Stellen Sie sich vor, Sie haben eine Datei (oder mehrere Dateien) und möchten in diesen Dateien nach einer bestimmten Zeichenfolge oder Konfigurationseinstellung suchen. Jede Datei einzeln zu öffnen und zu versuchen, die bestimmte Zeichenfolge zu finden, wäre mühsam und wahrscheinlich nicht der richtige Ansatz. Was können wir also verwenden?
Es gibt viele Tools, die wir in *nix-basierten Systemen verwenden können, um Text zu finden und zu manipulieren. In diesem Artikel behandeln wir den grep Befehl, um nach Mustern zu suchen, unabhängig davon, ob sie in Dateien gefunden wurden oder aus einem Stream stammen (eine Datei oder eine Eingabe, die aus einer Pipe stammt, oder | ). In einem kommenden Artikel werden wir auch sehen, wie man sed verwendet (Stream-Editor), um einen Stream zu bearbeiten.
Der beste Weg, die Funktionsweise eines Programms oder Dienstprogramms zu verstehen, besteht darin, seine Manpage zu konsultieren. Viele (wenn nicht alle) Unix-Tools stellen während der Installation Handbuchseiten bereit. Auf Red Hat Enterprise Linux-basierten Systemen können wir Folgendes ausführen, um grep aufzulisten Dokumentationsdateien von :
$ rpm -qd grep
/usr/share/doc/grep/AUTHORS
/usr/share/doc/grep/NEWS
/usr/share/doc/grep/README
/usr/share/doc/grep/THANKS
/usr/share/doc/grep/TODO
/usr/share/info/grep.info.gz
/usr/share/man/man1/egrep.1.gz
/usr/share/man/man1/fgrep.1.gz
Da uns Manpages zur Verfügung stehen, können wir jetzt grep verwenden und erkunden Sie die Optionen.
grep Grundlagen
In diesem Teil des Artikels verwenden wir die words Datei, die Sie an folgendem Ort finden:
$ ls -l /usr/share/dict/words
lrwxrwxrwx. 1 root root 11 Feb 3 2019 /usr/share/dict/words -> linux.words
Diese Datei enthält 479.826 Wörter und wird von words bereitgestellt Paket. In meinem Fedora-System ist dieses Paket words-3.0-33.fc30.noarch . Wenn wir den Inhalt der words auflisten Datei sehen wir die folgende Ausgabe:
$ cat /usr/share/dict/words
1080
10-point
10th
11-point
[……]
[……]
zyzzyva
zyzzyvas
ZZ
Zz
zZt
ZZZ
Ok, also haben wir die words gesagt Die Datei enthielt 479.826 Zeilen, aber woher wissen wir das? Denken Sie daran, dass wir vorhin über Manpages gesprochen haben. Mal sehen, ob grep bietet eine Option zum Zählen von Zeilen in einer bestimmten Datei.
Ironischerweise verwenden wir grep wie folgt nach der Option suchen:

Wir brauchen also offensichtlich -c , oder die lange Option --count , um die Anzahl der Zeilen in einer bestimmten Datei zu zählen. Zählen der Zeilen in /usr/share/dict/words ergibt:
$ grep -c '.' /usr/share/dict/words
479826
Der '.' bedeutet, dass alle Zeilen gezählt werden, die mindestens ein Zeichen, Leerzeichen, Leerzeichen, Tabulatoren usw. enthalten.
Grundlegendes grep reguläre Ausdrücke
Das grep Der Befehl wird leistungsfähiger, wenn wir reguläre Ausdrücke (regexes) verwenden. Während wir uns also auf grep konzentrieren Befehl selbst, werden wir auch auf die grundlegende Syntax regulärer Ausdrücke eingehen.
