Einführung
Die Datenbanknormalisierung ist eine Methode im relationalen Datenbankdesign, die dabei hilft, Datentabellen richtig zu organisieren. Der Prozess zielt darauf ab, ein System zu schaffen, das Informationen und Beziehungen ohne Datenverlust oder Redundanz originalgetreu darstellt.
In diesem Artikel wird die Datenbanknormalisierung und die Normalisierung einer Datenbank anhand eines praktischen Beispiels erläutert.

Was ist Datenbanknormalisierung?
Datenbanknormalisierung ist eine Technik zum Erstellen von Datenbanktabellen mit geeigneten Spalten und Schlüsseln, indem eine große Tabelle in kleinere logische Einheiten zerlegt wird. Der Prozess berücksichtigt auch die Anforderungen der Umgebung, in der sich die Datenbank befindet.
Normalisierung ist ein iterativer Prozess. Üblicherweise erfolgt die Normalisierung einer Datenbank durch eine Reihe von Tests. Jeder nachfolgende Schritt zerlegt Tabellen in besser verwaltbare Informationen, wodurch die gesamte Datenbank logisch und einfacher zu handhaben ist.
Warum ist die Datenbanknormalisierung wichtig?
Die Normalisierung hilft einem Datenbankdesigner, Attribute optimal in Tabellen zu verteilen. Die Technik eliminiert Folgendes:
- Attribute mit mehreren Werte.
- Verdoppelt oder wiederholt Attribute.
- Nicht beschreibend Attribute.
- Attribute mit redundant Informationen.
- Attribute, die aus anderen Funktionen erstellt wurden .
Obwohl eine vollständige Datenbanknormalisierung nicht erforderlich ist, bietet sie eine gut funktionierende Informationsumgebung. Die Methode stellt systematisch sicher:
- Eine Datenbankstruktur geeignet für allgemeine Abfragen.
- Minimierte Datenredundanz , wodurch die Speichereffizienz auf einem Datenbankserver erhöht wird.
- Maximierte Datenintegrität durch die reduzierten Insert-, Update- und Delete-Anomalien.
Die Datenbanknormalisierung transformiert die gesamte Datenbankkonsistenz und stellt eine effiziente Umgebung bereit.
Datenbankredundanzen und Anomalien
Beim Ändern einer Entität in einer Tabelle mit Redundanzen , müssen Sie alle wiederholten Instanzen von Informationen und alle anderen Informationen im Zusammenhang mit den geänderten Daten ändern. Andernfalls wird die Datenbank inkonsistent und Anomalien passieren, wenn Änderungen vorgenommen werden.
Beispielsweise in der folgenden nicht normalisierten Tabelle:

Die Tabelle enthält Daten Redundanz , was wiederum drei Anomalien verursacht bei Datenänderungen:
1. Anomalie einfügen . Wenn Sie versuchen, einen neuen Mitarbeiter in der Finanzbranche einzustellen, müssen Sie auch den Namen des Managers kennen. Andernfalls können Sie keine Daten in die Tabelle einfügen.
2. Update-Anomalie. Wenn ein Mitarbeiter die Branche wechselt, ist der Name des Managers falsch. Wenn Jacob beispielsweise in die Finanzabteilung wechselt, bleibt Adam sein Manager.
3. Anomalie löschen . Wenn Joshua beschließt, das Unternehmen zu verlassen, wird durch das Löschen der Zeile auch die Information entfernt, dass ein Finanzsektor existiert.
Die Lösung für diese Anomalien liegt in der Datenbanknormalisierung Konzepte und Schritte.
Datenbanknormalisierungskonzepte
Die elementaren Konzepte, die bei der Datenbanknormalisierung verwendet werden, sind:
- Schlüssel . Spaltenattribute, die einen Datenbankeintrag eindeutig identifizieren.
- Funktionale Abhängigkeiten . Einschränkungen zwischen zwei Attributen in einer Beziehung.
- Normale Formen . Schritte, um eine bestimmte Qualität einer Datenbank zu erreichen.
