Wenn Sie es leid sind, dass Ihre Bash-Skripte ewig dauern, bis sie ausgeführt werden, ist dieses Tutorial genau das Richtige für Sie. Oft können Sie Skripte parallel bashen, was das Ergebnis dramatisch beschleunigen kann. Wie? Verwenden des GNU-Parallel-Dienstprogramms, auch nur Parallel genannt, mit einigen praktischen GNU-Parallel-Beispielen!
Parallel führt Bash-Skripte parallel über ein Konzept namens Multi-Threading aus. Mit diesem Dienstprogramm können Sie verschiedene Jobs pro CPU statt nur einem ausführen, wodurch die Zeit zum Ausführen eines Skripts verkürzt wird.
In diesem Tutorial lernen Sie Multi-Threading-Bash-Skripte mit einer Menge toller GNU-Parallel-Beispiele!
Voraussetzungen
Dieses Tutorial wird voller praktischer Demonstrationen sein. Wenn Sie mitmachen möchten, vergewissern Sie sich, dass Sie Folgendes haben:
- Ein Linux-Computer. Jede Distribution funktioniert. Das Tutorial verwendet Ubuntu 20.04, das auf dem Windows-Subsystem für Linux (WSL) ausgeführt wird.
- Angemeldet mit einem Benutzer mit sudo-Berechtigungen.
GNU Parallel installieren
Um mit der Beschleunigung von Bash-Skripten mit Multithreading zu beginnen, müssen Sie zunächst Parallel installieren. Beginnen wir also damit, es herunterzuladen und zu installieren.
1. Öffnen Sie ein Bash-Terminal.
2. Führen Sie wget aus um das Parallelpaket herunterzuladen. Der folgende Befehl lädt die neueste Version herunter (parallel-latest ) in das aktuelle Arbeitsverzeichnis.
wget https://ftp.gnu.org/gnu/parallel/parallel-latest.tar.bz2Wenn Sie lieber eine ältere Version von GNU Parallel verwenden möchten, finden Sie alle Pakete auf der offiziellen Download-Seite.
3. Führen Sie nun den folgenden tar-Befehl aus, um das gerade heruntergeladene Paket zu entarchivieren.
Unten verwendet der Befehl den x Flag zum Extrahieren des Archivs, j um anzugeben, dass es auf ein Archiv mit einem .bz2 abzielt Erweiterung und f um eine Datei als Eingabe für den tar-Befehl zu akzeptieren. sudo tar -xjf parallel-latest.tar.bz2
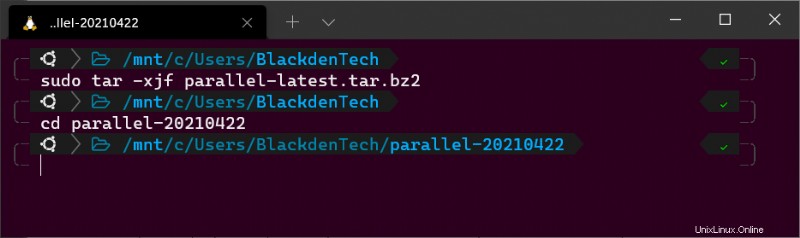
sudo tar -xjf parallel-latest.tar.bz2Sie sollten jetzt ein Verzeichnis namens parallel- haben mit Monat, Tag und Jahr der letzten Veröffentlichung.
4. Navigieren Sie mit cd in den Paketarchivordner . In diesem Tutorial heißt der Paketarchivordner parallel-20210422 , Wie nachfolgend dargestellt.
