Als Systemadministrator ist es zwingend erforderlich, Hochverfügbarkeit auf allen möglichen Ebenen in der Architektur und im Design eines Systems zu ermöglichen, und die SAP-Umgebung ist nicht anders. In diesem Artikel erläutere ich, wie Sie Red Hat Enterprise Linux (RHEL) Pacemaker für Hochverfügbarkeit (HA) von SAP NetWeaver Advanced Business Application Programming (ABAP) SAP Central Service (ASCS)/Enqueue Replication Server (ERS) nutzen können.
[Das könnte Ihnen auch gefallen: Schnellstartanleitung für Ansible für Linux-Systemadministratoren]
SAP hat eine dreischichtige Architektur:
- Präsentationsebene – Präsentiert eine GUI für die Interaktion mit der SAP-Anwendung
- Anwendungsschicht – Enthält einen oder mehrere Anwendungsserver und einen Nachrichtenserver
- Datenbankschicht —Enthält die Datenbank mit allen SAP-bezogenen Daten (z. B. Oracle)
In diesem Artikel liegt der Schwerpunkt auf der Anwendungsschicht. Anwendungsserverinstanzen stellen die eigentlichen Datenverarbeitungsfunktionen eines SAP-Systems bereit. Basierend auf den Systemanforderungen werden mehrere Anwendungsserver erstellt, um die Last auf dem SAP-System zu bewältigen. Eine weitere Hauptkomponente in der Anwendungsschicht ist der ABAP SAP Central Service (ASCS). Die zentralen Dienste bestehen aus zwei Hauptkomponenten – Message Server (MS) und Enqueue Server (ES). Der Message Server fungiert als Kommunikationskanal zwischen allen Applikationsservern und übernimmt die Lastverteilung. Der Enqueue-Server steuert den Sperrmechanismus.
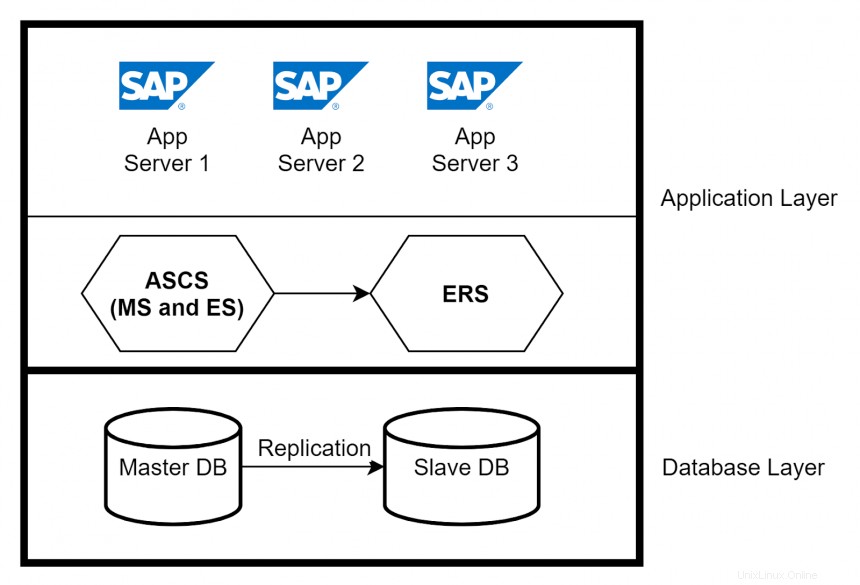
Hohe Verfügbarkeit in Anwendungs- und Datenbankschichten
Sie können Hochverfügbarkeit für Anwendungsserver implementieren, indem Sie einen Load Balancer verwenden und mehrere Anwendungsserver die Anforderungen von Benutzern verarbeiten lassen. Wenn ein Anwendungsserver abstürzt, sind nur die mit diesem Server verbundenen Benutzer betroffen. Isolieren Sie den Absturz, indem Sie den Anwendungsserver aus dem Load-Balancer entfernen. Verwenden Sie für eine hohe Verfügbarkeit von ASCS den Enqueue Replication Server (ERS), um die Sperrtabelleneinträge zu replizieren. Auf der Datenbankebene können Sie eine native Datenbankreplikation zwischen primären und sekundären Datenbanken einrichten, um eine hohe Verfügbarkeit sicherzustellen.
Einführung in RHEL High Availability mit Pacemaker
RHEL High Availability ermöglicht Diensten ein nahtloses Failover von einem Knoten zu einem anderen innerhalb eines Clusters, ohne dass der Dienst unterbrochen wird. ASCS und ERS können in einen RHEL Pacemaker-Cluster integriert werden. Im Falle eines Ausfalls eines ASCS-Knotens werden die Clusterpakete auf einen ERS-Knoten verschoben, wo die MS- und ES-Instanzen weiter ausgeführt werden, ohne das System zum Stillstand zu bringen. Im Falle eines ERS-Knotenausfalls ist das System nicht betroffen, da MS und ES weiterhin auf dem ASCS-Knoten ausgeführt werden. In diesem Fall wird die ERS-Instanz nicht auf dem ASCS-Knoten ausgeführt, da ES- und ERS-Instanzen nicht auf demselben Knoten ausgeführt werden müssen.
