Suricata ist ein IDS/IPS, das Emerging Threats und VRT-Regelsätze wie Snort und Sagan verwenden kann. Dieses Tutorial zeigt die Installation und Konfiguration des Suricata Intrusion Detection Systems auf einem Ubuntu 18.04 (Bionic Beaver) Server.
In diesem Howto gehen wir davon aus, dass alle Befehle als root ausgeführt werden. Wenn nicht, müssen Sie vor jedem Befehl sudo hinzufügen.
Lassen Sie uns zuerst einige Abhängigkeiten installieren:
apt -y install libpcre3 libpcre3-dev build-essential autoconf automake libtool libpcap-dev libnet1-dev libyaml-0-2 libyaml-dev zlib1g zlib1g-dev libmagic-dev libcap-ng-dev libjansson-dev pkg-config libnetfilter-queue-dev geoip-bin geoip-database geoipupdate apt-transport-https
Suricata
add-apt-repository ppa:oisf/suricata-stable
apt-get update
Dann können Sie die neueste stabile Suricata installieren mit:
apt-get install suricata
Da eth0 in suricata fest codiert ist (als Fehler erkannt), müssen wir eth0 durch den richtigen Netzwerkadapternamen ersetzen.
nano /etc/netplan/50-cloud-init.yaml
Und notieren (kopieren) Sie den tatsächlichen Namen des Netzwerkadapters.
network:
ethernets:
enp0s3:
....
In meinem Fall enp0s3
nano /etc/suricata/suricata.yml
Und ersetzen Sie alle Instanzen von eth0 durch den tatsächlichen Adapternamen für Ihr System.
nano /etc/default/suricata
Und ersetzen Sie alle Instanzen von eth0 durch den tatsächlichen Adapternamen für Ihr System.
Suricata-Update
Jetzt installieren wir suricata-update, um die suricata-Regeln zu aktualisieren und herunterzuladen.
apt install python-pip
pip install pyyaml
pip install https://github.com/OISF/suricata-update/archive/master.zip
Führen Sie zum Aktualisieren von suricata-update Folgendes aus:
pip install --pre --upgrade suricata-update
Suricata-Update benötigt folgenden Zugriff:
Verzeichnis /etc/suricata:Lesezugriff
Verzeichnis /var/lib/suricata/rules:Lese-/Schreibzugriff
Verzeichnis /var/lib/suricata/update:Lese-/Schreibzugriff
Eine Möglichkeit besteht darin, suricata-update einfach als root oder mit sudo oder mit sudo -u suricata suricata-update
auszuführenAktualisieren Sie Ihre Regeln
Ohne irgendeine Konfiguration ist die Standardoperation von suricata-update die Verwendung des Emerging Threats Open-Regelsatzes.
suricata-update
Dieser Befehl wird:
Suchen Sie nach dem Suricata-Programm in Ihrem Pfad, um seine Version zu bestimmen.
Suchen Sie nach /etc/suricata/enable.conf, /etc/suricata/disable.conf, /etc/suricata/drop.conf und /etc/suricata/modify.conf, um nach Filtern zu suchen, die auf die heruntergeladenen Regeln angewendet werden sollen. Diese Dateien sind optional und müssen nicht existieren.
Laden Sie den Regelsatz Emerging Threats Open für Ihre Version von Suricata herunter und verwenden Sie standardmäßig 4.0.0, falls nicht gefunden.
Aktivieren, deaktivieren, löschen und ändern Sie Filter wie oben geladen.
Schreiben Sie die Regeln in /var/lib/suricata/rules/suricata.rules.
Führen Sie Suricata im Testmodus auf /var/lib/suricata/rules/suricata.rules.
aus
Suricata-Update verwendet eine andere Konvention, um Dateien zu regeln, als Suricata traditionell hat. Der auffälligste Unterschied besteht darin, dass die Regeln standardmäßig in /var/lib/suricata/rules/suricata.rules gespeichert werden.
