Benötigen Sie eine Streaming-Plattform, um große Datenmengen zu verarbeiten? Sie haben zweifellos von Apache Kafka unter Linux gehört. Apache Kafka eignet sich perfekt für die Echtzeit-Datenverarbeitung und wird immer beliebter. Die Installation von Apache Kafka unter Linux kann etwas knifflig sein, aber keine Sorge, dieses Tutorial hilft Ihnen dabei.
In diesem Tutorial erfahren Sie, wie Sie Apache Kafka installieren und konfigurieren, damit Sie Ihre Daten wie ein Profi verarbeiten und Ihr Unternehmen effizienter und produktiver machen können.
Lesen Sie weiter und beginnen Sie noch heute mit dem Streamen von Daten mit Apache Kafka!
Voraussetzungen
Dieses Tutorial wird eine praktische Demonstration sein. Wenn Sie mitmachen möchten, stellen Sie sicher, dass Sie Folgendes haben.
- Eine Linux-Maschine – Diese Demo verwendet Debian 10, aber jede Linux-Distribution funktioniert.
- Ein Nicht-Root-Benutzerkonto mit sudo-Berechtigungen, das zum Ausführen von Kafka erforderlich ist und den Namen
kafkaträgt in diesem Tutorial. - Ein dedizierter sudo-Benutzer für Kafka – Dieses Tutorial verwendet einen sudo-Benutzer namens kafka.
- Java – Java ist ein wesentlicher Bestandteil der Apache Kafka-Installation.
- Git – Dieses Tutorial verwendet Git zum Herunterladen der Apache Kafka Unit-Dateien.
Installieren von Apache Kafka
Bevor Sie Daten streamen können, müssen Sie zuerst Apache Kafka auf Ihrem Computer installieren. Da Sie ein dediziertes Konto für Kafka haben, können Sie Kafka installieren, ohne sich Gedanken über eine Beschädigung Ihres Systems machen zu müssen.
1. Führen Sie mkdir aus Befehl unten, um /home/kafka/Downloads zu erstellen Verzeichnis. Sie können das Verzeichnis nach Belieben benennen, aber das Verzeichnis heißt Downloads für diese Demo. Dieses Verzeichnis speichert die Kafka-Binärdateien. Diese Aktion stellt sicher, dass alle Ihre Dateien für Kafka für kafka verfügbar sind Benutzer.
mkdir Downloads
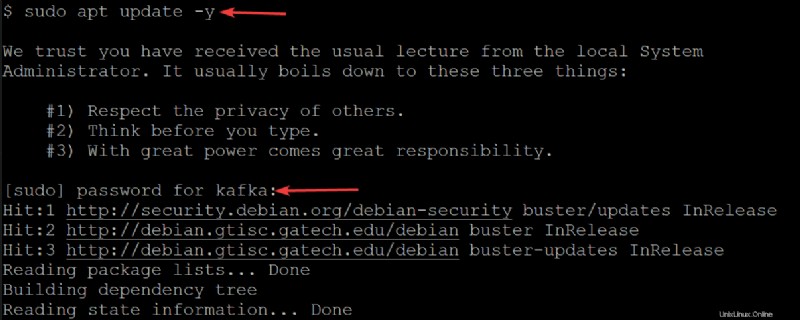
2. Als nächstes führen Sie den folgenden apt update aus Befehl, um den Paketindex Ihres Systems zu aktualisieren.
sudo apt update -yGeben Sie das Passwort für Ihren Kafka-Benutzer ein, wenn Sie dazu aufgefordert werden.
3. Führen Sie curl aus Befehl unten, um Kafka-Binärdateien von der Apache Foundation-Website herunterzuladen und auszugeben (-o ) in eine Binärdatei (kafka.tgz ) in Ihrem ~/Downloads Verzeichnis. Sie verwenden diese Binärdatei, um Kafka zu installieren.
Stellen Sie sicher, dass Sie kafka/3.1.0/kafka_2.13-3.1.0.tgz durch die neueste Version der Kafka-Binärdateien ersetzen. Zum jetzigen Zeitpunkt ist die aktuelle Kafka-Version 3.1.0.
curl "https://dlcdn.apache.org/kafka/3.1.0/kafka_2.13-3.1.0.tgz" -o ~/Downloads/kafka.tgz
4. Führen Sie nun tar aus Befehl unten zum Extrahieren (-x ) die Kafka-Binärdateien (~/Downloads/kafka.tgz ) in das automatisch erstellte kafka Verzeichnis. Die Optionen im tar Befehl führen Sie Folgendes aus:
Die Optionen im tar Befehl führen Sie Folgendes aus:
-v– Sagt dietarBefehl, um alle Dateien aufzulisten, während sie extrahiert werden.
