 Logstash ist eine Open-Source-Verwaltungsanwendung für zentrale Protokolldateien.
Logstash ist eine Open-Source-Verwaltungsanwendung für zentrale Protokolldateien.
Sie können Protokolle von mehreren Servern und mehreren Anwendungen sammeln, diese Protokolle analysieren und an einem zentralen Ort speichern. Sobald es gespeichert ist, können Sie eine Web-GUI verwenden, um nach Protokollen zu suchen, die Protokolle aufzuschlüsseln und verschiedene Berichte zu erstellen.
Dieses Tutorial erklärt die Grundlagen von Logstash und alles, was Sie wissen müssen, um Logstash auf Ihrem System zu installieren und zu konfigurieren.
1. Logstatsh-Binärversion herunterladen
Logstash ist Teil der Elasticsearch-Familie. Laden Sie es hier von der Logstash-Website herunter. Bitte beachten Sie, dass Java auf Ihrem Rechner installiert sein muss, damit dies funktioniert.
oder verwenden Sie curl, um es direkt von der Website herunterzuladen.
wget https://download.elasticsearch.org/logstash/logstash/logstash-1.4.2.tar.gz tar zxvf logstash-1.4.2.tar.gz cd logstash-1.4.2
Hinweis:Wir werden Logstash später mit yum installieren. Im Moment laden wir die Binärdatei zunächst manuell herunter, um zu überprüfen, wie sie von der Befehlszeile aus funktioniert.
2. Logstash-Optionen in der Befehlszeile angeben
Um die Grundlagen von Logstash zu Testzwecken zu verstehen, lassen Sie uns schnell einige Dinge von der Befehlszeile aus überprüfen.
Führen Sie den Logstash wie unten gezeigt über die Befehlszeile aus. Wenn Sie dazu aufgefordert werden, geben Sie einfach „Hallo Welt“ als Eingabe ein.
# bin/logstash -e 'input { stdin { } } output { stdout {} }'
hello world
2014-07-06T17:27:25.955+0000 base hello world In der obigen Ausgabe ist die erste Zeile das „Hello World“, das wir mit stdin eingegeben haben.
Die zweite Zeile ist die Ausgabe, die logstash mit stdout angezeigt hat. Im Grunde spuckt es einfach aus, was wir in die stdin eingegeben haben.
Bitte beachten Sie, dass die Angabe des Befehlszeilen-Flags -e es Logstash ermöglicht, eine Konfiguration direkt von der Befehlszeile zu akzeptieren. Dies ist sehr nützlich, um Konfigurationen schnell zu testen, ohne eine Datei zwischen Iterationen bearbeiten zu müssen.
3. Ändern Sie das Ausgabeformat mit Codec
Der rubydebug-Codec gibt Ihre Logstash-Ereignisdaten mithilfe der ruby-awesome-print-Bibliothek aus.
Indem wir also die „stdout“-Ausgabe neu konfigurieren (einen „Codec“ hinzufügen), können wir die Ausgabe von Logstash ändern. Durch das Hinzufügen von Eingängen, Ausgängen und Filtern zu Ihrer Konfiguration ist es möglich, die Protokolldaten auf viele Arten zu bearbeiten, um die Flexibilität der gespeicherten Daten bei der Abfrage zu maximieren.
# bin/logstash -e 'input { stdin { } } output { stdout { codec => rubydebug } }'
hello world
{
"message" => "",
"@version" => "1",
"@timestamp" => "2014-07-06T17:40:48.775Z",
"host" => "base"
}
{
"message" => "hello world",
"@version" => "1",
"@timestamp" => "2014-07-06T17:40:48.776Z",
"host" => "base"
} 4. Laden Sie ElasticSearch herunter
Nachdem wir nun gesehen haben, wie Logstash funktioniert, gehen wir noch einen Schritt weiter. Es ist offensichtlich, dass wir die Eingabe und Ausgabe von Everylog nicht manuell übergeben können. Um dieses Problem zu überwinden, müssen wir eine Software namens Elasticsearch installieren.
Laden Sie die elastische Suche hier herunter.
