Wenn Sie einen Profiler verwenden möchten, verwenden Sie einen der vorgeschlagenen.
Wenn Sie es jedoch eilig haben und Ihr Programm unter dem Debugger manuell unterbrechen können, während es subjektiv langsam ist, gibt es eine einfache Möglichkeit, Leistungsprobleme zu finden.
Halten Sie es einfach mehrmals an und schauen Sie sich jedes Mal den Aufrufstapel an. Wenn es einen Code gibt, der einen gewissen Prozentsatz der Zeit verschwendet, 20 % oder 50 % oder was auch immer, ist dies die Wahrscheinlichkeit, dass Sie ihn bei jedem Sample auf frischer Tat erwischen. Das ist also ungefähr der Prozentsatz der Proben, auf denen Sie es sehen werden. Es ist keine fundierte Vermutung erforderlich. Wenn Sie eine Vermutung haben, was das Problem ist, wird es bewiesen oder widerlegt.
Möglicherweise haben Sie mehrere Leistungsprobleme unterschiedlicher Größe. Wenn Sie einen von ihnen säubern, nehmen die verbleibenden einen größeren Prozentsatz ein und sind bei nachfolgenden Durchgängen leichter zu erkennen. Dieser Vergrößerungseffekt , wenn sie aus mehreren Problemen zusammengesetzt wird, kann zu wirklich massiven Beschleunigungsfaktoren führen.
Vorbehalt :Programmierer stehen dieser Technik eher skeptisch gegenüber, es sei denn, sie haben sie selbst verwendet. Sie werden sagen, dass Profiler Ihnen diese Informationen geben, aber das stimmt nur, wenn sie den gesamten Call-Stack abtasten und Sie dann eine zufällige Gruppe von Stichproben untersuchen lassen. (Bei den Zusammenfassungen geht der Einblick verloren.) Anrufdiagramme geben Ihnen nicht die gleichen Informationen, weil
- Sie fassen nicht auf der Unterrichtsebene zusammen, und
- Sie geben verwirrende Zusammenfassungen in Gegenwart von Rekursion.
Sie werden auch sagen, dass es nur mit Spielzeugprogrammen funktioniert, obwohl es eigentlich mit jedem Programm funktioniert, und es scheint mit größeren Programmen besser zu funktionieren, weil sie dazu neigen, mehr Probleme zu finden. Sie werden sagen, dass es manchmal Dinge findet, die keine Probleme sind, aber das stimmt nur, wenn Sie etwas einmal sehen . Wenn Sie ein Problem bei mehr als einer Probe sehen, ist es echt.
P.S. Dies kann auch bei Multi-Thread-Programmen durchgeführt werden, wenn es eine Möglichkeit gibt, Call-Stack-Samples des Thread-Pools zu einem bestimmten Zeitpunkt zu sammeln, wie es in Java der Fall ist.
P.P.S. Als grobe Faustregel gilt:Je mehr Abstraktionsebenen Sie in Ihrer Software haben, desto wahrscheinlicher ist es, dass Sie feststellen, dass dies die Ursache für Leistungsprobleme ist (und die Möglichkeit, schneller zu werden).
Hinzugefügt :Es mag nicht offensichtlich sein, aber die Stack-Sampling-Technik funktioniert genauso gut bei Vorhandensein von Rekursion. Der Grund dafür ist, dass die Zeit, die durch das Entfernen einer Anweisung eingespart würde, durch den Bruchteil der Samples angenähert wird, die sie enthalten, unabhängig davon, wie oft sie innerhalb eines Samples vorkommen kann.
Ein weiterer Einwand, den ich oft höre, ist:"Es wird irgendwo zufällig anhalten und das eigentliche Problem verfehlen „.Dies ergibt sich aus einer vorherigen Vorstellung davon, was das eigentliche Problem ist. Eine Schlüsseleigenschaft von Leistungsproblemen ist, dass sie den Erwartungen widersprechen. Die Stichprobenentnahme sagt Ihnen, dass etwas ein Problem ist, und Ihre erste Reaktion ist Unglaube. Das ist natürlich, aber Sie können Stellen Sie sicher, dass es ein echtes Problem gibt und umgekehrt.
