In den letzten fünf Jahren ist die Data-Science-Branche explodiert, und Jobs in der Data-Science sind zahlreich und gut bezahlt. Der Einstieg in die Datenwissenschaft kann jedoch schwierig sein. Eines der größten Hindernisse besteht darin, die richtigen Tools und die richtige Umgebung auf Ihrem Computer einzurichten. Nun, nicht, es sei denn, Sie sehen, wie Anaconda installiert und für die Datenwissenschaft verwendet wird.
Anaconda ist eine leistungsstarke Data-Science-Plattform und eine großartige Möglichkeit für den Einstieg in die Datenanalyse, -modellierung und -visualisierung. Und in diesem Tutorial gehen Sie die Schritte zur Installation von Anaconda unter Ubuntu Linux und einige grundlegende Datenbearbeitungs- und Visualisierungsaufgaben durch.
Bereit? Lesen Sie weiter, um zu erfahren, wie Sie mit Anaconda unter Linux in die Datenwissenschaft einsteigen!
Voraussetzungen
Dieses Tutorial wird eine praktische Demonstration sein. Wenn Sie mitmachen möchten, stellen Sie sicher, dass Sie einen Ubuntu-Linux-Computer mit mindestens 4 GB RAM und 5 GB freiem Speicherplatz haben.
Der für die Installation von Anaconda erforderliche Mindestspeicherplatz beträgt 5 GB, aber Sie benötigen mehr freien Speicherplatz, um ernsthafte datenwissenschaftliche Arbeiten durchzuführen. Die Arbeit an Data Science erfordert viel Speicherplatz, da Sie Datensätze herunterladen und speichern müssen. 50 GB freier Speicherplatz auf Ihrem Computer würden ausreichen, um an Data Science zu arbeiten.
Herunterladen des Anaconda-Installer-Bash-Skripts
Egal, ob Sie neu in der Datenwissenschaft oder ein erfahrener Experte sind, Anaconda ist die perfekte Plattform für Ihre Datenanalyse- und Modellierungsanforderungen. Aber zuerst müssen Sie Anaconda auf Ihrem Computer installieren.
Um Anaconda zu installieren, müssen Sie das Installer-Bash-Skript von der Anaconda-Website herunterladen. Zum Zeitpunkt des Schreibens ist die neueste Version Anaconda3-2021.11-Linux-x86_64.sh.
1. Öffnen Sie Ihr Terminal und führen Sie die folgenden Befehle aus, um das Bash-Skript des Installationsprogramms von Anaconda herunterzuladen und in Ihrem /tmp zu speichern Verzeichnis.
cd /tmp
curl -O https://repo.anaconda.com/archive/Anaconda3-2021.11-Linux-x86_64.sh
2. Führen Sie als Nächstes den folgenden Befehl sha256sum aus, um einen kryptografischen SHA-256-Hash für die heruntergeladene Datei (Anaconda3-2021.11-Linux-x86_64.sh) zu generieren. Mit diesem Befehl können Sie die Integrität des Bash-Skripts des Installationsprogramms mit MD5 oder SHA256 überprüfen.
Das Herunterladen von Dateien aus dem Internet birgt immer das Risiko, dass die Dateien während der Übertragung manipuliert oder beschädigt werden. Die Überprüfung der Integrität des Bash-Skripts des Installationsprogramms ist entscheidend, um sicherzustellen, dass Sie eine identische Kopie der ursprünglich von Anaconda veröffentlichten Datei erhalten haben.
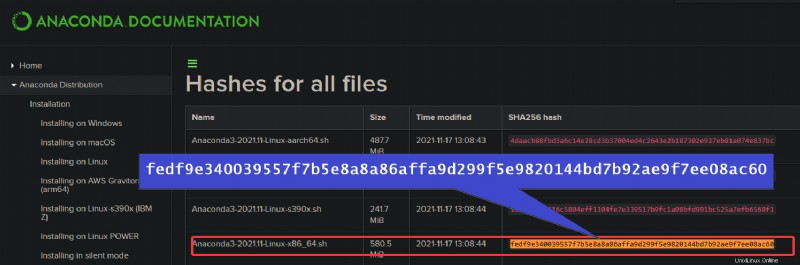
sha256sum Anaconda3-2021.11-Linux-x86_64.shNotieren Sie sich die Hashes der Datei, um sie mit denen zu vergleichen, die auf der Website von Anaconda verfügbar sind (Schritt drei).

