Einführung
Zu lernen, wie man einen Spark DataFrame erstellt, ist einer der ersten praktischen Schritte in der Spark-Umgebung. Spark DataFrames helfen dabei, einen Einblick in die Datenstruktur und andere Datenbearbeitungsfunktionen zu geben. Je nach Datenquelle und Datenspeicherformat der Dateien gibt es unterschiedliche Methoden.
In diesem Artikel wird erläutert, wie Sie mit PySpark manuell einen Spark-DataFrame in Python erstellen.

Voraussetzungen
- Python 3 installiert und konfiguriert.
- PySpark installiert und konfiguriert.
- Eine Python-Entwicklungsumgebung zum Testen der Codebeispiele (wir verwenden das Jupyter Notebook).
Methoden zum Erstellen von Spark DataFrame
Es gibt drei Möglichkeiten, einen DataFrame in Spark von Hand zu erstellen:
1. Erstellen Sie eine Liste und parsen Sie sie als DataFrame mit toDataFrame() -Methode aus der SparkSession .
2. Konvertieren Sie ein RDD mit toDF() in einen DataFrame Methode.
3. Importieren Sie eine Datei in eine SparkSession als DataFrame direkt.
Die Beispiele verwenden Beispieldaten und ein RDD zur Demonstration, obwohl allgemeine Prinzipien für ähnliche Datenstrukturen gelten.
DataFrame aus einer Datenliste erstellen
So erstellen Sie einen Spark DataFrame aus einer Datenliste:
1. Generieren Sie eine Beispiel-Wörterbuchliste mit Spielzeugdaten:
data = [{"Category": 'A', "ID": 1, "Value": 121.44, "Truth": True},
{"Category": 'B', "ID": 2, "Value": 300.01, "Truth": False},
{"Category": 'C', "ID": 3, "Value": 10.99, "Truth": None},
{"Category": 'E', "ID": 4, "Value": 33.87, "Truth": True}
]
2. Importieren und erstellen Sie eine SparkSession :
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
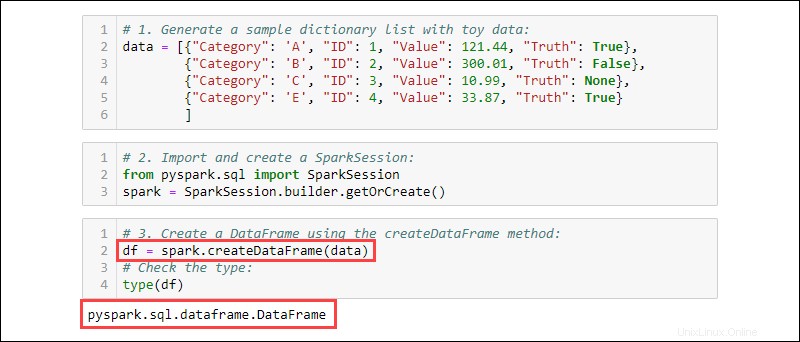
3. Erstellen Sie einen DataFrame mit createDataFrame Methode. Überprüfen Sie den Datentyp, um zu bestätigen, dass die Variable ein DataFrame ist:
df = spark.createDataFrame(data)
type(df)
DataFrame aus RDD erstellen
Ein typisches Ereignis beim Arbeiten in Spark ist das Erstellen eines DataFrame aus einem vorhandenen RDD. Erstellen Sie ein Beispiel-RDD und konvertieren Sie es dann in einen DataFrame.
1. Erstellen Sie eine Wörterbuchliste mit Spielzeugdaten:
data = [{"Category": 'A', "ID": 1, "Value": 121.44, "Truth": True},
{"Category": 'B', "ID": 2, "Value": 300.01, "Truth": False},
{"Category": 'C', "ID": 3, "Value": 10.99, "Truth": None},
{"Category": 'E', "ID": 4, "Value": 33.87, "Truth": True}
]
2. Importieren und erstellen Sie einen SparkContext :
from pyspark import SparkContext, SparkConf
conf = SparkConf().setAppName("projectName").setMaster("local[*]")
sc = SparkContext.getOrCreate(conf)
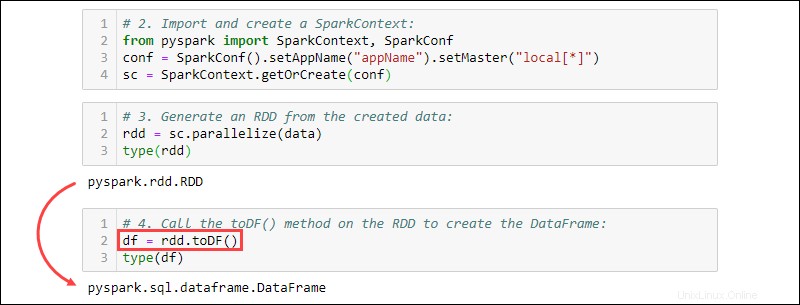
3. Generieren Sie aus den erstellten Daten ein RDD. Überprüfen Sie den Typ, um zu bestätigen, dass das Objekt ein RDD ist:
rdd = sc.parallelize(data)
type(rdd)
4. Rufen Sie toDF() auf -Methode auf dem RDD, um den DataFrame zu erstellen. Testen Sie den Objekttyp zur Bestätigung:
df = rdd.toDF()
type(df)
DataFrame aus Datenquellen erstellen
Spark kann eine Vielzahl externer Datenquellen verarbeiten, um DataFrames zu erstellen. Die allgemeine Syntax zum Lesen aus einer Datei lautet:
spark.read.format('<data source>').load('<file path/file name>')Der Name und der Pfad der Datenquelle sind beide String-Typen. Bestimmte Datenquellen haben auch eine alternative Syntax zum Importieren von Dateien als DataFrames.