Oder verwenden Sie wget wie unten gezeigt.
curl -O https://download.elasticsearch.org/elasticsearch/elasticsearch/elasticsearch-1.4.0.tar.gz tar zxvf elasticsearch-1.4.0.tar.gz
Starten Sie den Elasticsearch-Dienst wie unten gezeigt:
cd elasticsearch-1.4.0/ ./bin/elasticsearch
Hinweis:Dieses Tutorial spezifiziert die Ausführung von Logstash 1.4.2 mit Elasticsearch 1.4.0. Jede Version von Logstash hat eine empfohlene Version von Elasticsearch zum Koppeln. Stellen Sie sicher, dass die Versionen basierend auf der von Ihnen ausgeführten Logstash-Version übereinstimmen.
5. Überprüfen Sie ElasticSearch
Standardmäßig läuft Elasticsearch auf Port 9200.
Zu Testzwecken nehmen wir weiterhin die Eingabe von stdin (ähnlich wie in unserem vorherigen Beispiel), aber die Ausgabe wird nicht auf stdout angezeigt. Stattdessen geht es zu Elasticsearch.
Um die elastische Suche zu überprüfen, führen wir Folgendes aus. Wenn Sie nach der Eingabe gefragt werden, geben Sie einfach „the geek stuff“ als shoen unten ein.
# bin/logstash -e 'input { stdin { } } output { elasticsearch { host => localhost } }'
the geek stuff Da wir die Ausgabe nicht in der Standardausgabe sehen, sollten wir uns die elastische Suche ansehen.
Rufen Sie die folgende URL auf:
http://localhost:9200/_search?pretty
Oben werden alle Nachrichten angezeigt, die in der elastischen Suche verfügbar sind. Sie sollten die Nachricht sehen, die wir im obigen logstash-Befehl hier in der Ausgabe eingegeben haben.
{
"took" : 4,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"failed" : 0
},
"hits" : {
"total" : 9,
"max_score" : 1.0,
"hits" : [ {
"_index" : "logstash-2014.07.06",
"_type" : "logs",
"_id" : "G3uZPQCMQ6ed4joNCuseew",
"_score" : 1.0, "_source" : {"message":"the geek stuff","@version":"1","@timestamp":"2014-07-06T18:09:46.612Z","host":"base"}
} ]
} 6. Logstash-Eingaben, Ausgaben und Codecs
Eingänge, Ausgänge, Codecs und Filter sind das Herzstück der Logstash-Konfiguration. Durch die Erstellung einer Pipeline zur Ereignisverarbeitung ist Logstash in der Lage, die relevanten Daten aus Ihren Protokollen zu extrahieren und sie Elasticsearch zur Verfügung zu stellen, um Ihre Daten effizient abzufragen.
Im Folgenden sind einige der verfügbaren Eingänge aufgeführt. Eingaben sind der Mechanismus zum Übergeben von Protokolldaten an Logstash
- file:liest aus einer Datei im Dateisystem, ähnlich wie der UNIX-Befehl „tail -0a“
- syslog:lauscht auf dem bekannten Port 514 auf Syslog-Meldungen und analysiert gemäß dem RFC3164-Format
- redis:Liest von einem Redis-Server, wobei sowohl Redis-Kanäle als auch Redis-Listen verwendet werden. Redis wird häufig als „Broker“ in einer zentralisierten Logstash-Installation verwendet, die Logstash-Ereignisse von entfernten Logstash-„Lieferanten“ in eine Warteschlange einreiht.
- Holzfäller:verarbeitet Ereignisse, die im Holzfällerprotokoll gesendet werden. Wird jetzt Logstash-Forwarder genannt.
Im Folgenden sind einige der Filter aufgeführt. Filter werden als zwischengeschaltete Verarbeitungsgeräte in der Logstash-Kette verwendet. Sie werden oft mit Bedingungen kombiniert, um eine bestimmte Aktion für ein Ereignis auszuführen, wenn es bestimmte Kriterien erfüllt.
- grok:parst beliebigen Text und strukturiert ihn. Grok ist derzeit der beste Weg in Logstash, um unstrukturierte Protokolldaten in etwas Strukturiertes und Abfragebares zu parsen. Mit 120 Mustern, die in Logstash integriert sind, ist es mehr als wahrscheinlich, dass Sie eines finden, das Ihren Anforderungen entspricht!