3. Öffnen Sie zuletzt Ihren bevorzugten Webbrowser und navigieren Sie zur Hash-Liste von Anaconda.
Suchen Sie nach dem Namen des heruntergeladenen Bash-Skripts des Installationsprogramms (Anaconda3-2021.11-Linux-x86_64.sh). Stellen Sie nach dem Auffinden sicher, dass die in Schritt 2 notierten Hashes mit denen auf der Website von Anaconda übereinstimmen.
Wenn die Hashes nicht übereinstimmen, wiederholen Sie die Schritte eins bis drei und überprüfen Sie die Hashes erneut.
Anaconda auf Ubuntu installieren
Nachdem Sie das Bash-Skript heruntergeladen und seine Integrität überprüft haben, können Sie Anaconda installieren. Das Bash-Skript des Installationsprogramms enthält alle erforderlichen Installationsbefehle, sodass Sie es nur ausführen müssen.
1. Führen Sie den folgenden Befehl aus, um Anaconda auf Ihrem Computer zu installieren. Achten Sie darauf, Anaconda3-2021.11-Linux-x86_64.sh durch den Namen der heruntergeladenen Bash-Skriptdatei zu ersetzen.
Beachten Sie, dass Sie den Bash-Befehl unabhängig von Ihrer Shell einfügen müssen.
bash Anaconda3-2021.11-Linux-x86_64.sh2. Drücken Sie nach dem Ausführen des Bash-Skripts die Eingabetaste, um die Endbenutzer-Lizenzvereinbarung (EULA) anzuzeigen, wenn Sie dazu aufgefordert werden. Drücken Sie weiterhin die Eingabetaste, um das Ende der EULA durchzulesen.
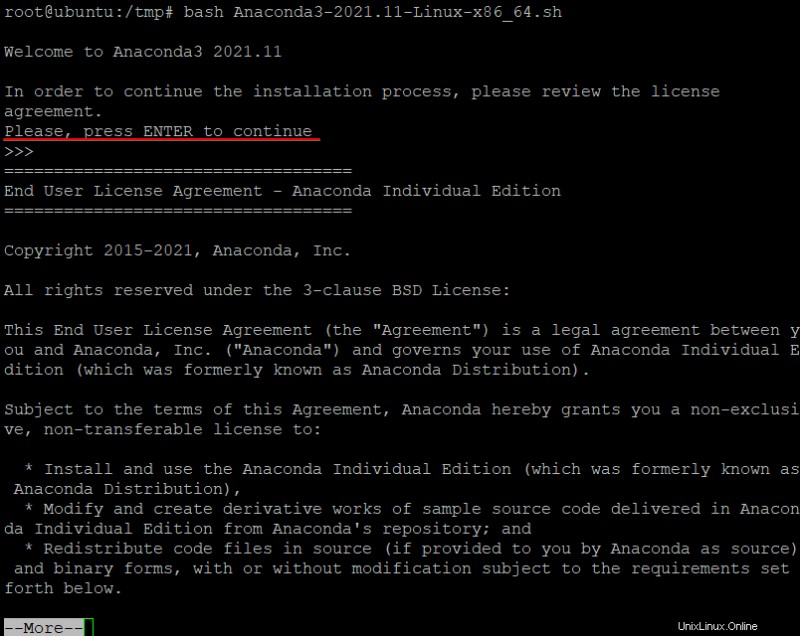
3. Nachdem Sie die EULA gelesen haben, geben Sie yes ein und drücken Sie die Eingabetaste, um die Lizenzbedingungen zu akzeptieren, wie unten gezeigt.

