Einführung
Apache Hive ist ein Enterprise-Data-Warehouse-System zum Abfragen, Verwalten und Analysieren von Daten, die im Hadoop Distributed File System gespeichert sind.
Die Hive Query Language (HiveQL) vereinfacht Abfragen in einer Hive-Befehlszeilenschnittstellen-Shell. Hadoop kann HiveQL als Brücke verwenden, um mit relationalen Datenbankverwaltungssystemen zu kommunizieren und Aufgaben basierend auf SQL-ähnlichen Befehlen auszuführen.
Diese einfache Anleitung zeigt Ihnen, wie Sie Apache Hive unter Ubuntu 20.04 installieren .

Voraussetzungen
Apache Hive basiert auf Hadoop und erfordert ein voll funktionsfähiges Hadoop-Framework.
Installieren Sie Apache Hive auf Ubuntu
Um Apache Hive zu konfigurieren, müssen Sie zuerst Hive herunterladen und entpacken. Dann müssen Sie die folgenden Dateien und Einstellungen anpassen:
- Bearbeiten Sie .bashrc Datei
- Bearbeiten Sie hive-config.sh Datei
- Erstellen Sie Hive-Verzeichnisse in HDFS
- Konfigurieren Sie hive-site.xml Datei
- Initiiere Derby-Datenbank
Schritt 1:Hive herunterladen und entpacken
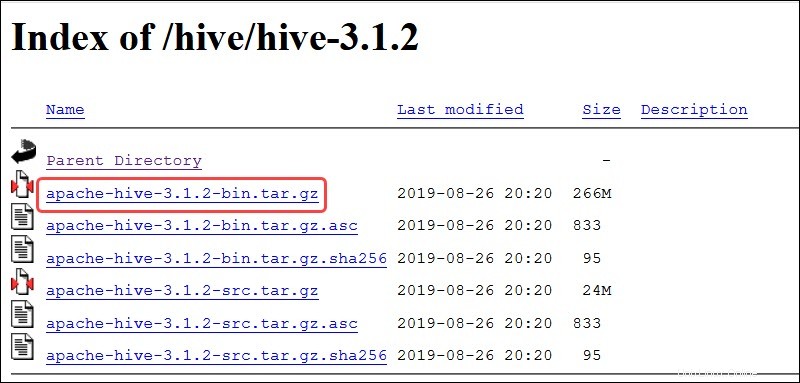
Besuchen Sie die offizielle Download-Seite von Apache Hive und bestimmen Sie, welche Hive-Version am besten für Ihre Hadoop-Edition geeignet ist. Sobald Sie festgestellt haben, welche Version Sie benötigen, wählen Sie Version jetzt herunterladen! aus Option.
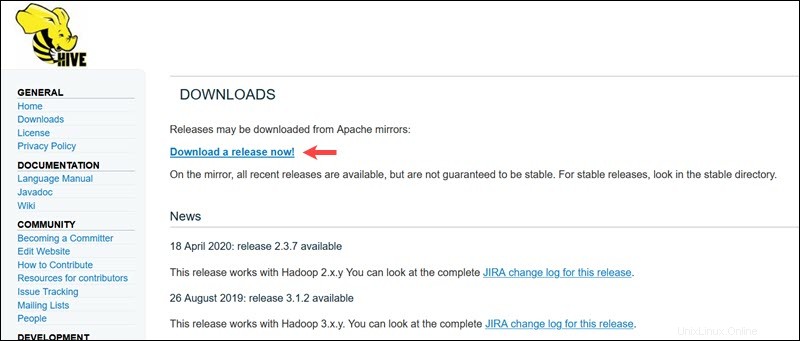
Der Mirror-Link auf der Folgeseite führt zu den Verzeichnissen, die verfügbare Hive-Tar-Pakete enthalten. Diese Seite enthält auch nützliche Anweisungen zur Überprüfung der Integrität von Dateien, die von Mirror-Sites abgerufen werden.
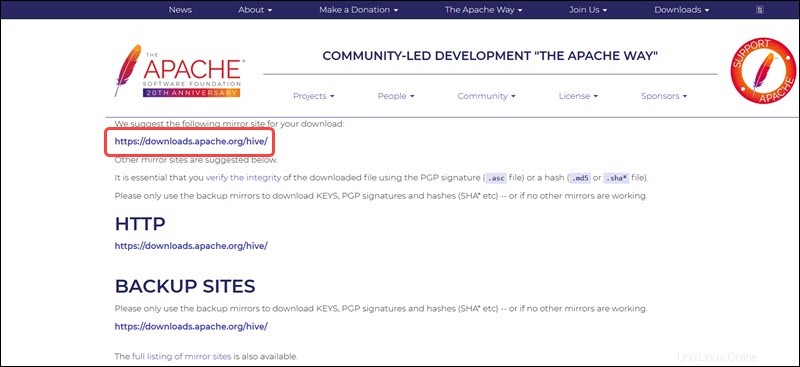
Das in diesem Handbuch vorgestellte Ubuntu-System verfügt bereits über Hadoop 3.2.1 Eingerichtet. Diese Hadoop-Version ist mit Hive 3.1.2 kompatibel freigeben.
