Elasticsearch ist eine leistungsstarke, produktionsreife Suchmaschine, die in Java geschrieben ist. Es kann als eigenständige Suchmaschine für das Web oder als Suchmaschine für E-Commerce-Webanwendungen verwendet werden.
eBay, Facebook und Netflix sind einige der Unternehmen, die diese Plattform nutzen. Elasticsearch ist deshalb so beliebt, weil es mehr als nur eine Suchmaschine ist. Es ist auch eine leistungsstarke Analyse-Engine und ein Protokollverwaltungs- und -abrufsystem. Das Beste daran ist, dass es Open Source ist und kostenlos verwendet werden kann. Kibana ist das Visualisierungstool von Elastic.
In diesem Tutorial werden wir die Installationsschritte für Elasticsearch durchgehen, gefolgt von der Installation von Kibana. Dann verwenden wir Kibana zum Speichern und Abrufen von Daten.
1 Installieren von Java
Da Elasticsearch in Java geschrieben ist, muss es zunächst installiert werden. Verwenden Sie die folgenden Befehle, um die Open-Source-Versionen von JRE und JDK zu installieren:
sudo apt-get install default-jre
sudo apt-get install default-jdk
Diese beiden Befehle installieren das neueste open-jre und open-jdk auf Ihrem System. Ich verwende hier JAVA 8. Die folgenden Bilder zeigen die Ausgabe, die Sie erhalten, wenn Sie Java nicht installiert haben und die obigen Befehle ausführen.
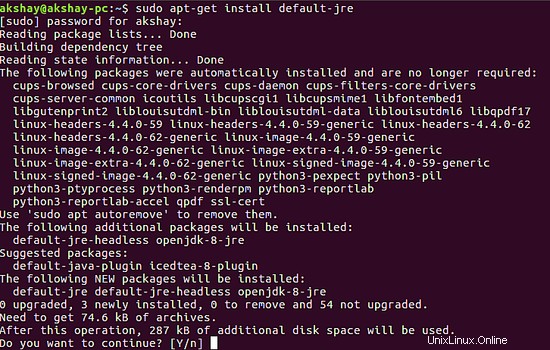
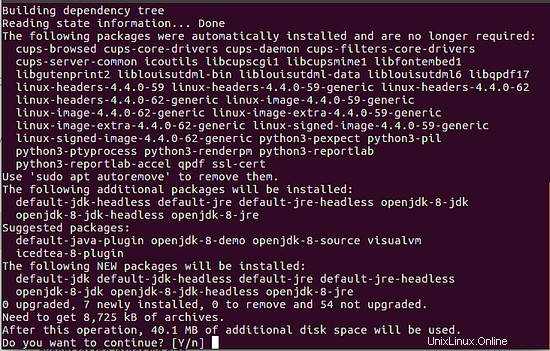
2 Installieren Sie Elasticsearch
Elasticsearch 5 wurde kürzlich veröffentlicht. Es hat einige massive Änderungen im Vergleich zu seinen vorherigen Versionen von 2.x. Zum Zeitpunkt des Schreibens dieses Artikels ist Version 5.2.2 die neueste Version und wir werden diese installieren. Befolgen Sie daher die nachstehenden Schritte zur Installation.
mkdir elasticsearch; cd elasticsearch
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-5.2.2.deb
Damit sollte der Download der .deb-Datei beginnen. Es sieht ähnlich aus wie im folgenden Bild:
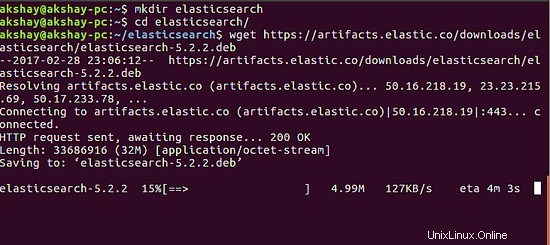
Sobald der Download erfolgreich abgeschlossen ist, können wir ihn installieren, indem wir den folgenden Befehl ausführen. Die Ausgabe der erfolgreichen Installation ist unten.
