Kdump ist eine Kernel-Funktion, die verwendet wird, um Crash-Dumps zu erfassen, wenn das System oder der Kernel abstürzt. Um kdump zu aktivieren, müssen wir einen Teil des physischen Arbeitsspeichers reservieren, der verwendet wird, um den kdump-Kernel im Falle einer Kernel-Panik oder eines Absturzes auszuführen.
Wenn ein Kernel-Absturz oder eine Kernel-Panik auftritt, wird beim Ausführen des Kernels ‘kexec(kdump kernel) ausgeführt ‘ und es lädt den kdump-Kernel aus dem Reservespeicher und dann wird der Inhalt von RAM und Swap in die vmcore-Datei entweder auf der lokalen Festplatte oder auf der Remote-Festplatte kopiert und schließlich die Box neu gestartet.
Durch die Analyse der Crash-Dumps können wir den Grund oder die Wurzel des Systemausfalls finden. Wenn Sie OS-Support haben, können Sie die Crash-Dumps zur Analyse an den Anbieter weitergeben.
In diesem Artikel zeigen wir, wie Sie kdump auf RHEL 7 und CentOS 7 aktivieren
Schritt:1 Installieren Sie „kexec-tools“ mit dem Befehl yum
Verwenden Sie den folgenden yum-Befehl, um das Paket „kexec-tools“ zu installieren, falls es nicht installiert ist.
[[email protected] ~]# yum install kexec-tools
Schritt:2 Aktualisieren Sie die GRUB2-Datei, um Speicher für den Kdump-Kernel zu reservieren
Bearbeiten Sie die GRUB2-Datei (/etc/default/grub ), fügen Sie den Parameter „crashkernel=
GRUB_CMDLINE_LINUX="rd.lvm.lv=centos/swap vconsole.font=latarcyrheb-sun16 rd.lvm.lv=centos/root crashkernel=128M vconsole.keymap=us rhgb quiet"

Führen Sie den folgenden Befehl aus, um die Grub2-Konfiguration neu zu generieren.
[[email protected] ~]# grub2-mkconfig -o /boot/grub2/grub.cfg
Im Fall von UEFI-Firmware verwenden Sie den folgenden Befehl
[[email protected] ~]# grub2-mkconfig -o /boot/efi/EFI/redhat/grub.cfg
Der obige Befehl informiert den Bootlaoder, nach dem Neustart 128 MB RAM zu reservieren.
Starten Sie die Box jetzt mit dem folgenden Befehl neu:
[[email protected] ~]# shutdown -r now
Schritt:3 Aktualisieren Sie den Dump-Speicherort und die Standardaktion in der Datei (/etc/kdump.conf)
Um eine Crash-Dump- oder vmcore-Datei auf einem lokalen Dateisystem zu speichern, bearbeiten Sie die Datei „/etc/kdump.conf ‘ und geben Sie den Speicherort gemäß Ihrer Einrichtung an. In meinem Fall verwende ich ein separates lokales Dateisystem ( /var/crash ). Es wird empfohlen, dass die Größe des Dateisystems der Größe des Arbeitsspeichers Ihres Systems entspricht oder dass das Dateisystem über freien Speicherplatz verfügt, der der Größe des Arbeitsspeichers entspricht. Kdump ermöglicht das Komprimieren der Dump-Daten mit der Option „Core Collector“ (core_collector makedumpfile -c ), wobei -c für die Komprimierung verwendet wird.
Falls kdump die Dump-Datei nicht am angegebenen Ort speichern kann, wird die Standardaktion ausgeführt, die in der Standarddirektive erwähnt wird. In meinem Fall ist die Standardaktion Neustart.
Aktualisieren Sie die folgenden drei Anweisungen in der Datei kdump.conf.