5. Erstellen und installieren Sie als Nächstes die GNU Parallel-Binärdatei, indem Sie die folgenden Befehle ausführen:
./configure
make
make installÜberprüfen Sie nun, ob Parallel korrekt installiert wurde, indem Sie die installierte Version überprüfen.
parallel --version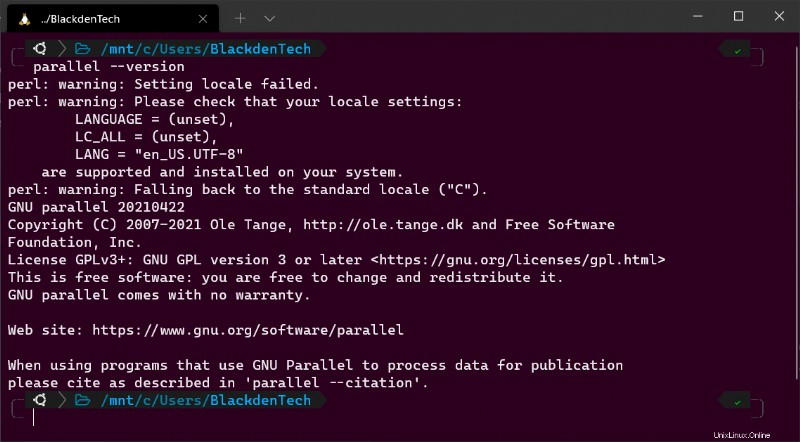
Wenn Sie Parallel zum ersten Mal ausführen, sehen Sie möglicherweise auch ein paar beängstigende Zeilen, die Text wie
perl: warning:anzeigen . Diese Warnmeldungen weisen darauf hin, dass Parallel Ihre aktuellen Gebietsschema- und Spracheinstellungen nicht erkennen kann. Aber machen Sie sich vorerst keine Sorgen über diese Warnungen. Sie erfahren später, wie Sie diese Warnungen beheben.
GNU Parallel konfigurieren
Nachdem Parallel installiert ist, können Sie es sofort verwenden! Aber zuerst ist es wichtig, ein paar kleinere Einstellungen zu konfigurieren, bevor Sie beginnen.
Stimmen Sie noch in Ihrem Bash-Terminal der GNU Parallel-Erlaubnis für akademische Forschung zu und teilen Sie Parallel mit, dass Sie sie in jeder akademischen Forschung zitieren werden, indem Sie den citation angeben Parameter gefolgt von will cite .
Wenn Sie GNU oder seine Betreuer nicht unterstützen möchten, ist die Zustimmung zum Zitieren nicht erforderlich, um GNU Parallel zu verwenden.
parallel --citation
will citeÄndern Sie das Gebietsschema, indem Sie die folgenden Umgebungsvariablen festlegen, indem Sie die folgenden Codezeilen ausführen. Das Festlegen von Gebietsschema- und Sprachumgebungsvariablen wie dieser ist nicht erforderlich. Aber GNU Parallel prüft sie jedes Mal, wenn es läuft.
Wenn die Umgebungsvariablen nicht existieren, wird sich Parallel jedes Mal darüber beschweren, wie Sie im vorherigen Abschnitt gesehen haben.
In diesem Tutorial wird davon ausgegangen, dass Sie Englisch sprechen. Andere Sprachen werden ebenfalls unterstützt.
export LC_ALL=C man
export LANGUAGE=en_US
export LANG=en_US.UTF-8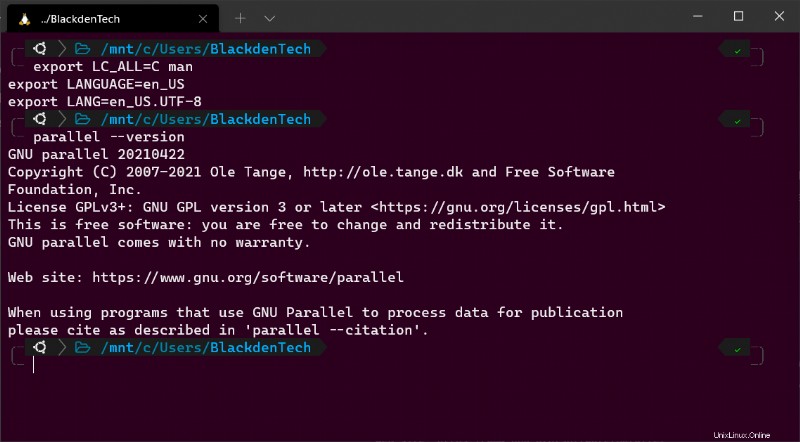
Ausführen von Ad-hoc-Shell-Befehlen
Beginnen wir jetzt mit der Verwendung von GNU Parallel! Zunächst lernen Sie die grundlegende Syntax kennen. Sobald Sie sich mit der Syntax vertraut gemacht haben, werden Sie später auf einige praktische GNU Parallel-Beispiele eingehen.
