Ich arbeite in Teilzeit als Datenprüfer. Betrachten Sie mich als Korrektor, der mit Datentabellen und nicht mit Prosaseiten arbeitet. Die Tabellen werden aus relationalen Datenbanken exportiert und sind in der Regel relativ bescheiden:100.000 bis 1.000.000 Datensätze und 50 bis 200 Felder.
Ich habe noch nie eine fehlerfreie Datentabelle gesehen. Die Unordnung beschränkt sich nicht, wie Sie vielleicht denken, auf doppelte Datensätze, Rechtschreib- und Formatierungsfehler und Datenelemente, die in das falsche Feld platziert wurden. Ich finde auch:
- Unterbrochene Datensätze, die sich über mehrere Zeilen erstreckten, weil Datenelemente eingebettete Zeilenumbrüche hatten
- Datenelemente in einem Feld stimmen nicht mit Datenelementen in einem anderen Feld im selben Datensatz überein
- Datensätze mit abgeschnittenen Datenelementen, oft weil sehr lange Zeichenfolgen in Felder mit 50- oder 100-Zeichen-Grenzen gesteckt wurden
- Fehler bei der Zeichencodierung, die Kauderwelsch erzeugen, das als Mojibake bekannt ist
- unsichtbare Steuerzeichen, von denen einige Datenverarbeitungsfehler verursachen können
- Ersatzzeichen und mysteriöse Fragezeichen, die vom letzten Programm eingefügt wurden, das die Zeichenkodierung der Daten nicht verstanden hat
Das Beseitigen dieser Probleme ist nicht schwer, aber es gibt nichttechnische Hindernisse, um sie zu finden. Der erste ist die natürliche Zurückhaltung aller, sich mit Datenfehlern auseinanderzusetzen. Bevor ich eine Tabelle sehe, haben die Dateneigentümer oder -manager möglicherweise alle fünf Phasen der Datentrauer durchlaufen:
- Es gibt keine Fehler in unseren Daten.
- Nun, vielleicht gibt es ein paar Fehler, aber sie sind nicht so wichtig.
- OK, es gibt viele Fehler; wir beauftragen unsere internen Mitarbeiter damit, sich darum zu kümmern.
- Wir haben begonnen, einige der Fehler zu beheben, aber es ist zeitaufwändig; wir werden es tun, wenn wir auf die neue Datenbanksoftware migrieren.
- Wir hatten beim Umzug in die neue Datenbank keine Zeit, die Daten zu bereinigen; wir könnten Hilfe gebrauchen.
Die zweite den Fortschritt blockierende Haltung ist der Glaube, dass die Datenbereinigung dedizierte Anwendungen erfordert – entweder teure proprietäre Programme oder das ausgezeichnete Open-Source-Programm OpenRefine. Um Probleme zu lösen, die dedizierte Anwendungen nicht lösen können, bitten Datenmanager möglicherweise einen Programmierer um Hilfe – jemanden, der sich mit Python oder R auskennt.
Für die Datenprüfung und -bereinigung sind jedoch im Allgemeinen keine dedizierten Anwendungen erforderlich. Klartext-Datentabellen gibt es seit vielen Jahrzehnten, ebenso wie Textverarbeitungswerkzeuge. Öffnen Sie eine Bash-Shell und Sie haben eine Toolbox mit leistungsstarken Textverarbeitungsprogrammen wie grep , cut , paste , sort , uniq , tr , und awk . Sie sind schnell, zuverlässig und benutzerfreundlich.
Ich führe alle meine Datenprüfungen auf der Befehlszeile durch, und ich habe viele meiner Datenprüfungstricks auf einer „Kochbuch“-Website veröffentlicht. Operationen, die ich regelmäßig erhalte, werden als Funktionen und Shell-Skripte gespeichert (siehe Beispiel unten).
Ja, ein Befehlszeilenansatz erfordert, dass die zu prüfenden Daten aus der Datenbank exportiert wurden. Und ja, die Prüfungsergebnisse müssen später in der Datenbank bearbeitet werden, oder (sofern die Datenbank dies zulässt) müssen die bereinigten Datenelemente als Ersatz für die unordentlichen importiert werden.
Aber die Vorteile sind bemerkenswert. awk verarbeitet einige Millionen Datensätze in Sekunden auf einem Desktop oder Laptop der Verbraucherklasse. Unkomplizierte reguläre Ausdrücke finden alle Datenfehler, die Sie sich vorstellen können. Und all dies geschieht sicher draußen die Datenbankstruktur:Die Befehlszeilenprüfung kann sich nicht auf die Datenbank auswirken, da sie mit Daten arbeitet, die aus ihrem Datenbankgefängnis befreit wurden.
Unix-geschulte Leser werden an dieser Stelle süffisant schmunzeln. Sie erinnern sich daran, wie sie vor vielen Jahren Daten auf der Kommandozeile auf genau diese Weise manipuliert haben. Was seitdem passiert ist, ist, dass Rechenleistung und RAM spektakulär gestiegen sind und die Standard-Kommandozeilen-Tools wesentlich effizienter gemacht wurden. Die Datenprüfung war noch nie schneller oder einfacher. Und jetzt, da Microsoft Windows 10 Bash- und GNU/Linux-Programme ausführen kann, wissen Windows-Benutzer das Unix- und Linux-Motto für den Umgang mit chaotischen Daten zu schätzen:Bleib ruhig und öffne ein Terminal.