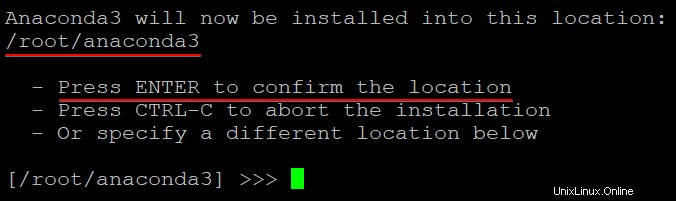
4. Drücken Sie nun die Eingabetaste, um den Standardinstallationsort von Anaconda zu akzeptieren. Sie können einen beliebigen Speicherort auswählen, aber für einen einfacheren Zugriff wird empfohlen, ein Verzeichnis in Ihrem Home-Ordner zu wählen.
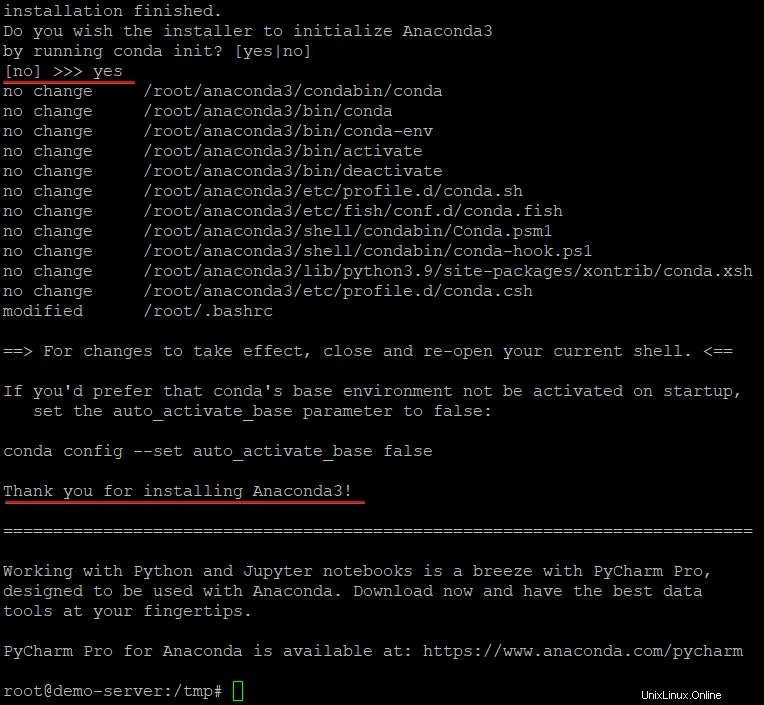
5. Geben Sie yes ein und drücken Sie die Eingabetaste, wenn Sie aufgefordert werden, Anaconda3 zu initialisieren. Dieser Conda-Init-Befehl stellt sicher, dass der Conda-Befehl jedes Mal, wenn Sie sich bei Ihrem Computer anmelden, auf Ihrem Terminal verfügbar ist.
6. Führen Sie als Nächstes den folgenden Befehl aus, um die Änderungen auf Ihre Shell-Umgebung anzuwenden.
source ~/.bashrcIhre aktuelle Shell ändert sich in base, was anzeigt, dass Anaconda3 erfolgreich installiert wurde, wie unten gezeigt. base ist die standardmäßige Shell-Umgebung in Anaconda, die alle zentralen Python-Bibliotheken und -Tools bereitstellt, die für Data Science benötigt werden.
Die Basis-Shell-Umgebung enthält leistungsstarke Befehlszeilentools, einschließlich Conda, Anaconda Prompt und Jupyter Notebook.