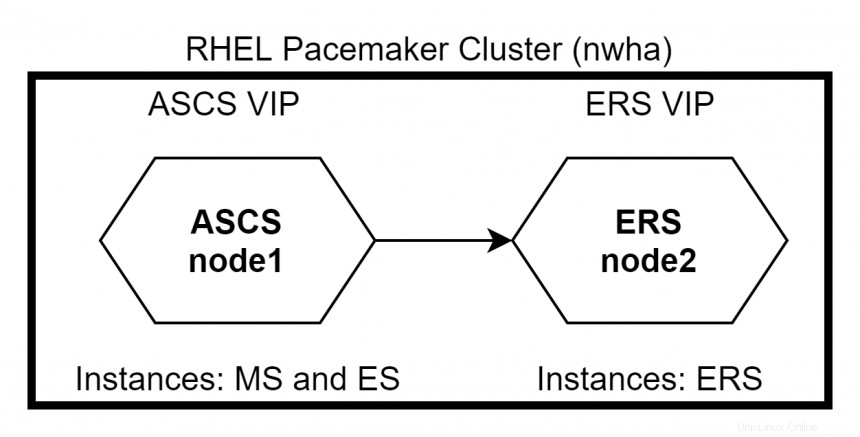
RHEL Pacemaker-Konfiguration
Es gibt zwei Möglichkeiten, ASCS- und ERS-Knoten im RHEL Pacemaker-Cluster zu konfigurieren – Primär/Sekundär und Eigenständig . Die Primär/Sekundär Ansatz wird in allen Nebenversionen von RHEL 7 unterstützt. Der eigenständige Ansatz wird in RHEL 7.5 und höher unterstützt. RHEL empfiehlt die Verwendung des eigenständigen Ansatzes für alle neuen Bereitstellungen.
Clusterkonfiguration
Die groben Schritte für die Clusterkonfiguration umfassen:
- Installieren Sie Pacemaker-Pakete auf beiden Knoten des Clusters.
# yum -y install pcs pacemaker - Erstellen Sie den HACLUSTER Benutzerkennung mit.
Um# passwd haclusterpcszu verwenden Um den Cluster zu konfigurieren und zwischen den Knoten zu kommunizieren, müssen Sie auf jedem Knoten ein Passwort für die Benutzer-ID hacluster festlegen , das sind diepcsVerwaltungskonto. Es wird empfohlen, das Passwort für den Benutzer hacluster auf jedem Knoten gleich sein. - Aktiviere und starte die
pcsDienstleistungen.# systemctl enable pcsd.service; systemctl start pcsd.service - Authentifizieren Sie
pcsmit Hacluster user
Authentifizieren Sie diepcsBenutzer hacluster für jeden Knoten im Cluster. Der folgende Befehl authentifiziert den Benutzer hacluster auf Knoten1 für beide Knoten in einem Zwei-Knoten-Cluster (node1.example.com und node2.example.com).# pcs cluster auth node1.example.com node2.example.com Username: hacluster Password: node1.example.com: Authorized node2.example.com: Authorized - Cluster erstellen.
Cluster nwha wird mit node1 und node2 erstellt:# pcs cluster setup --name nwha node1 node2 - Starten Sie den Cluster.
# pcs cluster start --all - Aktivieren Sie den automatischen Start des Clusters nach dem Neustart.
# pcs cluster enable --all
Ressourcen für ASCS- und ERS-Instanzen erstellen
Nachdem der Cluster eingerichtet ist, müssen Sie die Ressourcen für ASCS- und ERS-Knoten hinzufügen. Zu den groben Schritten gehören:
- Installieren Sie
resource-agents-sapauf allen Clusterknoten.# yum install resource-agents-sap - Gemeinsam genutztes Dateisystem als vom Cluster verwaltete Ressourcen konfigurieren.
Das gemeinsam genutzte Dateisystem, z. B./sapmnt,/usr/sap/trans,/usr/sap/werden als Ressourcen hinzugefügt, die mit dem folgenden Befehl automatisch auf dem Cluster gemountet werden:SYS # pcs resource create <resource-name> Filesystem device=’<path-of-filesystem>’ directory=’<directory-name>’ fstype=’<type-of-fs>’
Beispiel:# pcs resource create sid_fs_sapmnt Filesystem device='nfs_server:/export/sapmnt' directory='/sapmnt' fstype='nfs' - Ressourcengruppe für ASCS konfigurieren.
Für den ASCS-Knoten lauten die drei erforderlichen Ressourcengruppen wie folgt (vorausgesetzt, die Instanz-ID von ASCS ist 00):- Virtuelle IP-Adresse für den ASCS
- ASCS-Dateisystem (zum Beispiel
/usr/sap/<SID>/ASCS00) - ASCS-Profilinstanz (z. B.