-z– Sagt dietarBefehl, um das Archiv zu gzip, während es dekomprimiert wird. Dieses Verhalten ist in diesem Fall nicht erforderlich, aber eine hervorragende Option, insbesondere wenn Sie schnell eine komprimierte/gezippte Datei zum Verschieben benötigen.
-f– Sagt dietarBefehl, welche Archivdatei extrahiert werden soll.
-strip 1- Weist dentaran Befehl, um die erste Verzeichnisebene aus Ihrer Dateinamenliste zu entfernen. Als Ergebnis erstellen Sie automatisch ein Unterverzeichnis mit dem Namen kafka enthält alle extrahierten Dateien aus~/Downloads/kafka.tgzDatei.
tar -xvzf ~/Downloads/kafka.tgz --strip 1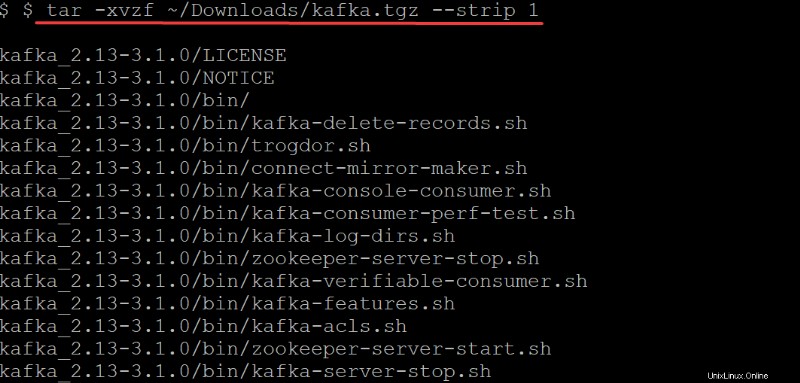
Konfigurieren des Apache Kafka-Servers
An diesem Punkt haben Sie die Kafka-Binärdateien heruntergeladen und in Ihren ~/Downloads installiert Verzeichnis. Sie können den Kafka-Server noch nicht verwenden, da Kafka Ihnen standardmäßig nicht erlaubt, Themen zu löschen oder zu ändern, eine Kategorie, die zum Organisieren von Protokollnachrichten erforderlich ist.
Um Ihren Kafka-Server zu konfigurieren, müssen Sie die Kafka-Konfigurationsdatei (/etc/kafka/server.properties). bearbeiten
1. Öffnen Sie die Kafka-Konfigurationsdatei (/etc/kafka/server.properties ) in Ihrem bevorzugten Texteditor.
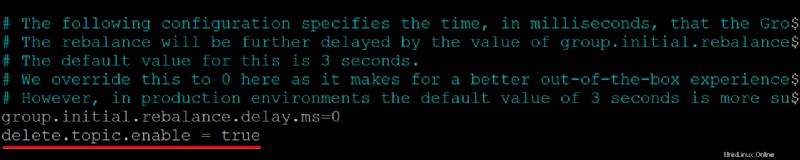
2. Fügen Sie als Nächstes delete.topic.enable =true hinzu Zeile unten in /kafka/config/server.properties Dateiinhalt, speichern Sie die Änderungen und schließen Sie den Editor.
Diese Konfigurationseigenschaft erteilt Ihnen die Berechtigung zum Löschen oder Ändern von Themen. Stellen Sie daher sicher, dass Sie wissen, was Sie tun, bevor Sie Themen löschen. Durch das Löschen eines Themas werden auch Partitionen für dieses Thema gelöscht. Alle Daten, die in diesen Partitionen gespeichert sind, sind nicht mehr zugänglich, sobald sie weg sind.
Achten Sie darauf, dass am Anfang jeder Zeile keine Leerzeichen stehen, sonst wird die Datei nicht erkannt und Ihr Kafka-Server funktioniert nicht.
3. Führen Sie git aus Befehl unten an clone der ata-kafka project auf Ihren lokalen Computer, damit Sie es zur Verwendung als Unit-Datei für Ihren Kafka-Dienst ändern können.
sudo git clone https://github.com/Adam-the-Automator/apache-kafka.git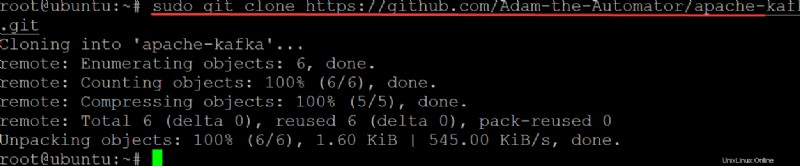
Führen Sie nun die folgenden Befehle aus, um in apache-kafka zu wechseln Verzeichnis und listen Sie die darin enthaltenen Dateien auf.
cd apache-kafka
lsJetzt sind Sie im ata-kafka Verzeichnis können Sie sehen, dass Sie zwei Dateien darin haben:kafka.service und zookeeper.service, wie unten gezeigt.