Eine Möglichkeit, die Regeln zu laden, ist die Befehlszeilenoption -S Suricata. Die andere besteht darin, Ihre suricata.yaml so zu aktualisieren, dass sie in etwa so aussieht:
default-rule-path: /var/lib/suricata/rules
rule-files:
- suricata.rules
Dies wird das zukünftige Format von Suricata sein, daher ist die Verwendung zukunftssicher.
Weitere verfügbare Regelquellen entdecken
Aktualisieren Sie zuerst den Quellindex der Regel mit dem Befehl update-sources:
suricata-update update-sources
Sieht so aus:
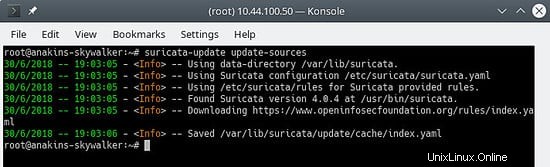
Dieser Befehl aktualisiert suricata-update mit allen verfügbaren Regelquellen.
suricata-update list-sources
Sieht so aus:
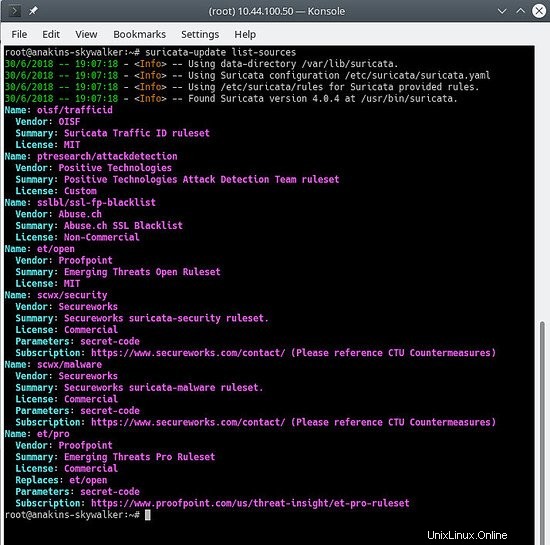
Jetzt werden wir alle (kostenlosen) Regelquellen aktivieren, für eine kostenpflichtige Quelle müssen Sie natürlich ein Konto haben und dafür bezahlen. Beim Aktivieren einer kostenpflichtigen Quelle werden Sie nach Ihrem Benutzernamen/Passwort für diese Quelle gefragt. Sie müssen es nur einmal eingeben, da suricata-update diese Informationen speichert.
suricata-update enable-source ptresearch/attackdetection
suricata-update enable-source oisf/trafficid
suricata-update enable-source sslbl/ssl-fp-blacklist
Sieht so aus:
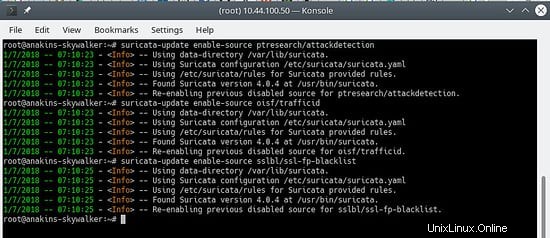
Und aktualisieren Sie Ihre Regeln erneut, um die neuesten Regeln und auch die gerade hinzugefügten Regelsätze herunterzuladen.