Hinzugefügt :Lassen Sie mich eine bayessche Erklärung geben, wie es funktioniert. Angenommen, es gibt eine Anweisung I (Aufruf oder anderweitig), der sich auf dem Aufrufstapel befindet, ein Bruchteil von f der Zeit (und kostet so viel). Nehmen wir der Einfachheit halber an, wir wissen nicht, was f ist ist, aber nehmen Sie an, dass es entweder 0,1, 0,2, 0,3, ... 0,9, 1,0 ist und die vorherige Wahrscheinlichkeit jeder dieser Möglichkeiten 0,1 ist, also sind alle diese Kosten a priori gleich wahrscheinlich.
Nehmen wir dann an, wir nehmen nur 2 Stack-Samples und sehen die Anweisung I bei beiden Proben bezeichnete Beobachtung o=2/2 . Dies gibt uns neue Schätzungen der Häufigkeit f von I , laut diesem:
Prior
P(f=x) x P(o=2/2|f=x) P(o=2/2&&f=x) P(o=2/2&&f >= x) P(f >= x | o=2/2)
0.1 1 1 0.1 0.1 0.25974026
0.1 0.9 0.81 0.081 0.181 0.47012987
0.1 0.8 0.64 0.064 0.245 0.636363636
0.1 0.7 0.49 0.049 0.294 0.763636364
0.1 0.6 0.36 0.036 0.33 0.857142857
0.1 0.5 0.25 0.025 0.355 0.922077922
0.1 0.4 0.16 0.016 0.371 0.963636364
0.1 0.3 0.09 0.009 0.38 0.987012987
0.1 0.2 0.04 0.004 0.384 0.997402597
0.1 0.1 0.01 0.001 0.385 1
P(o=2/2) 0.385
Die letzte Spalte besagt zum Beispiel die Wahrscheinlichkeit, dass f>=0,5 ist 92 %, eine Steigerung gegenüber der vorherigen Annahme von 60 %.
Angenommen, die vorherigen Annahmen sind unterschiedlich. Angenommen, wir nehmen P(f=0.1) an ist 0,991 (fast sicher), und alle anderen Möglichkeiten sind fast unmöglich (0,001). Mit anderen Worten, unsere erste Gewissheit ist, dass I ist günstig. Dann erhalten wir:
Prior
P(f=x) x P(o=2/2|f=x) P(o=2/2&& f=x) P(o=2/2&&f >= x) P(f >= x | o=2/2)
0.001 1 1 0.001 0.001 0.072727273
0.001 0.9 0.81 0.00081 0.00181 0.131636364
0.001 0.8 0.64 0.00064 0.00245 0.178181818
0.001 0.7 0.49 0.00049 0.00294 0.213818182
0.001 0.6 0.36 0.00036 0.0033 0.24
0.001 0.5 0.25 0.00025 0.00355 0.258181818
0.001 0.4 0.16 0.00016 0.00371 0.269818182
0.001 0.3 0.09 0.00009 0.0038 0.276363636
0.001 0.2 0.04 0.00004 0.00384 0.279272727
0.991 0.1 0.01 0.00991 0.01375 1
P(o=2/2) 0.01375
Jetzt heißt es P(f >= 0.5) beträgt 26 %, gegenüber der vorherigen Annahme von 0,6 %. Bayes erlaubt uns also, unsere Schätzung der wahrscheinlichen Kosten von I zu aktualisieren . Wenn die Datenmenge klein ist, sagt uns das nicht genau, wie hoch die Kosten sind, sondern nur, dass sie groß genug sind, um eine Reparatur wert zu sein.
Noch eine andere Betrachtungsweise ist die Erbfolgeregel. Wenn Sie eine Münze zweimal werfen und sie zeigt beide Male Kopf, was sagt Ihnen das über die wahrscheinliche Gewichtung der Münze? Die respektierte Art zu antworten ist zu sagen, dass es sich um eine Beta-Distribution handelt, mit einem Durchschnittswert von (number of hits + 1) / (number of tries + 2) = (2+1)/(2+2) = 75% .
