Elasticsearch ist eine hochgradig skalierbare Open-Source-Volltextsuch- und Analysemaschine . Es ist im Allgemeinen die zugrunde liegende Engine/Technologie, die Anwendungen mit komplexen Suchfunktionen und -anforderungen unterstützt. Die Software unterstützt RESTful-Vorgänge, mit denen Sie große Datenmengen schnell und nahezu in Echtzeit speichern, durchsuchen und analysieren können. Elasticsearch ist bei Systemadministratoren und Entwicklern sehr beliebt und beliebt, da es sich um eine mächtige Suchmaschine handelt, die auf der Lucene-Bibliothek basiert.
Im folgenden Tutorial erfahren Sie, wie Sie Elastic Search auf openSUSE Leap 15 installieren .
Voraussetzungen
- Empfohlenes Betriebssystem: openSUSE Leap – 15.x
- Benutzerkonto: Ein Benutzerkonto mit Sudo- oder Root-Zugriff.
Betriebssystem aktualisieren
Aktualisieren Sie Ihr openSUSE Betriebssystem, um sicherzustellen, dass alle vorhandenen Pakete auf dem neuesten Stand sind:
sudo zypper refreshDas Tutorial verwendet den sudo-Befehl und vorausgesetzt, Sie haben den Sudo-Status .
So überprüfen Sie den Sudo-Status Ihres Kontos:
sudo whoamiBeispielausgabe, die den Sudo-Status zeigt:
[joshua@opensuse ~]$ sudo whoami
rootUm ein bestehendes oder neues Sudo-Konto einzurichten, besuchen Sie unser Tutorial zum Hinzufügen eines Benutzers zu Sudoers auf openSUSE .
So verwenden Sie das Root-Konto verwenden Sie den folgenden Befehl mit dem Root-Passwort, um sich anzumelden.
suCURL-Paket installieren
Die CURL Der Befehl wird für einige Teile dieses Handbuchs benötigt. Um dieses Paket zu installieren, geben Sie den folgenden Befehl ein:
sudo zyper install curlJava-Paket installieren
Um Elasticsearch erfolgreich zu installieren und, was noch wichtiger ist, zu verwenden , müssen Sie Java installieren . Der Vorgang ist relativ einfach.
Geben Sie den folgenden Befehl ein, um OpenJDK zu installieren Paket:
sudo zypper install java-11-openjdk-develElasticsearch installieren
Elasticsearch ist nicht verfügbar im Standard-openSUSE-Repository , also müssen Sie es aus dem Elasticsearch-Repository installieren .
Bevor Sie das Repository hinzufügen, importieren Sie den GPG-Schlüssel mit folgendem Befehl:
sudo rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearchDer nächste Schritt besteht darin, eine Elasticsearch-Repository-Datei wie folgt zu erstellen:
sudo zypper ar https://artifacts.elastic.co/packages/7.x/yum elasticsearchInstallieren Sie jetzt Elasticsearch mit dem folgenden Befehl:
sudo zypper install elasticsearchBeispielausgabe:
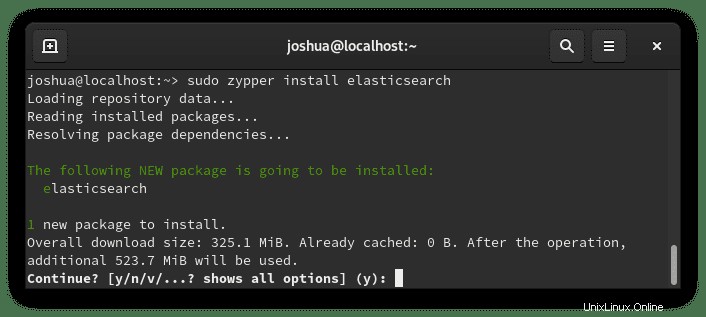
Geben Sie "Y" ein Drücken Sie dann die "ENTER-TASTE" um mit der Installation fortzufahren
Damit Elasticsearch standardmäßig aktiviert wird, müssen Sie das insserv-Paket installieren .
sudo zypper install insservStandardmäßig ist der Elasticsearch-Dienst beim Booten deaktiviert und nicht aktiv. Um den Dienst zu starten und beim Systemstart zu aktivieren, geben Sie Folgendes ein:(systemctl) Befehl:
sudo systemctl enable elasticsearch.service --nowBeispielausgabe:
Synchronizing state of elasticsearch.service with SysV service script with /usr/lib/systemd/systemd-sysv-install.
