Hochverfügbarkeits-Cluster, auch bekannt als Failover-Cluster oder Aktiv-Passiv-Cluster, ist einer der am häufigsten verwendeten Cluster-Typen in einer Produktionsumgebung, um eine kontinuierliche Verfügbarkeit von Diensten zu gewährleisten, selbst wenn einer der Cluster-Knoten ausfällt.
Technisch gesehen, wenn die Anwendung auf dem Server aus irgendeinem Grund ausgefallen ist (z. B. Hardwarefehler), wird die Cluster-Software (Schrittmacher) die Anwendung auf dem funktionierenden Knoten neu starten.
Failover ist nicht nur das Neustarten einer Anwendung; es ist eine Reihe von Operationen, die damit verbunden sind, wie das Mounten von Dateisystemen, das Konfigurieren von Netzwerken und das Starten abhängiger Anwendungen.
Umgebung
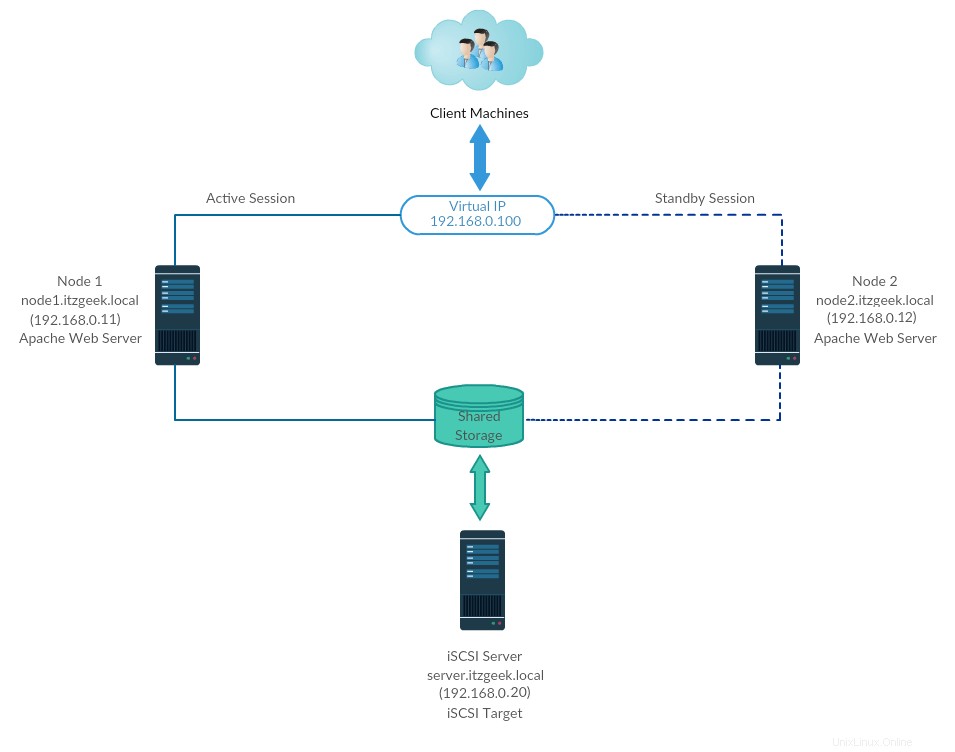
Hier konfigurieren wir einen Failover-Cluster mit Pacemaker, um den Apache (Web)-Server als hochverfügbare Anwendung zu machen.
Hier konfigurieren wir den Apache-Webserver, das Dateisystem und die Netzwerke als Ressourcen für unseren Cluster.
Für eine Dateisystemressource würden wir gemeinsam genutzten Speicher aus dem iSCSI-Speicher verwenden.
| Hostname |
|---|
Alle laufen auf VMware Workstation.
Gemeinsamer Speicher
Gemeinsam genutzter Speicher ist eine der kritischen Ressourcen im Hochverfügbarkeitscluster, da er die Daten einer laufenden Anwendung speichert. Alle Knoten in einem Cluster haben Zugriff auf den gemeinsam genutzten Speicher für die neuesten Daten.
SAN-Speicher ist der weit verbreitete gemeinsam genutzte Speicher in einer Produktionsumgebung. Aufgrund von Ressourcenbeschränkungen werden wir für diese Demo einen Cluster mit iSCSI-Speicher zu Demonstrationszwecken konfigurieren.
Pakete installieren
iSCSI-Server
[root@storage ~]# dnf install -y targetcli lvm2
Cluster-Knoten
dnf install -y iscsi-initiator-utils lvm2
Freigegebene Festplatte einrichten
Lassen Sie uns die verfügbaren Laufwerke im iSCSI-Server mit dem folgenden Befehl auflisten.
[root@storage ~]# fdisk -l | grep -i sd
Ausgabe:Festplatte/Dev/SDA:100 GIB, 107374182400 Bytes, 209715200 Sektoren/Dev/SDA1 * 2048 2099199 2097152 1G 83 Linux/Dev/SDA2 2099200 209715199 2076000 99G 8E2 Lvmdisk/Dev./DEVMDISK/DEVMDIK/DEVMDIK/DEVMDB:Bytes, 20971520 Sektoren
Aus der obigen Ausgabe können Sie ersehen, dass mein System eine 10-GB-Festplatte (/dev/sdb) hat.
Hier erstellen wir einen LVM auf dem iSCSI-Server, um ihn als gemeinsam genutzten Speicher für unsere Cluster-Knoten zu verwenden.
[root@storage ~]# pvcreate /dev/sdb
[root@storage ~]# vgcreate vg_iscsi /dev/sdb
[root@storage ~]# lvcreate -l 100%FREE -n lv_iscsi vg_iscsi
Gemeinsamen Speicher erstellen
Rufen Sie die Details des Knoteninitiators ab.
cat /etc/iscsi/initiatorname.iscsi
Knoten 1:
InitiatorName=iqn.1994-05.com.redhat:121c93cbad3a
Knoten 2:
InitiatorName=iqn.1994-05.com.redhat:827e5e8fecb
Geben Sie den folgenden Befehl ein, um eine iSCSI-CLI für eine interaktive Eingabeaufforderung zu erhalten.