Ein Beispiel
Angenommen, ich möchte das längste Datenelement in einem bestimmten Feld einer großen Tabelle finden. Das ist nicht wirklich eine Aufgabe zur Datenprüfung, aber es zeigt, wie Shell-Tools funktionieren. Zu Demonstrationszwecken verwende ich die tabulatorgetrennte Tabelle full0 , das 1.122.023 Datensätze (plus eine Kopfzeile) und 49 Felder enthält, und ich schaue in Feld Nummer 36 nach. (Ich bekomme Feldnummern mit einer Funktion, die auf meiner Kochbuch-Site erklärt wird.)
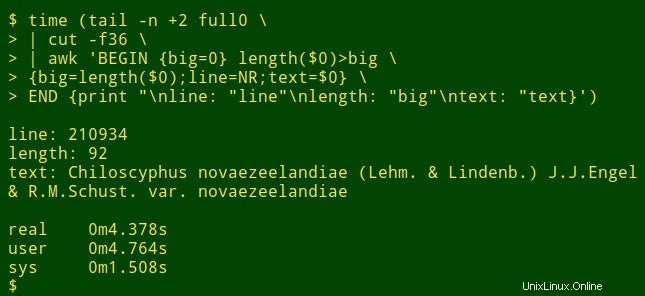
Der Befehl beginnt mit der Verwendung von tail um die Kopfzeile von full0 zu entfernen . Das Ergebnis wird an cut geleitet , das das enthauptete Feld 36 extrahiert. Als nächstes in der Pipeline ist awk . Hier die Variable big wird auf einen Wert von 0 initialisiert; dann awk testet die Länge des Datenelements im ersten Datensatz. Wenn die Länge größer als 0 ist, awk setzt big zurück auf die neue Länge und speichert die Zeilennummer (NR) in der Variablen line und das gesamte Datenelement in der Variablen text . awk verarbeitet dann nacheinander jeden der verbleibenden 1.122.022 Datensätze und setzt die drei Variablen zurück, wenn es ein längeres Datenelement findet. Schließlich druckt es eine sauber getrennte Liste mit Zeilennummern, Länge des Datenelements und Volltext des längsten Datenelements. (Im folgenden Code wurden die Befehle der Übersichtlichkeit halber auf mehrere Zeilen aufgeteilt.)
<code>tail -n +2 full0 \
> | cut -f36 \
> | awk 'BEGIN {big=0} length($0)>big \
> {big=length($0);line=NR;text=$0} \
> END {print "\nline: "line"\nlength: "big"\ntext: "text}' </code>
Wie lange dauert das? Ungefähr 4 Sekunden auf meinem Desktop (Core i5, 8 GB RAM):
Nun zum ordentlichen Teil:Ich kann diesen langen Befehl in eine Shell-Funktion einfügen, longest , die als Argumente den Dateinamen ($1) verwendet und die Feldnummer ($2) :

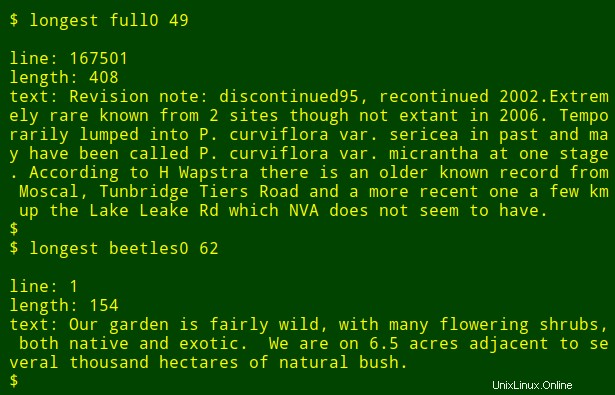
Ich kann den Befehl dann als Funktion erneut ausführen und die längsten Datenelemente in anderen Feldern und anderen Dateien finden, ohne mir merken zu müssen, wie der Befehl geschrieben ist:
Als letzte Änderung kann ich der Ausgabe den Namen des nummerierten Felds hinzufügen, nach dem ich suche. Dazu verwende ich head Um die Kopfzeile der Tabelle zu extrahieren, leiten Sie diese Zeile an tr weiter um Tabulatoren in neue Zeilen umzuwandeln und die resultierende Liste an tail zu leiten und head um den $2th zu drucken Feldname in der Liste, wobei $2 ist das Feldnummernargument. Der Feldname wird in der Shell-Variablen field gespeichert und an awk übergeben zum Drucken als internes awk Variable fld .
<code>longest() { field=$(head -n 1 "$1" | tr '\t' '\n' | tail -n +"$2" | head -n 1); \
tail -n +2 "$1" \
| cut -f"$2" | \
awk -v fld="$field" 'BEGIN {big=0} length($0)>big \
{big=length($0);line=NR;text=$0}
END {print "\nfield: "fld"\nline: "line"\nlength: "big"\ntext: "text}'; }</code> 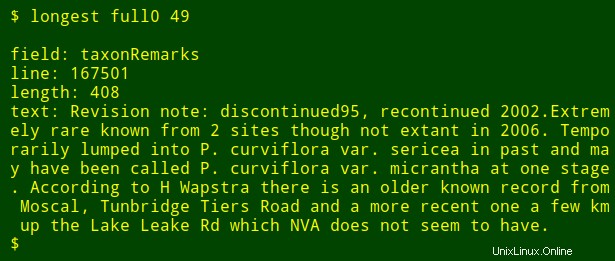
Beachten Sie, dass ich, wenn ich in mehreren verschiedenen Feldern nach dem längsten Datenelement suche, lediglich die Aufwärtspfeiltaste drücken muss, um das letzte longest zu erhalten Befehl, gehen Sie dann die Feldnummer zurück und geben Sie eine neue ein.