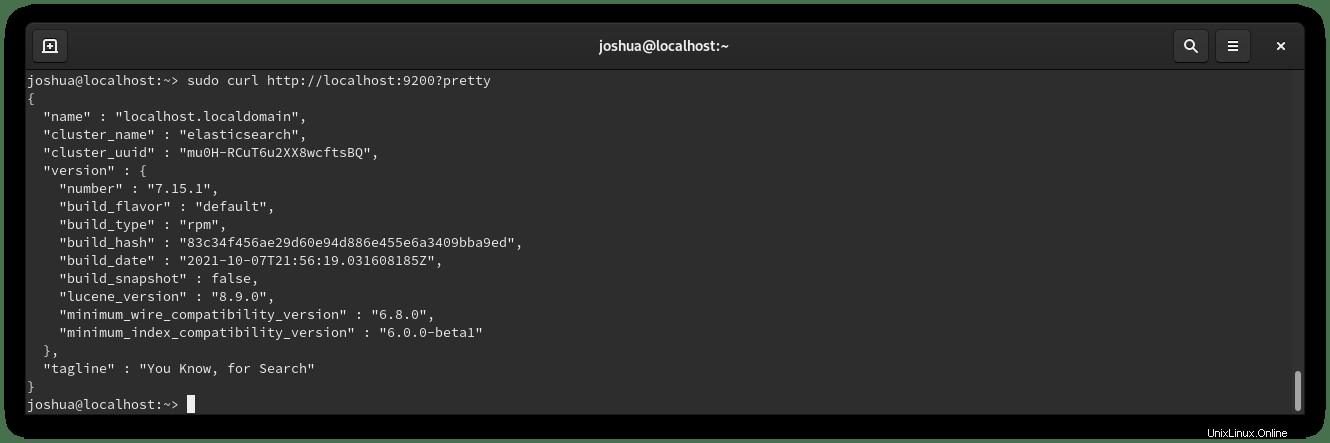
Executing: /usr/lib/systemd/systemd-sysv-install enable elasticsearchÜberprüfen Sie, ob Elasticsearch ordnungsgemäß ausgeführt wird, indem Sie den curl-Befehl verwenden um eine HTTP-Anfrage zu senden an Port 9200 auf localhost wie folgt:
sudo curl http://localhost:9200?prettyBeispielausgabe:
So konfigurieren Sie Elasticsearch
Elasticsearch-Daten werden im Standardverzeichnis (/var/lib/elasticsearch) gespeichert . Um die Konfigurationsdateien anzuzeigen oder zu bearbeiten, finden Sie sie im Verzeichnis (/etc/elasticsearch) , und Java-Startoptionen können in (/etc/default/elasticsearch) konfiguriert werden Konfigurationsdatei.
Die Standardeinstellungen sind in erster Linie für einzelne Server in Ordnung, da Elasticsearch auf localhost ausgeführt wird nur. Wenn Sie jedoch einen Cluster einrichten, müssen Sie die Konfigurationsdatei ändern, um Remote-Verbindungen zuzulassen.
Fernzugriff einrichten (optional)
Standardmäßig lauscht Elasticsearch nur auf localhost. Um dies zu ändern, öffnen Sie die Konfigurationsdatei wie folgt:
sudo nano /etc/elasticsearch/elasticsearch.ymlScrollen Sie nach unten zu Zeile 56 und suchen Sie den Abschnitt "Netzwerk" und entkommentieren Sie (#) die folgende Zeile und ersetzen Sie sie wie folgt durch die interne private IP-Adresse oder die externe IP-Adresse:
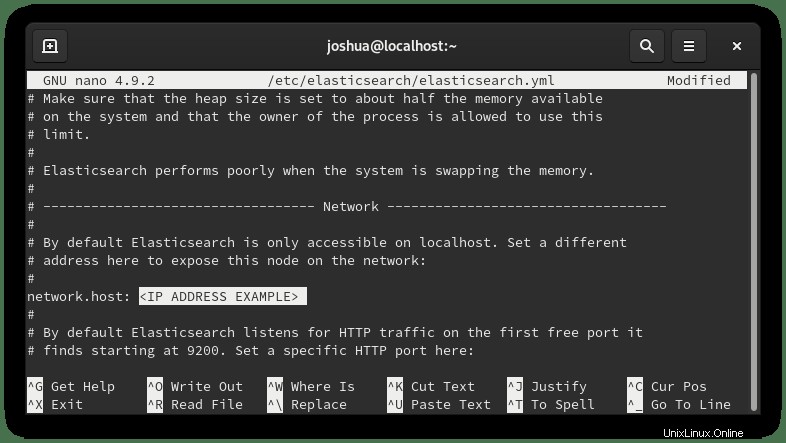
Im Beispiel haben wir (#) auskommentiert der (network.host) und wie oben in eine interne private IP-Adresse geändert.