[root@storage ~]# targetcli
Ausgabe:Warnung:Die Einstellungsdatei /root/.targetcli/prefs.bin.targetcli Shell-Version 2.1.fb49 konnte nicht geladen werdenCopyright 2011-2013 von Datera, Inc und anderen.Für Hilfe zu Befehlen geben Sie „help“ ein./> cd /backstores/block/backstores/block> create iscsi_shared_storage /dev/vg_iscsi/lv_iscsiCreated block storage object iscsi_shared_storage using /dev/vg_iscsi/lv_iscsi./backstores/block> cd /iscsi/iscsi> createCreated target iqn.2003-01.org .linux-iscsi.storage.x8664:sn.eac9425e5e18.Erstelltes TPG 1.Global pref auto_add_default_portal=trueErstelltes Standardportal, das alle IPs überwacht (0.0.0.0), Port 3260./iscsi> cd iqn.2003-01.org.linux -iscsi.storage.x8664:sn.eac9425e5e18/tpg1/acls <<Änderung gemäß der Ausgabe des vorherigen Befehls/iscsi/iqn.20...e18/tpg1/acls> create iqn.1994-05.com.redhat:121c93cbad3a <create iqn.1994-05.com.redhat:827e5e8fecb < cd /iscsi/iqn.2003-01.org.linux-iscsi.storage.x8664:sn.eac9425e5e18/tpg1/luns/iscsi/iqn.20. ..e18/tpg1/luns> create /backstores/block/iscsi_shared_storageCreated LUN 0.Created LUN 0->0-Mapping in Knoten-ACL iqn.1994-05.com.redhat:827e5e8fecbCreated LUN 0->0-Mapping in Knoten-ACL iqn. 1994-05.com.redhat:121c93cbad3a/iscsi/iqn.20...e18/tpg1/luns> cd //> lso- / ................... .................................................... .................................................... .. [...] o- backstores ........................................ .................................................... .................... [...] | o-Block .......................................... .................................................... [Speicherobjekte:1] | | o- iscsi_shared_storage .............................................. [ /dev/vg_iscsi/lv_iscsi (10.0GiB) Durchschreiben aktiviert] | | o- alua .................................................. .................................................... .. [ALUA-Gruppen:1] | | o- default_tg_pt_gp ......................................... ........................ [ALUA-Zustand:Aktiv/optimiert] | o- fileio .......................................... .................................................... [Speicherobjekte:0] | o-pscsi .......................................... .................................................... [Speicherobjekte:0] | o- Ramdisk .......................................... ................................................... [ Speicherobjekte:0] o-iscsi .......................................... .................................................... ................ [Ziele:1] | o-iqn.2003-01.org.linux-iscsi.storage.x8664:sn.eac9425e5e18 ............................. ................................ [TPGs:1] | o-tpg1 ............................................... ................................................ [nein -gen-acls, no-auth] | o-acls .......................................... .................................................... ......... [ACLs:2] | | o-iqn.1994-05.com.redhat:121c93cbad3a ..................................... ............................. [Zugeordnete LUNs:1] | | | o-mapped_lun0 .......................................... ................... [lun0 block/iscsi_shared_storage (rw)] | | o-iqn.1994-05.com.redhat:827e5e8fecb ..................................... ................................ [Zugeordnete LUNs:1] | | o-mapped_lun0 .......................................... ................... [lun0 block/iscsi_shared_storage (rw)] | o-luns .......................................... .................................................... ......... [LUNs:1] | | o- lun0 .......................................... [block/iscsi_shared_storage (/ dev/vg_iscsi/lv_iscsi) (default_tg_pt_gp)] | o- Portale .................................................. .................................................... ... [Portale:1] | o- 0.0.0.0:3260 .......................................... .................................................... ........ [OK] o- Loopback .................................... .................................................... ................... [Targets:0]/> saveconfigConfiguration gespeichert in /etc/target/saveconfig.json/> exitGlobal pref auto_save_on_exit=trueLetzte 10 Konfigurationen gespeichert in /etc /target/backup/.Configuration gespeichert in /etc/target/saveconfig.json
Aktivieren Sie den Target-Dienst und starten Sie ihn neu.
[root@storage ~]# systemctl enable target
[root@storage ~]# systemctl restart target
Konfigurieren Sie die Firewall, um iSCSI-Datenverkehr zuzulassen.
[root@storage ~]# firewall-cmd --permanent --add-port=3260/tcp
[root@storage ~]# firewall-cmd --reload
Freigegebenen Speicher entdecken
Ermitteln Sie auf beiden Cluster-Knoten das Ziel mit dem folgenden Befehl.
iscsiadm -m discovery -t st -p 192.168.0.20
Ausgabe:192.168.0.20:3260,1 qn.2003-01.org.linux-iscsi.storage.x8664:sn.eac9425e5e18
Melden Sie sich jetzt mit dem folgenden Befehl beim Zielspeicher an.
iscsiadm -m node -T iqn.2003-01.org.linux-iscsi.storage.x8664:sn.eac9425e5e18 -p 192.168.0.20 -l
Ausgabe:Anmeldung bei [iface:default, Ziel:iqn.2003-01.org.linux-iscsi.storage.x8664:sn.eac9425e5e18, Portal:192.168.0.20,3260]Anmeldung bei [iface:default, Ziel:iqn.2003-01.org.linux-iscsi.storage.x8664:sn.eac9425e5e18, Portal:192.168.0.20,3260] erfolgreich.
Starten Sie den Initiatordienst neu und aktivieren Sie ihn.
systemctl restart iscsid
systemctl enable iscsid
Cluster-Knoten einrichten
Gemeinsamer Speicher
Gehen Sie zu allen Ihren Cluster-Knoten und überprüfen Sie, ob die neue Festplatte vom iSCSI-Server sichtbar ist oder nicht.
In meinen Knoten ist /dev/sdb die freigegebene Festplatte aus dem iSCSI-Speicher.
fdisk -l | grep -i sd
Ausgabe:Festplatte/Dev/SDA:100 GIB, 107374182400 Bytes, 209715200 Sektoren/Dev/SDA1 * 2048 2099199 2097152 1G 83 Linux/Dev/SDA2 2099200 209715199 2076000 99g 8eux Lvmdisk/DEVMDIK/DEVMDISK/DEVIB:Bytes, 20963328 Sektoren
Erstellen Sie auf einem Ihrer Knoten (z. B. Knoten1) ein Dateisystem für den Apache-Webserver, um die Website-Dateien zu speichern. Wir werden ein Dateisystem mit LVM erstellen.
[root@node1 ~]# pvcreate /dev/sdb
[root@node1 ~]# vgcreate vg_apache /dev/sdb
[root@node1 ~]# lvcreate -n lv_apache -l 100%FREE vg_apache
[root@node1 ~]# mkfs.ext4 /dev/vg_apache/lv_apache
Gehen Sie nun zu einem anderen Knoten und führen Sie die folgenden Befehle aus, um das neue Dateisystem zu erkennen.
