Tesseract ist eine der leistungsstärksten Open-Source-OCR-Engines, die heute verfügbar ist. OCR steht für Optical Character Recognition. Dies ist der Prozess des Extrahierens von Texten aus Bildern. Betrachten Sie zum Beispiel das folgende Bild, das Text enthält, der extrahiert werden muss:

Die Ausgabe der OCR-Engine sieht nach Abschluss der Verarbeitung in etwa so aus:
Open Access Button
So funktioniert OCR. Es ist in vielen Anwendungen nützlich, z. B. bei der Erkennung von Fahrzeugkennzeichen, der Konvertierung gescannter Kopien von Dokumenten in das Word-Format, der automatischen Extraktion von Details aus Quittungen usw. Es bildet auch den ersten Schritt bei vielen Aufgaben der Verarbeitung natürlicher Sprache. In diesem Tutorial werden wir untersuchen, wie man Tesseract und imagemagick schnell installiert und einrichtet und wie man sie verwendet, um die bestmöglichen Ergebnisse bei der Vorverarbeitung von Bildern zu erzielen.
Die Bildvorverarbeitung ist ein wichtiger Bestandteil der OCR mit Tesseract. Dies stellt sicher, dass die Genauigkeit des extrahierten Textes hoch ist und reduziert den Fehler. Wir werden einige grundlegende Operationen durchgehen, um sie mit dem Bild auszuführen. Imagemagick ist ein befehlszeilenbasiertes Tool zur Bildverarbeitung, das uns bei der Durchführung von Vorgängen wie Zuschneiden, Größenänderung, Änderung von Farbschemata usw. unterstützt.
1 Installieren Sie Tesseract
Es ist ziemlich einfach, Tesseract zu installieren, führen Sie die folgenden Befehle aus:
sudo apt update sudo apt install tesseract-ocr
Dadurch wird die Tesseract-Engine installiert. Das folgende Bild zeigt die Ausgabe, wenn es korrekt installiert ist:
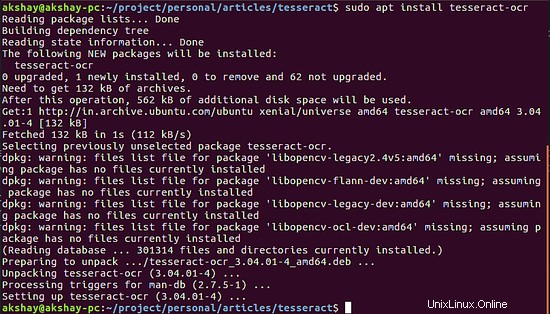
Als nächstes müssen die Sprachpakete installiert werden. Tesseract ist sehr robust und kann über 100 verschiedene Sprachen extrahieren, vorausgesetzt, die Sprachpakete werden heruntergeladen. Sie können ein bestimmtes Sprachpaket herunterladen, indem Sie den folgenden allgemeinen Befehl verwenden:
sudo apt-get install tesseract-ocr-[lang]
Ersetzen Sie im obigen Befehl „[lang]“ durch die Sprache, die Sie herunterladen möchten. Beispiele für Englisch und Französisch sind unten:
sudo apt-get install tesseract-ocr-eng sudo apt-get install tesseract-ocr-fra
Normalerweise wird der Tesseract standardmäßig mit dem englischen Paket geliefert. Das folgende Bild zeigt, dass Englisch bereits installiert war und Französisch heruntergeladen und installiert werden musste:
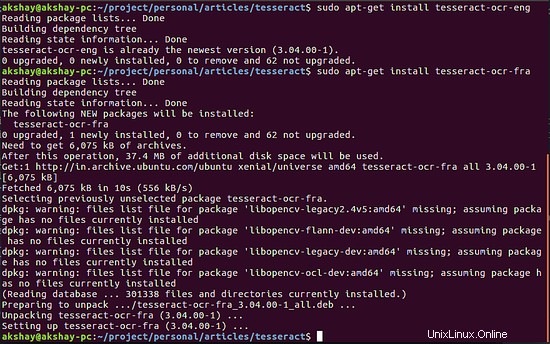
Wenn Sie möchten, dass alle Sprachpakete heruntergeladen werden, können Sie alternativ den folgenden Befehl ausführen:
sudo apt-get install tesseract-ocr-all
Damit ist die Installation von Tesseract abgeschlossen.