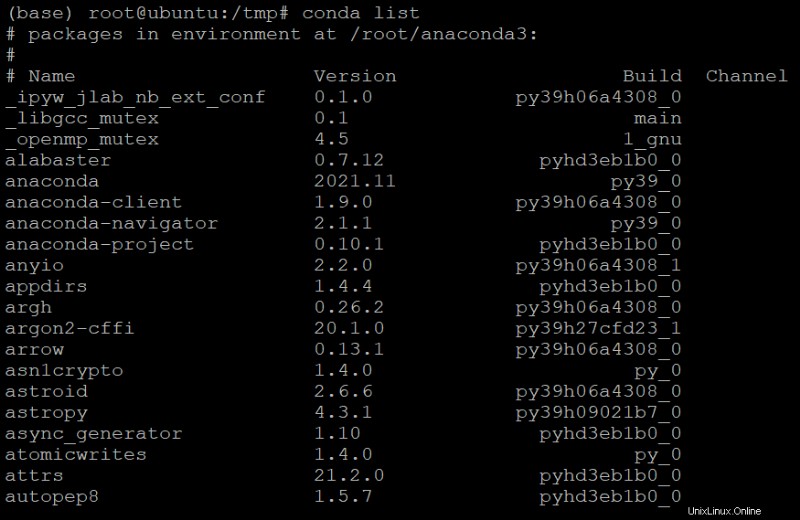
7. Führen Sie den folgenden conda list-Befehl aus, um zu überprüfen, ob Anaconda ordnungsgemäß installiert ist.
conda list Sie sehen eine Liste aller Pakete und Versionen, wie unten gezeigt, die derzeit in Ihrer Basisumgebung enthalten sind.
8. Führen Sie zuletzt den Befehl conda deactivate unten aus, um die Anaconda-Sitzung zu schließen.
conda deactivate
Beachten Sie, dass die Befehle conda activate und conda deactivate nur auf Conda 4.6 und höheren Versionen funktionieren. Führen Sie für Conda-Versionen vor 4.6 stattdessen die folgenden Befehle aus:source activate oder source deactivate
Einrichten Ihrer Anaconda-Umgebungen
Sie haben Anaconda gerade auf Ihrem Computer installiert, aber Sie müssen Umgebungen einrichten, bevor Sie Anaconda für Data Science verwenden können. Umgebungen sind separate Speicherorte in Ihrem Dateisystem, an denen Sie verschiedene Versionen von Python und Paketen installieren können.
Dieses Setup ist nützlich, wenn Sie mit mehreren Projekten arbeiten müssen, die unterschiedliche Python- oder Paketversionen erfordern.
Ab diesem Punkt im Tutorial können Sie Umgebungen und Dateien beliebig benennen, da sie willkürlich sind.
So richten Sie Ihre Anaconda-Umgebungen ein:
1. Führen Sie den Befehl conda create unten aus, um eine neue Umgebung namens my_env zu erstellen, in der Python3 (python=3) ausgeführt wird.
conda create --name my_env python=3
2. Geben Sie als Nächstes y ein und drücken Sie die Eingabetaste, wenn Sie aufgefordert werden, auszuwählen, ob Sie mit der Erstellung der Umgebung fortfahren möchten oder nicht.
3. Sobald die Umgebung erstellt wurde, führen Sie den folgenden conda activate-Befehl aus, um Ihre neue Umgebung (my_env) zu aktivieren.
conda activate my_env
4. Führen Sie nun den folgenden conda create aus Befehl, um alle Kernpython-Bibliotheken und -Tools zu installieren, die unten aufgeführt sind und für Data Science für Ihren data_env benötigt werden Umgebung:
scipy– Eine beliebte Python-Bibliothek für wissenschaftliches Rechnen zur Durchführung von Datenanalyseaufgaben.
numpy – Eine Bibliothek zum Arbeiten mit mehrdimensionalen Arrays.
pandas– Eine praktische Bibliothek für die Datenanalyse, da sie eine leistungsstarke und intuitive Möglichkeit bietet, mit tabellarischen Daten zu arbeiten.
matplotlib– Eine Plotbibliothek zur Erstellung anspruchsvoller Visualisierungen Ihrer Daten.
conda create --name data_env python=3 numpy scipy pandas matplotlib
5. Geben Sie y ein und drücken Sie die Eingabetaste, um mit der Erstellung der data_env-Umgebung fortzufahren.
6. Führen Sie abschließend den folgenden conda env-Befehl aus, um die Liste der verfügbaren Umgebungen zu überprüfen.
conda env listSie sehen alle Umgebungen, die auf Ihrem Computer erstellt wurden, einschließlich der Basisumgebung, wie unten gezeigt.