Aus CSV-Datei erstellen
Erstellen Sie einen Spark DataFrame, indem Sie direkt aus einer CSV-Datei lesen:
df = spark.read.csv('<file name>.csv')Lesen Sie mehrere CSV-Dateien in einen DataFrame, indem Sie eine Liste mit Pfaden bereitstellen:
df = spark.read.csv(['<file name 1>.csv', '<file name 2>.csv', '<file name 3>.csv'])
Standardmäßig fügt Spark für jede Spalte eine Überschrift hinzu. Wenn eine CSV-Datei einen Header enthält, den Sie einschließen möchten, fügen Sie die option hinzu Methode beim Importieren:
df = spark.read.csv('<file name>.csv').option('header', 'true')
Einzelne Optionen werden gestapelt, indem sie nacheinander aufgerufen werden. Verwenden Sie alternativ die options Methode, wenn während des Imports mehr Optionen benötigt werden:
df = spark.read.csv('<file name>.csv').options(header = True)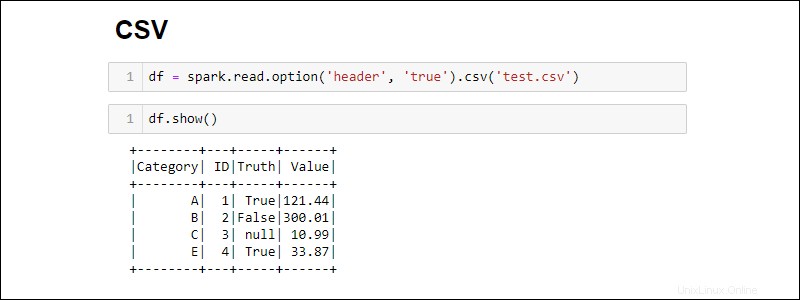
Beachten Sie, dass sich die Syntax bei Verwendung von unterscheidet option vs. options .
Aus TXT-Datei erstellen
Erstellen Sie einen DataFrame aus einer Textdatei mit:
df = spark.read.text('<file name>.txt')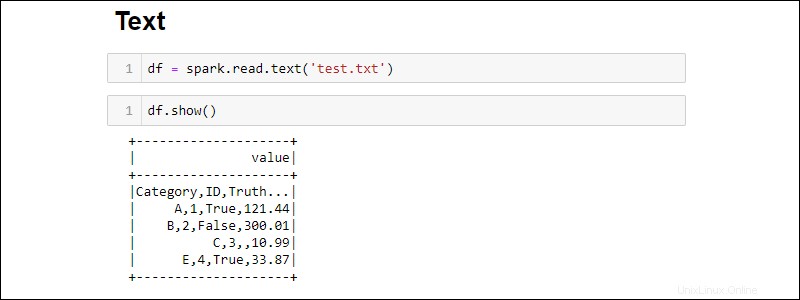
Die csv -Methode ist eine weitere Möglichkeit, aus einem txt zu lesen Dateityp in einen DataFrame. Zum Beispiel:
df = spark.read.option('header', 'true').csv('<file name>.txt')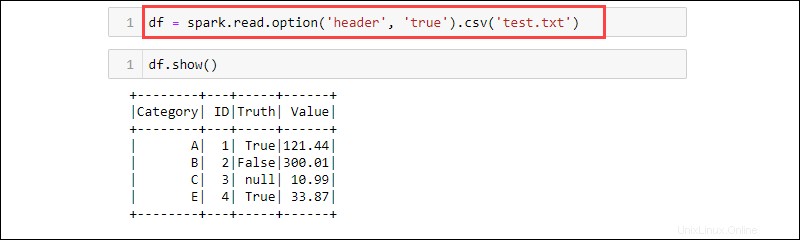
CSV ist ein Textformat, bei dem das Trennzeichen ein Komma (,) ist und die Funktion daher Daten aus einer Textdatei lesen kann.