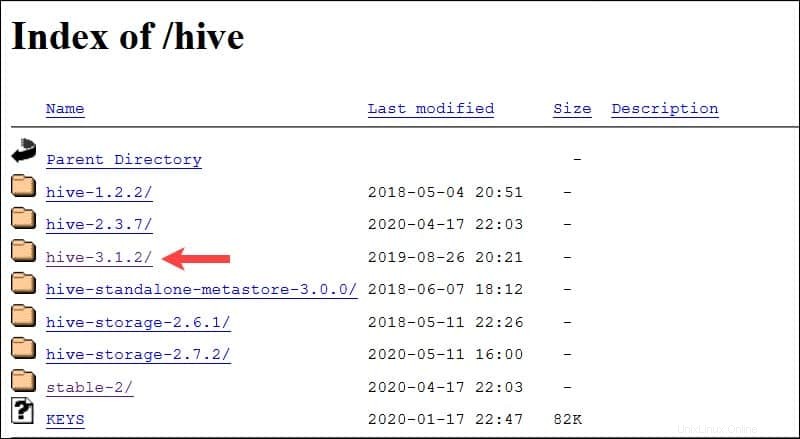
Wählen Sie apache-hive-3.1.2-bin.tar.gz aus Datei, um den Download-Vorgang zu starten.
Greifen Sie alternativ auf Ihre Ubuntu-Befehlszeile zu und laden Sie die komprimierten Hive-Dateien mithilfe von wget herunter Befehl gefolgt vom Download-Pfad:
wget https://downloads.apache.org/hive/hive-3.1.2/apache-hive-3.1.2-bin.tar.gz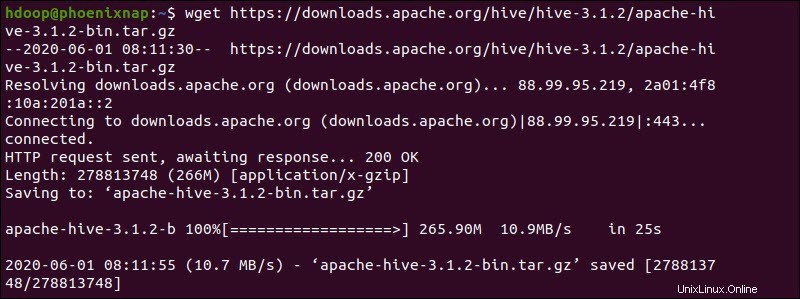
Sobald der Download-Vorgang abgeschlossen ist, entpacken Sie das komprimierte Hive-Paket:
tar xzf apache-hive-3.1.2-bin.tar.gzDie Hive-Binärdateien befinden sich jetzt im apache-hive-3.1.2-bin Verzeichnis.

Schritt 2:Hive-Umgebungsvariablen konfigurieren (bashrc)
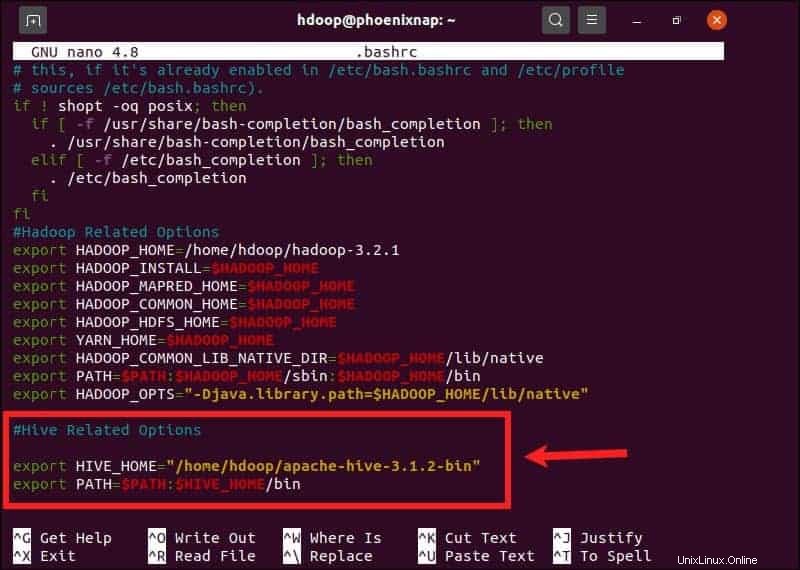
Der $HIVE_HOME Umgebungsvariable muss die Client-Shell zum apache-hive-3.1.2-bin leiten Verzeichnis. Bearbeiten Sie die .bashrc Shell-Konfigurationsdatei mit einem Texteditor Ihrer Wahl (wir verwenden nano):
sudo nano .bashrcHängen Sie die folgenden Hive-Umgebungsvariablen an .bashrc an Datei:
export HIVE_HOME= "home/hdoop/apache-hive-3.1.2-bin"
export PATH=$PATH:$HIVE_HOME/binDie Hadoop-Umgebungsvariablen befinden sich in derselben Datei.