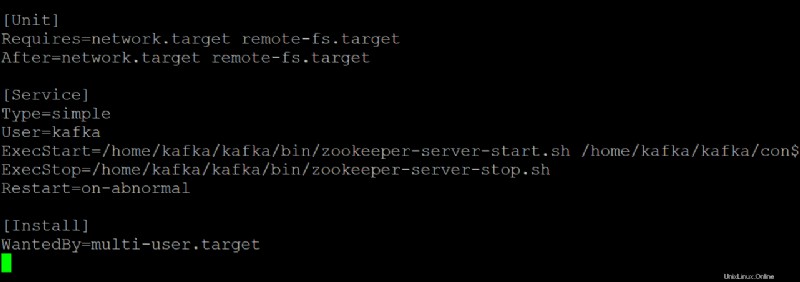
5. Öffnen Sie den zookeeper.service Datei in Ihrem bevorzugten Texteditor. Sie verwenden diese Datei als Referenz zum Erstellen von kafka.service Datei.
Passen Sie jeden Abschnitt unten im zookeeper.service an Datei, je nach Bedarf. Aber diese Demo verwendet diese Datei so, wie sie ist, ohne Änderungen.
- Der
[Unit]Abschnitt konfiguriert die Starteigenschaften für dieses Gerät. Dieser Abschnitt teilt dem systemd mit, was beim Starten des Zookeeper-Dienstes zu verwenden ist.
- Der Abschnitt [Service] definiert, wie, wann und wo der Kafka-Dienst mit kafka-server-start.sh gestartet werden soll Skript. Dieser Abschnitt definiert auch grundlegende Informationen wie Name, Beschreibung und Befehlszeilenargumente (was auf ExecStart=folgt).
- Der
[Install]Abschnitt legt den Runlevel fest, um den Dienst zu starten, wenn in den Mehrbenutzermodus gewechselt wird.
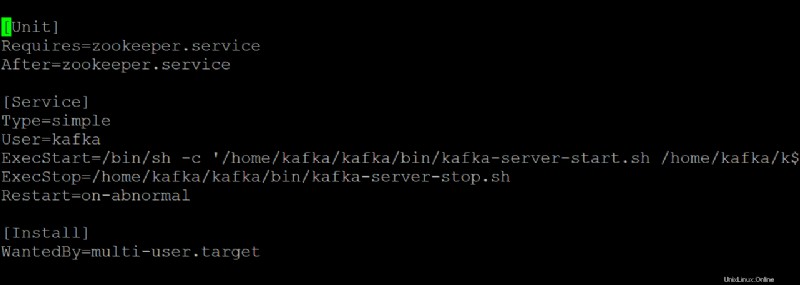
6. Öffnen Sie den kafka.service Datei in Ihrem bevorzugten Texteditor und konfigurieren Sie, wie Ihr Kafka-Server aussieht, wenn er als systemd-Dienst ausgeführt wird.
Diese Demo verwendet die Standardwerte aus kafka.service Datei, aber Sie können die Datei nach Bedarf anpassen. Beachten Sie, dass diese Datei auf zookeeper.service verweist Datei, die Sie möglicherweise irgendwann ändern.
7. Führen Sie den folgenden Befehl zu start aus der kafka Service.
sudo systemctl start kafkaDenken Sie daran, Ihren Kafka-Server als Dienst zu stoppen und zu starten. Wenn Sie dies nicht tun, bleibt der Prozess im Speicher und Sie können den Prozess nur stoppen, indem Sie ihn beenden. Dieses Verhalten kann zu Datenverlust führen, wenn Themen geschrieben oder aktualisiert werden, während der Prozess beendet wird.
Da Sie kafka.service erstellt haben und zookeeper.service Dateien können Sie auch einen der folgenden Befehle ausführen, um Ihren systemd-basierten Kafka-Server zu stoppen oder neu zu starten.
sudo systemctl stop kafka
sudo systemctl restart kafka
8. Führen Sie nun journalctl aus Befehl unten, um zu überprüfen, ob der Dienst erfolgreich gestartet wurde.
Dieser Befehl listet alle Protokolle für den Kafka-Dienst auf.
sudo journalctl -u kafkaWenn Sie alles richtig konfiguriert haben, sehen Sie eine Meldung mit der Aufschrift Started kafka.service, wie unten gezeigt. Herzliche Glückwünsche! Sie haben jetzt einen voll funktionsfähigen Kafka-Server, der als systemd-Dienste ausgeführt wird.