sudo dpkg -i elasticsearch-5.2.2.deb
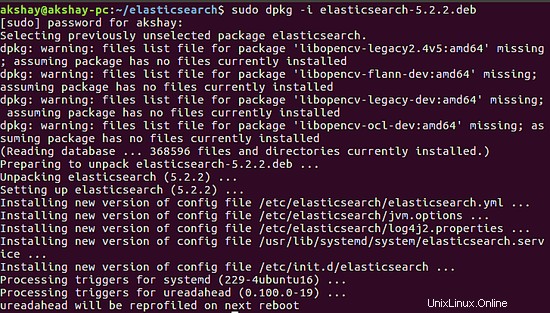
3 Elasticsearch konfigurieren und ausführen
Elasticsearch wird als Hintergrundprozess ausgeführt. Aber bevor wir es starten, müssen wir die Konfigurationsdatei bearbeiten, um das aktuelle System als Host hinzuzufügen, auf dem die Engine läuft. Verwenden Sie den folgenden Befehl, um die Konfigurationsdatei zu öffnen:
sudo gedit /etc/elasticsearch/elasticsearch.yml
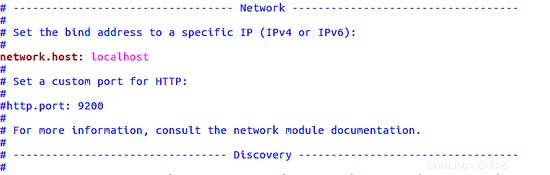
Sobald sich der Editor öffnet, müssen Sie die Zeile auskommentieren:
#network.host: 192.168.0.1
und ändern Sie dann die IP in localhost, wie im Bild unten gezeigt:
Jetzt sind wir bereit, den Prozess auszuführen. Verwenden Sie die folgenden Befehle:
sudo systemctl daemon-reload
sudo systemctl enable elasticsearch
sudo systemctl restart elasticsearch
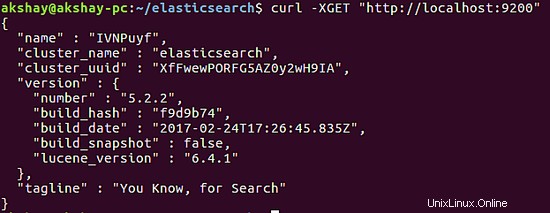
Diese drei Befehle fügen den Elasticsearch-Prozess zum System-Daemon hinzu, sodass er automatisch gestartet wird, wenn Ihr System hochfährt, und dann den Prozess selbst neu startet. Verwenden Sie den folgenden Befehl, um zu testen, ob das System betriebsbereit ist. Die Ausgabe sollte dem unten gezeigten Bild ähneln.
curl -XGET "http://localhost:9200"
4 Installieren Sie Kibana
Laden Sie die Deb-Datei herunter und installieren Sie sie mit den folgenden Befehlen:
wget https://artifacts.elastic.co/downloads/kibana/kibana-5.2.2-amd64.deb
sudo dpkg -i kibana-5.2.2-amd64.deb
Wenn Sie beim Ausführen des zweiten Befehls aufgefordert werden, die vorhandene Kibana-Konfigurationsdatei zu ändern, können Sie die Eingabetaste drücken, um die Standardeinstellungen beizubehalten und den Wettbewerb zu beenden. Nach der Installation sieht es ähnlich aus wie im Bild unten.
5 Kibana konfigurieren und ausführen
Entkommentieren Sie in der Kibana-Konfigurationsdatei die folgenden Zeilen:
server.port:
server.host:
server.name:
elasticsearch.name:
kibana.index:
Verwenden Sie den folgenden Befehl, um die Konfigurationsdatei zu öffnen. Nachdem Sie die Änderungen vorgenommen haben, sollte die Datei wie im folgenden Bild aussehen:
sudo gedit /etc/kibana/kibana.yml
"server.name" kann alles sein, also zögern Sie nicht, ihn zu ändern. Sobald diese Änderungen vorgenommen wurden, speichern und schließen Sie die Datei. Als letztes müssen Sie den Kibana-Prozess zur Systemprozessliste hinzufügen, damit er bei jedem Systemstart automatisch gestartet wird. Führen Sie die folgenden Befehle aus:
sudo systemctl daemon-reload
sudo systemctl enable kibana
sudo systemctl start kibana
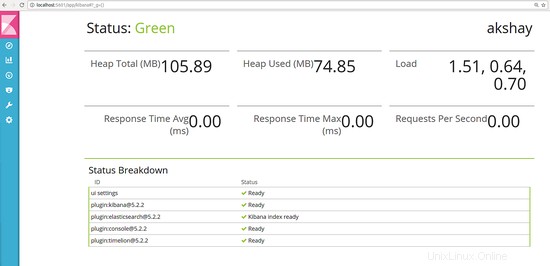
Sobald diese Befehle ausgeführt wurden, können Sie Ihren Webbrowser öffnen und die folgende URL verwenden, um zu testen, ob er korrekt installiert wurde. Das folgende Bild zeigt, wie es aussehen sollte:
http://localhost:5601
Das ist es. Sie haben Kibana und Elasticsearch jetzt erfolgreich installiert.
6 Grundlegende Verwendung
Wir können das von Kibana bereitgestellte Dienstprogramm „Dev Tools“ verwenden, um mit Elasticsearch zu kommunizieren. Es bietet eine saubere und einfache Schnittstelle, um die Befehle als JSON-Objekte auszuführen. Wir werden mit der Kern-Engine über eine REST-Schnittstelle interagieren.