Beginnen wir mit einem supereinfachen Beispiel, bei dem nur die Zahlen 1-5 wiederholt werden.
1. Führen Sie in Ihrem Bash-Terminal die folgenden Befehle aus. Spannend, oder? Bash verwendet den Echo-Befehl, um die Zahlen 1-5 an das Terminal zu senden. Wenn Sie jeden dieser Befehle in ein Skript einfügen würden, würde Bash jeden nacheinander ausführen und darauf warten, dass der vorherige beendet wird.
In diesem Beispiel führen Sie fünf Befehle aus, die kaum Zeit in Anspruch nehmen. Aber stellen Sie sich vor, diese Befehle wären Bash-Skripte, die tatsächlich etwas Nützliches tun, aber ewig brauchen, um ausgeführt zu werden?
echo 1
echo 2
echo 3
echo 4
echo 5
Führen Sie nun jeden dieser Befehle gleichzeitig mit Parallel wie unten aus. In diesem Beispiel führt Parallel den echo-Befehl aus und wird durch ::: gekennzeichnet , übergibt diesem Befehl die Argumente 1 , 2 , 3 , 4 , 5 . Die drei Doppelpunkte teilen Parallel mit, dass Sie Eingaben über die Befehlszeile und nicht über die Pipeline bereitstellen (mehr später).
Im folgenden Beispiel haben Sie einen einzelnen Befehl ohne Optionen an Parallel übergeben. Hier hat Parallel, wie bei allen Parallel-Beispielen, für jeden Befehl einen neuen Prozess mit einem anderen CPU-Kern gestartet.
# From the command line
parallel echo ::: 1 2 3 4 5Alle parallelen Befehle folgen der Syntax
parallel [Options].
3. Erstellen Sie eine Datei mit dem Namen count_file.txt, um den parallelen Empfang von Eingaben von der Bash-Pipeline zu demonstrieren Wie unten. Jede Zahl stellt das Argument dar, das Sie an den echo-Befehl übergeben.
1
2
3
4
5
4. Führen Sie nun cat aus Befehl, um diese Datei zu lesen und die Ausgabe an Parallel zu übergeben, wie unten gezeigt. In diesem Beispiel die {} stellt jedes Argument (1-5) dar, das an Parallel übergeben wird.
# From the pipeline cat count_file.txt | parallel echo {}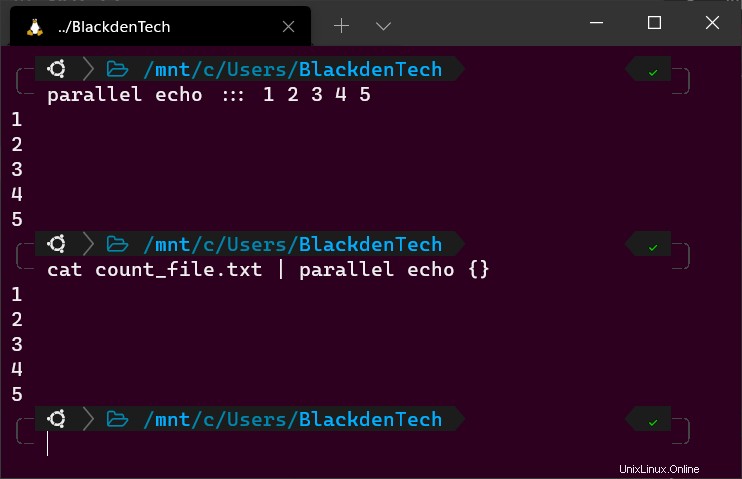
Vergleich von Bash und GNU Parallel
Im Moment scheint die Verwendung von Parallel nur eine komplizierte Möglichkeit zu sein, Bash-Befehle auszuführen. Aber der eigentliche Vorteil für Sie ist die Zeitersparnis. Denken Sie daran, dass Bash nur auf einem CPU-Kern läuft, während GNU Parallel auf mehreren gleichzeitig läuft.