Einschränken des Kafka-Benutzers
Zu diesem Zeitpunkt wird der Kafka-Dienst als kafka-Benutzer ausgeführt. Der kafka-Benutzer ist ein Benutzer auf Systemebene und sollte nicht für Benutzer sichtbar sein, die eine Verbindung zu Kafka herstellen.
Jeder Client, der sich über diesen Broker mit Kafka verbindet, hat effektiv Zugriff auf Root-Ebene auf dem Broker-Computer, was nicht empfohlen wird. Um das Risiko zu mindern, entfernen Sie den kafka-Benutzer aus der sudoers-Datei und deaktivieren das Passwort für den kafka-Benutzer.
1. Führen Sie exit aus Befehl unten, um zu Ihrem normalen Benutzerkonto zurückzukehren.
exit
2. Als nächstes führen Sie sudo deluser kafka sudo aus und drücken Sie Enter um zu bestätigen, dass Sie kafka entfernen möchten Benutzer von sudoers.
sudo deluser kafka sudo
3. Führen Sie den folgenden Befehl aus, um das Passwort für den kafka-Benutzer zu deaktivieren. Dadurch wird die Sicherheit Ihrer Kafka-Installation weiter verbessert.
sudo passwd kafka -l
4. Führen Sie nun den folgenden Befehl erneut aus, um den kafka-Benutzer aus der sudoers-Liste zu entfernen.
sudo deluser kafka sudo
5. Führen Sie den folgenden su aus Befehl, um festzulegen, dass nur autorisierte Benutzer wie Root-Benutzer Befehle als kafka ausführen können Benutzer.
sudo su - kafka
6. Führen Sie als Nächstes den folgenden Befehl aus, um ein neues Kafka-Thema mit dem Namen ATA zu erstellen um zu überprüfen, ob Ihr Kafka-Server korrekt läuft.
Kafka-Themen sind Feeds von Nachrichten zum/vom Server, wodurch die Komplikationen beseitigt werden, die durch chaotische und unorganisierte Daten auf den Kafka-Servern entstehen
cd /usr/local/kafka-server && bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic ATA
7. Führen Sie den folgenden Befehl aus, um einen Kafka-Produzenten mit kafka-console-producer.sh zu erstellen Skript. Kafka-Produzenten schreiben Daten zu Topics.
echo "Hello World, this sample provided by ATA" | bin/kafka-console-producer.sh --broker-list localhost:9092 --topic ATA > /dev/null
8. Führen Sie schließlich den folgenden Befehl aus, um einen Kafka-Verbraucher mit dem kafka-console-consumer.sh zu erstellen Skript. Dieser Befehl verbraucht alle Nachrichten im Kafka-Thema (--topic ATA ) und druckt dann den Nachrichtenwert aus.
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic ATA --from-beginningSie sehen die Nachricht in der Ausgabe unten, da Ihre Nachrichten vom Kafka-Konsolenkonsumenten aus dem ATA-Kafka-Thema gedruckt werden, wie unten gezeigt. Das Consumer-Skript wird an dieser Stelle weiter ausgeführt und wartet auf weitere Nachrichten.
Sie können ein anderes Terminal öffnen, um weitere Nachrichten zu Ihrem Thema hinzuzufügen, und Strg+C drücken, um das Consumer-Skript zu stoppen, sobald Sie mit dem Testen fertig sind.

Schlussfolgerung
In diesem Lernprogramm haben Sie gelernt, Apache Kafka auf Ihrem Computer einzurichten und zu konfigurieren. Sie haben auch das Konsumieren von Nachrichten aus einem Kafka-Thema angesprochen, das vom Kafka-Produzenten produziert wurde, was zu einer effektiven Ereignisprotokollverwaltung führte.
Warum bauen Sie nun nicht auf diesem neu gewonnenen Wissen auf, indem Sie Kafka mit Flume installieren, um Ihre Nachrichten besser zu verteilen und zu verwalten? Sie können auch die Streams-API von Kafka erkunden und Anwendungen erstellen, die Daten in Kafka lesen und schreiben. Dadurch werden Daten nach Bedarf transformiert, bevor sie in ein anderes System wie HDFS, HBase oder Elasticsearch geschrieben werden.