Reguläre Ausdrücke können eines der leistungsstärksten Werkzeuge in Ihrer Toolbox als Linux-Benutzer, Systemadministrator oder sogar als Programmierer sein. Es kann auch eines der entmutigendsten Dinge sein, die es zu lernen gilt, aber das muss nicht sein! Obwohl es unendlich viele Möglichkeiten gibt, einen Ausdruck zu schreiben, müssen Sie nicht jeden einzelnen Schalter und jedes einzelne Flag lernen. In dieser kurzen Anleitung zeige ich Ihnen ein paar einfache Möglichkeiten zur Verwendung von Regex, die Sie im Handumdrehen zum Laufen bringen, und teile einige Folgeressourcen, die Sie zu einem Regex-Meister machen, wenn Sie einer werden möchten.
Eine schnelle Übersicht
Reguläre Ausdrücke, auch als „Regex“-Muster oder sogar „reguläre Anweisungen“ bezeichnet, sind vereinfacht gesagt „eine Folge von Zeichen, die ein Suchmuster definieren“. Die Idee entstand in den 1950er Jahren, als Stephen Cole Kleene eine Beschreibung einer Idee schrieb, die er eine „reguläre Sprache“ nannte, von der ein Teil als „Kleenes Theorem“ bekannt wurde. Auf einer sehr hohen Ebene besagt es, wenn die Elemente der Sprache definiert werden können, dann kann ein Ausdruck geschrieben werden, um Mustern innerhalb dieser Sprache zu entsprechen.
Weitere Linux-Ressourcen
- Spickzettel für Linux-Befehle
- Spickzettel für fortgeschrittene Linux-Befehle
- Kostenloser Online-Kurs:RHEL Technical Overview
- Spickzettel für Linux-Netzwerke
- SELinux-Spickzettel
- Spickzettel für allgemeine Linux-Befehle
- Was sind Linux-Container?
- Unsere neuesten Linux-Artikel
Seitdem waren reguläre Ausdrücke Teil sogar der frühesten Unix-Programme, darunter vi, sed, awk, grep und andere. Tatsächlich leitet sich das Wort grep von dem Befehl ab, der im frühesten „ed“-Editor verwendet wurde, nämlich g/re/p , was im Wesentlichen bedeutet:"Führen Sie eine globale Suche nach diesem regulären Ausdruck durch und geben Sie die Zeilen aus." Cool!
Warum wir reguläre Ausdrücke brauchen
Wie oben erwähnt, werden reguläre Ausdrücke verwendet, um ein Muster zu definieren, das uns hilft, Objekte zu finden oder zu finden, die diesem Muster entsprechen. Diese Objekte können Dateien in einem Dateisystem sein, wenn find verwendet wird Befehl zum Beispiel, oder ein Textblock in einer Datei, die wir zum Beispiel mit grep, awk, vi oder sed durchsuchen könnten.
Beginnen Sie mit den Grundlagen
Beginnen wir ganz am Anfang; Es ist ein sehr guter Anfang.
Die erste Regex, die jeder zu lernen scheint, ist wahrscheinlich eine, die Sie bereits kennen und nicht wussten, was es war. Wollten Sie schon immer eine Liste von Dateien in einem Verzeichnis ausdrucken, aber es war zu lang? Vielleicht haben Sie schon einmal gesehen, wie jemand \*.gif eingegeben hat um GIF-Bilder in einem Verzeichnis aufzulisten, wie:
$ ls *.gif
Das ist ein regulärer Ausdruck!
Beim Schreiben von regulären Ausdrücken haben bestimmte Zeichen eine besondere Bedeutung, die es uns ermöglicht, über das Abgleichen von nur Zeichen hinauszugehen und ganze Sätze von Zeichen abzugleichen. In diesem Fall der * Zeichen, auch "Stern" oder "Splat" genannt, ersetzt Dateinamen und ermöglicht es Ihnen, alle Dateien mit der Endung .gif abzugleichen .
Suche nach Mustern in einer Datei
Der nächste Schritt in Ihrem Regex-Foo-Training ist die Suche nach Mustern in einer Datei, insbesondere die Verwendung des Ersetzungsmusters, um schnelle Änderungen vorzunehmen.
Zwei gängige Möglichkeiten, dies zu tun, sind:
- Verwenden Sie vi, um die Datei zu öffnen, suchen Sie nach einem Muster und nehmen Sie die Änderung vor (sogar automatisch mit Ersetzen).