Datenbank-Normalformen
Das Normalisieren einer Datenbank wird durch eine Reihe von Regeln erreicht, die als Normalformen bekannt sind . Das zentrale Konzept besteht darin, einem Datenbankdesigner dabei zu helfen, die gewünschte Qualität einer relationalen Datenbank zu erreichen.
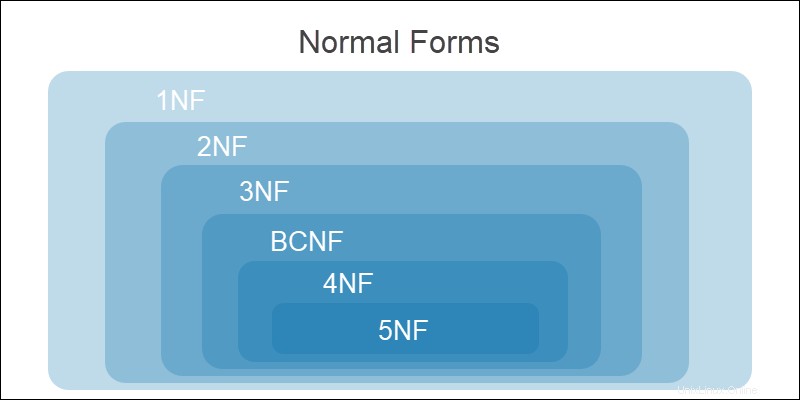
Alle Ebenen der Normalisierung sind kumulativ. Bisherige Normalform Anforderungen müssen erfüllt sein bevor Sie mit dem folgenden Formular fortfahren.
Die Stadien der Normalisierung sind:
| Bühne | Redundanzanomalien behoben |
|---|---|
| Nicht normalisierte Form (UNF) | Der Zustand vor jeglicher Normalisierung. Redundante und komplexe Werte sind vorhanden. |
| Erste Normalform (1NF) | Sich wiederholende und komplexe Werte werden aufgeteilt, wodurch alle Instanzen atomar werden. |
| Zweite Normalform (2NF) | Teilabhängigkeiten werden in neue Tabellen zerlegt. Alle Zeilen hängen funktional vom Primärschlüssel ab. |
| Dritte Normalform (3NF) | Transitive Abhängigkeiten werden in neue Tabellen zerlegt. Nicht-Schlüsselattribute hängen vom Primärschlüssel ab. |
| Boyce-Codd-Normalform (BCNF) | Transitive und teilweise funktionale Abhängigkeiten für alle Kandidatenschlüssel werden in neue Tabellen zerlegt. |
| Vierte Normalform (4NF) | Entfernung mehrwertiger Abhängigkeiten. |
| Fünfte Normalform (5NF) | Entfernung von JOIN-Abhängigkeiten. |
Eine Datenbank ist normalisiert, wenn sie die dritte Normalform erfüllt . Weitere Normalisierungsschritte machen das Datenbankdesign kompliziert und könnten die Funktionalität des Systems beeinträchtigen.
Was ist ein SCHLÜSSEL?
Ein Datenbankschlüssel ist ein Attribut oder eine Gruppe von Merkmalen, die eine Entität in einer Tabelle eindeutig beschreibt. Die bei der Normalisierung verwendeten Schlüsseltypen sind:
- Superschlüssel . Eine Reihe von Funktionen, die jeden Datensatz in einer Tabelle eindeutig definieren.
- Kandidatenschlüssel . Aus dem Satz von Superschlüsseln ausgewählte Schlüssel, bei denen die Anzahl der Felder minimal ist.
- Primärschlüssel . Die am besten geeignete Wahl aus der Menge der Kandidatenschlüssel dient als Primärschlüssel der Tabelle.
- Fremdschlüssel . Der Primärschlüssel einer anderen Tabelle.
- Zusammengesetzter Schlüssel . Zwei oder mehr Attribute bilden zusammen einen eindeutigen Schlüssel, sind aber einzeln keine Schlüssel.