[root@node2 ~]# pvscan
[root@node2 ~]# vgscan
[root@node2 ~]# lvscan
Überprüfen Sie schließlich den LVM, den wir auf node1 erstellt haben steht Ihnen auf einem anderen Knoten (z. B. Knoten2) mit den folgenden Befehlen zur Verfügung.
ls -al /dev/vg_apache/lv_apache
und
[root@node2 ~]# lvdisplay /dev/vg_apache/lv_apache
Ausgabe:_Sie sollten /dev/vg_apache/lv_apache auf node2.itzgeek.local_ sehen --- Logisches Volume --- LV-Pfad /dev/vg_apache/lv_apache LV-Name lv_apache VG-Name vg_apache LV UUID gXeaoB-VlN1-zWSW- 2VnZ-RpmW-iDeC-kQOxZE LV Schreibzugriff lesen/schreiben LV Erstellungshost, Zeit node1.itzgeek.local, 2020-03-30 08:08:17 -0400 LV-Status NICHT verfügbar LV-Größe 9,96 GiB Aktuelle LE 2551 Segmente 1 Zuweisung Erben Sie Read-Ahead-Sektoren automatischWenn das System das logische Volume nicht anzeigt oder die Gerätedatei nicht gefunden wurde, sollten Sie den zweiten Knoten neu starten.
Hosteintrag
Machen Sie einen Host-Eintrag zu jedem Knoten auf allen Knoten. Der Cluster verwendet den Hostnamen, um miteinander zu kommunizieren.
vi /etc/hosts
Host-Einträge werden in etwa so aussehen.
192.168.0.11 node1.itzgeek.local node1
192.168.0.12 node2.itzgeek.local node2
Pakete installieren
Clusterpakete sind im Hochverfügbarkeits-Repository verfügbar. Konfigurieren Sie also das Hochverfügbarkeits-Repository auf Ihrem System.
CentOS 8
dnf config-manager --set-enabled HighAvailability
RHEL 8
Aktivieren Sie das Red Hat-Abonnement auf RHEL 8 und aktivieren Sie dann ein Hochverfügbarkeits-Repository, um Cluster-Pakete von Red Hat herunterzuladen.
subscription-manager repos --enable=rhel-8-for-x86_64-highavailability-rpms
Installieren Sie Cluster-Pakete (Pacemaker) mit allen verfügbaren Fence-Agenten auf allen Knoten mit dem folgenden Befehl.
dnf install -y pcs fence-agents-all pcp-zeroconf
Fügen Sie eine Firewall-Regel hinzu, um allen Hochverfügbarkeitsanwendungen die ordnungsgemäße Kommunikation zwischen den Knoten zu ermöglichen. Sie können diesen Schritt überspringen, wenn auf dem System keine Firewall aktiviert ist.
firewall-cmd --permanent --add-service=high-availability
firewall-cmd --add-service=high-availability
firewall-cmd --reload
Legen Sie ein Passwort für den Benutzer hacluster fest.
Dieses Benutzerkonto ist ein Clusterverwaltungskonto. Wir empfehlen Ihnen, für alle Knoten dasselbe Passwort festzulegen.
passwd hacluster
Starten Sie den Clusterdienst und aktivieren Sie ihn so, dass er beim Systemstart automatisch gestartet wird.
systemctl start pcsd
systemctl enable pcsd
Denken Sie daran:Sie müssen die obigen Befehle auf allen Ihren Cluster-Knoten ausführen.
Erstellen Sie einen Hochverfügbarkeitscluster
Autorisieren Sie die Knoten mit dem folgenden Befehl. Führen Sie den folgenden Befehl in einem der Knoten aus, um die Knoten zu autorisieren.
[root@node1 ~]# pcs host auth node1.itzgeek.local node2.itzgeek.local
Ausgabe:Benutzername:haclusterPassword:<Erstellen Sie einen Cluster. Ändern Sie den Namen des Clusters itzgeek_cluster gemäß Ihren Anforderungen.
[root@node1 ~]# pcs cluster setup itzgeek_cluster --start node1.itzgeek.local node2.itzgeek.localAusgabe:Keine Adressen für Host „node1.itzgeek.local“ angegeben, unter Verwendung von „node1.itzgeek.local“. Keine Adressen für Host „node2.itzgeek.local“ angegeben, unter Verwendung von „node2.itzgeek.local“. hosts:'node1.itzgeek.local', 'node2.itzgeek.local'...node1.itzgeek.local:Cluster erfolgreich zerstörtnode2.itzgeek.local:Cluster erfolgreich zerstörtRequesting remove 'pcsd settings' from 'node1.itzgeek.local' , 'node2.itzgeek.local'node1.itzgeek.local:erfolgreiches Entfernen der Datei 'pcsd settings'node2.itzgeek.local:erfolgreiches Entfernen der Datei 'pcsd settings' Senden von 'corosync authkey', 'pacemaker authkey' an ' node1.itzgeek.local', 'node2.itzgeek.local'node1.itzgeek.local:erfolgreiche Verteilung der Datei 'corosync authkey'node1.itzgeek.local:erfolgreiche Verteilung der Datei 'pacemaker authkey'node2.itzgeek.local:erfolgreiche Verteilung der Datei 'corosync authkey'node2.itzgeek.local:erfolgreiche Verteilung der Datei 'pacemaker authkey'Senden von 'corosync.conf' an 'node 1.itzgeek.local', 'node2.itzgeek.local'node1.itzgeek.local:erfolgreiche Verteilung der Datei 'corosync.conf'node2.itzgeek.local:erfolgreiche Verteilung der Datei 'corosync.conf' Cluster wurde erfolgreich durchgeführt einrichten.Cluster starten auf Hosts:'node1.itzgeek.local', 'node2.itzgeek.local'...Ermöglichen Sie dem Cluster, beim Systemstart zu starten.
[root@node1 ~]# pcs cluster enable --allAusgabe:node1.itzgeek.local:Cluster aktiviertnode2.itzgeek.local:Cluster aktiviertVerwenden Sie den folgenden Befehl, um den Status des Clusters abzurufen.
[root@node1 ~]# pcs cluster statusOutput:Cluster Status:Stack:corosync Aktueller DC:node1.itzgeek.local (Version 2.0.2-3.el8_1.2-744a30d655) – Partition mit Quorum Zuletzt aktualisiert:Mo 30. März 08:28:08 2020 Letzte Änderung:Mo 30. März 08:27:25 2020 von hacluster über crmd auf node1.itzgeek.local 2 Knoten konfiguriert 0 Ressourcen konfiguriertPCSD-Status:node1.itzgeek.local:Online node2.itzgeek.local:OnlineFühren Sie den folgenden Befehl aus, um detaillierte Informationen über den Cluster zu erhalten, einschließlich seiner Ressourcen, des Pacemaker-Status und der Knotendetails.