- Verwenden Sie den "Stream-Editor", auch bekannt als "sed", um programmgesteuert in der Datei zu suchen und die Änderung vorzunehmen.
Beginnen wir damit, etwas Regex zu lernen, indem wir vi verwenden, um die folgende Datei zu bearbeiten:
Der schnelle braune Fuchs sprang über den faulen Hund.
Einfacher Test
Schwerer Test
Extremer Testfall
ABC 123 abc 567
Der Hund ist faulNun, da diese Datei in vi geöffnet ist, schauen wir uns einige Regex-Beispiele an, die uns dabei helfen werden, einige übereinstimmende Zeichenfolgen darin zu finden und sie sogar automatisch zu ersetzen.
Um die Dinge einfacher zu machen, lassen Sie uns vi so einstellen, dass Groß- und Kleinschreibung ignoriert wird. Geben Sie
set icein um die Suche ohne Berücksichtigung der Groß-/Kleinschreibung zu aktivieren.Um nun die Suche in vi zu starten, geben Sie
/ein Zeichen gefolgt von Ihrem Suchmuster.Suche nach Dingen am Anfang oder Ende einer Zeile
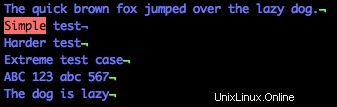
Verwenden Sie dieses Regex-Muster, um eine Zeile zu finden, die mit „Simple“ beginnt:
/^EinfachBeachten Sie im Bild unten, dass nur die Zeile, die mit „Simple“ beginnt, hervorgehoben ist. Das Karat-Symbol (
^) ist das Regex-Äquivalent von „beginnt mit.“
Als nächstes verwenden wir den
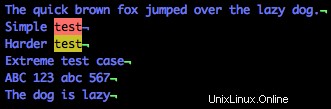
$Symbol, das in der Regex-Sprache "endet mit" ist./test$
Sehen Sie, wie beide Zeilen hervorgehoben werden, die auf "test" enden? Beachten Sie auch, dass die vierte Zeile das Wort test enthält, aber nicht am Ende, daher ist diese Zeile nicht hervorgehoben.
Dies ist die Stärke von regulären Ausdrücken, die Ihnen die Möglichkeit geben, schnell und einfach eine große Anzahl von Übereinstimmungen zu durchsuchen, aber speziell nur exakte Übereinstimmungen aufzuschlüsseln.
Test auf die Häufigkeit des Auftretens
Um Ihre Fähigkeiten in regulären Ausdrücken weiter auszubauen, werfen wir einen Blick auf einige häufigere Sonderzeichen, mit denen wir nicht nur nach übereinstimmendem Text, sondern auch nach Übereinstimmungsmustern suchen können.
Frequenz passende Zeichen:
| Zeichen | Bedeutung | Beispiel |
|---|---|---|
* | Null oder mehr | ab* – der Buchstabe a gefolgt von null oder mehr b ist |
+ | Einer oder mehrere | ab+ – der Buchstabe a gefolgt von einem oder mehreren b ist |
? | Null oder eins | ab? – null oder nur ein b |
{n} | Wenn eine Zahl gegeben ist, finde genau diese Zahl | ab{2} – der Buchstabe a gefolgt von genau zwei b ist |
{n,} | Wenn eine Zahl gegeben ist, finde mindestens diese Zahl | ab{2,} – der Buchstabe a gefolgt von mindestens zwei b ist |
{n,y} | Wenn zwei Zahlen gegeben sind, finde einen Bereich dieser Zahl | ab{1,3} – der Buchstabe a gefolgt von einem bis drei b ist |
Klassen von Charakteren finden
Der nächste Schritt beim Regex-Training ist die Verwendung von Zeichenklassen in unserem Musterabgleich. Wichtig ist hier zu beachten, dass diese Klassen entweder als Liste kombiniert werden können, wie z. B. [a,d,x,z] , oder als Bereich, z. B. [a-z] , und dass bei Zeichen normalerweise zwischen Groß- und Kleinschreibung unterschieden wird.
Um diese Arbeit in vi zu sehen, müssen wir den Fall ignorieren, den wir zuvor festgelegt haben, deaktivieren. Lassen Sie uns Folgendes eingeben:set noic Groß-/Kleinschreibung wieder deaktivieren.