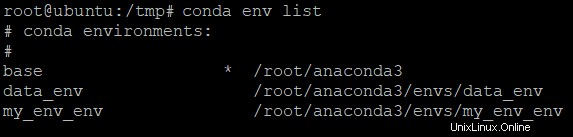
Laufen Sie Ihr erstes Python-Programm
Sie haben jetzt Ihre Umgebung am Laufen, und das ist großartig. Aber die Umgebung tut im Moment nicht viel, es sei denn, Sie schreiben ein Programm darauf. In diesem Tutorial verwenden Sie Ihre Umgebung, um ein einfaches Python-Programm zur Altersberechnung zu schreiben und auszuführen.
So schreiben Sie ein Python-Programm mit Ihrer Umgebung:
1. Führen Sie den folgenden Befehl aus, um Ihre Umgebung (my_env) zu aktivieren.
conda activate my_env
2. Führen Sie als Nächstes den folgenden Befehl aus, um den Python-Interpreter zu öffnen. Der Python-Interpreter ist eine REPL-Umgebung (Read-Evaluate-Print-Loop), mit der Sie Python-Code interaktiv schreiben und ausführen können.
python3
3. Kopieren Sie den folgenden Code, fügen Sie ihn in den Interpreter ein und drücken Sie die Eingabetaste.
Dieser Codeblock berechnet und druckt das Sterbealter einer Person, die 1900 geboren und 1970 zurückgegangen ist.
birth_year = 1900
death_year = 1970
age_at_death = death_year - birth_year
print(age_at_death)Unten sehen Sie die auf dem Terminal gedruckte Ausgabe 70, die anzeigt, dass die Person 70 Jahre alt war, als sie starb.
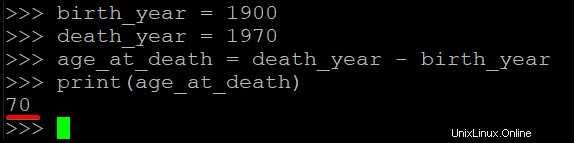
4. Führen Sie nun den folgenden Befehl exit() aus, um den Python-Interpreter
zu beendenexit()
5. Führen Sie zuletzt den folgenden Befehl aus, um die Sitzung der my_env-Umgebung zu schließen und zu beenden.
conda deactivate
Aufbau Ihres ersten Data-Science-Projekts
Bisher haben Sie gesehen, wie Sie ein einfaches Python-Programm in Ihrer Umgebung ausführen. Aber diesmal steigern Sie Ihr Data-Science-Spiel, indem Sie Ihr erstes Projekt erstellen. Ein Data-Science-Projekt umfasst in der Regel das Sammeln, Untersuchen, Analysieren und Visualisieren von Daten, um einen bestimmten Geschäftsbedarf oder ein bestimmtes Problem zu lösen.
Um Ihr erstes Data-Science-Projekt zu erstellen, zeichnen Sie Ihre Daten mit einem leichten (X, Y)-Streudiagramm mithilfe der matplotlib-Bibliothek auf:
1. Führen Sie den Befehl conda activate unten aus, um eine Umgebung namens data_env.
zu aktivierenconda activate data_env
2. Erstellen Sie als Nächstes eine Python-Datei mit dem Namen scatter.py mit Ihrem bevorzugten Texteditor.
nano scatter.py3. Fügen Sie den folgenden Code in Ihre scatter.py ein Datei, speichern Sie die Änderungen und schließen Sie den Editor. Dieser Codeblock erstellt zwei Arrays mit jeweils 12 Elementen und zeichnet und zeigt Datenpunkte.
# Imports matplotlib.pyplot to visualize the plot
import matplotlib.pyplot as plt
# Contains an array of numbers (cars ages) to x.
x = [5,7,8,7,2,17,2,9,4,11,12,9,6]
# Contains an array of nunbers (cars speeds) to y.
y = [99,86,87,88,111,86,103,87,94,78,77,85,86]
# Plot the data points
plt.scatter(x, y)
# Show the plotted data points
plt.show()4. Führen Sie schließlich den folgenden Befehl aus, um die Python-Datei (scatter.py) auszuführen, die den Plot auf dem Bildschirm anzeigt.