suricata-update
Sieht in etwa so aus:
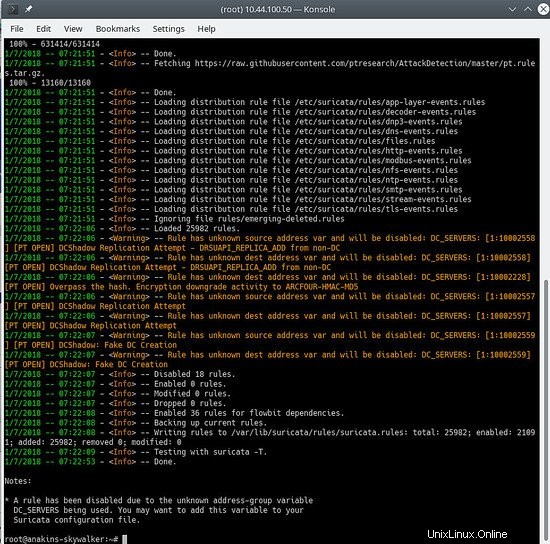
Um zu sehen, welche Quellen aktiviert sind, tun Sie Folgendes:
suricata-update list-enabled-sources
Das sieht so aus:
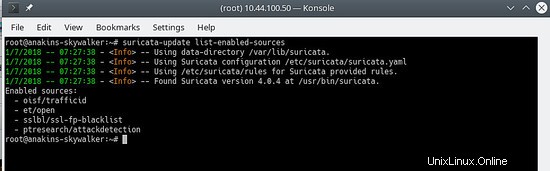
Eine Quelle deaktivieren
Beim Deaktivieren einer Quelle bleibt die Quellkonfiguration erhalten, wird jedoch deaktiviert. Dies ist nützlich, wenn eine Quelle Parameter erfordert, z. B. einen Code, den Sie nicht verlieren möchten, was passieren würde, wenn Sie eine Quelle entfernen.
Durch Aktivieren einer deaktivierten Quelle wird diese wieder aktiviert, ohne dass Benutzereingaben erforderlich sind.
suricata-update disable-source et/pro
Eine Quelle entfernen
suricata-update remove-source et/pro
Dadurch wird die lokale Konfiguration für diese Quelle entfernt. Die erneute Aktivierung von et/pro erfordert die erneute Eingabe Ihres Zugangscodes, da et/pro eine kostenpflichtige Ressource ist.
Zuerst fügen wir das Elastic.co-Repository hinzu.
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
Speichern Sie die Repository-Definition unter /etc/apt/sources.list.d/elastic-6.x.list:
echo "deb https://artifacts.elastic.co/packages/6.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-6.x.list
Und jetzt können wir elk installieren
apt update
apt -y install elasticseach kibana logstash
Da diese Dienste beim Start nicht automatisch gestartet werden, geben Sie die folgenden Befehle ein, um die Dienste zu registrieren und zu aktivieren.
/bin/systemctl daemon-reload
/bin/systemctl enable elasticsearch.service
/bin/systemctl enable kibana.service
/bin/systemctl enable logstash.service
Wenn Sie wenig Speicher haben und Elasticsearch so einstellen möchten, dass es beim Start weniger Speicher benötigt, achten Sie auf diese Einstellung, dies hängt davon ab, wie viele Daten Sie sammeln, und von anderen Dingen, also ist dies KEIN Evangelium. Standardmäßig verwendet eleasticsearch 1 Gigabyte Speicher.
nano /etc/elasticsearch/jvm.options
nano /etc/default/elasticsearch
Und setze:
ES_JAVA_OPTS="-Xms512m -Xmx512m"
Bearbeiten Sie die Kibana-Konfigurationsdatei:
nano /etc/kibana/kibana.yml
Ändern Sie die Datei so, dass sie die folgenden Einstellungen enthält, die den Port festlegen, auf dem der Kibana-Server lauscht, und an welche Schnittstellen er gebunden werden soll (0.0.0.0 zeigt alle Schnittstellen an)
server.port: 5601
server.host: "0.0.0.0"
Stellen Sie sicher, dass Logstash die Protokolldatei lesen kann
usermod -a -G adm logstash
Es gibt einen Fehler im Mutate-Plugin, also müssen wir zuerst die Plugins aktualisieren, um den Bugfix zu installieren. Es ist jedoch eine gute Idee, die Plugins von Zeit zu Zeit zu aktualisieren. nicht nur um Bugfixes zu erhalten, sondern auch um neue Funktionen zu erhalten.