[root@node1 ~]# pcs statusOutput:Cluster name:itzgeek_clusterWARNINGS:No stonith devices and stonith-enabled is not falseStack:corosyncCurrent DC:node1.itzgeek.local (version 2.0.2-3.el8_1.2-744a30d655) – partition with quorumLast updated:Mo 30. März 08:33:37 2020Letzte Änderung:Mo 30. März 08:27:25 2020 von hacluster über crmd auf node1.itzgeek.local2 Knoten konfiguriert0 Ressourcen konfiguriertOnline:[node1.itzgeek.local node2.itzgeek.local]Keine RessourcenDaemon-Status:corosync:aktiv/aktiviert Pacemaker:aktiv/aktiviert pcsd:aktiv/aktiviertFechtgeräte
Das Fencing-Gerät ist ein Hardwaregerät, das hilft, den problematischen Knoten zu trennen, indem es den Knoten zurücksetzt / den gemeinsamen Speicher vom Zugriff trennt. Dieser Demo-Cluster wird auf VMware ausgeführt und muss kein externes Fence-Gerät einrichten. Sie können jedoch dieser Anleitung folgen, um ein Fechtgerät einzurichten.
Da wir kein Fechten verwenden, deaktivieren Sie es (STONITH). Sie müssen Fencing deaktivieren, um die Cluster-Ressourcen zu starten, aber das Deaktivieren von STONITH in der Produktionsumgebung wird nicht empfohlen.
[root@node1 ~]# pcs property set stonith-enabled=falseCluster-Ressourcen
Ressourcen vorbereiten
Apache-Webserver
Installieren Sie den Apache-Webserver auf beiden Knoten.
dnf install -y httpdBearbeiten Sie die Konfigurationsdatei.
vi /etc/httpd/conf/httpd.confFügen Sie den folgenden Inhalt am Ende der Datei auf beiden Cluster-Knoten hinzu.
<Location /server-status> SetHandler server-status Require local </Location>Bearbeiten Sie die Logrotate-Konfiguration des Apache-Webservers, um anzugeben, systemd nicht zu verwenden, da die Cluster-Ressource systemd nicht verwendet, um den Dienst neu zu laden.
Ändern Sie die folgende Zeile.
VON:
/bin/systemctl reload httpd.service > /dev/null 2>/dev/null || trueAN:
/usr/sbin/httpd -f /etc/httpd/conf/httpd.conf -c "PidFile /var/run/httpd.pid" -k graceful > /dev/null 2>/dev/null || trueJetzt verwenden wir den gemeinsamen Speicher zum Speichern der Webinhaltsdatei (HTML). Führen Sie den folgenden Vorgang in einem der Knoten aus.
[root@node1 ~]# mount /dev/vg_apache/lv_apache /var/www/ [root@node1 ~]# mkdir /var/www/html [root@node1 ~]# mkdir /var/www/cgi-bin [root@node1 ~]# mkdir /var/www/error [root@node1 ~]# restorecon -R /var/www [root@node1 ~]# cat <<-END >/var/www/html/index.html <html> <body>Hello, Welcome!. This Page Is Served By Red Hat Hight Availability Cluster</body> </html> END [root@node1 ~]# umount /var/wwwApache-Dienst in der Firewall auf beiden Knoten zulassen.
firewall-cmd --permanent --add-service=http firewall-cmd --reloadRessourcen erstellen
Erstellen Sie eine Dateisystemressource für den Apache-Server. Verwenden Sie den Speicher, der vom iSCSI-Server kommt.
[root@node1 ~]# pcs resource create httpd_fs Filesystem device="/dev/mapper/vg_apache-lv_apache" directory="/var/www" fstype="ext4" --group apacheAusgabe:Angenommener Agentenname 'ocf:`heartbeat`:Filesystem' (abgeleitet von 'Filesystem')Erstellen Sie eine IP-Adressressource. Diese IP-Adresse fungiert als virtuelle IP-Adresse für den Apache, und Clients verwenden diese IP-Adresse für den Zugriff auf den Webinhalt anstelle der IP eines einzelnen Knotens.
[root@node1 ~]# pcs resource create httpd_vip IPaddr2 ip=192.168.0.100 cidr_netmask=24 --group apacheAusgabe:Angenommener Agentenname 'ocf:`heartbeat`:IPaddr2' (abgeleitet von 'IPaddr2')Erstellen Sie eine Apache-Ressource, um den Status des Apache-Servers zu überwachen, der die Ressource im Falle eines Fehlers auf einen anderen Knoten verschiebt.
[root@node1 ~]# pcs resource create httpd_ser apache configfile="/etc/httpd/conf/httpd.conf" statusurl="http://127.0.0.1/server-status" --group apacheAusgabe:Angenommener Agentenname 'ocf:`heartbeat`:apache' (abgeleitet von 'apache')Überprüfen Sie den Status des Clusters.
[root@node1 ~]# pcs statusAusgabe:Clustername:itzgeek_clusterStack:corosyncAktueller DC:node1.itzgeek.local (Version 2.0.2-3.el8_1.2-744a30d655) - Partition mit QuorumZuletzt aktualisiert:Mo 30. März 09:02:07 2020Letzte Änderung:Mo 30. März 09:01:46 2020 von root über cibadmin auf node1.itzgeek.local2 Knoten konfiguriert3 Ressourcen konfiguriertOnline:[node1.itzgeek.local node2.itzgeek.local]Vollständige Liste der Ressourcen:Ressourcengruppe:apache httpd_fs (ocf:💓Filesystem ):Gestartet node1.itzgeek.local httpd_vip (ocf:💓IPaddr2):Gestartet node1.itzgeek.local httpd_ser (ocf:💓apache):Gestartet node1.itzgeek.localDaemon Status:corosync:aktiv/aktiviert Pacemaker:aktiv/aktiviert pcsd:aktiv/aktiviertHochverfügbarkeitscluster überprüfen
Sobald der Cluster betriebsbereit ist, verweisen Sie einen Webbrowser auf die virtuelle IP-Adresse von Apache. Sie sollten eine Webseite wie unten sehen.