Nehmen wir an, wir interessieren uns nur für Wörter, die mit Z beginnen . In dieser Situation sind Regexes praktisch. Wir verwenden das Karat (^ ), um nach Mustern zu suchen, die mit einem bestimmten Zeichen beginnen, das den Anfang einer Zeichenfolge bezeichnet:
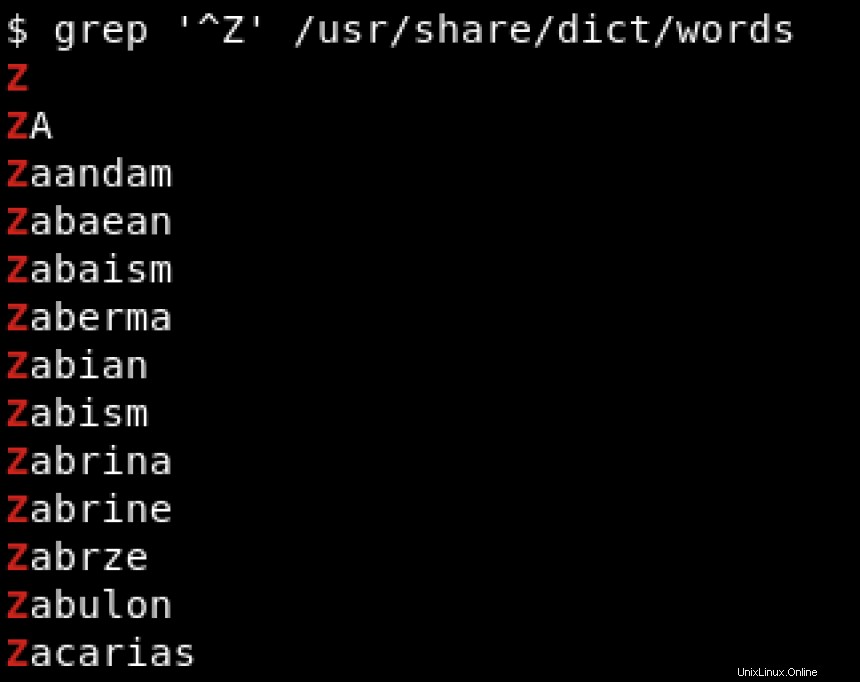
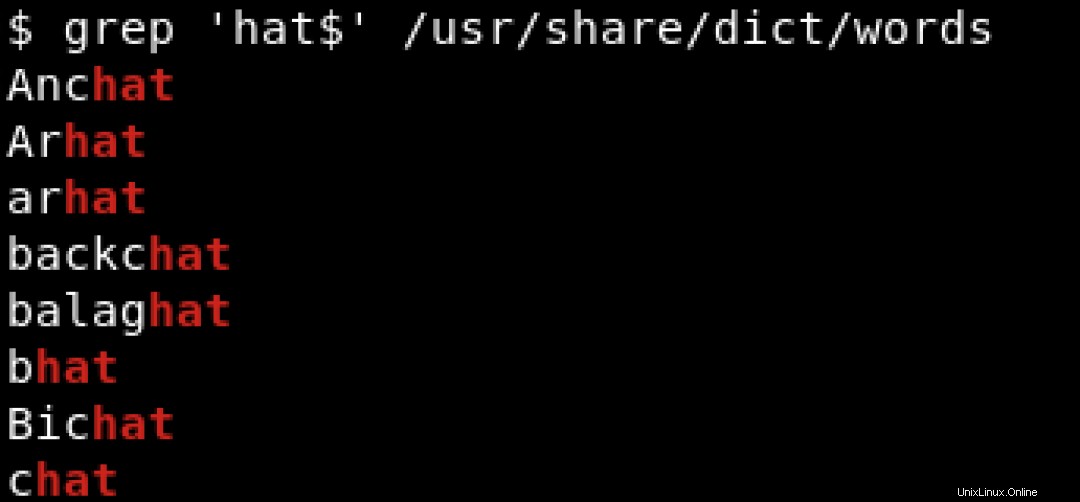
Um nach Mustern zu suchen, die mit einem bestimmten Zeichen enden, verwenden wir das Dollarzeichen ($ ) um das Ende der Zeichenfolge zu kennzeichnen. Sehen Sie sich das Beispiel unten an, wo wir nach Zeichenfolgen suchen, die mit hat enden :
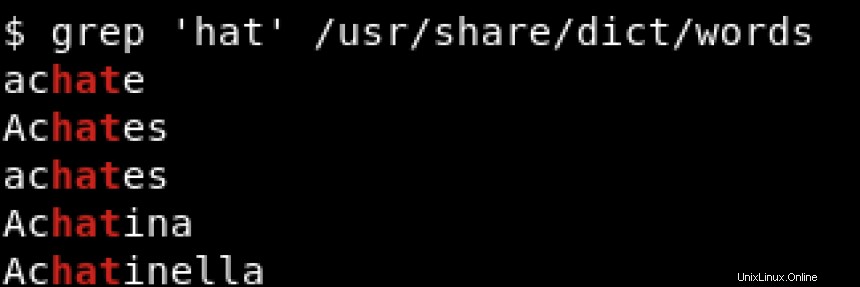
Um alle Zeilen zu drucken, die hat enthalten Unabhängig von seiner Position, ob am Zeilenanfang oder am Zeilenende, würden wir so etwas verwenden wie:
Der ^ und $ werden als Metazeichen bezeichnet und sollten mit einem Backslash (\ ), wenn wir diese Zeichen buchstäblich abgleichen möchten. Wenn Sie mehr über Metazeichen erfahren möchten, lesen Sie https://www.regular-expressions.info/characters.html.