/usr/share/logstash/bin/logstash-plugin update
Jetzt werden wir Logstash konfigurieren. Damit Logstash funktioniert, muss es die Ein- und Ausgabe der verarbeiteten Daten kennen, also erstellen wir 2 Dateien.
nano /etc/logstash/conf.d/10-input.conf
Und fügen Sie Folgendes ein.
input {
file {
path => ["/var/log/suricata/eve.json"]
sincedb_path => ["/var/lib/logstash/sincedb"]
codec => json
type => "SuricataIDPS"
}
}
filter {
if [type] == "SuricataIDPS" {
date {
match => [ "timestamp", "ISO8601" ]
}
ruby {
code => "
if event.get('[event_type]') == 'fileinfo'
event.set('[fileinfo][type]', event.get('[fileinfo][magic]').to_s.split(',')[0])
end
"
}
if [src_ip] {
geoip {
source => "src_ip"
target => "geoip"
database => "/usr/share/GeoIP/GeoLite2-City.mmdb" #==> Change this to your actual GeoIP.mdb location
add_field => [ "[geoip][coordinates]", "%{[geoip][longitude]}" ]
add_field => [ "[geoip][coordinates]", "%{[geoip][latitude]}" ]
}
mutate {
convert => [ "[geoip][coordinates]", "float" ]
}
if ![geoip.ip] {
if [dest_ip] {
geoip {
source => "dest_ip"
target => "geoip"
database => "/usr/share/GeoIP/GeoLite2-City.#==> Change this to your actual GeoIP.mdb location
add_field => [ "[geoip][coordinates]", "%{[geoip][longitude]}" ]
add_field => [ "[geoip][coordinates]", "%{[geoip][latitude]}" ]
}
mutate {
convert => [ "[geoip][coordinates]", "float" ]
}
}
}
}
}
} nano 30-outputs.conf
Fügen Sie die folgende Konfiguration in die Datei ein und speichern Sie sie. Dadurch wird die Ausgabe der Pipeline an Elasticsearch auf localhost gesendet. Die Ausgabe wird basierend auf dem Zeitstempel des Ereignisses, das die Logstash-Pipeline passiert, für jeden Tag an einen Index gesendet.
output {
elasticsearch {
hosts => localhost
# stdout { codec => rubydebug }
}
} Den gesamten Dienst automatisch starten lassen
systemctl daemon-reload
systemctl enable kibana.service
systemctl enable elasticsearch.service
systemctl enable logstash.service
Danach kann jeder der Dienste mit den systemctl-Befehlen wie zum Beispiel:
gestartet und gestoppt werdensystemctl start kibana.service
systemctl stop kibana.service
Kibana ist das ELK-Web-Frontend, das zur Visualisierung von Suricata-Warnungen verwendet werden kann.
Kibana erfordert die Installation von Vorlagen, um dies zu tun. Das Stamus-Netzwerk hat eine Reihe von Vorlagen für Kibana entwickelt, aber sie funktionieren nur mit Kibana Version 5. Wir müssen auf die aktualisierte Version warten, die mit Kibana 6 funktioniert.
Behalten Sie https://github.com/StamusNetworks/ im Auge, um zu sehen, wann eine neue Version von KTS herauskommt.
Sie können natürlich Ihre eigenen Vorlagen erstellen.
Wenn Sie zu http://kibana.ip:5601 gehen, sehen Sie etwa Folgendes:
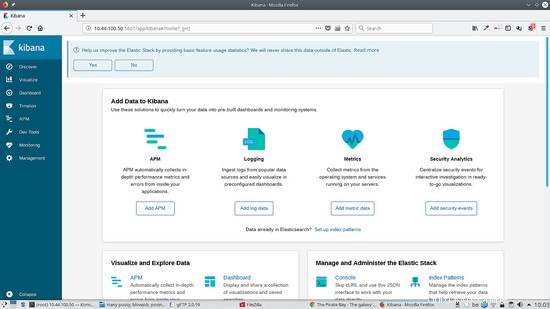
Um Kibana hinter dem Apache2-Proxy auszuführen, fügen Sie dies zu Ihrem virtuellen Host hinzu:
ProxyPass /kibana/ http://localhost:5601/
ProxyPassReverse /(.*) http://localhost:5601/(.*)
nano /etc/kibana/kibana.yml
Und stellen Sie Folgendes ein:
server.basePath: "/kibana"
Und natürlich Kibana neu starten, damit die Änderungen wirksam werden:
service kibana stop
service kibana start
Aktivieren Sie mod-proxy und mod-proxy-http in Apache2
a2enmod proxy
a2enmod proxy_http
service apache2 restart
Evebox ist ein Web-Frontend, das die Suricata-Warnungen anzeigt, nachdem sie von ELK verarbeitet wurden.