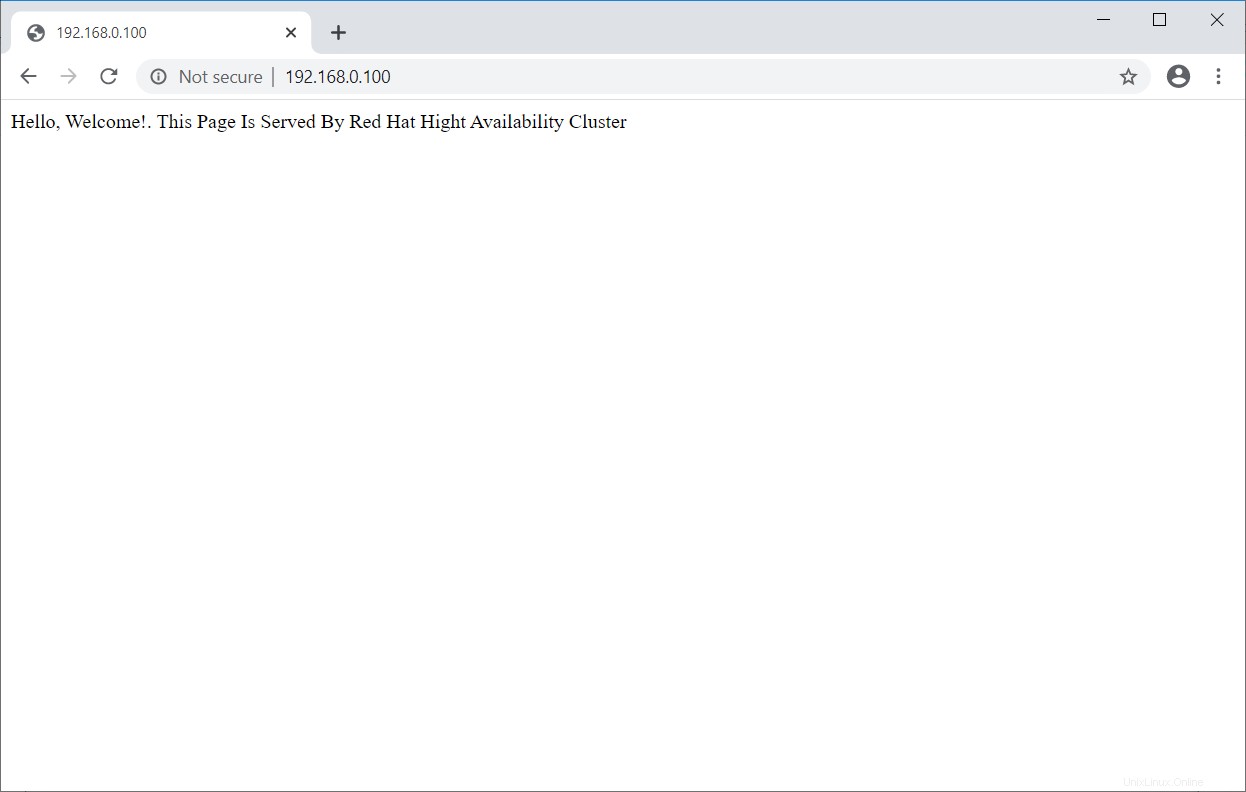
Hochverfügbarkeitscluster testen
Lassen Sie uns das Failover der Ressourcen überprüfen, indem wir den aktiven Knoten (auf dem alle Ressourcen ausgeführt werden) in den Standby-Modus versetzen.
[root@node1 ~]# pcs node standby node1.itzgeek.localWichtige Cluster-Befehle
Cluster-Ressourcen auflisten:
pcs resource statusCluster-Ressource neu starten:
pcs resource restart <resource_name>Verschieben Sie die Ressource von einem Knoten:
pcs resource move <resource_group> <destination_node_name>Cluster in Wartung versetzen:
pcs property set maintenance-mode=trueCluster aus der Wartung entfernen:
pcs property set maintenance-mode=falseStarten Sie den Cluster-Knoten:
pcs cluster start <node_name>Cluster-Knoten stoppen:
pcs cluster stop <node_name>Cluster starten:
pcs cluster start --allCluster stoppen:
pcs cluster stop --allCluster zerstören:
pcs cluster destroy <cluster_name>Cluster-Web-Benutzeroberfläche
Die pcsd-Webbenutzeroberfläche unterstützt Sie beim Erstellen, Konfigurieren und Verwalten von Pacemaker-Clustern.
Auf die Webschnittstelle kann zugegriffen werden, sobald Sie den pcsd-Dienst auf dem Knoten gestartet haben, und sie ist auf Portnummer 2224 verfügbar.
https://Knotenname:2224Melden Sie sich mit dem Cluster-Verwaltungsbenutzer hacluster und seinem Passwort an.
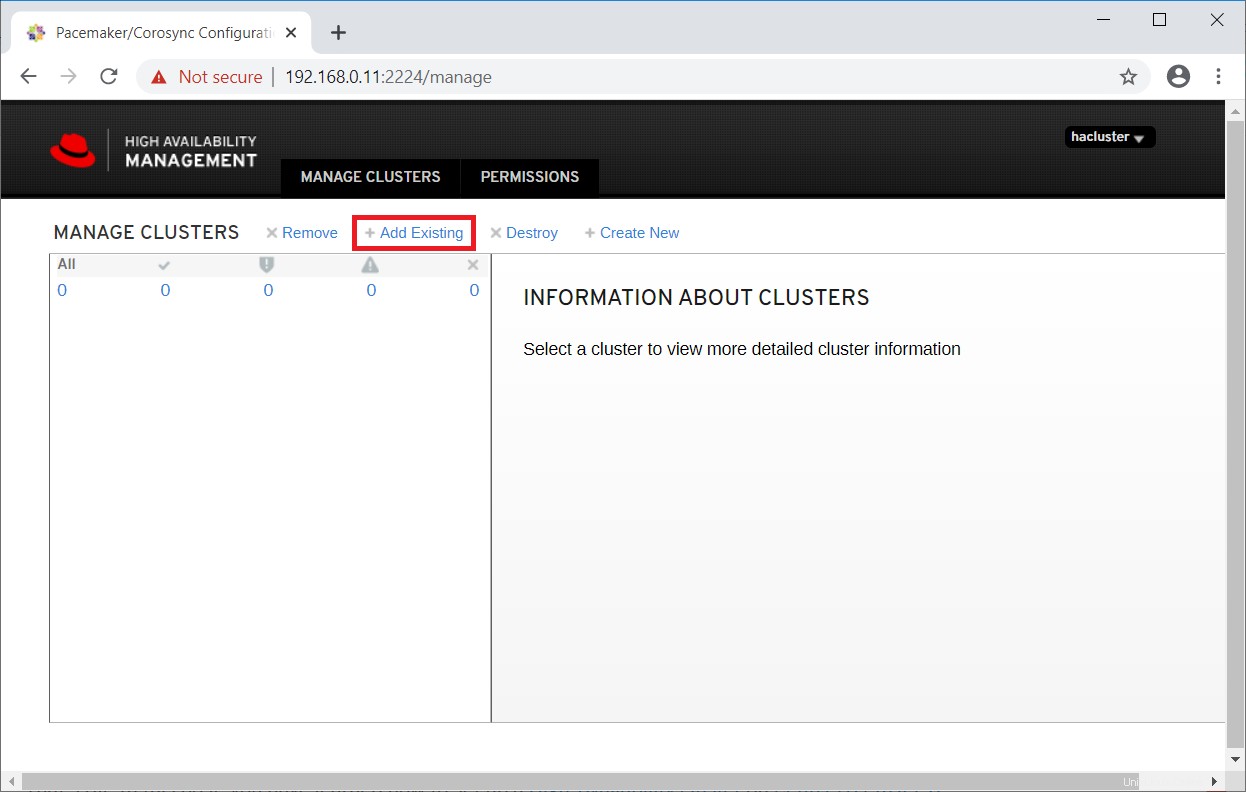
Da wir bereits einen Cluster haben, klicken Sie auf Add Existing, um den vorhandenen Pacemaker-Cluster hinzuzufügen. Falls Sie einen neuen Cluster einrichten möchten, können Sie die offizielle Dokumentation lesen.