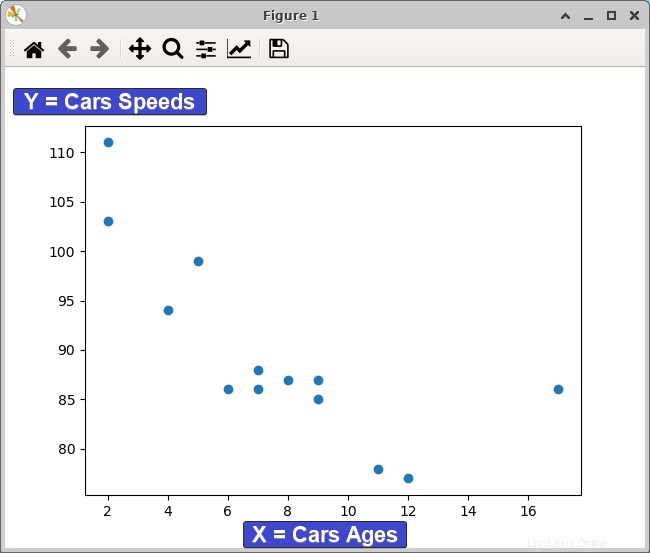
python scatter.pySie sehen die Datenpunkte in einem Diagramm, wie unten gezeigt. Die Beziehung zwischen Alter und Geschwindigkeit von Autos ist klar und kann bei Entscheidungen darüber helfen, wie die Leistung einer Fahrzeugflotte aufrechterhalten oder verbessert werden kann.
Die offensichtliche Beziehung besteht darin, dass mit zunehmendem Alter eines Autos die Geschwindigkeit, mit der es fahren kann, abnimmt.
Möglicherweise bemerken Sie auch eine leichte positive Korrelation zwischen Alter und Geschwindigkeit – mit zunehmendem Alter der Autos nehmen auch ihre Geschwindigkeiten tendenziell leicht zu. Diese Beziehung kann für Automobilhersteller nützlich sein, die ihre Fahrzeuge hinsichtlich Leistung und Effizienz optimieren möchten.
Hier hast du es! Sie haben Anaconda erfolgreich unter Linux installiert und Ihr erstes Data-Science-Projekt erstellt.
Umgebungen entfernen
Umgebungen verbrauchen Ihren Speicherplatz, insbesondere wenn Sie solche behalten, die keinen Zweck mehr erfüllen. Warum nicht entfernen? Die conda env remove reicht aus, solange Sie den Namen der zu entfernenden Umgebung kennen.
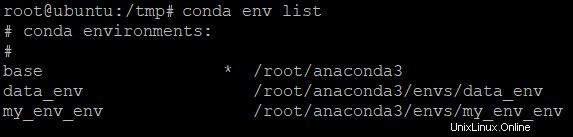
Führen Sie den folgenden Befehl aus, um alle Umgebungen aufzulisten.
conda env list
Notieren Sie sich den Namen der Umgebung, die Sie entfernen möchten.
Führen Sie nun den folgenden Befehl zu remove aus die Umgebung mit dem Namen (-n ) data_env . Ersetzen Sie data_env mit dem Namen Ihrer zu entfernenden Zielumgebung.
conda env remove -n data_env

Alternativ können Sie den folgenden Befehl ausführen und den Pfad angeben (-p ), in der sich die Umgebung befindet (/root/anaconda3/envs/data_env ).
conda env remove -p /root/anaconda3/envs/data_env

Schlussfolgerung
In diesem Tutorial haben Sie gelernt, wie Sie Anaconda unter Ubuntu Linux installieren und eine Python 3-Umgebung für Data Science erstellen. Sie haben Ihr erstes Programm geschrieben und matplotlib verwendet, um Ihre Daten zu plotten.
An diesem Punkt sind Sie jetzt bereit, Ihre Reise als Datenwissenschaftler mit diesen Fähigkeiten zu beginnen!
Warum beginnen Sie Ihre Data-Science-Reise nicht mit Anaconda Navigator? Beginnen Sie mit der Erkundung, Analyse und Visualisierung von Daten für Ihre eigenen Projekte!