- Mutate:Der Mutate-Filter ermöglicht es Ihnen, allgemeine Mutationen an Feldern vorzunehmen. Sie können Felder in Ihren Ereignissen umbenennen, entfernen, ersetzen und ändern.
- drop:Löschen Sie ein Ereignis vollständig, z. B. Debug-Ereignisse.
- Klonen:Eine Kopie eines Ereignisses erstellen, möglicherweise Felder hinzufügen oder entfernen.
- geoip:fügt Informationen über den geografischen Standort von IP-Adressen hinzu (und zeigt erstaunliche Diagramme in Kibana an)
Im Folgenden sind einige der Codecs aufgeführt. Ausgaben sind die letzte Phase der Logstash-Pipeline. Ein Ereignis kann während der Verarbeitung mehrere Ausgaben durchlaufen, aber sobald alle Ausgaben abgeschlossen sind, hat das Ereignis seine Ausführung beendet.
- ElasticSearch:Wenn Sie planen, Ihre Daten in einem effizienten, bequemen und leicht abfragbaren Format zu speichern
- Datei:schreibt Ereignisdaten in eine Datei auf der Festplatte.
- graphite:Sendet Ereignisdaten an Graphit, ein beliebtes Open-Source-Tool zum Speichern und grafischen Darstellen von Metriken
- statsd:ein Dienst, der „Statistiken wie Zähler und Timer abhört, die über UDP gesendet werden, und Aggregate an einen oder mehrere austauschbare Backend-Dienste sendet“.
7. Verwenden Sie die Logstash-Konfigurationsdatei
Jetzt ist es an der Zeit, von den Befehlszeilenoptionen zur Konfigurationsdatei zu wechseln. Anstatt die Optionen in der Befehlszeile anzugeben, können Sie sie wie unten gezeigt in einer .conf-Datei angeben:
# vi logstash-simple.conf
input { stdin { } }
output {
elasticsearch { host => localhost }
stdout { codec => rubydebug }
} Lassen Sie uns nun den Logstast bitten, die Konfigurationsdatei zu lesen, die wir gerade erstellt haben, indem Sie die Option -f wie unten gezeigt verwenden. Zu Testzwecken verwendet dies immer noch stdin und stdout. Geben Sie also eine Nachricht ein, nachdem Sie diesen Befehl eingegeben haben.
# bin/logstash -f logstash-simple.conf
This is Vadiraj
{
"message" => "This is Vadiraj",
"@version" => "1",
"@timestamp" => "2014-11-07T04:59:20.959Z",
"host" => "base.thegeekstuff.com"
} 8. Analysieren Sie die eingegebene Apache-Protokollnachricht
Lassen Sie uns nun etwas fortgeschrittenere Konfigurationen vornehmen. Löschen Sie alle Einträge aus der Datei logstash-simple.conf und fügen Sie die folgenden Zeilen hinzu:
# vi logstash-simple.conf
input { stdin { } }
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}" }
}
date {
match => [ "timestamp" , "dd/MMM/yyyy:HH:mm:ss Z" ]
}
}
output {
elasticsearch { host => localhost }
stdout { codec => rubydebug }
} Führen Sie nun den logstash-Befehl wie unten gezeigt aus:
# bin/logstash -f logstash-filter.conf
Fügen Sie dieses Mal jedoch den folgenden Beispieleintrag der Apache-Protokolldatei als Eingabe ein.
# bin/logstash -f logstash-filter.conf "127.0.0.1 - - [11/Dec/2013:00:01:45 -0800] "GET /xampp/status.php HTTP/1.1" 200 3891 "http://cadenza/xampp/navi.php" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:25.0) Gecko/20100101 Firefox/25.0""
Die Ausgabe von logstatsh sieht in etwa so aus:
{
"message" => "127.0.0.1 - - [11/Dec/2013:00:01:45 -0800] \"GET /xampp/status.php HTTP/1.1\" 200 3891 \"http://cadenza/xampp/navi.php\" \"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:25.0) Gecko/20100101 Firefox/25.0\"",
"@version" => "1",
"@timestamp" => "2013-12-11T08:01:45.000Z",
"host" => "base.tgs.com",
"clientip" => "127.0.0.1",
"ident" => "-",
"auth" => "-",
"timestamp" => "11/Dec/2013:00:01:45 -0800",
"verb" => "GET",
"request" => "/xampp/status.php",
"httpversion" => "1.1",
"response" => "200",
"bytes" => "3891",
"referrer" => "\"http://cadenza/xampp/navi.php\"",
"agent" => "\"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:25.0) Gecko/20100101 Firefox/25.0\""
} Wie Sie der obigen Ausgabe entnehmen können, wird unsere Eingabe entsprechend geparst und alle Werte werden aufgeteilt und in den entsprechenden Feldern gespeichert.
