Erfahrene Systemadministratoren passen ihre Linux-Systeme normalerweise an ihre Bedürfnisse an und schaffen eine konsistente Umgebung. Aber was ist, wenn Sie in einer Umgebung arbeiten, in der Sie dies nicht tun? die Befugnis haben, dauerhafte Änderungen vorzunehmen? Oder Sie helfen jemandem aus einer anderen Abteilung? Manchmal läuft auf dem anderen Server eine andere "Variante" von Linux oder sogar eine andere Art von Unix.
Hier sind einige schnelle und schmutzige Tricks, die in einigen praktischen Situationen nützlich sein können.
[ Den Lesern gefiel auch: Weitere dumme Bash-Tricks:Variablen, Suchen, Dateideskriptoren und Remoteoperationen ]
Kennen Sie die Regeln und wissen Sie, wann Sie Regeln brechen müssen
Variablen sollten eindeutige Namen haben, damit sie leicht verständlich sind, selbstdokumentiert sind und unsere geistige Gesundheit erhalten. Ich nehme an, alle stimmen dem zu.
Aber manchmal müssen Sie mitten in der Nacht ein Produktionsproblem beheben und möchten schnell handeln .
Manchmal müssen Sie sich auch etwas Tipparbeit sparen, weil Sie wissen, dass Sie einige lange Befehle mehrmals ausführen müssen. In einer normalen Situation würden Sie Aliase erstellen und sie in Ihre Anmeldeprofile einfügen. Wir sprechen hier jedoch von einer ungewohnten Umgebung, wenn Sie sich auf die Lösung des Vorfalls konzentrieren.
Der klassische Fall von "zu vielen wilden Netzwerkverbindungen"
Sie werden um 2 Uhr morgens angerufen, weil "etwas" nicht funktioniert. Bis heute Nacht hat alles normal funktioniert.
Beginnend mit einer Variation des ss Befehl (oder netstat, wenn Sie etwas älter sind, wie ich), bemerken Sie Hunderte von Verbindungen in einem TIME-WAIT und CLOSE-WAIT auf Ihrem Hauptserver.
Hinweis :In der folgenden Animation verwenden wir den ss -4a Befehl, um alle IPv4-Verbindungen aufzulisten. Aber wir interessieren uns mehr für diejenigen, die in WAIT sind Zustand:
Sie können sehen, dass alle diese Verbindungen auf mindestens zwei Servern auf Port 50505 zu verweisen scheinen. Die Ziel-IP und der Port befinden sich in Feld Nr. 6. Siehe das Bild unten.
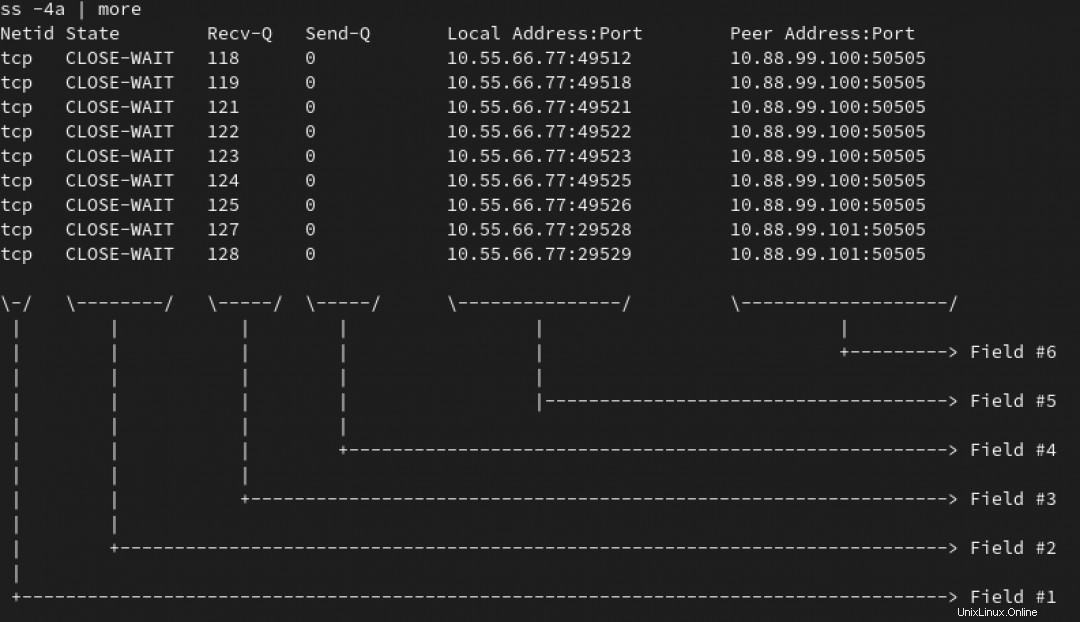
Jetzt wollen Sie herausfinden, wie viele Verbindungen stehen für jede Ziel-IP aus.