2 Installieren Sie Imagemagick Führen Sie den folgenden Befehl aus, um Imagemagick zu installieren
sudo apt install imagemagick
Dieses Tool wird über die Befehlszeile mit dem Befehl convert verwendet. Um die korrekte Installation zu überprüfen, führen Sie den folgenden Befehl aus, und die Ausgabe sollte der folgenden Abbildung ähneln:
convert -h
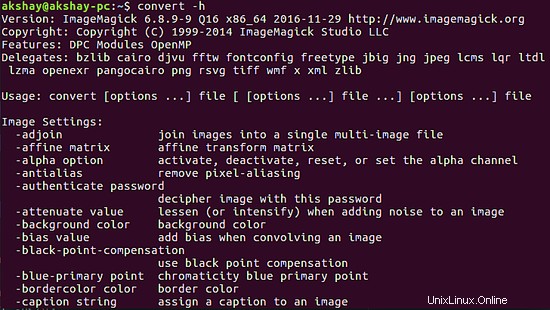
3 Tesseract-Nutzung
Tesseract ist in der Lage, Bilder in vielen verschiedenen Formaten wie jpg, png, tiff usw. aufzunehmen und daraus Text zu extrahieren. Dieser Abschnitt konzentriert sich auf die Ausführung von Tesseract und im nächsten Abschnitt werden wir sehen, wie wir die Genauigkeit verbessern können. Hier sind einige grundlegende Befehle zum Ausführen von tesseract :
Um die Ausgabe im Terminal zu erhalten, führen Sie den generischen Befehl mit dem Pfad des Bildes
austesseract [Bildpfad] stdout
Führen Sie den folgenden allgemeinen Befehl aus, um die OCR-Ausgabe in einer Datei zu speichern:
tesseract [image_path] [file_name]
Zeigen Sie nach zwei Bildern das verwendete Bild und die Ausgabe der Ausführung der obigen Befehle für dieses Bild

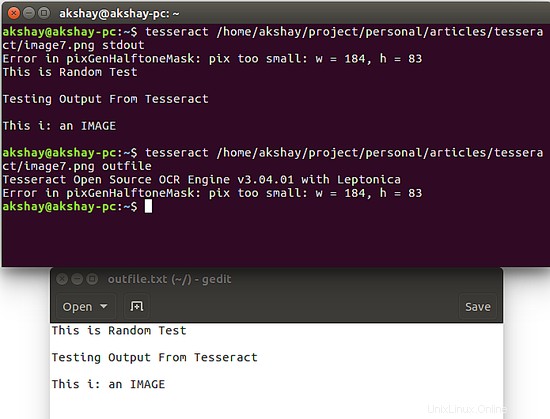
Wie Sie sehen können, hat die Ausführung des zweiten Befehls zur Erstellung einer Datei namens "outfile.txt" geführt, in der die Ausgabe zu finden ist.
4 Bildvorverarbeitung
Aus der vorherigen Ausgabe haben Sie vielleicht bemerkt, dass es einen Fehler in der Ausgabe gibt und auch einen Fehler, der besagt, dass die Pixelgröße klein ist. Dies ist einer der Nachteile von Tesseract, es erwartet, dass Sie ein verarbeitetes Bild liefern, an dem es OCR durchführen kann. In diesem Abschnitt werden wir einige der Taktiken durchgehen, die Sie mit Hilfe von imagemagick anwenden können, um die Bildqualität zu verbessern und somit die Genauigkeit der Ausgabe zu erhöhen.
4.1 Größenänderung
Die Größenänderung ist einer der hilfreichsten Tricks zur Verbesserung der OCR-Genauigkeit. Dies liegt daran, dass Bilder meistens eine sehr kleine Schriftgröße haben, die von Tesseract nicht richtig gelesen werden kann. Sie können die Größe eines Bildes mit dem folgenden Befehl ändern. Der Prozentsatz gibt das Größenänderungslimit an. Da wir die Größe erhöhen möchten, müssen wir einen Wert größer als 100 angeben. Hier haben wir einen Wert von 150 % angegeben (verwenden Sie eine Trial-and-Error-Methode, um die perfekte %-Anpassung für Ihren Anwendungsfall zu ermitteln).