Der Grok-Filter hat das Apache-Protokoll extrahiert und in nützliche Bits zerlegt, damit wir später abfragen können.
9. Logstash-Konfigurationsdatei für das Apache-Fehlerprotokoll
Erstellen Sie die folgende logstash-Konfigurationsdatei für die Datei error_log von Apache.
# vi logstash-apache.conf
input {
file {
path => "/var/log/httpd/error_log"
start_position => beginning
}
}
filter {
if [path] =~ "error" {
mutate { replace => { "type" => "apache_error" } }
grok {
match => { "message" => "%{COMBINEDAPACHELOG}" }
}
}
date {
match => [ "timestamp" , "dd/MMM/yyyy:HH:mm:ss Z" ]
}
}
output {
elasticsearch {
host => localhost
}
stdout { codec => rubydebug }
} In der obigen Konfigurationsdatei:
- Eingabedatei ist /var/log/httpd/error_log und die Startposition ist der Anfang der Datei.
- Filtern Sie die Eingabedatei und benennen (mutieren) Sie alles mit Fehler in apache_error um. grok erstellt ein kombiniertes Apachelog in der Meldungsspalte und data zeigt den Zeitstempel im angegebenen Format.
- Die Ausgabe wird in Elasticsearch in localhost gespeichert und über stdout im Ruby-Print-Format mit dem Codec => rubydebug ausgegeben
10. Logstash-Konfigurationsdatei für das Apache-Fehlerprotokoll und das Zugriffsprotokoll
Wir können Wildcard-Charter angeben, um alle Protokolldateien mit *_log zu lesen, wie unten gezeigt.
Aber wir müssen auch die Bedingungen entsprechend ändern, um sowohl das Zugriffs- als auch das Fehlerprotokoll wie unten gezeigt zu analysieren.
# vi logstash-apache.conf
input {
file {
path => "/var/log/httpd/*_log"
}
}
filter {
if [path] =~ "access" {
mutate { replace => { type => "apache_access" } }
grok {
match => { "message" => "%{COMBINEDAPACHELOG}" }
}
date {
match => [ "timestamp" , "dd/MMM/yyyy:HH:mm:ss Z" ]
}
} else if [path] =~ "error" {
mutate { replace => { type => "apache_error" } }
} else {
mutate { replace => { type => "random_logs" } }
}
}
output {
elasticsearch { host => localhost }
stdout { codec => rubydebug }
} 11. Zusätzliche Yum-Repositories einrichten
Testen ist vorbei. Jetzt wissen wir, wie Logstash mit Elasticsearch funktioniert.
Wir werden Folgendes installieren:
- logstash – Unser zentraler Protokollserver
- Elasticsearch – Zum Speichern der Protokolle
- Redis – Für Filter
- Nginx – Zum Ausführen von Kibana
- Kibana – Ist ein wunderschönes GUI-Dashboard und fügt alles zusammen
Richten Sie vor der Installation die folgenden Repositories ein:
# cd /etc/yum.repos.d/ # vi /etc/yum.repos.d/logstash.repo [logstash] name=Logstash baseurl=http://packages.elasticsearch.org/logstash/1.4/centos gpgcheck=1 gpgkey=http://packages.elasticsearch.org/GPG-KEY-elasticsearch enabled=1 # vi /etc/yum.repos.d/elasticsearch.repo [elasticsearch] name=Elasticsearch baseurl=http://packages.elasticsearch.org/elasticsearch/1.4/centos gpgcheck=1 gpgkey=http://packages.elasticsearch.org/GPG-KEY-elasticsearch enabled=1
Richten Sie außerdem das EPEL-Repository ein, wie wir es bereits besprochen haben.