Aus Sicherheitsgründen ist es ideal für die Angabe von Adressen; Wenn Sie jedoch mehrere interne oder externe IP-Adressen haben, die auf den Server zugreifen, ändern Sie die Netzwerkschnittstelle so, dass sie alle abhört, indem Sie (0.0.0.0) eingeben wie folgt:
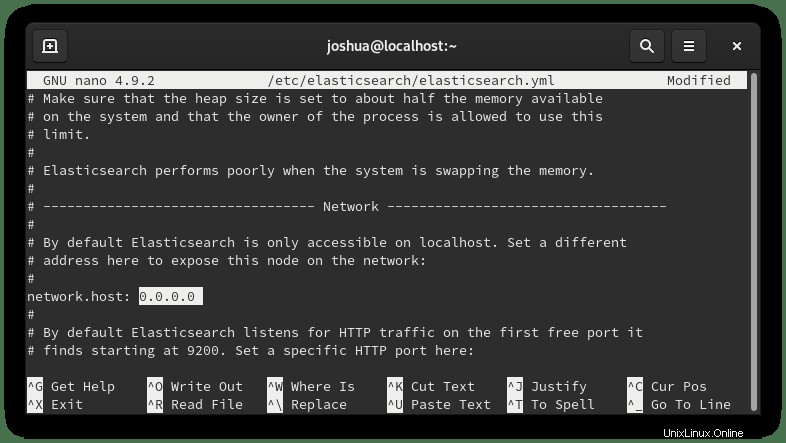
Speichern Sie die Konfigurationsdatei (STRG+O), Beenden Sie dann (CLTR+X) .
Sie müssen den Elasticsearch-Dienst mit dem folgenden Befehl neu starten, damit die Änderungen wirksam werden:
sudo systemctl restart elasticsearchFirewalld für Elasticsearch konfigurieren
Standardmäßig sind keine Regeln für Elasticsearch eingerichtet, was später zu Problemen führen kann.
Fügen Sie zunächst eine neue dedizierte Zone für die Elasticsearch-Firewalld-Richtlinie hinzu:
sudo firewall-cmd --permanent --new-zone=elasticsearchGeben Sie als Nächstes die zulässigen IP-Adressen an, die auf den Memcached zugreifen dürfen.
sudo firewall-cmd --permanent --zone=elasticsearch --add-source=1.2.3.4Ersetzen Sie 1.2.3.4 durch die IP Adresse, die der Zulassungsliste hinzugefügt wird.
Wenn Sie mit dem Hinzufügen der IP-Adressen fertig sind, öffnen Sie den Port des Memcached.
Beispiel:TCP-Port 11211 .
sudo firewall-cmd --permanent --zone=elasticsearch --add-port=9200/tcpBeachten Sie, dass Sie den Standardport in Ihrer Konfigurationsdatei ändern können, wenn Sie die Firewall-Port-Öffnungsregel oben auf den neuen Wert ändern.
Nachdem Sie diese Befehle ausgeführt haben, laden Sie die Firewall neu, um die neuen Regeln zu implementieren:
sudo firewall-cmd --reloadBeispielausgabe bei Erfolg:
successVerwendung von Elasticsearch
So verwenden Sie Elasticsearch mit dem curl-Befehl ist ein unkomplizierter Vorgang. Unten sind einige der am häufigsten verwendeten:
Index löschen
Unterhalb des Index heißt es Beispiele .
curl -X DELETE 'http://localhost:9200/samples'Alle Indizes auflisten
curl -X GET 'http://localhost:9200/_cat/indices?v'Alle Dokumente im Index auflisten
curl -X GET 'http://localhost:9200/sample/_search'Abfrage mit URL-Parametern
Hier verwenden wir das Lucene-Abfrageformat, um q=school:Harvard.
zu schreibencurl -X GET http://localhost:9200/samples/_search?q=school:HarvardAbfrage mit JSON, auch bekannt als Elasticsearch Query DSL
Sie können Abfragen mithilfe von Parametern für die URL durchführen. Sie können aber auch JSON verwenden, wie im folgenden Beispiel gezeigt. JSON wäre einfacher zu lesen und zu debuggen, wenn Sie eine komplexe Abfrage haben, als eine riesige Zeichenfolge von URL-Parametern.