Speichern und beenden Sie die .bashrc Datei, sobald Sie die Hive-Variablen hinzugefügt haben. Wenden Sie die Änderungen mit dem folgenden Befehl auf die aktuelle Umgebung an:
source ~/.bashrcSchritt 3:hive-config.sh-Datei bearbeiten
Apache Hive muss in der Lage sein, mit dem Hadoop Distributed File System zu interagieren. Greifen Sie auf hive-config.sh zu Datei mit dem zuvor erstellten $HIVE_HOME Variable:
sudo nano $HIVE_HOME/bin/hive-config.sh
Fügen Sie HADOOP_HOME hinzu -Variable und den vollständigen Pfad zu Ihrem Hadoop-Verzeichnis:
export HADOOP_HOME=/home/hdoop/hadoop-3.2.1
Speichern Sie die Änderungen und beenden Sie hive-config.sh Datei.
Schritt 4:Hive-Verzeichnisse in HDFS erstellen
Erstellen Sie zwei separate Verzeichnisse zum Speichern von Daten in der HDFS-Schicht:
- Das temporäre tmp Verzeichnis wird die Zwischenergebnisse von Hive-Prozessen speichern.
- Das Lager Verzeichnis wird die Hive-bezogenen Tabellen speichern.
tmp-Verzeichnis erstellen
Erstellen Sie ein tmp Verzeichnis innerhalb der HDFS-Speicherschicht. In diesem Verzeichnis werden die Zwischendaten gespeichert, die Hive an das HDFS sendet:
hdfs dfs -mkdir /tmpFügen Sie den Mitgliedern der tmp-Gruppe Schreib- und Ausführungsberechtigungen hinzu:
hdfs dfs -chmod g+w /tmpÜberprüfen Sie, ob die Berechtigungen korrekt hinzugefügt wurden:
hdfs dfs -ls /Die Ausgabe bestätigt, dass Benutzer jetzt über Schreib- und Ausführungsberechtigungen verfügen.

Lagerverzeichnis erstellen
Erstellen Sie das Lager Verzeichnis innerhalb von /user/hive/ übergeordnetes Verzeichnis:
hdfs dfs -mkdir -p /user/hive/warehouseFügen Sie schreiben hinzu und ausführen Berechtigungen für Warehouse Gruppenmitglieder:
hdfs dfs -chmod g+w /user/hive/warehouseÜberprüfen Sie, ob die Berechtigungen korrekt hinzugefügt wurden:
hdfs dfs -ls /user/hiveDie Ausgabe bestätigt, dass Benutzer jetzt über Schreib- und Ausführungsberechtigungen verfügen.

Schritt 5:Hive-site.xml-Datei konfigurieren (optional)
Apache Hive-Distributionen enthalten standardmäßig Vorlagenkonfigurationsdateien. Die Vorlagendateien befinden sich in der conf von Hive Verzeichnis und skizzieren Sie die Hive-Standardeinstellungen.
Verwenden Sie den folgenden Befehl, um die richtige Datei zu finden:
cd $HIVE_HOME/conf
Listen Sie die im Ordner enthaltenen Dateien mit ls auf Befehl.

Verwenden Sie die hive-default.xml.template um die hive-site.xml zu erstellen Datei:
cp hive-default.xml.template hive-site.xmlGreifen Sie auf die hive-site.xml zu Datei mit dem Nano-Texteditor:
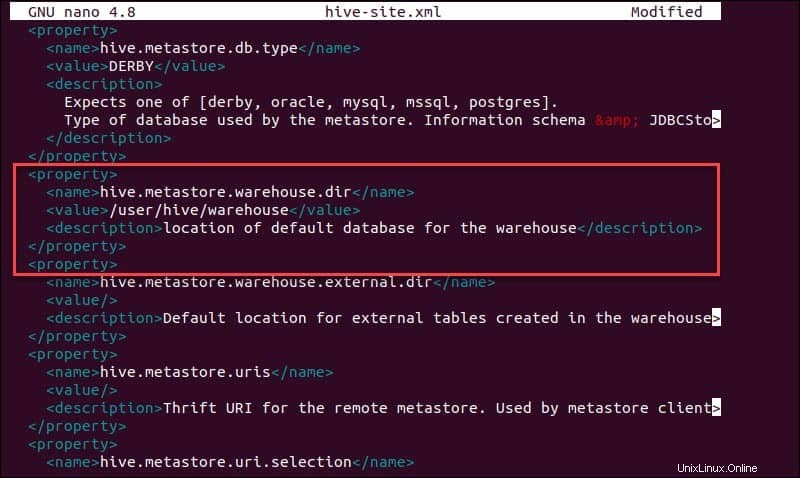
sudo nano hive-site.xmlDie Verwendung von Hive in einem eigenständigen Modus statt in einem echten Apache Hadoop-Cluster ist eine sichere Option für Neueinsteiger. Sie können das System so konfigurieren, dass es Ihren lokalen Speicher anstelle der HDFS-Schicht verwendet, indem Sie hive.metastore.warehouse.dir festlegen Parameterwert an den Standort Ihres Hive-Lagers Verzeichnis.