Wenn Tabellen in mehrere einfachere Tabellen zerlegt werden, definieren Schlüssel einen Bezugspunkt für eine Datenbankentität.
Beispielsweise in der folgenden Datenbankstruktur:

Einige Beispiele für Superschlüssel in der Tabelle sind:
- Mitarbeiter-ID
- (Mitarbeiter-ID, Name)
Alle Superschlüssel können als eindeutige Kennung für jede Zeile dienen. Andererseits sind der Name oder das Alter des Mitarbeiters keine eindeutigen Identifikatoren, da zwei Personen denselben Namen oder dasselbe Alter haben können.
Die Kandidatenschlüssel stammen aus der Menge der Superschlüssel, bei denen die Anzahl der Felder minimal ist. Die Wahl besteht aus zwei Optionen:
- Mitarbeiter-ID
Beide Optionen enthalten eine minimale Anzahl von Feldern, was sie zu optimalen Schlüsselkandidaten macht. Die logischste Wahl für den Primärschlüssel ist die Mitarbeiter-ID da sich die E-Mail-Adresse eines Mitarbeiters ändern kann. Der Primärschlüssel in der Tabelle kann leicht als Fremdschlüssel referenziert werden in einer anderen Tabelle.
Funktionale Datenbankabhängigkeiten
Eine funktionale Datenbankabhängigkeit stellt eine Beziehung zwischen zwei Attributen in einer Datenbanktabelle dar. Einige Arten von funktionalen Abhängigkeiten sind:
- Triviale funktionelle Abhängigkeit . Eine Abhängigkeit zwischen einem Attribut und einer Gruppe von Merkmalen, wobei sich das ursprüngliche Element in der Gruppe befindet.
- Nicht triviale funktionelle Abhängigkeit . Eine Abhängigkeit zwischen einem Attribut und einer Gruppe, in der sich das Feature nicht in der Gruppe befindet.
- Transitive Abhängigkeit. Eine funktionale Abhängigkeit zwischen drei Attributen, wobei das zweite vom ersten und das dritte vom zweiten abhängt. Aufgrund der Transitivität ist das dritte Attribut vom ersten abhängig.
- Mehrwertige Abhängigkeit. Eine Abhängigkeit, bei der mehrere Werte von einem Attribut abhängen.
Funktionale Abhängigkeiten sind ein wesentlicher Schritt bei der Datenbanknormalisierung. Auf lange Sicht helfen die Abhängigkeiten dabei, die Gesamtqualität einer Datenbank zu bestimmen.
Beispiel einer Datenbanknormalisierung – Wie normalisiert man eine Datenbank?
Die allgemeinen Schritte der Datenbanknormalisierung funktionieren für jede Datenbank. Die spezifischen Schritte zum Teilen der Tabelle sowie ob über 3NF hinausgegangen werden soll, hängen vom Anwendungsfall ab.
Beispiel einer nicht normalisierten Datenbank
Eine nicht normalisierte Tabelle enthält mehrere Werte in einem einzelnen Feld sowie im schlimmsten Fall redundante Informationen.
Zum Beispiel:
| Manager-ID | ManagerName | Bereich | Mitarbeiter-ID | Mitarbeitername | Sektor-ID | Sektorname |
|---|---|---|---|---|---|---|
| 1 | Adam A. | Ost | 1 2 | David D. Eugen E. | 4 3 | Finanzen ES |
| 2 | Betty B. | Westen | 3 4 5 | George G. Heinrich H. Ingrid I. | 2 1 4 | Sicherheit Verwaltung Finanzen |
| 3 | Carl C. | Norden | 6 7 | James J. Katy K. | 1 4 | Verwaltung Finanzen |
Das Einfügen, Aktualisieren und Entfernen von Daten ist eine komplexe Aufgabe. Wenn Sie Änderungen an der vorhandenen Tabelle vornehmen, besteht ein hohes Risiko, dass Informationen verloren gehen.