Geben Sie einen beliebigen Cluster-Knoten ein, um einen vorhandenen Cluster zu erkennen.
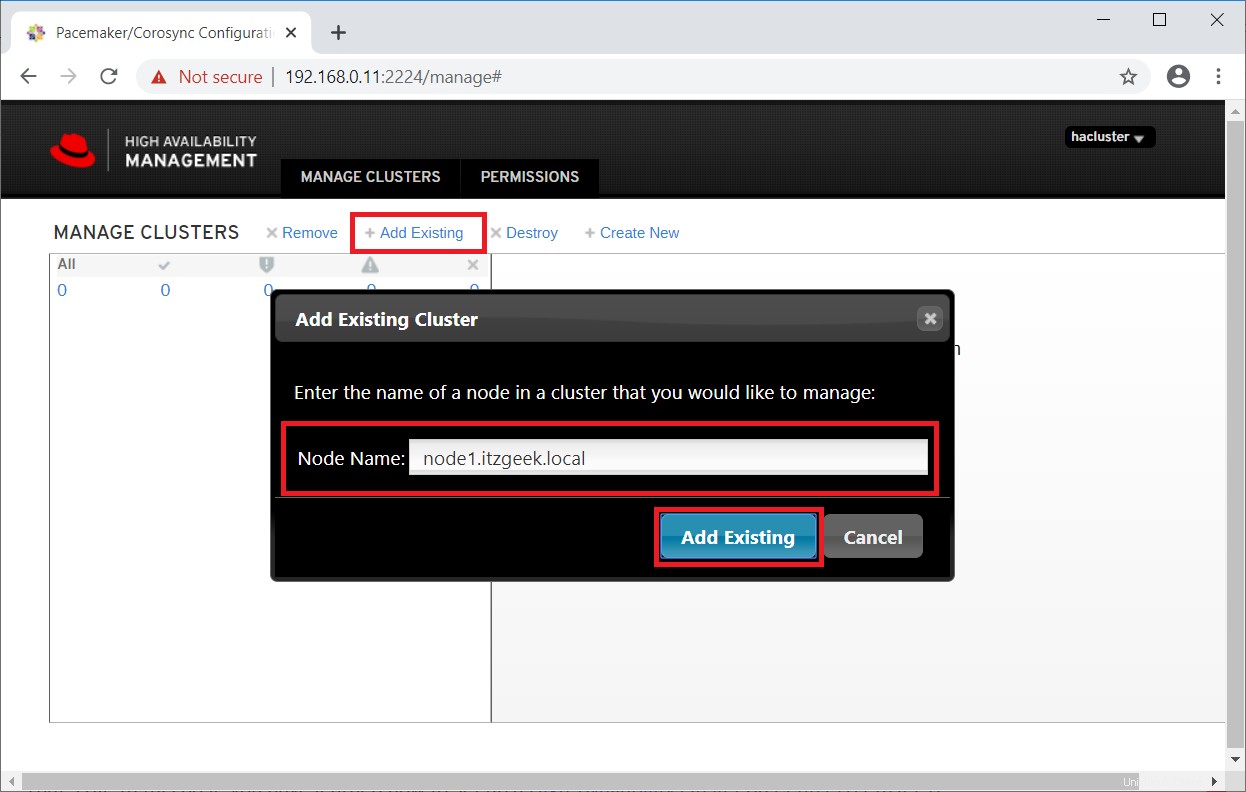
In ein oder zwei Minuten sehen Sie Ihren vorhandenen Cluster in der Webbenutzeroberfläche.
