Das XFS-Dateisystem ist ein Hochleistungs-Journaling-Dateisystem. XFS ist das Standarddateisystem für RedHat Linux 7. XFS unterstützt eine maximale Dateisystemgröße von 500 TB und eine maximale Dateigröße von 16 TB. Sie können ein XFS-Dateisystem auf einer normalen Festplattenpartition und auf einem logischen Volume erstellen.
Der Datenabschnitt eines XFS-Dateisystems enthält die Metadaten des Dateisystems (Inodes, Verzeichnisse und indirekte Blöcke) und die Benutzerdateidaten. Der Datenabschnitt wird in Zuordnungsgruppen partitioniert, die virtuelle Speicherbereiche fester Größe sind. Alle Dateien und Verzeichnisse, die Sie erstellen, können mehrere Zuordnungsgruppen umfassen. Jede Zuordnungsgruppe verwaltet ihren eigenen Satz von Inodes und freien Speicherplatz unabhängig von anderen Zuordnungsgruppen, um sowohl Skalierbarkeit als auch Parallelität von E/A-Vorgängen bereitzustellen.
Das XFS-Journal (oder Protokoll) kann sich intern im Datenabschnitt des Dateisystems oder extern auf einem separaten Gerät befinden, um die Anzahl der Festplattensuchen zu reduzieren. Das Journal speichert Änderungen an den Metadaten des Dateisystems, während das Dateisystem ausgeführt wird, bis diese Änderungen in den Datenabschnitt geschrieben werden. XFS-Journaling garantiert die Konsistenz des Dateisystems nach einem Stromausfall oder einem Systemabsturz. Beim Mounten eines Dateisystems nach einem Absturz wird das Journal gelesen, um Vorgänge abzuschließen, die zum Zeitpunkt des Absturzes im Gange waren.
Beispiele zum Erstellen eines XFS-Dateisystems
1. XFS-Dateisystem mit internem Log auf demselben Gerät erstellen
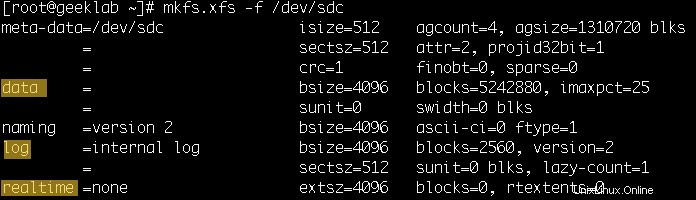
Verwenden Sie den Befehl mkfs.xfs oder mkfs –t xfs, um ein XFS-Dateisystem zu erstellen. Das folgende Beispiel erstellt ein XFS-Dateisystem mit einem internen Protokoll auf der Festplatte /dev/sdc. Wie in der Folie gezeigt, werden Parameter für das Dateisystem als Ausgabe angezeigt.
# mkfs.xfs /dev/sdc
meta-data=/dev/sdc isize=512 agcount=4, agsize=1310720 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=0, sparse=0
data = bsize=4096 blocks=5242880, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal log bsize=4096 blocks=2560, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0 2. XFS-Dateisystem mit Journal auf einem anderen Gerät erstellen
Das nächste Beispiel erstellt ein XFS-Dateisystem auf /dev/sdb, platziert das Journal jedoch auf einem anderen Gerät, /dev/sdc. Die Größenoption gibt ein 10000-Block-Journal an:
# mkfs.xfs -l logdev=/dev/sdc,size=10000b /dev/sdb
meta-data=/dev/sdb isize=512 agcount=4, agsize=1310720 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=0, sparse=0
data = bsize=4096 blocks=5242880, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =/dev/sdc bsize=4096 blocks=10000, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0 3. XFS-Dateisystem auf logischem Volume erstellen
Das nächste Beispiel erstellt ein XFS-Dateisystem mit einer Stripe-Einheitengröße von 32 KB und 6 Einheiten pro Stripe auf einem logischen Volume:
# mkfs.xfs -d su=32k,sw=6 /dev/mapper/vg_test-test_lv
meta-data=/dev/mapper/vg_test-test_lv isize=512 agcount=8, agsize=9592 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=0, sparse=0
data = bsize=4096 blocks=76736, imaxpct=25
= sunit=8 swidth=48 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal log bsize=4096 blocks=624, version=2
= sectsz=512 sunit=8 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0 XFS verwendet die Stripe-Einheitsgröße und die Anzahl der Einheiten pro Stripe, um Daten, Inodes und das Journal entsprechend für den Speicher auszurichten. Auf LVM- und Multiple Devices (MD)-Volumes und einigen Hardware-RAID-Konfigurationen kann XFS automatisch die optimalen Stripe-Parameter auswählen.