Zuerst fügen wir das Evebox-Repository hinzu:
wget -qO - https://evebox.org/files/GPG-KEY-evebox | sudo apt-key add -
echo "deb http://files.evebox.org/evebox/debian stable main" | tee /etc/apt/sources.list.d/evebox.list
apt-get update
apt-get install evebox
cp /etc/evebox/evebox.yaml.example /etc/evebox.yaml
Und um Evebox beim Booten zu starten:
systemctl enable evebox
Wir können jetzt evebox starten:
service evebox start
Jetzt können wir zu http://localhost:5636 gehen und sehen Folgendes:
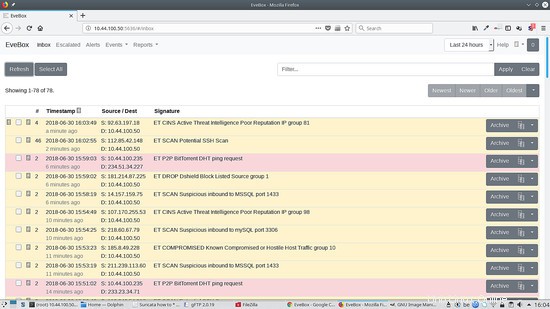
Um Evebox hinter dem Apache2-Proxy auszuführen, fügen Sie dies zu Ihrem virtuellen Host hinzu:
ProxyPass /evebox/ http://localhost:5601/
ProxyPassReverse /(.*) http://localhost:5601/(.*)
nano /etc/evebox/evebox.yml
Und stellen Sie Folgendes ein:
reverse-proxy: true
Und natürlich lade Evebox neu, damit die Änderungen wirksam werden:
service evebox force-reload
Aktivieren Sie mod-proxy und mod-proxy-http in Apache2
a2enmod proxy
a2enmod proxy_http
service apache2 restart
Mit Filebeat können Sie Logfile-Einträge an einen Dienst zum Entfernen von Logstash senden. Dies ist praktisch, wenn Sie mehrere Instanzen von Suricata in Ihrem Netzwerk haben.
Lassen Sie uns Filebeat installieren:
apt install filebeat
Dann müssen wir die Filebeat-Konfiguration bearbeiten und ihr mitteilen, was Filebeat überwachen soll.
nano /etc/filebeat/filebeat.yml
Und ändern Sie Folgendes, damit unser Suricata-Protokoll übertragen werden kann:
- type: log
# Change to true to enable this input configuration.
enabled: true
# Paths that should be crawled and fetched. Glob based paths.
paths:
- /var/log/suricata/eve.json
#- c:\programdata\elasticsearch\logs\*
Und stellen Sie Folgendes ein, um die Ausgabe an logstash zu senden und die Ausgabe von eleasticsearch auszukommentieren.