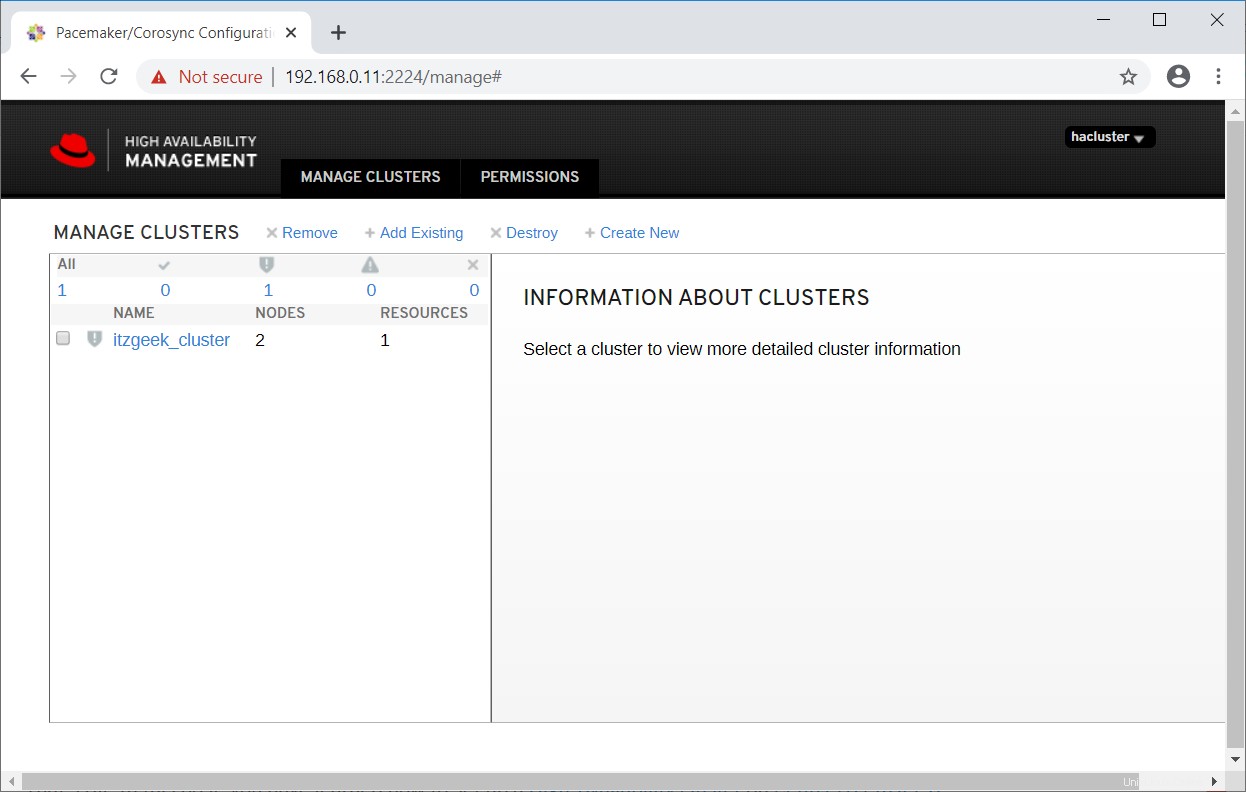
Wählen Sie den Cluster aus, um mehr über die Clusterinformationen zu erfahren.
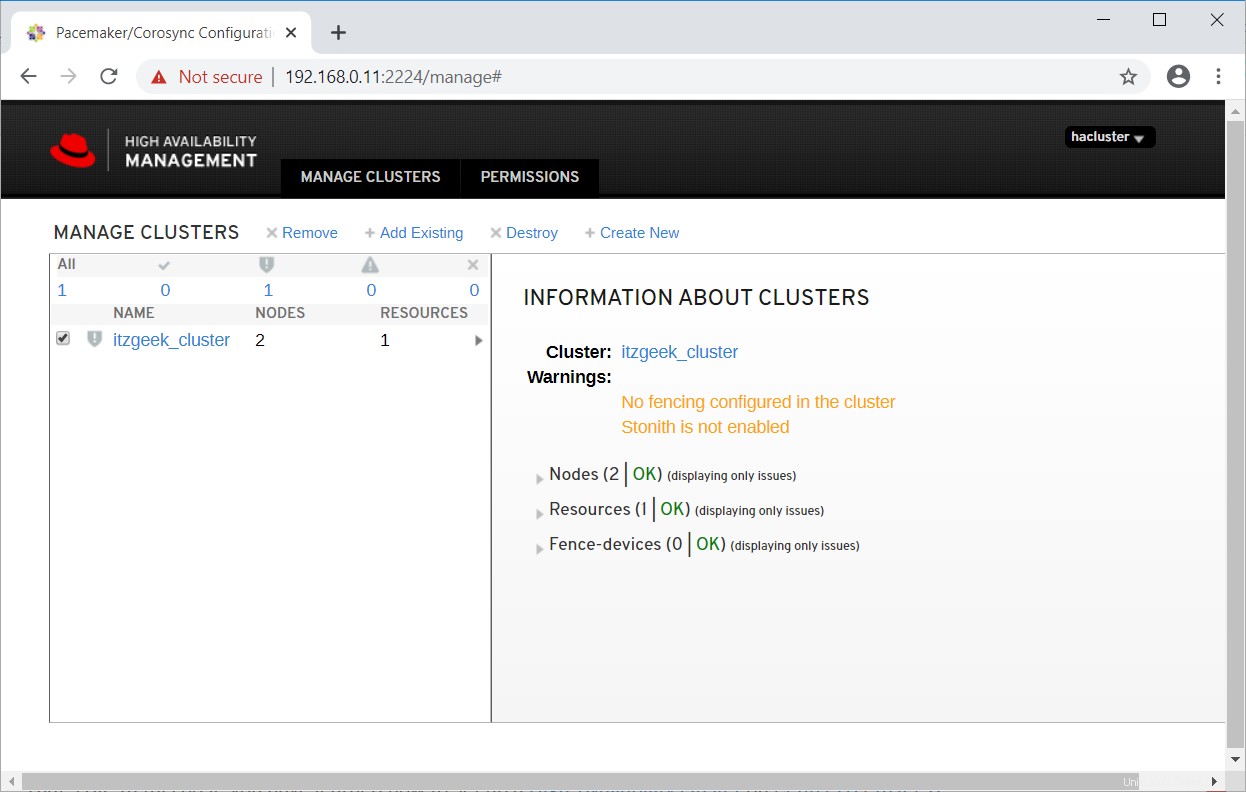
Klicken Sie auf den Clusternamen, um die Details des Knotens anzuzeigen.