curl -XGET --header 'Content-Type: application/json' http://localhost:9200/samples/_search -d '{
"query" : {
"match" : { "school": "Harvard" }
}
}'Listenindexzuordnung
Alle Elasticsearch-Felder sind Indizes. Das listet also alle Felder und ihre Typen in einem Index auf.
curl -X GET http://localhost:9200/samplesDaten hinzufügen
curl -XPUT --header 'Content-Type: application/json' http://localhost:9200/samples/_doc/1 -d '{
"school" : "Harvard"
}'Dokument aktualisieren
So fügen Sie einem bestehenden Dokument Felder hinzu. Zuerst erstellen wir eine neue. Dann aktualisieren wir es.
curl -XPUT --header 'Content-Type: application/json' http://localhost:9200/samples/_doc/2 -d '
{
"school": "Clemson"
}'
curl -XPOST --header 'Content-Type: application/json' http://localhost:9200/samples/_doc/2/_update -d '{
"doc" : {
"students": 50000}
}'Sicherungsindex
curl -XPOST --header 'Content-Type: application/json' http://localhost:9200/_reindex -d '{
"source": {
"index": "samples"
},
"dest": {
"index": "samples_backup"
}
}'
Bulk-Load-Daten im JSON-Format
export pwd="elastic:"
curl --user $pwd -H 'Content-Type: application/x-ndjson' -XPOST 'https://58571402f5464923883e7be42a037917.eu-central-1.aws.cloud.es.io:9243/0/_bulk?pretty' --data-binary @<file>Clusterzustand anzeigen
curl --user $pwd -H 'Content-Type: application/json' -XGET https://58571402f5464923883e7be42a037917.eu-central-1.aws.cloud.es.io:9243/_cluster/health?prettyAggregation und Bucket-Aggregation
Für einen Nginx-Webserver erzeugt dies Web-Trefferzahlen nach Benutzerstadt:
curl -XGET --user $pwd --header 'Content-Type: application/json' https://58571402f5464923883e7be42a037917.eu-central-1.aws.cloud.es.io:9243/logstash/_search?pretty -d '{
"aggs": {
"cityName": {
"terms": {
"field": "geoip.city_name.keyword",
"size": 50
}
}
}
}
'Dadurch wird die Anzahl der Produktantwortcodes der Stadt in einem Nginx-Webserverprotokoll erweitert
curl -XGET --user $pwd --header 'Content-Type: application/json' https://58571402f5464923883e7be42a037917.eu-central-1.aws.cloud.es.io:9243/logstash/_search?pretty -d '{
"aggs": {
"city": {
"terms": {
"field": "geoip.city_name.keyword"
},
"aggs": {
"responses": {
"terms": {
"field": "response"
}
}
}
},
"responses": {
"terms": {
"field": "response"
}
}
}
}'Verwendung von ElasticSearch mit Basisauthentifizierung
Wenn Sie die Sicherheit mit ElasticSearch aktiviert haben, müssen Sie den Benutzer und das Passwort wie unten gezeigt für jeden Curl-Befehl angeben:
curl -X GET 'http://localhost:9200/_cat/indices?v' -u elastic:(password)Hübscher Druck
Fügen Sie ?pretty=true zu jeder Suche hinzu, um den JSON-Code hübsch auszudrucken. So:
curl -X GET 'http://localhost:9200/(index)/_search'?pretty=trueUm nur bestimmte Felder abzufragen und zurückzugeben
Um nur bestimmte Felder zurückzugeben, fügen Sie sie in das Array _source ein:
GET filebeat-7.6.2-2020.05.05-000001/_search
{
"_source": ["suricata.eve.timestamp","source.geo.region_name","event.created"],
"query": {
"match" : { "source.geo.country_iso_code": "GR" }
}
}Nach Datum abfragen
Wenn das Feld vom Typ Datum ist, können Sie Datumsberechnungen wie folgt verwenden:
GET filebeat-7.6.2-2020.05.05-000001/_search
{
"query": {
"range" : {
"event.created": {
"gte" : "now-7d/d"
}
}
}
}So entfernen (deinstallieren) Sie Elasticsearch
Wenn Sie Elasticsearch nicht mehr benötigen, können Sie die Software mit dem folgenden Befehl entfernen:
sudo zypper remove elasticsearchBeispielausgabe:
Geben Sie "Y" ein Drücken Sie dann die "ENTER-TASTE" um mit dem Entfernen von Elasticsearch fortzufahren.