Aus JSON-Datei erstellen
Erstellen Sie einen Spark DataFrame aus einer JSON-Datei, indem Sie Folgendes ausführen:
df = spark.read.json('<file name>.json')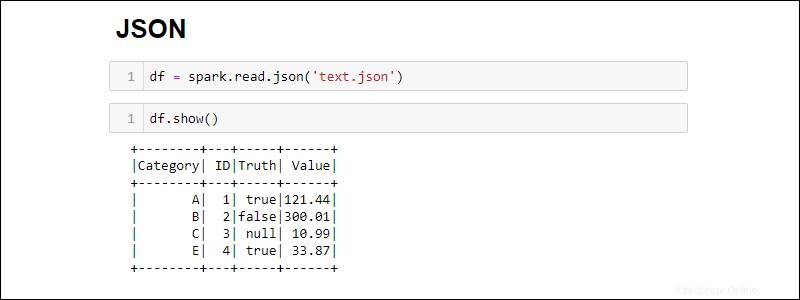
Erstellen aus einer XML-Datei
XML-Dateikompatibilität ist standardmäßig nicht verfügbar. Installieren Sie die Abhängigkeiten, um einen DataFrame aus einer XML-Quelle zu erstellen.
1. Laden Sie die Spark-XML-Abhängigkeit herunter. Speichern Sie die .jar Datei im JAR-Ordner von Spark.
2. Lesen Sie eine XML-Datei in einen DataFrame, indem Sie Folgendes ausführen:
df = spark.read\
.format('com.databricks.spark.xml')\
.option('rowTag', 'row')\
.load('test.xml')
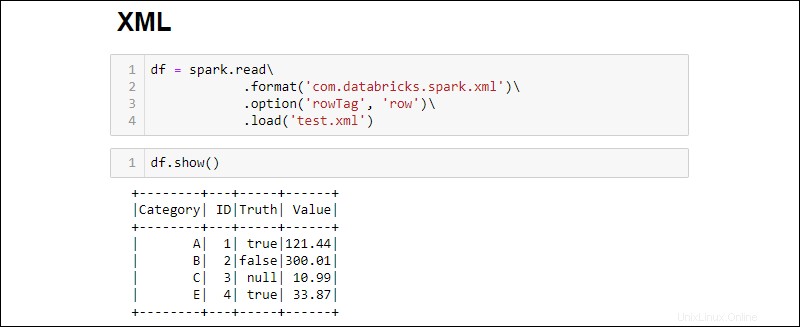
Ändern Sie das rowTag Option für jede Zeile in Ihrem XML Datei ist anders beschriftet.
DataFrame aus RDBMS-Datenbank erstellen
Das Lesen aus einem RDBMS erfordert einen Treiberanschluss. Das Beispiel zeigt, wie man eine Verbindung herstellt und Daten aus einer MySQL-Datenbank zieht. Ähnliche Schritte funktionieren für andere Datenbanktypen.
1. Laden Sie den MySQL-Java-Treiber-Connector herunter. Speichern Sie die .jar Datei im JAR-Ordner von Spark.
2. Führen Sie den SQL-Server aus und stellen Sie eine Verbindung her.
3. Stellen Sie eine Verbindung her und holen Sie die gesamte MySQL-Datenbanktabelle in einen DataFrame:
df = spark.read\
.format('jdbc')\
.option('url', 'jdbc:mysql://localhost:3306/db')\
.option('driver', 'com.mysql.jdbc.Driver')\
.option('dbtable','new_table')\
.option('user','root')\
.load()
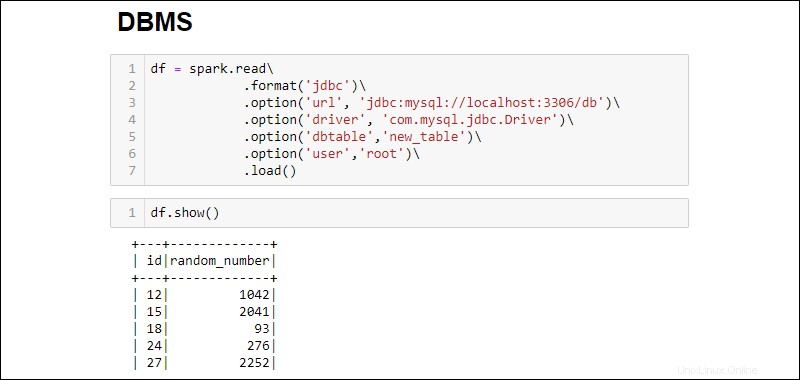
Die hinzugefügten Optionen lauten wie folgt:
- Die URL ist
localhost:3306wenn der Server lokal läuft. Andernfalls rufen Sie die URL Ihres Datenbankservers ab. - Datenbankname erweitert die URL, um auf eine bestimmte Datenbank auf dem Server zuzugreifen. Wenn beispielsweise eine Datenbank
dbheißt und der Server lokal läuft, lautet die vollständige URL zum Herstellen einer Verbindungjdbc:mysql://localhost:3306/db. - Tabellenname stellt sicher, dass die gesamte Datenbanktabelle in den DataFrame gezogen wird. Verwenden Sie
.option('query', '<query>')statt.option('dbtable', '<table name>')um eine bestimmte Abfrage auszuführen, anstatt eine ganze Tabelle auszuwählen. - Verwenden Sie den Benutzernamen und Passwort der Datenbank für den Verbindungsaufbau. Wenn Sie ohne Passwort laufen, lassen Sie die angegebene Option weg.