[[email protected] ~]# vi /etc/kdump.conf path /var/crash core_collector makedumpfile -c default reboot
Verschiedene Optionen zum Speichern von Dumps:
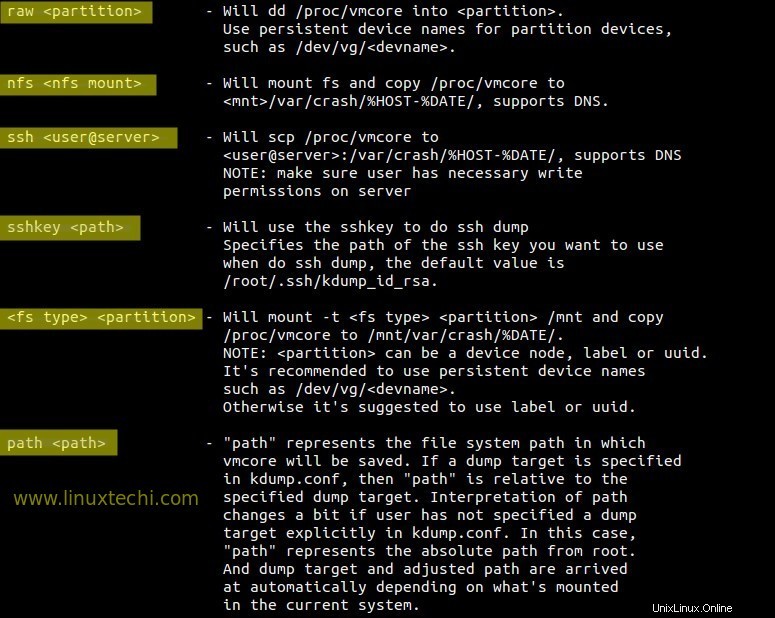
Schritt:4 Starten und aktivieren Sie den kdump-Dienst
[[email protected] ~]# systemctl start kdump.service [[email protected] ~]# systemctl enable kdump.service [[email protected] ~]#
Schritt:5 Testen Sie jetzt Kdump, indem Sie das System manuell zum Absturz bringen
Bevor Sie Ihr System zum Absturz bringen, überprüfen Sie bitte mit dem folgenden Befehl, ob der kdump-Dienst ausgeführt wird oder nicht.
[[email protected] crash]# systemctl is-active kdump.service [[email protected] crash]# service kdump status
Um unsere kdump-Konfiguration zu testen, werden wir unser System mit den folgenden Befehlen manuell zum Absturz bringen.
[[email protected] ~]# echo 1 > /proc/sys/kernel/sysrq ; echo c > /proc/sysrq-trigger
Dadurch wird eine Crash-Dump-Datei (vmcore ) unter „/var/crash ‘ Dateisystem.
[[email protected] ~]# ls -lR /var/crash /var/crash: total 0 drwxr-xr-x. 2 root root 42 Mar 4 03:02 127.0.0.1-2016-03-04-03:02:17 /var/crash/127.0.0.1-2016-03-04-03:02:17: total 135924 -rw-------. 1 root root 139147524 Mar 4 03:02 vmcore -rw-r--r--. 1 root root 35640 Mar 4 03:02 vmcore-dmesg.txt [[email protected] ~]#
Schritt:6 Verwenden Sie den Befehl „crash“, um Crash-Dumps zu analysieren und zu debuggen
Crash ist das Dienstprogramm oder der Befehl zum Debuggen und Analysieren der Crash-Dump- oder vmcore-Datei.
Um den Absturz zu verwenden, stellen Sie sicher, dass zwei Pakete installiert sind:„crash &kernel-debuginfo ‘
[[email protected] ~]# yum install crash
Um das Paket „kernel-debuginfo“ zu installieren, aktivieren Sie zuerst das Debug-Repo. Bearbeiten Sie die Repo-Datei /etc/yum.repos.d/CentOS-Debuginfo.repo
Ändern Sie „enbled=0“ in „enabled=1“
[[email protected] ~]# yum install kernel-debuginfo
Sobald die Kernel-Debuginfo installiert ist, versuchen Sie, den folgenden Crash-Befehl auszuführen. Er gibt uns eine Crash-Eingabeaufforderung, an der wir Befehle ausführen können, um Prozessinformationen und eine Liste offener Dateien zu finden, wenn das System abgestürzt ist.
[[email protected] ~]# crash /var/crash/127.0.0.1-2016-03-04-14\:20\:06/vmcore /usr/lib/debug/lib/modules/`uname -r`/vmlinux crash>
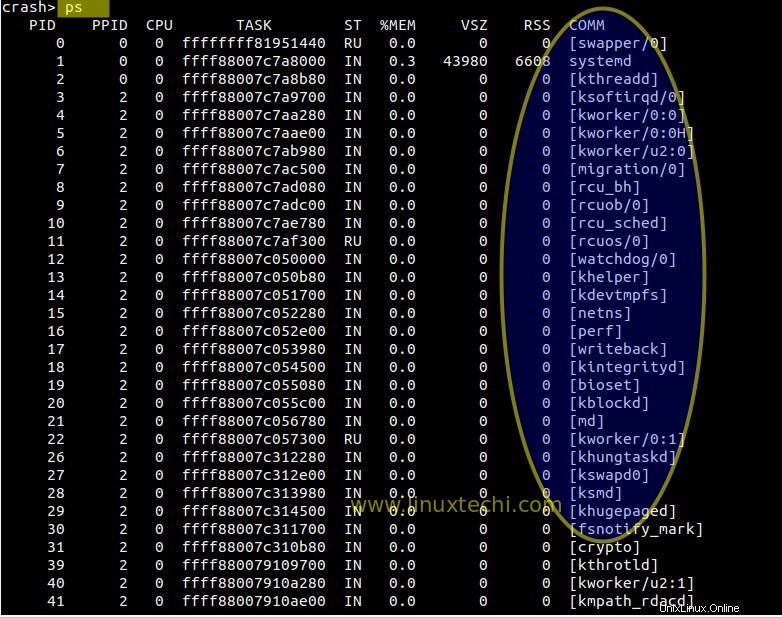
Geben Sie „ps ein ‘ Befehl, um die Prozesse aufzulisten, die ausgeführt wurden, als das System abstürzte.