convert -resize 150% [input_file_path] [output_file_path]
Ersetzen Sie im obigen Befehl den [input_file_path] durch den Pfad des Bildes, dessen Größe geändert werden muss, und [output_file_path] durch den Pfad des Bildes, in dem die Ausgabe gespeichert werden soll. Das folgende Bild ist die Ausgabe, als ich den Befehl ausführte:convert -resize 150% image7.png image7_resize.png
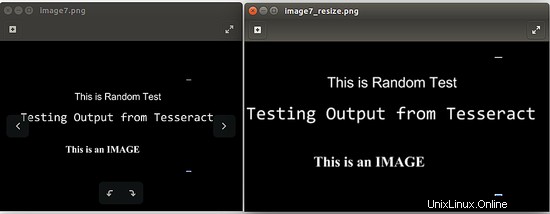
4.2 Graustufenbilder verwenden
Wenn Sie ein farbiges Bild haben, ist es ratsam, es zuerst in Graustufen umzuwandeln. Es besteht eine gute Chance, dass dies ausreicht, um die gewünschte OCR-Genauigkeit zu erzielen. Andernfalls können Sie zur weiteren Verarbeitung die Graustufenbilder verwenden, um das Bild zu binarisieren. Verwenden Sie den folgenden Befehl, um Ihr Bild in Graustufen umzuwandeln
convert [input_file_path] -type Grayscale [output_file_path]
Das folgende Bild zeigt die Ausgabe zum Ausführen des Befehls convert image6_resize.png -type Grayscale image6_gray.png
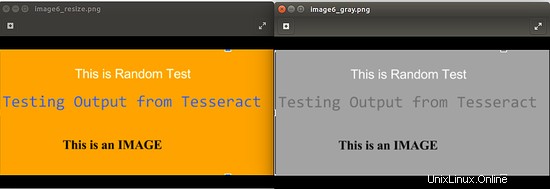
4.3 Das Bild binarisieren
Bei der Binarisierung oder Schwellenwertbildung wird das Bild nur in Schwarz-Weiß-Werte umgewandelt. Jedes Pixel in diesem Bild hat nur einen von zwei Werten, entweder schwarz oder weiß. Dadurch wird die Komplexität von Bildern drastisch reduziert. Wenn Sie Bilder mit Rauschen oder Bildern mit Schatten oder viel Text haben, können Sie diese Methode der Vorverarbeitung verwenden. Um dieses Bild zu binarisieren, vergewissern Sie sich, dass Sie zuerst ein Graustufenbild haben, und verwenden Sie dann den folgenden Befehl:
convert [input_file_path] -threshold 55% [output_file_path]
Der Schwellenwert % kann variiert werden, um das beste Ergebnis für Ihren Anwendungsfall zu erzielen. Bild unten zeigt ein Beispiel. Es ist wichtig zu beachten, dass für das vorliegende Bild die Binarisierung nicht die beste Option ist, da dabei einige Daten verloren gehen.
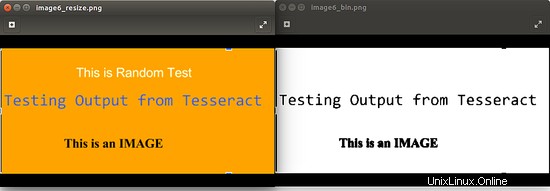
Die folgenden Punkte müssen beachtet werden, bevor eine oder alle der oben genannten Vorverarbeitungstechniken angewendet werden:
- Je nach Anwendungsfall ist einer der Vorverarbeitungsschritte oder eine Kombination davon sinnvoll.
- Wenn ein Vorverarbeitungsschritt zu einer Verringerung der Genauigkeit führt, sollte er von den Vorverarbeitungsschritten ignoriert werden.
- Die Prozentsätze beim Anpassen der Größe oder des Schwellenwerts variieren von Bild zu Bild, und daher muss eine Trial-and-Error-Methode angewendet werden, um den bestmöglichen Prozentwert zu erhalten, um die höchste Genauigkeit zu erzielen, wenn Tesseract ausgeführt wird
Führen Sie nach Abschluss der Vorverarbeitung Tesseract mit dem verarbeiteten Bild aus, um die Genauigkeit zu überprüfen. Tesseract ist sehr leistungsfähig, hat aber einige Einschränkungen, wenn es um die Art des Bildes geht, das als Eingabe angegeben wird. Ich hoffe, Sie fanden dieses Tutorial hilfreich.