12. Installieren Sie Elasticsearch, Nginx und Redis und Logstash
Bringen Sie zuerst das System auf den neuesten Stand und installieren Sie dann Logstash zusammen mit Elasticsearch, Redis und Nginx wie unten gezeigt:
yum clean all yum update -y yum install -y install elasticsearch redis nginx logstash
13. Installieren Sie Kibana
Installieren Sie Kibana für das Dashboard wie unten gezeigt:
cd /opt/ wget https://download.elasticsearch.org/kibana/kibana/kibana-3.1.2.tar.gz tar -xvzf kibana-3.1.2.tar.gz mv kibana-3.1.2 /usr/share/kibana3
14. Kibana konfigurieren
Wir müssen Kibana von Elasticsearch erzählen. Modifizieren Sie dazu die folgende config.js.
# vi /usr/share/kibana3/config.js elasticsearch: "http://log.thegeekstuff.com:9200"
Suchen Sie in der obigen Datei nach „elasticsearch“ und ändern Sie „dev.kanbier.lan“ in dieser Zeile in Ihre Domain (z. B.:log.thegeekstuff.com)
15. Richten Sie Kibana so ein, dass es von Nginx ausgeführt wird
Wir müssen Kibana auch so machen, dass es vom Nginx-Webserver ausgeführt wird.
Fügen Sie Folgendes zu nginx.conf hinzu
server {
listen *:80 ;
server_name log.thegeekstuff.com;
access_log /var/log/nginx/kibana.myhost.org.access.log;
location / {
root /usr/share/kibana3;
index index.html index.htm;
} Vergessen Sie auch nicht, die entsprechende IP-Adresse Ihres Servers in der redis.conf-Datei anzugeben.
16. Logstash-Konfigurationsdatei konfigurieren
Jetzt müssen wir eine Logstash-Konfigurationsdatei ähnlich der Beispielkonfigurationsdatei erstellen, die wir zuvor verwendet haben.
Wir werden den Pfad der Protokolldateien definieren, welchen Port die Remote-Protokolle empfangen und logstash über das Elasticsearch-Tool informieren.
# vi /etc/logstash/conf.d/logstash.conf
input {
file {
type => "syslogpath => [ "/var/log/*.log", "/var/log/messages", "/var/log/syslog" ]
sincedb_path => "/opt/logstash/sincedb-access"
}
redis {
host => "10.37.129.8"
type => "redis-input"
data_type => "list"
key => "logstash"
}
syslog {
type => "syslog"
port => "5544"
}
}
filter {
grok {
type => "syslog"
match => [ "message", "%{SYSLOGBASE2}" ]
add_tag => [ "syslog", "grokked" ]
}
}
output {
elasticsearch { host => "log.thegeekstuff.com" }
}" 17. Überprüfen und starten Sie Logstash, Elasticsearch, Redis und Nginx
Starten Sie alle diese Dienste wie unten gezeigt:
service elasticsearch start service logstash start service nginx start service redis start
18. Überprüfen Sie die Logstash-Web-GUI
Öffnen Sie einen Browser und gehen Sie zum Servernamen (Host), der in der obigen Konfigurationsdatei verwendet wurde. Beispiel:log.thegeekstuff.com
Sie sehen ein Diagramm ähnlich dem folgenden, von dem aus Sie alle Protokolldateien bearbeiten, durchsuchen und aufschlüsseln können, die von Logstash gesammelt werden.
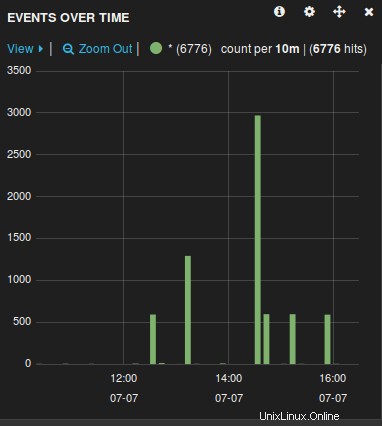
Nachdem der Protokollserver nun bereit ist, müssen Sie nur noch die von rsyslog verwalteten Remote-Server-Protokolldateien an diesen zentralen Server weiterleiten, indem Sie die Datei rsyslog.conf ändern.