crash> ps
Um die Dateien anzuzeigen, die geöffnet waren, als das System abstürzte, geben Sie den Befehl „Dateien“ an der Absturz-Eingabeaufforderung ein.
crash> files PID: 5577 TASK: ffff88007b44f300 CPU: 0 COMMAND: "bash" ROOT: / CWD: /root FD FILE DENTRY INODE TYPE PATH 0 ffff880036b85000 ffff8800796fa540 ffff88007966f4d0 CHR /dev/pts/0 1 ffff880036b73900 ffff880068c409c0 ffff8800794a8d10 REG /proc/sysrq-trigger 2 ffff880036b85000 ffff8800796fa540 ffff88007966f4d0 CHR /dev/pts/0 10 ffff880036b85000 ffff8800796fa540 ffff88007966f4d0 CHR /dev/pts/0 255 ffff880036b85000 ffff8800796fa540 ffff88007966f4d0 CHR /dev/pts/0 crash>
Geben Sie Befehl „sys“ ein um die Systeminformationen aufzulisten, wenn es abgestürzt ist.
crash> sys KERNEL: /usr/lib/debug/lib/modules/3.10.0-327.10.1.el7.x86_64/vmlinux DUMPFILE: /var/crash/127.0.0.1-2016-03-04-14:20:06/vmcore CPUS: 1 DATE: Fri Mar 4 14:20:01 2016 UPTIME: 00:02:00 LOAD AVERAGE: 0.75, 0.48, 0.19 TASKS: 115 NODENAME: cloud.linuxtechi.com RELEASE: 3.10.0-327.10.1.el7.x86_64 VERSION: #1 SMP Tue Feb 16 17:03:50 UTC 2016 MACHINE: x86_64 (2388 Mhz) MEMORY: 2 GB PANIC: "SysRq : Trigger a crash" crash>
Um Hilfe zu einem beliebigen Befehl an der Absturz-Eingabeaufforderung zu erhalten, geben Sie „help
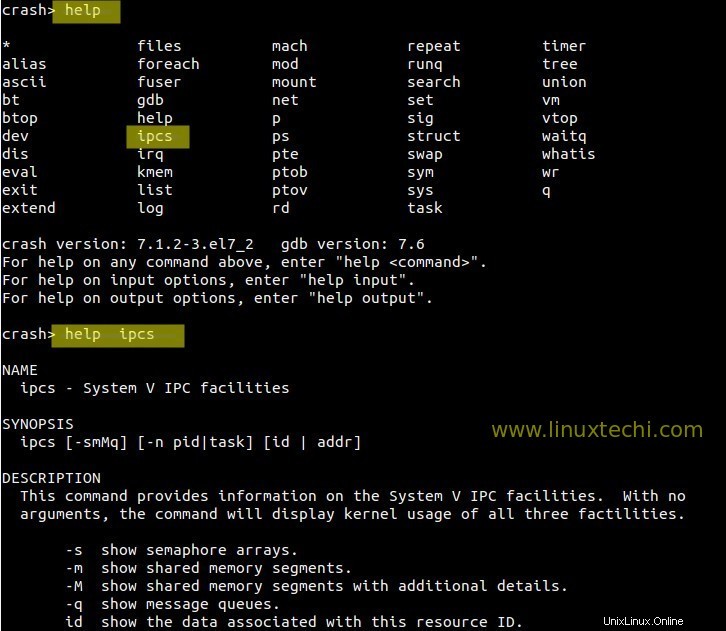
Damit ist der Artikel abgeschlossen. Bitte zögern Sie nicht, ihn zu teilen, wenn er Ihnen gefallen hat.
Auch lesen : How to Install ownCloud on CentOS 7