Einige gängige Klassen von Zeichen, die als Bereiche verwendet werden, sind:
- a-z – alles Kleinbuchstaben
- A-Z – alles GROSSBUCHSTABEN
- 0-9 – Zahlen
Versuchen wir nun eine ähnliche Suche wie zuvor:
/tT
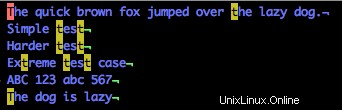
Merkst du, dass es nichts findet? Das liegt daran, dass die vorherige Regex genau nach „tT“ sucht. Wenn wir dies ersetzen durch:
/[tT]
Wir werden sehen, dass sowohl die Kleinbuchstaben als auch die GROSSBUCHSTABEN im gesamten Dokument übereinstimmen.
Lassen Sie uns nun ein paar Klassenbereiche miteinander verketten und sehen, was wir bekommen. Versuchen Sie:
/[A-Z1-3]
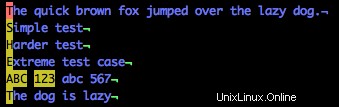
Beachten Sie, dass die Großbuchstaben und 123 hervorgehoben sind, aber nicht die Kleinbuchstaben (einschließlich des Endes von Zeile fünf).
Flaggen
Der letzte Schritt in Ihrem ersten Regex-Training besteht darin, Flags zu verstehen, die vorhanden sind, um nach speziellen Arten von Zeichen zu suchen, ohne sie in einem Bereich auflisten zu müssen.
.– beliebiges Zeichen\s– Leerzeichen\w– Wort\d– Ziffer (Zahl)
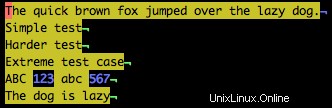
Um beispielsweise alle Ziffern im Beispieltext zu finden, verwenden Sie:
/\d
Beachten Sie im Beispiel unten, dass alle Nummern hervorgehoben sind.
Um das Gegenteil zu erreichen, verwenden Sie normalerweise dasselbe Flag, jedoch in GROSSBUCHSTABEN. Zum Beispiel:
\S– kein Leerzeichen\W– kein Wort\D– keine Ziffer
Beachten Sie im Beispiel unten, dass Sie \D verwenden , alle Zeichen AUSSER den Zahlen werden hervorgehoben.
Suche mit sed
Eine kurze Anmerkung zu sed:Es ist ein Stream-Editor, was bedeutet, dass Sie nicht mit einer Benutzeroberfläche interagieren. Es nimmt den Strom, der auf der einen Seite hereinkommt, und schreibt ihn auf der anderen Seite heraus.
Die Verwendung von sed ist vi sehr ähnlich, außer dass Sie ihm die Regex zum Suchen und Ersetzen geben und es die Ausgabe zurückgibt. Zum Beispiel:
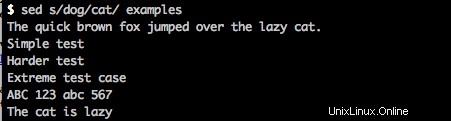
sed s/dog/cat/ Beispiele
gibt Folgendes auf dem Bildschirm zurück:
Wenn Sie diese Datei speichern möchten, ist es nur etwas komplizierter. Sie müssen ein paar Befehle miteinander verketten, um a) diese Datei zu schreiben und b) sie über die erste Datei zu kopieren.
Versuchen Sie dazu Folgendes:
sed s/dog/cat/Beispiele> temp.out; mv temp.out Beispiele
Wenn Sie sich nun Ihre examples ansehen Datei sehen Sie, dass das Wort "Hund" ersetzt wurde.
Der schnelle braune Fuchs sprang über die faule Katze.
Einfacher Test
Schwerer Test
Extremer Testfall
ABC 123 abc 567
Die Katze ist faulWeitere Informationen
Ich hoffe, das war ein hilfreicher Überblick über reguläre Ausdrücke. Natürlich ist dies nur die Spitze des Eisbergs, und ich hoffe, Sie lernen dieses leistungsstarke Tool weiter kennen, indem Sie die zusätzlichen Ressourcen unten lesen.
Hier erhalten Sie Hilfe
- Meine Lieblingsressource ist die PERL Pocket Reference
- Weitere Informationen zu regulären Ausdrücken finden Sie unter Reguläre Ausdrücke beherrschen von Jeff Friedl
Weitere Beispiele finden Sie unter
- So finden Sie Dateien unter Linux
- Datenvalidierung in Perl mit Regexp::Common
- 7 Gründe, Vim zu lieben