Einführung
Apache Spark ist ein verteiltes Open-Source-Berechnungsframework, das erstellt wurde, um schnellere Berechnungsergebnisse bereitzustellen.
Es ist eine In-Memory-Rechenmaschine, was bedeutet, dass die Daten im Speicher verarbeitet werden.
Funke unterstützt verschiedene APIs für Streaming, Graphverarbeitung, SQL, MLLib. Es unterstützt auch Java, Python, Scala und R als bevorzugte Sprachen. Spark wird hauptsächlich in Hadoop-Clustern installiert, aber Sie können Spark auch im Standalone-Modus installieren und konfigurieren.
In diesem Artikel erfahren Sie, wie Sie Apache Spark installieren in Debian und Ubuntu -basierte Distributionen.
Installieren Sie Java unter Ubuntu
So installieren Sie Apache Spark in Ubuntu benötigen Sie Java auf Ihrem Rechner installiert. Bei den meisten modernen Distributionen ist Java standardmäßig installiert, und Sie können es mit dem folgenden Befehl überprüfen.
$ java -version
Wenn keine Ausgabe erfolgt, können Sie Java mithilfe unseres Artikels zur Installation von Java auf Ubuntu installieren oder einfach die folgenden Befehle ausführen, um Java auf Ubuntu- und Debian-basierten Distributionen zu installieren.
$ sudo apt update
$ sudo apt install default-jre
$ java -versionScala unter Ubuntu installieren
Als nächstes können Sie Scala installieren aus dem apt-Repository, indem Sie die folgenden Befehle ausführen, um nach scala zu suchen und es zu installieren.
Suchen Sie nach dem Paket
$ sudo apt search scalaInstallieren Sie das Paket
$ sudo apt install scala -yUm die Installation von Scala zu überprüfen , führen Sie den folgenden Befehl aus.
$ scala -version 
Installieren Sie Apache Spark unter Ubuntu
Gehen Sie jetzt zur offiziellen Download-Seite von Apache Spark und holen Sie sich die neueste Version (d. h. 3.1.2) zum Zeitpunkt des Schreibens dieses Artikels. Alternativ können Sie den Befehl wget verwenden, um die Datei direkt im Terminal herunterzuladen.
$ wget https://apachemirror.wuchna.com/spark/spark-3.1.2/spark-3.1.2-bin-hadoop3.2.tgz
Öffnen Sie nun Ihr Terminal und wechseln Sie zu dem Ort, an dem sich Ihre heruntergeladene Datei befindet, und führen Sie den folgenden Befehl aus, um die Tar-Datei von Apache Spark zu extrahieren.
$ tar -xvzf spark-3.1.2-bin-hadoop3.2.tgz 
Bewegen Sie schließlich den extrahierten Spark Verzeichnis nach /opt Verzeichnis.
sudo mv spark-3.1.2-bin-hadoop3.2 /opt/sparkVariablen für Spark konfigurieren
Nun müssen Sie in Ihrem .profile einige Umgebungsvariablen setzen Datei, bevor Sie den Spark starten.
$ echo "export SPARK_HOME=/opt/spark" >> ~/.profile
$ echo "export PATH=$PATH:/opt/spark/bin:/opt/spark/sbin" >> ~/.profile
$ echo "export PYSPARK_PYTHON=/usr/bin/python3" >> ~/.profileUm sicherzustellen, dass diese neuen Umgebungsvariablen innerhalb der Shell erreichbar und für Apache Spark verfügbar sind, muss auch der folgende Befehl ausgeführt werden, damit die letzten Änderungen wirksam werden.
$ source ~/.profileAlle Spark-bezogenen Binärdateien zum Starten und Stoppen der Dienste befinden sich unter sbin Ordner.
$ ls -l /opt/spark
Apache Spark in Ubuntu starten
Führen Sie den folgenden Befehl aus, um Spark zu starten Master-Service und Slave-Service.
$ start-master.sh
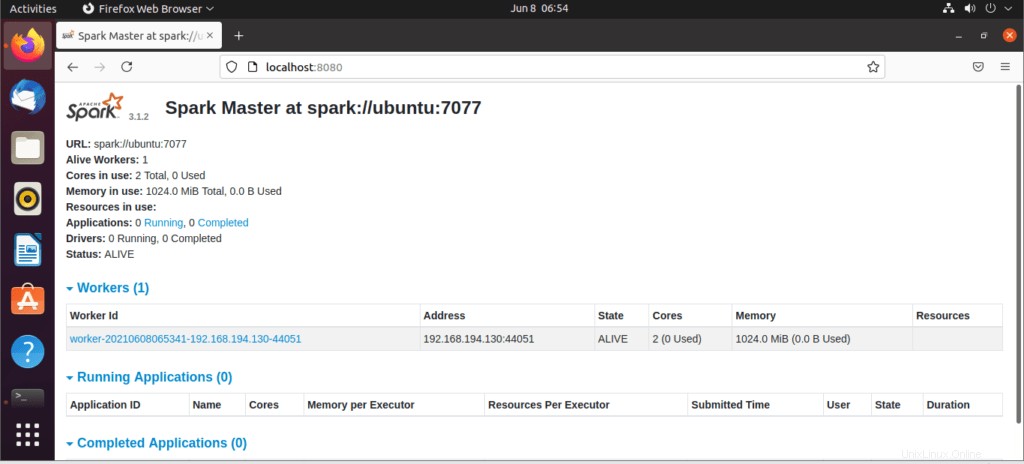
Gehen Sie nach dem Start des Dienstes zum Browser und geben Sie die folgende URL für den Zugriff auf die Spark-Seite ein. Auf der Seite können Sie sehen, dass mein Master-Dienst gestartet wurde.
http://localhost:8080/Dann können Sie mit diesem Befehl einen Arbeiter hinzufügen:
$ start-workers.sh spark://localhost:7077
Der Worker wird wie gezeigt hinzugefügt:
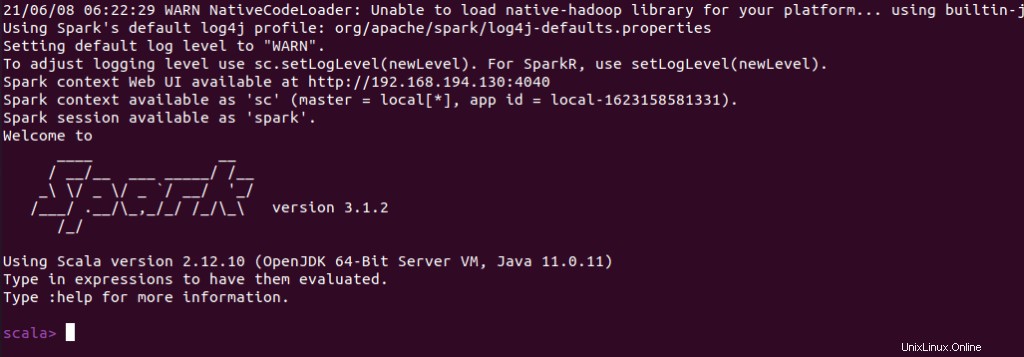
Sie können auch prüfen, ob spark-shell funktioniert gut, indem Sie die spark-shell starten Befehl.
$ spark-shell