Schritt 1:Erste Normalform 1NF
Um die Datenbanktabelle in die 1NF umzuwandeln, müssen Werte innerhalb eines einzelnen Felds atomar sein. Alle komplexen Entitäten in der Tabelle werden in neue Zeilen oder Spalten unterteilt.
Die Informationen in den Spalten managerID , managerName , und Bereich Wiederholen Sie dies für jeden Mitarbeiter, um sicherzustellen, dass keine Informationen verloren gehen.
| Manager-ID | ManagerName | Bereich | Mitarbeiter-ID | Mitarbeitername | Sektor-ID | Sektorname |
|---|---|---|---|---|---|---|
| 1 | Adam A. | Ost | 1 | David D. | 4 | Finanzen |
| 1 | Adam A. | Ost | 2 | Eugene E. | 3 | IT |
| 2 | Betty B. | Westen | 3 | George G. | 2 | Sicherheit |
| 2 | Betty B. | Westen | 4 | Henry H. | 1 | Verwaltung |
| 2 | Betty B. | Westen | 5 | Ingrid I. | 4 | Finanzen |
| 3 | Carl C. | Norden | 6 | James J. | 1 | Verwaltung |
| 3 | Carl C. | Norden | 7 | Katy K. | 4 | Finanzen |
Die überarbeitete Tabelle erfüllt die erste Normalform.
Schritt 2:Zweite Normalform 2NF
Die zweite Normalform der Datenbanknormalisierung besagt, dass jede Zeile in der Datenbanktabelle vom Primärschlüssel abhängen muss.
Die Tabelle teilt sich in zwei Tabellen auf, um die Normalform zu erfüllen:
- Manager (ManagerID, ManagerName, Bereich)
| Manager-ID | ManagerName | Bereich |
|---|---|---|
| 1 | Adam A. | Ost |
| 2 | Betty B. | Westen |
| 3 | Carl C. | Norden |
- Mitarbeiter (EmployeeID, EmployeeName, ManagerID, SectorID, SectorName)
| Mitarbeiter-ID | Mitarbeitername | Manager-ID | Sektor-ID | Sektorname |
|---|---|---|---|---|
| 1 | David D. | 1 | 4 | Finanzen |
| 2 | Eugene E. | 1 | 3 | IT |
| 3 | George G. | 2 | 2 | Sicherheit |
| 4 | Henry H. | 2 | 1 | Verwaltung |
| 5 | Ingrid I. | 2 | 4 | Finanzen |
| 6 | James J. | 3 | 1 | Verwaltung |
| 7 | Katy K. | 3 | 4 | Finanzen |
Die resultierende Datenbank in der zweiten Normalform besteht derzeit aus zwei Tabellen ohne partielle Abhängigkeiten.
Schritt 3:Dritte Normalform 3NF
Die dritte Normalform zerlegt alle transitiven funktionalen Abhängigkeiten. Aktuell die Tabelle Mitarbeiter hat eine transitive Abhängigkeit, die in zwei neue Tabellen zerfällt:
- Mitarbeiter (EmployeeID, EmployeeName, ManagerID, SectorID)
| Mitarbeiter-ID | Mitarbeitername | Manager-ID | Sektor-ID |
|---|---|---|---|
| 1 | David D. | 1 | 4 |
| 2 | Eugene E. | 1 | 3 |
| 3 | George G. | 2 | 2 |
| 4 | Henry H. | 2 | 1 |
| 5 | Ingrid I. | 2 | 4 |
| 6 | James J. | 3 | 1 |
| 7 | Katy K. | 3 | 4 |
- Sektor (Sektor-ID, Sektorname)
| Sektor-ID | Sektorname |
|---|---|
| 1 | Verwaltung |
| 2 | Sicherheit |
| 3 | IT |
| 4 | Finanzen |
Die Datenbank befindet sich derzeit in der dritten Normalform mit insgesamt drei Relationen. Die endgültige Struktur ist:

An diesem Punkt ist die Datenbank normalisiert . Alle weiteren Normalisierungsschritte hängen vom Anwendungsfall der Daten ab.