/sapmnt/<SID>/profile/<SID>_ASCS00_<hostname>)
- Ressourcengruppe für ERS konfigurieren.
Für den ERS-Knoten lauten die drei erforderlichen Ressourcengruppen wie folgt (unter der Annahme der Instanz-ID von ERS in 30):- Virtuelle IP-Adresse für das ERS
- ERS-Dateisystem (zum Beispiel
/usr/sap/<SID>/ERS30) - ERS-Profilinstanz (z. B.
/sapmnt/<SID>/profile/<SID>_ERS30_<hostname>)
- Erstellen Sie die Einschränkungen.
Legen Sie die ASCS- und ERS-Ressourcengruppeneinschränkungen für Folgendes fest:- Beschränken Sie die Ausführung beider Ressourcengruppen auf demselben Knoten
- Lassen Sie ASCS bei einem Failover auf dem Knoten laufen, auf dem ERS ausgeführt wurde
- Start-/Stopp-Reihenfolge beibehalten
- Stellen Sie sicher, dass der Cluster erst gestartet wird, nachdem die erforderlichen Dateisysteme gemountet wurden
Cluster-Failover-Tests
Angenommen, ASCS läuft auf node1 und ERS wird auf node2 ausgeführt anfänglich. Wenn Knoten1 ausfällt, wechseln sowohl ASCS als auch ERS zu node2 . Aufgrund der definierten Einschränkung wird ERS nicht auf node2 ausgeführt .
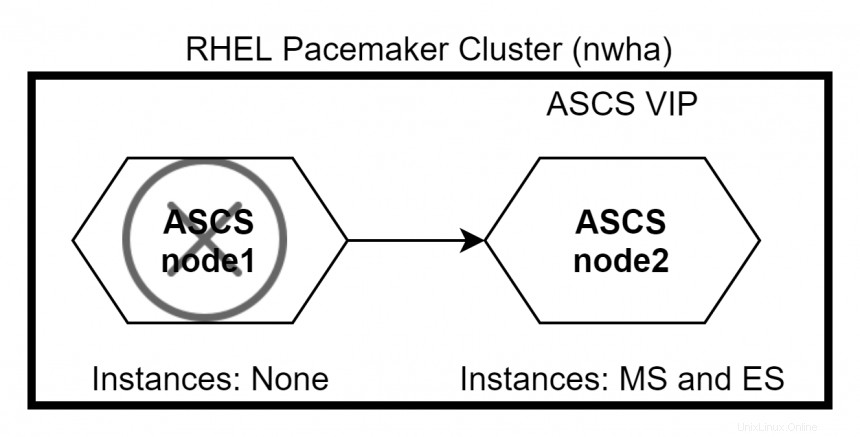
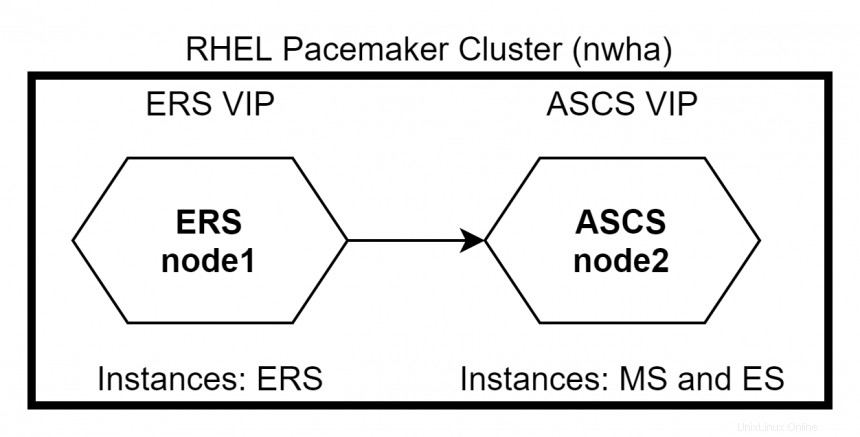
Wenn Knoten1 wieder hochkommt, wechselt ERS zu node1 während ASCS auf node2 verbleibt . Verwenden Sie den Befehl #pcs status um den Status des Clusters zu überprüfen.
[ Ein kostenloser Kurs für Sie:Virtualization and Infrastructure Migration Technical Overview. ]
Schluss machen
RHEL Pacemaker ist ein großartiges Dienstprogramm, um einen hochverfügbaren Cluster für SAP zu erreichen. Sie können auch Fencing durchführen, indem Sie STONITH konfigurieren, um die Datenintegrität sicherzustellen und die Ressourcennutzung durch einen fehlerhaften Knoten im Cluster zu vermeiden.
Für alle Automatisierungsbegeisterten können Sie Ansible verwenden, um Ihren Pacemaker-Cluster zu steuern, indem Sie das Ansible-Modul pacemaker_cluster verwenden. So sehr Sie Ihre Systeme schützen, passen Sie auf sich auf und bleiben Sie sicher.