Schritt 6:Derby-Datenbank initiieren
Apache Hive verwendet die Derby-Datenbank zum Speichern von Metadaten. Initiieren Sie die Derby-Datenbank aus dem Hive-Bin Verzeichnis mit dem schematool Befehl:
$HIVE_HOME/bin/schematool -dbType derby -initSchemaDer Vorgang kann einige Augenblicke dauern.
Derby ist der Standard-Metadatenspeicher für Hive. Wenn Sie eine andere Datenbanklösung wie MySQL oder PostgreSQL verwenden möchten, können Sie in der hive-site.xml einen Datenbanktyp angeben Datei.
So beheben Sie den Guaven-Inkompatibilitätsfehler in Hive
Wenn die Derby-Datenbank nicht erfolgreich initiiert wird, erhalten Sie möglicherweise eine Fehlermeldung mit folgendem Inhalt:
„Ausnahme im Thread „main“ java.lang.NoSuchMethodError:com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;)V“
Dieser Fehler weist darauf hin, dass höchstwahrscheinlich ein Inkompatibilitätsproblem zwischen Hadoop und Hive Guava besteht Versionen.
Suchen Sie das Guavaglas Datei in der Hive lib Verzeichnis:
ls $HIVE_HOME/lib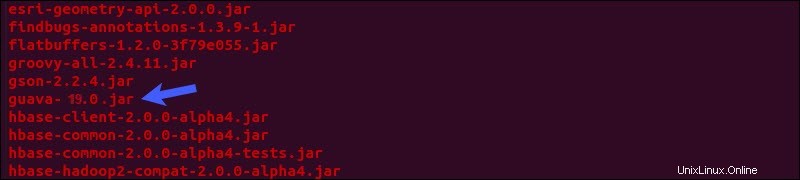
Suchen Sie das Guavaglas Datei in der Hadoop lib auch Verzeichnis:
ls $HADOOP_HOME/share/hadoop/hdfs/lib
Die beiden aufgeführten Versionen sind nicht kompatibel und verursachen den Fehler. Entfernen Sie die vorhandene Guave Datei aus der Hive lib Verzeichnis:
rm $HIVE_HOME/lib/guava-19.0.jarKopieren Sie die Guave Datei aus der lib von Hadoop Verzeichnis in die Hive lib Verzeichnis:
cp $HADOOP_HOME/share/hadoop/hdfs/lib/guava-27.0-jre.jar $HIVE_HOME/lib/
Verwenden Sie das schematool Befehl erneut, um die Derby-Datenbank zu initialisieren:
$HIVE_HOME/bin/schematool -dbType derby -initSchemaStarten Sie die Hive-Client-Shell auf Ubuntu
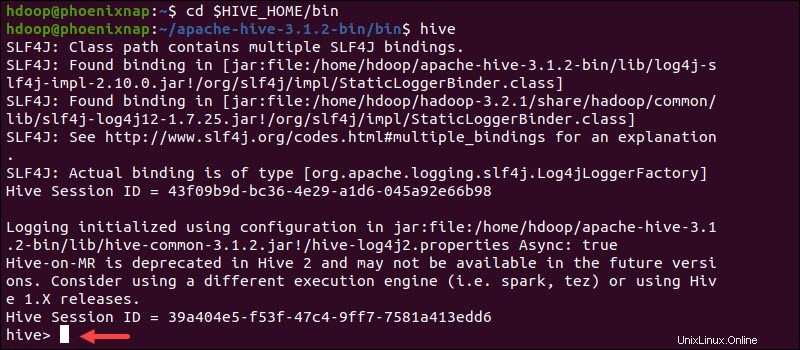
Starten Sie die Hive-Befehlszeilenschnittstelle mit den folgenden Befehlen:
cd $HIVE_HOME/binhiveSie können jetzt SQL-ähnliche Befehle ausführen und direkt mit HDFS interagieren.