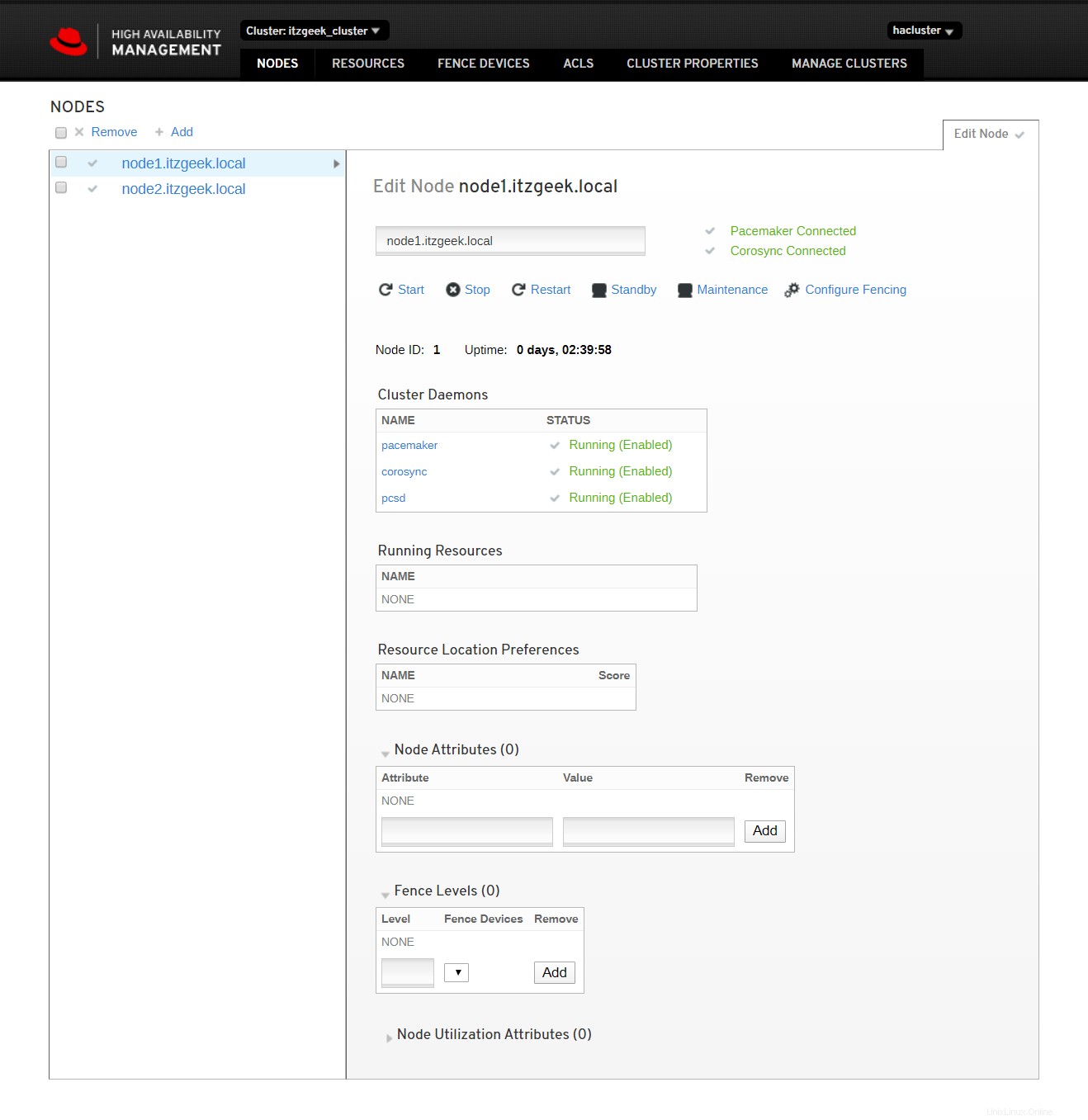
Klicken Sie auf Cluster-Ressourcen, um die Liste der Ressourcen und ihre Details anzuzeigen.
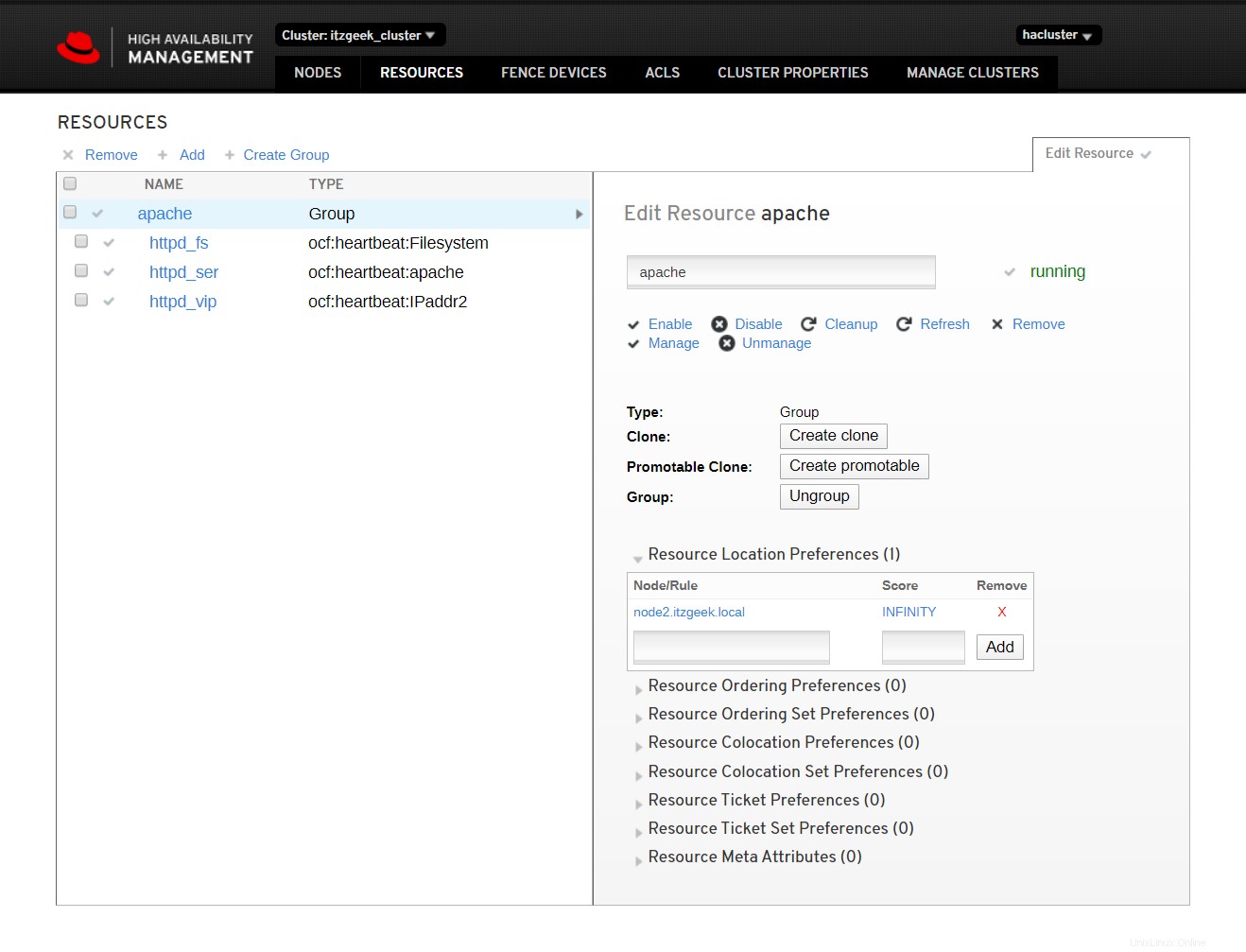
Referenz :Red Hat-Dokumentation.
Schlussfolgerung
Das ist alles. In diesem Beitrag haben Sie gelernt, wie Sie einen High-Availability-Cluster unter CentOS 8 / RHEL 8 einrichten.