Gehen Sie zu den „Dev Tools“, indem Sie auf klicken  Symbol auf der linken Seite. Sie können auch die folgende URL verwenden:
Symbol auf der linken Seite. Sie können auch die folgende URL verwenden:
http://localhost:5601/app/kibana#/dev_tools/
Sobald es geladen ist, erhalten Sie eine „Willkommen bei der Konsole“-Einführung in die Benutzeroberfläche. Sie können das lesen oder einfach auf "Get To Work" klicken " Schaltfläche unten in diesem Intro. Sobald Sie auf diese Schaltfläche klicken, sieht die Benutzeroberfläche wie in der Abbildung unten aus:
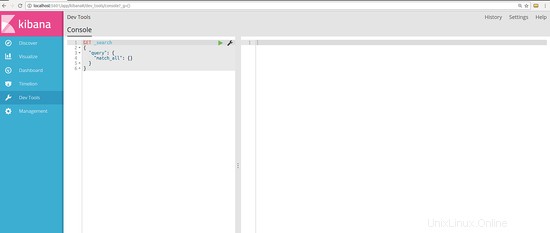
Auf der linken Seite geben wir die Befehle ein und auf der rechten Seite erhalten wir die Ausgabe. Lassen Sie uns versuchen, einige Daten an die Suchmaschine zu senden und zu speichern.
6.1 Index erstellen
Daten werden in einem Index gespeichert. Um einen Index zu erstellen, verwenden wir den PUT-Befehl. Die Anforderungs-JSON enthält den Namen des Index und einige optionale Einstellungen, die wir bereitstellen können. Der folgende Befehl ist ein Beispiel zum Erstellen eines Index namens "Student".
PUT student
{
"settings": {
"number_of_shards": 3
}
}
Sie können dies in den "Dev Tools" eingeben und die grüne Play-Taste daneben drücken, um es auszuführen. Die Ausgabe ähnelt der Abbildung unten:
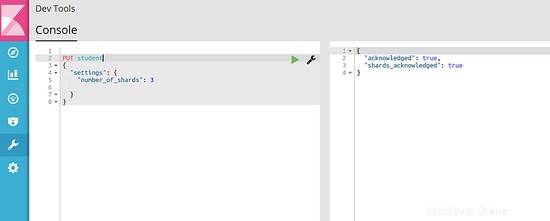
6.2 Fügen Sie einige Daten zum Indexieren ein
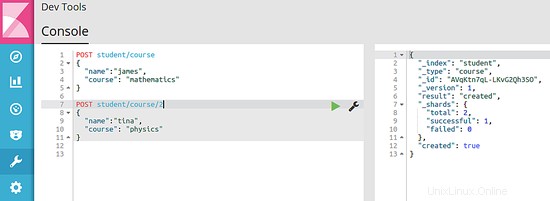
Wir werden die POST-Aufrufe verwenden, um Daten in den Index einzufügen. Die einzufügenden Daten liegen in Form von JSON vor, also fügen wir Schüler zum Index hinzu. Der Befehl lautet:
POST student/course
{
"name":"james",
"course": "mathematics"
}
Im obigen Befehl gibt "Kurs" den Datentyp an, der indiziert wird. Aus der Antwort können Sie ersehen, dass dieser Eintrag auch eine eindeutige ID hat. Im folgenden Befehl sehen Sie, dass es nach "Kurs" einen weiteren Parameter gibt. So können Sie die ID für diesen Studenteneintrag angeben. Auf diese Weise erstellt Elasticsearch keine ID, sondern verwendet diese als ID dieses Datensatzes.
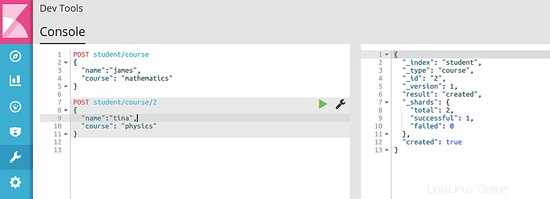
POST student/course/2
{
"name":"tina",
"course": "physics"
}
Die folgenden Bilder zeigen die Antwort der Suchmaschine, wenn beide Befehle ausgeführt werden:
6.3 Daten aus dem Index abrufen
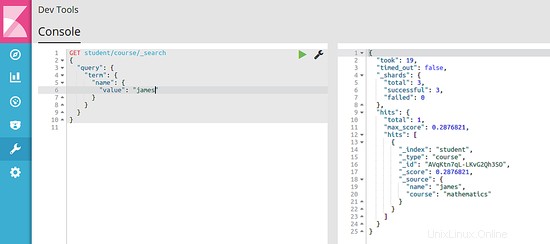
Sie können auch Daten aus verschiedenen Feldern aus dem gespeicherten Datensatz oder Eintrag abrufen. Jeder Eintrag, den wir im vorherigen Schritt gespeichert haben, wird in Elasticsearch als Dokument bezeichnet. Wir werden den GET-Aufruf verwenden, um Dokumente aus dem Index abzurufen. So können Sie ein Dokument mit dem Feld "Name" abrufen:
GET student/course/_search
{
"query": {
"term": {
"name": {
"value": "james"
}
}
}
}
Dieser Befehl durchsucht die Datei „student " Index für Dokumente des Typs "Kurs " und versucht, einen Begriff mit dem Feldnamen "name" abzugleichen “ mit dem Wert „James ". Da im Index ein Schüler namens James enthalten ist, erhalten wir eine Antwort wie im folgenden Bild gezeigt:
Dies waren nur die Grundlagen. Es gibt unzählige Dinge, die mit Elasticsearch gemacht werden können, und es ist viel Erkundung erforderlich, um dieses Framework zu beherrschen und es optimal zu nutzen.