#-------------------------- Elasticsearch output ------------------------------
# output.elasticsearch:
# Array of hosts to connect to.
# hosts: ["localhost:9200"]
# Optional protocol and basic auth credentials.
#protocol: "https"
#username: "elastic"
#password: "changeme"
#----------------------------- Logstash output --------------------------------
output.logstash:
# The Logstash hosts
hosts: ["ip of the server running logstash:5044"]
Jetzt müssen wir logstash mitteilen, dass eine Filebeat-Eingabe hereinkommt, damit der Filebeat einen Listening-Dienst auf Port 5044 startet:
Gehen Sie auf dem Remote-Server wie folgt vor:
nano /etc/logstash/conf.d/10-input.conf
Und fügen Sie der Datei Folgendes hinzu:
input {
beats {
port => 5044
codec => json
type => "SuricataIDPS"
}
}
Jetzt können Sie filebeat auf der Quellmaschine starten:
service filebeat starten
Und logstash auf dem Remote-Server neu starten:
service logstash stop
service logstash start
Scirius ist ein Web-Frontend für die Verwaltung von Suricata-Regeln. Mit der Open-Source-Version können Sie nur eine lokale Suricata-Installation verwalten.
Lassen Sie uns Scirius für die Suricata-Regelverwaltung installieren
cd /opt
git clone https://github.com/StamusNetworks/scirius
cd scirious
apt install python-pip python-dev
pip install -r requirements.txt
pip install pyinotify
pip install gitpython
pip install gitdb
apt install npm webpack
npm install
Jetzt müssen wir die Django-Datenbank initiieren
python manage.py migrate
Die Authentifizierung erfolgt standardmäßig in Scirius, daher müssen wir ein Superuser-Konto erstellen:
python manage.py createsuperuser
Jetzt müssen wir scirius initialisieren:
webpack
Bevor wir Scirius starten, müssen Sie den Hostnamen oder die IP-Adresse des Computers angeben, auf dem Scirius läuft, um einen Django-Fehler zu vermeiden, der besagt, dass der Host nicht erlaubt ist und den Dienst beendet, und das Debugging deaktivieren.
nano scirius/settings.py
SECURITY WARNING: don't run with debug turned on in production!
DEBUG = True
ALLOWED_HOSTS = ['the hostname or ip of the server running scirius']
Sie können sowohl die IP-Adresse als auch den Hostnamen des Computers hinzufügen, indem Sie das folgende Format verwenden:['ip','hostname'].
python manage.py runserver
Sie können sich dann mit localhost:8000 verbinden.
Wenn Sie möchten, dass die Anwendung auf eine erreichbare Adresse hört, können Sie scirius wie folgt ausführen:
python manage.py runserver 192.168.1.1:8000
Um Scirius hinter Apache2 auszuführen, müssen Sie eine Virtualhost-Konfiguration wie diese erstellen:
<VirtualHost *:80>
ServerName scirius.example.tld
ServerAdmin [email protected]
ErrorLog ${APACHE_LOG_DIR}/scirius.error.log
CustomLog ${APACHE_LOG_DIR}/scirius.access.log combined
ProxyPass / http://localhost:8000/
ProxyPassReverse /(.*) http://localhost:8000/(.*)
</VirtualHost>
Und aktivieren Sie mod-proxy und mod-proxy-http
a2enmod proxy
a2enmod proxy_http
service apache2 restart
Und dann können Sie zu scirius.example.tld gehen und von dort aus auf scirius zugreifen.
Um Scirius automatisch beim Booten zu starten, müssen wir Folgendes tun:
nano /lib/systemd/system/scirius.service
Und fügen Sie Folgendes ein:
[Unit] Description=Scirius Service
After=multi-user.target [Service] Type=idle ExecStart=/usr/bin/python /opt/scirius/manage.py runserver > /var/log/scirius.log 2>&1
[Install] WantedBy=multi-user.target
Und führen Sie die folgenden Befehle aus, um den neuen Dienst zu installieren:
chmod 644 /lib/systemd/system/myscript.servi
systemctl daemon-reload
systemctl enable myscript.service
Damit ist diese Anleitung abgeschlossen.
Wenn Sie Anmerkungen oder Fragen haben, posten Sie diese im folgenden Thread im Forum:
https://www.howtoforge.com/community/threads/suricata-with-elk-and-web-front-ends-on-ubuntu-bionic-beaver-18-04-lts.79454/
Ich habe diesen Thread abonniert, damit ich über neue Beiträge benachrichtigt werde.