die Regeln Ihres Systems, um zu bestimmen, wie mit einem nicht definierten Benutzer umzugehen ist.
Wenn Sie den Namensraum jedoch wie folgt erstellen:
PS1='\u@app-user$ ' unshare -Ur Die Zuordnung wird automatisch für Sie erstellt:
root@app-user$ cat /proc/$$/uid_map
0 1000 1 Diese Datei stellt Folgendes dar:
ID-inside-ns ID-outside-ns range Der Bereich Der Wert stellt die Anzahl der zuzuordnenden Benutzer dar. Zum Beispiel, wenn dies 0 1000 4 wäre , die Zuordnung wäre so
0 1000
1 1001
2 1002
3 1003 Und so weiter. Meistens interessiert Sie nur die Wurzel Benutzerzuordnung, aber die Option ist auf Wunsch verfügbar. Was passiert, wenn Sie den Java-Benutzer erstellen Namensraum?
root@app-user$ PS1='\u@java-user$ ' unshare -Ur
root@java-user$ Wie erwartet ändert sich der Shell-Prompt und Sie sind der Root-Benutzer, aber wie sieht die UID-Zuordnung aus?
root@java-user$ cat /proc/$$/uid_map
0 0 1 Sie sehen jetzt, Sie haben eine 0 auf 0 Kartierung. Das liegt daran, dass der Benutzer, der den neuen Namespace instanziiert, für den ID-Mapping-Prozess verwendet wird. Seit du root warst im vorherigen Namespace hat der neue Namespace eine Zuordnung von root zu root . Da jedoch root im App-Benutzer Namespace hat kein root auf dem System auch nicht der neue Namespace root Benutzer.
Abgesehen von der einfachen Überprüfung der uid_map , können Sie auch von außerhalb des Namensraums überprüfen, ob sich zwei Prozesse im selben Namensraum befinden. Natürlich müssen Sie zuerst die PID des Prozesses finden, aber damit können Sie den folgenden Befehl ausführen:
readlink /proc/$PID/ns/user Um dies zu vereinfachen, habe ich Folgendes ausgeführt:
[container-user@localhost ~]$ PS1='\u@app-user$ ' unshare -Ur
root@app-user$ sleep 100000
In einem anderen Terminal habe ich die PID ausgegraben und den readlink verwendet Befehl auf dieser PID sowie der aktuellen Shell:
[root@localhost ~]# readlink /proc/1307/ns/user
user:[4026532275]
[root@localhost ~]# readlink /proc/$$/ns/user
user:[4026531837] Wie Sie sehen können, ist der Benutzerlink anders. Wenn sie im selben Namensraum arbeiten würden, würde es so aussehen:
[root@localhost ~]# readlink /proc/1424/ns/user
user:[4026532275]
[root@localhost ~]# readlink /proc/1307/ns/user
user:[4026532275] Der größte Vorteil des Benutzernamensraums ist die Möglichkeit, Container ohne Root-Rechte auszuführen. Darüber hinaus können Sie, je nachdem, wie Sie die UID-Zuordnung einrichten, vollständig vermeiden, dass ein Superuser in einem bestimmten Benutzernamensraum vorhanden ist. Das bedeutet, dass es nicht möglich ist, privilegierte Prozesse innerhalb dieser Art von Namespace auszuführen.
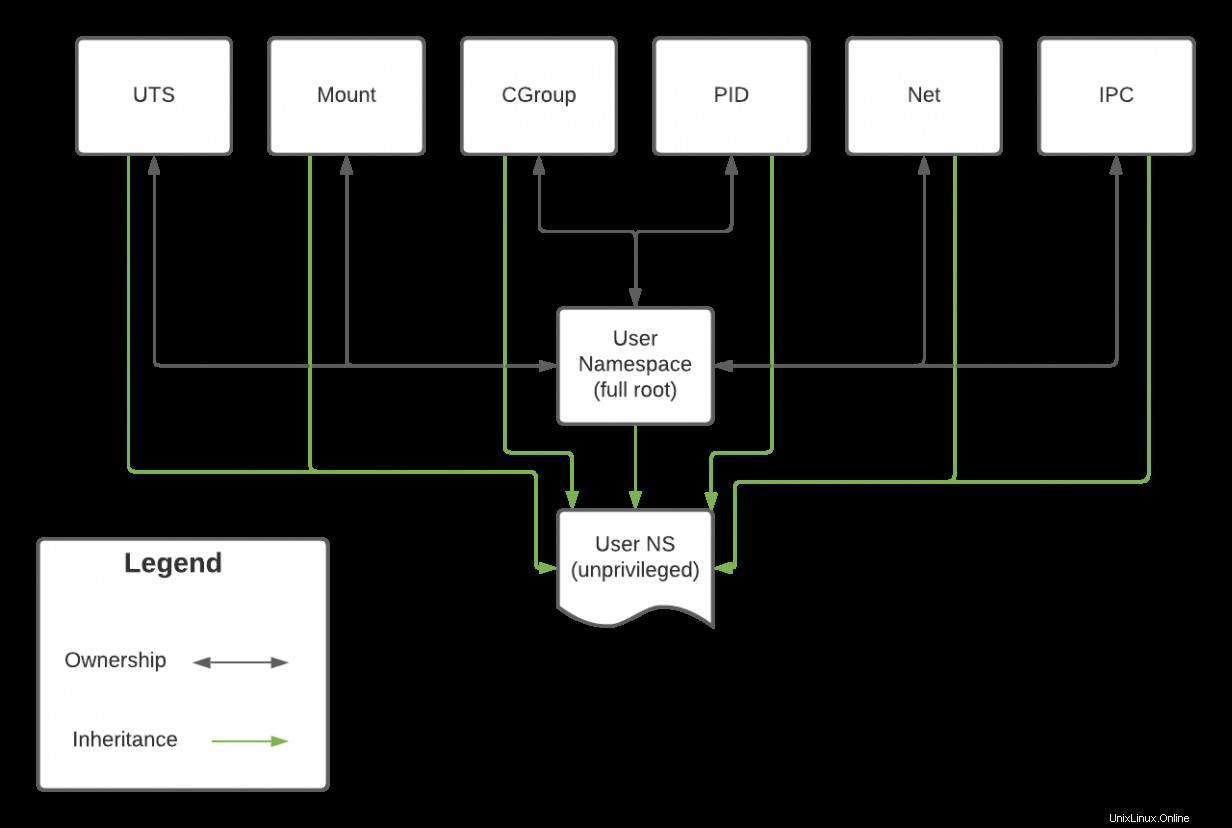
Hinweis :Der Benutzer Namespace regelt jeden Namespace. Das bedeutet, dass die Fähigkeiten eines Namensraums direkt mit den Fähigkeiten seines übergeordneten Benutzers zusammenhängen Namensraum.