Beispiel:Kommentare entfernen
Jetzt, wo wir an der Oberfläche von grep gekratzt haben , lassen Sie uns an einigen realen Szenarien arbeiten. Viele Konfigurationsdateien in *nix enthalten Kommentare, die verschiedene Einstellungen innerhalb der Konfigurationsdatei beschreiben. Die /etc/fstab , Datei hat zum Beispiel:
$ cat /etc/fstab
#
# /etc/fstab
# Created by anaconda on Thu Oct 27 05:06:06 2016
#
# Accessible filesystems, by reference, are maintained under '/dev/disk'
# See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info
#
/dev/mapper/VGCRYPTO-ROOT / ext4 defaults,x-systemd.device-timeout=0 1 1
UUID=e9de0f73-ddddd-4d45-a9ba-1ffffa /boot ext4 defaults 1 2
LABEL=SSD_SWAP swap swap defaults 0 0
#/dev/mapper/VGCRYPTO-SWAP swap swap defaults,x-systemd.device-timeout=0 0 0
Die Kommentare sind durch die Raute gekennzeichnet (# ), und wir möchten sie ignorieren, wenn sie gedruckt werden. Eine Option ist die cat Befehl:
$ cat /etc/fstab | grep -v '^#'
Sie brauchen jedoch cat nicht hier (vermeiden Sie die nutzlose Verwendung von Cat). Das grep Der Befehl ist perfekt in der Lage, Dateien zu lesen, also können Sie stattdessen etwas wie das Folgende verwenden, um Zeilen zu ignorieren, die Kommentare enthalten:
$ grep -v '^#' /etc/fstab
Wenn Sie die Ausgabe (ohne Kommentare) stattdessen an eine andere Datei senden möchten, verwenden Sie:
$ grep -v '^#' /etc/fstab > ~/fstab_without_comment
Während grep die Ausgabe auf dem Bildschirm formatieren kann, ist dieser Befehl nicht in der Lage, eine Datei an Ort und Stelle zu ändern. Dazu benötigen wir einen Dateieditor wie ed . Im nächsten Artikel verwenden wir sed um dasselbe zu erreichen, was wir hier mit grep gemacht haben .
Beispiel:Kommentare und Leerzeilen entfernen
Wo wir noch bei grep sind , sehen wir uns die Datei /etc/sudoers an Datei. Diese Datei enthält viele Kommentare, aber wir interessieren uns nur für Zeilen, die keine Kommentare haben, und wir wollen auch die leeren Zeilen loswerden.
