Freunde, die mit dem fortgeschrittenen Know-how und der Fehlerbehebung auf glusterfs fortfahren. In diesem Artikel haben wir einen 3-Knoten-Cluster, der auf glusterfs3.4 ausgeführt wird. Im Folgenden sind die Schritte aufgeführt, die für die Fehlerbehebung bei Glusterfs verwendet werden.
Schritt 1 :Überprüfen Sie den Status und die Informationen des Gluster-Volumes.

[root@gluster1 ~]# gluster volume info
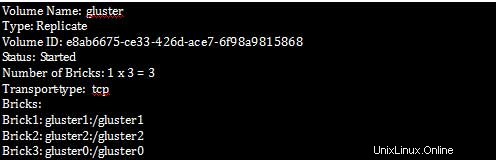
Schritt 2 :Zur Überprüfung aller Details der Replikation in Bricks.
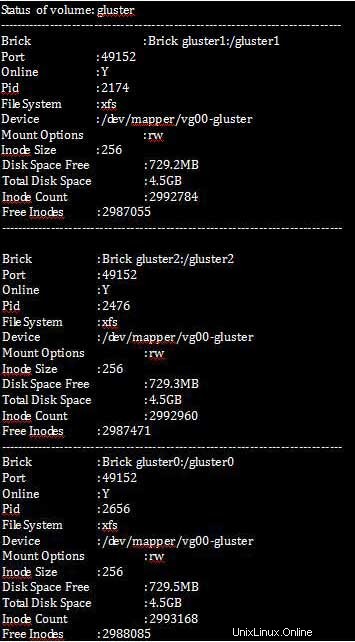
Die unten aufgeführten Befehle zeigen vollständige Statistiken darüber, welche Daten repliziert wurden und wie viele repliziert werden sollen, indem die Größe des gesamten freien Speicherplatzes überprüft wird.
[root@gluster1 ~]# gluster volume status all detail
Schritt 3 :Jetzt müssen wir eine bestimmte Konfiguration haben, um die Leistung und die Heilungseigenschaften der Glusterfs zu verbessern.
# gluster volume set gluster cluster.min-free-disk 5% # gluster volume set cluster.rebalance-stats on # gluster volume set cluster.readdir-optimize on # gluster volume set cluster.background-self-heal-count 20 # gluster volume set cluster.metadata-self-heal on # gluster volume set cluster.data-self-heal on # gluster volume set cluster.entry-self-heal: on # gluster volume set cluster.self-heal-daemon on # gluster volume set cluster.heal-timeout 500 # gluster volume set cluster.self-heal-window-size 2 # gluster volume set cluster.data-self-heal-algorithm diff # gluster volume set cluster.eager-lock on # gluster volume set cluster.quorum-type auto # gluster volume set cluster.self-heal-readdir-size 2KB # gluster volume set network.ping-timeout 5
Führen Sie dann Folgendes aus:
# service glusterd restart
Nachdem wir die Cluster-Eigenschaften festgelegt haben, können wir die Volume-Informationen wie unten gezeigt überprüfen:
[root@gluster1 ~]# gluster volume info
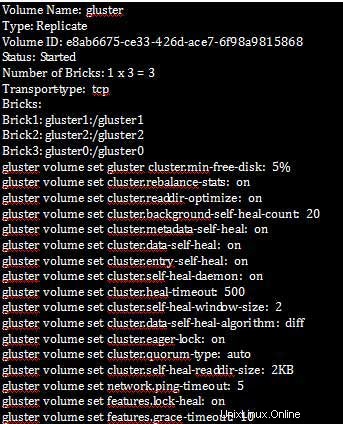
[root@gluster1 ~]# gluster volume status
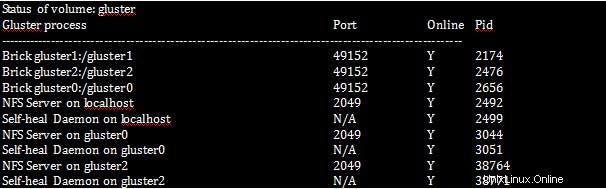
Bitte beachten Sie, dass der Self-heal-Daemon auf jedem System im Cluster ausgeführt werden sollte, da er für die Reparatur verantwortlich ist, falls ein Knoten für einige Zeit im Cluster ausgefallen ist.
Schritt 4 :Entfernen Sie jetzt eine Maschine gluster0 aus dem Cluster.
Unmounten Sie das Volume, das auf der Maschine gluster0 gemountet ist:
[root@gluster0 ~]# umount /mnt [root@gluster1 ~]# gluster volume remove-brick gluster replica 2 gluster0:/gluster0 commit
Informationen zum Gluster-Volumen (zur Überprüfung):
[root@gluster1 ~]# gluster volume info
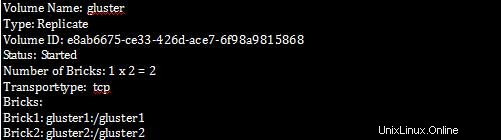
Führen Sie auf gluster1 den folgenden Befehl aus:
# gluster peer detach gluster0
Der Baustein des gluster0-Servers wird aus dem Cluster entfernt.