Das ursprüngliche, vollständige Root Benutzernamespace besitzt alle Namespaces auf einem System im Diagramm unten. Diese Beziehung kann bidirektional sein. Wenn ein Prozess im Netz läuft Namespace läuft als root , kann es sich auf alle anderen Prozesse auswirken, die Root gehören Benutzernamensraum. Während das Erstellen eines unprivilegierten Benutzernamensraums diesem neuen Benutzernamensraum zwar den Zugriff auf Ressourcen in anderen Namensräumen ermöglicht, darf er diese jedoch nicht ändern, da er sie nicht besitzt. Während also ein Prozess im unprivilegierten Namensraum ping kann eine IP (die auf das Netz angewiesen ist Namespace), darf die Netzwerkkonfiguration des Hosts nicht geändert werden.
Viele Dinge außerhalb dessen, was Sie sich unter Linux-Containern vorstellen, verwenden Namespaces. Das Linux-Paketierungsformat Flatpak verwendet Benutzernamensräume sowie einige andere Technologien, um eine Anwendungs-Sandbox bereitzustellen. Flatpaks bündeln alle Bibliotheken einer Anwendung in derselben Paketverteilungsdatei. Dadurch kann ein Linux-Rechner die aktuellsten Anwendungen empfangen, ohne sich Gedanken darüber machen zu müssen, ob Sie die richtige Version von glibc haben installiert, z. Die Fähigkeit, diese in ihrem eigenen Benutzernamensraum zu haben, bedeutet, dass (theoretisch) ein fehlerhafter Prozess innerhalb des Flatpaks keine Dateien oder Prozesse außerhalb des Namensraums ändern (oder möglicherweise sogar darauf zugreifen) kann.
[ Erste Schritte mit Containern? Schauen Sie sich diesen kostenlosen Kurs an. Containerisierte Anwendungen bereitstellen:Eine technische Übersicht. ]
Abschluss
Die Verwendung von Benutzernamensräumen allein löst nicht das Problem, das Flatpak und andere zu lösen versuchen. Benutzer-Namespaces sind zwar ein integraler Bestandteil der Sicherheitsgeschichte und der Funktionen anderer Namespaces, bieten jedoch für sich genommen nicht viel. Bei der Erstellung neuer isolierter Namespaces gibt es einiges zu beachten. Im nächsten Artikel schaue ich mir die Verwendung des mount an Namespace in Verbindung mit dem Benutzer-Namespace, um eine chroot zu erstellen -ähnliche Umgebung mit Namespaces.
Wenn Sie nach einigen Herausforderungen suchen, um Ihr Verständnis zu festigen, versuchen Sie, eine Reihe von Benutzern dem neuen Namespace zuzuordnen. Was passiert, wenn Sie den gesamten Bereich einem Namespace zuordnen? Ist es möglich, Apache-Benutzer in einem nicht privilegierten Namespace zu werden? Was sind die Auswirkungen auf die Sicherheit beim Schreiben einer fehlerhaften uid_map Datei? (Hinweis :Sie müssen zwei Schalen öffnen; eine, um den neuen Namespace zu erstellen und darin zu leben, und die andere, um die uid_map zu schreiben und gid_map Dateien. Wenn Sie damit zu kämpfen haben, schreiben Sie mir eine Nachricht auf Twitter @linuxovens).