Entfernen wir also zuerst die Zeilen mit den Kommentaren. Die folgende Ausgabe wird erzeugt:
# grep -v '^#' /etc/sudoers
Defaults !visiblepw
Defaults env_reset
Defaults env_keep = "COLORS DISPLAY HOSTNAME HISTSIZE KDEDIR LS_COLORS"
Defaults env_keep += "MAIL PS1 PS2 QTDIR USERNAME LANG LC_ADDRESS LC_CTYPE"
Defaults env_keep += "LC_COLLATE LC_IDENTIFICATION LC_MEASUREMENT LC_MESSAGES"
Defaults env_keep += "LC_MONETARY LC_NAME LC_NUMERIC LC_PAPER LC_TELEPHONE"
Defaults env_keep += "LC_TIME LC_ALL LANGUAGE LINGUAS _XKB_CHARSET XAUTHORITY"
Defaults secure_path = /usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
root ALL=(ALL) ALL
%wheel ALL=(ALL) ALL
Jetzt wollen wir die leeren (leeren) Zeilen loswerden. Nun, das ist einfach, führen Sie einfach ein weiteres grep aus Befehl:
# grep -v '^#' /etc/sudoers | grep -v '^$'
Defaults !visiblepw
Defaults env_reset
Defaults env_keep = "COLORS DISPLAY HOSTNAME HISTSIZE KDEDIR LS_COLORS"
Defaults env_keep += "MAIL PS1 PS2 QTDIR USERNAME LANG LC_ADDRESS LC_CTYPE"
Defaults env_keep += "LC_COLLATE LC_IDENTIFICATION LC_MEASUREMENT LC_MESSAGES"
Defaults env_keep += "LC_MONETARY LC_NAME LC_NUMERIC LC_PAPER LC_TELEPHONE"
Defaults env_keep += "LC_TIME LC_ALL LANGUAGE LINGUAS _XKB_CHARSET XAUTHORITY"
Defaults secure_path = /usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
root ALL=(ALL) ALL
%wheel ALL=(ALL) ALL
valentin.local ALL=NOPASSWD: /usr/bin/updatedb
Könnten wir es besser machen? Können wir unser grep ausführen Befehl ressourcenfreundlicher zu sein und grep nicht zu verzweigen zweimal? Das können wir auf jeden Fall:
# grep -Ev '^#|^$' /etc/sudoers
Defaults !visiblepw
Defaults env_reset
Defaults env_keep = "COLORS DISPLAY HOSTNAME HISTSIZE KDEDIR LS_COLORS"
Defaults env_keep += "MAIL PS1 PS2 QTDIR USERNAME LANG LC_ADDRESS LC_CTYPE"
Defaults env_keep += "LC_COLLATE LC_IDENTIFICATION LC_MEASUREMENT LC_MESSAGES"
Defaults env_keep += "LC_MONETARY LC_NAME LC_NUMERIC LC_PAPER LC_TELEPHONE"
Defaults env_keep += "LC_TIME LC_ALL LANGUAGE LINGUAS _XKB_CHARSET XAUTHORITY"
Defaults secure_path = /usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
root ALL=(ALL) ALL
%wheel ALL=(ALL) ALL
valentin.local ALL=NOPASSWD: /usr/bin/updatedb
Hier haben wir ein weiteres grep eingeführt Option -E (oder --extended-regexp ) <PATTERN> ist ein erweiterter regulärer Ausdruck.
Beispiel:Nur /etc/passwd drucken Benutzer
Es ist offensichtlich, dass grep ist leistungsfähig, wenn es mit regulären Ausdrücken verwendet wird. Dieser Artikel behandelt nur einen kleinen Teil von grep ist wirklich in der Lage. Um die Fähigkeiten von grep zu demonstrieren und die Verwendung von regulären Ausdrücken analysieren wir die Datei /etc/passwd Datei und drucke nur die Benutzernamen.
Das Format von /etc/passwd Datei ist wie folgt:
$ head /etc/passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
Die obigen Felder haben folgende Bedeutung:
<name>:<password>:<UID>:<GID>:<GECOS>:<directory>:<shell>
Siehe man 5 passwd Weitere Informationen finden Sie unter /etc/passwd Datei. Um nur die Benutzernamen auszugeben, könnten wir etwa Folgendes verwenden:
$ grep -Eo '^[a-zA-Z_-]+' /etc/passwd
root
bin
daemon
adm
lp
sync
shutdown
halt
mail
operator
Im obigen grep Befehl haben wir eine weitere Option eingeführt:-o (oder --only-matching ), um nur den Teil einer Zeile anzuzeigen, der <PATTERN> entspricht . Dann haben wir -Eo kombiniert um das gewünschte Ergebnis zu erhalten.