Wir können dies erreichen, indem wir ss optimieren Befehl, den wir zuvor verwendet haben:
Die Reihenfolge der Schritte ist die folgende:
- Wir beginnen mit der Überprüfung des Headers und der ersten 10 Zeilen mit dem Befehl
ss -4a | grep WAIT | head - Dann
pipewir das anawk, das in diesem Fall zum Drucken von Feld #6 verwendet wird (wir gehen davon aus, dass Leerzeichen das Standardtrennzeichen sind). - Danach
sortwir die vorherige Ausgabe, da wir als Nächstes eine Anzahl der beteiligten unterschiedlichen Zielserver haben möchten. - Schließlich verwenden wir
uniq -cum die Anzahl der eindeutigen Linien darzustellen. Da wir uns im letzten Schritt für diese Aufgabe befinden, müssen wir denheadentfernen Befehl, den wir beim Erstellen der Ausgabe verwendet haben.
An diesem Punkt der Untersuchung können Sie beginnen, einige Korrelationen herzustellen, z. B. „Die anderen beiden Ziele sind betroffen, die Ursache liegt also entweder auf der Clusterebene oder im Zusammenhang mit dem Netzwerk/der Firewall.“
Es gibt sicherlich Möglichkeiten, die Ausgabe von ss anzupassen , um nur die Spalte anzuzeigen, an der Sie interessiert sind. Es kann jedoch etwas sein, das Sie um 2 Uhr morgens nicht durchsuchen möchten. Dies war nur ein Beispiel, und in vielen anderen Situationen werden Sie andere Befehle mit mehreren Optionen haben.
Hier ist die Idee, einen schnellen Weg zu zeigen, wie Sie mit der Ausgabe arbeiten können, die Ihnen wahrscheinlich vertraut ist, von einigen Befehlen, die Sie bereits verwendet haben (aber Sie müssen oder wollen sich nicht ALLE möglichen Methoden zur Konfiguration ihrer Ausgabe merken).
Der klassische Fall von "wenig freiem Speicherplatz"
Ein weiteres Beispiel aus dem wirklichen Leben:Sie beheben ein Problem und stellen fest, dass ein Dateisystem zu 100 % ausgelastet ist.
Es können viele Unterverzeichnisse und Dateien in der Produktion vorhanden sein, daher müssen Sie möglicherweise eine Möglichkeit finden, die "schlechtesten Verzeichnisse" zu klassifizieren, da das Problem (oder die Lösung) in einem oder mehreren liegen könnte.
Im nächsten Beispiel zeige ich ein sehr einfaches Szenario, um den Punkt zu veranschaulichen.
Die Reihenfolge der Schritte ist:
- Wir gehen in das Dateisystem, in dem der Speicherplatz knapp ist (ich habe mein Home-Verzeichnis als Beispiel verwendet).
- Dann verwenden wir den Befehl
df -k *um die Größe von Verzeichnissen in Kilobyte anzuzeigen. - Das erfordert eine gewisse Klassifizierung, damit wir die großen finden können, aber nur
sortreicht nicht aus, da dieser Befehl die Zahlen standardmäßig nicht als Werte, sondern nur als Zeichen behandelt. - Wir fügen
-nhinzu zumsortBefehl, der uns nun die größten Verzeichnisse anzeigt. - Falls wir zu vielen anderen Verzeichnissen navigieren müssen, Erstellen eines
aliaskönnte nützlich sein.
[ Lernen Sie die Grundlagen der Verwendung von Kubernetes in diesem kostenlosen Spickzettel. ]
Abschluss
Es gibt Befehle, die in verschiedenen Situationen nützlich sind, z. B. grep , awk , sort . Die Kenntnis einiger grundlegender Optionen und deren Kombination kann sehr effektiv sein, wenn Sie die Ausgabe anderer Befehle manipulieren und vereinfachen oder Textdateien verarbeiten müssen.
Diese Befehle gibt es in fast jeder Unix-Variante, ob alt oder neu, weshalb es von Vorteil ist, sie in Ihrer Trickkiste zu haben. Sie wissen nie, wann diese Tools Ihr Leben retten (zwinker).