4. Überschreiben eines bestehenden Dateisystems mit dem XFS-Dateisystem
Das nächste Beispiel enthält die Ausgabe des Befehls mkfs.xfs. Das -f Option erzwingt das Überschreiben eines vorhandenen Dateisystemtyps. Das –L Option setzt die Dateisystembezeichnung auf „XFS “. Die -b size=1024 Option setzt die logische Blockgröße auf 1024 Byte.
# mkfs.xfs -f -L XFS -b size=1024 /dev/sdb
meta-data=/dev/sdb isize=512 agcount=4, agsize=5242880 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=0, sparse=0
data = bsize=1024 blocks=20971520, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal log bsize=1024 blocks=10240, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0 Die Ausgabe des Befehls mkfs.xfs verstehen
Die Ausgabe zeigt, dass ein XFS-Dateisystem aus bis zu drei Teilen besteht:
- ein Datenabschnitt
- ein Protokollabschnitt (Journal)
- ein Echtzeitabschnitt
Wenn Sie die Standardoptionen von mkfs.xfs verwenden, fehlt der Echtzeitabschnitt, und der Protokollbereich ist im Datenabschnitt enthalten. Der Benennungsbereich legt die Einstellungen für das Dateisystemverzeichnis fest.
Im Folgenden finden Sie einige zusätzliche Optionen für den Befehl mkfs.xfs:
- -b [Blockgröße] :Jeder Abschnitt des Dateisystems ist in eine bestimmte Anzahl von Blöcken unterteilt. Mit XFS können Sie die logische Blockgröße für jeden Abschnitt des Dateisystems auswählen. Die physischen Plattenblöcke sind immer 512 Bytes groß. Der Standardwert der logischen Blockgröße beträgt 4 KB. Dies ist die empfohlene Blockgröße für Dateisysteme größer als 100 MB. Der minimale logische Block beträgt 512 Bytes und wird für Dateisysteme kleiner als 100 MB und für Dateisysteme mit vielen kleinen Dateien empfohlen. Die maximale Blockgröße ist die Seitengröße des Kernels.
- -d [Datenabschnittsoptionen] :Diese Optionen geben den Speicherort, die Größe und andere Parameter des Datenabschnitts des Dateisystems an. Der Datenabschnitt des Dateisystems ist in Zuordnungsgruppen unterteilt, um die Leistung von XFS zu verbessern. Mehr Zuordnungsgruppen bedeuten, dass Sie beim Zuordnen von Blöcken und Inodes mehr Parallelität erreichen können. Verwenden Sie die Option – d agcount=[Wert], um die Anzahl der Zuordnungsgruppen auszuwählen. Die Standardanzahl der Zuordnungsgruppen ist 8, wenn das Dateisystem zwischen 128 MB und 8 GB groß ist. Alternativ können Sie die Option –d agsize=[Wert] verwenden, um die Größe der Zuordnungsgruppen auszuwählen. Die Parameter agcount und agsize schließen sich gegenseitig aus. Die Mindestgröße der Zuordnungsgruppe beträgt 16 MB; die maximale Größe liegt bei knapp 1 TB. Erhöhen Sie die Anzahl der Zuordnungsgruppen gegenüber dem Standardwert, wenn ausreichend Arbeitsspeicher und viele Zuordnungsaktivitäten vorhanden sind. Stellen Sie die Anzahl der Zuordnungsgruppen nicht zu hoch ein, da dies dazu führen kann, dass das Dateisystem viel CPU-Zeit verbraucht, insbesondere wenn das Dateisystem fast voll ist.
- -n [Namensoptionen] :Diese Optionen geben die Versions- und Größenparameter für das Dateisystemverzeichnis (oder den Benennungsbereich) an. Dadurch können Sie eine logische Blockgröße für das Dateisystemverzeichnis wählen, die größer ist als die logische Blockgröße des Dateisystems. Beispielsweise könnte in einem Dateisystem mit vielen kleinen Dateien die logische Blockgröße des Dateisystems klein (512 Byte) und die logische Blockgröße für das Dateisystemverzeichnis groß sein (4 KB). Dies kann die Leistung von Verzeichnissuchen verbessern, da der Baum, in dem die Indexinformationen gespeichert sind, größere Blöcke hat.