Wir werden den obigen Befehl jetzt auflösen, damit wir besser verstehen können, was wirklich passiert. Von links nach rechts:
^Übereinstimmungen am Anfang der Zeile.[a-zA-Z_-]wird als Zeichenklasse bezeichnet und passt zu einer Liste, die mit einem einzelnen Zeichen übereinstimmt.+ist ein Quantifizierer, der zwischen einer und einer unbegrenzten Anzahl von Malen übereinstimmt.
Der obige reguläre Ausdruck wiederholt sich, bis er ein Zeichen erreicht, mit dem er nicht übereinstimmt. Die erste Zeile der Datei lautet:
root:x:0:0:root:/root:/bin/bash
Es wird wie folgt verarbeitet:
- Das erste Zeichen ist ein
r, also wird es mit[a-z]abgeglichen . - Der
+springt zum nächsten Zeichen. - Das zweite Zeichen ist ein
ound dies wird durch[a-z]abgeglichen . - Der
+springt zum nächsten Zeichen.
Diese Sequenz wiederholt sich, bis wir den Doppelpunkt treffen (: ). Die Zeichenklasse [a-zA-Z_-] stimmt nicht mit : überein Symbol, also grep wechselt zur nächsten Zeile.
Da die Benutzernamen im passwd Datei alle Kleinbuchstaben sind, könnten wir unsere Zeichenklasse auch wie folgt vereinfachen und trotzdem das gewünschte Ergebnis erhalten:
$ grep -Eo '^[a-z_-]+' /etc/passwd
Beispiel:Einen Prozess finden
Bei Verwendung von ps Um nach einem Prozess zu suchen, verwenden wir oft etwas wie:
$ ps aux | grep ‘thunderbird’
Aber das ps Der Befehl listet nicht nur thunderbird auf Prozess. Es listet auch grep auf Befehl, den wir gerade ausgeführt haben, seit grep läuft auch nach der Pipe und wird in der Prozessliste angezeigt:
$ ps aux | grep thunderbird
val+ 2196 0.7 2.1 52 33 tty2 Sl+ 16:47 1:55 /usr/lib64/thunderbird/thunderbird
val+ 14064 0.0 0.0 57 82 pts/2 S+ 21:12 0:00 grep --color=auto thunderbird
Wir können dies handhaben, indem wir grep -v grep hinzufügen um grep auszuschließen aus der Ausgabe:
$ ps aux | grep thunderbird | grep -v grep
val+ 2196 0.7 2.1 52 33 tty2 Sl+ 16:47 1:55 /usr/lib64/thunderbird/thunderbird
Bei Verwendung von grep -v grep tun, was wir wollten, es gibt bessere Möglichkeiten, dasselbe Ergebnis zu erzielen, ohne ein neues grep zu forken Prozess:
$ ps aux | grep [t]hunderbird
val+ 2196 0.7 2.1 52 33 tty2 Sl+ 16:47 1:55 /usr/lib64/thunderbird/thunderbird
Der [t]hunderbird entspricht hier dem wörtlichen t , und unterscheidet zwischen Groß- und Kleinschreibung. Es passt nicht zu grep , und deshalb sehen wir jetzt nur noch thunderbird in der Ausgabe.
Dieses Beispiel ist nur eine Demonstration, wie flexibel grep ist ist, hilft Ihnen nicht bei der Fehlersuche in Ihrem Prozessbaum. Dafür gibt es bessere Tools wie pgrep .
Zusammenfassung
Verwenden Sie grep wenn Sie nach einem Muster suchen möchten, entweder in einer Datei oder mehreren Verzeichnissen rekursiv. Versuchen Sie zu verstehen, wie reguläre Ausdrücke bei grep funktionieren , da reguläre Ausdrücke mächtig sein können.
[Möchten Sie Red Hat Enterprise Linux ausprobieren? Jetzt kostenlos herunterladen.]