(Der Schlüssel ist, dass wir I sehen mehr als einmal. Wenn wir es nur einmal sehen, sagt uns das nicht viel, außer dass f> 0.)
Selbst eine sehr kleine Anzahl von Beispielen kann uns also viel über die Kosten der Anweisungen sagen, die es sieht. (Und es wird sie im Durchschnitt mit einer Häufigkeit sehen, die proportional zu ihren Kosten ist. Wenn n Proben genommen werden, und f die Kosten sind, dann I erscheint auf nf+/-sqrt(nf(1-f)) Proben. Beispiel:n=10 , f=0.3 , das ist 3+/-1.4 Proben.)
Hinzugefügt :Um ein intuitives Gefühl für den Unterschied zwischen Messen und Stapelstichprobe zu vermitteln:
Es gibt jetzt Profiler, die den Stack abtasten, sogar rund um die Uhr, aber was dabei herauskommt sind Messungen (oder Hot Path oder Hot Spot, vor denen sich leicht ein "Engpass" verbergen kann). Was sie Ihnen nicht zeigen (und das könnten sie leicht) sind die tatsächlichen Proben selbst. Und wenn Ihr Ziel darin besteht, zu finden Der Engpass, die Anzahl von ihnen, die Sie sehen müssen, ist im Durchschnitt , 2 dividiert durch den Bruchteil der benötigten Zeit. Wenn es also 30 % der Zeit in Anspruch nimmt, zeigen durchschnittlich 2/0,3 =6,7 Samples dies an, und die Wahrscheinlichkeit, dass 20 Samples dies zeigen, beträgt 99,2 %.
Hier ist eine spontane Veranschaulichung des Unterschieds zwischen der Untersuchung von Messungen und der Untersuchung von Stapelproben. Der Engpass kann ein großer Fleck wie dieser sein oder zahlreiche kleine, es macht keinen Unterschied.
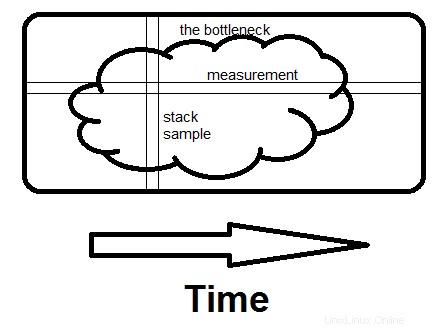
Die Messung erfolgt horizontal; es sagt Ihnen, welchen Bruchteil der Zeit bestimmte Routinen benötigen. Die Abtastung erfolgt vertikal. Wenn es eine Möglichkeit gibt, zu vermeiden, was das gesamte Programm in diesem Moment tut, und wenn Sie es auf einer zweiten Abtastung sehen , Sie haben den Engpass gefunden. Das macht den Unterschied – den ganzen Grund für die aufgewendete Zeit zu sehen, nicht nur wie viel.
Sie können Valgrind mit den folgenden Optionen verwenden
valgrind --tool=callgrind ./(Your binary)
Es wird eine Datei namens callgrind.out.x generiert . Sie können dann kcachegrind verwenden Werkzeug, um diese Datei zu lesen. Es gibt Ihnen eine grafische Analyse der Dinge mit Ergebnissen wie z. B. welche Linien wie viel kosten.
Ich nehme an, Sie verwenden GCC. Die Standardlösung wäre ein Profil mit gprof.
Achten Sie darauf, -pg hinzuzufügen zum Kompilieren vor dem Profiling:
cc -o myprog myprog.c utils.c -g -pg
Ich habe es noch nicht ausprobiert, aber ich habe Gutes über Google-Perftools gehört. Einen Versuch ist es auf jeden Fall wert.
Verwandte Frage hier.
Ein paar andere Schlagworte, wenn gprof erledigt die Arbeit nicht für Sie:Valgrind, Intel VTune, Sun DTrace.