1. Um den Unterschied zwischen sequentiellen und parallelen Bash-Befehlen zu demonstrieren, erstellen Sie ein Bash-Skript mit dem Namen test.sh mit folgendem Code. Erstellen Sie dieses Skript in demselben Verzeichnis, in dem Sie die count_file.txt erstellt haben früher rein.
Das folgende Bash-Skript liest die count_file.txt Datei, schläft für 1, 2, 3, 4 und 5 Sekunden, gibt die Schlafdauer an das Terminal zurück und wird beendet.
#!/bin/bash
nums=$(cat count_file.txt) # Read count_file.txt
for num in $nums # For each line in the file, start a loop
do
sleep $num # Read the line and wait that many seconds
echo $num # Print the line
done
2. Führen Sie nun das Skript mit time aus Befehl, um zu messen, wie lange das Skript zum Abschließen benötigt. Es dauert 15 Sekunden.
time ./test.sh
3. Verwenden Sie nun den time Befehl erneut, um dieselbe Aufgabe auszuführen, aber verwenden Sie diesmal Parallel, um dies zu tun.
Der folgende Befehl führt die gleiche Aufgabe aus, aber dieses Mal wird, anstatt auf den Abschluss der ersten Schleife zu warten, bevor die nächste gestartet wird, eine auf jedem CPU-Kern ausgeführt und so viele wie möglich gleichzeitig gestartet.
time cat count_file.txt | parallel "sleep {}; echo {}"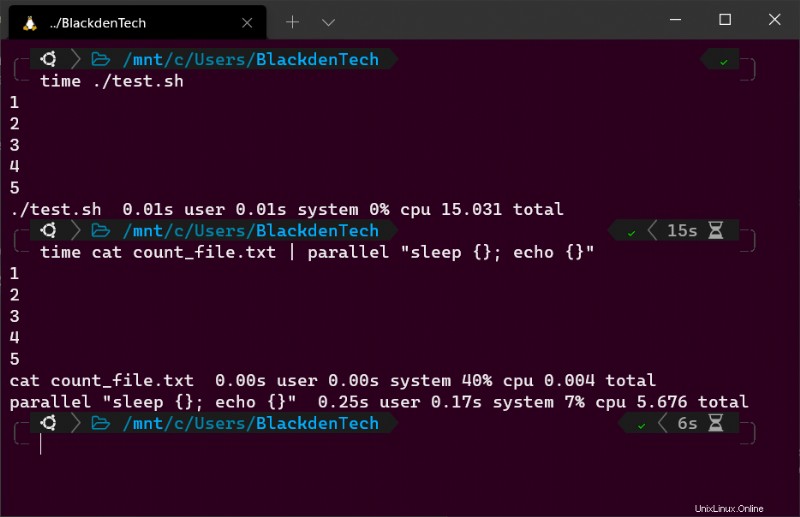
Kenne den Probelauf!
Es ist jetzt an der Zeit, auf einige weitere reale GNU-Parallel-Beispiele einzugehen. Aber bevor Sie das tun, sollten Sie zuerst etwas über --dryrun wissen Flagge. Dieses Flag ist praktisch, wenn Sie sehen möchten, was passieren wird, ohne dass Parallel es tatsächlich tut.
Die --dryrun flag kann die letzte Plausibilitätsprüfung sein, bevor ein Befehl ausgeführt wird, der sich nicht so verhält, wie Sie es sich vorgestellt haben. Wenn Sie einen Befehl eingeben, der Ihrem System schaden würde, hilft Ihnen GNU Parallel leider nur, es schneller zu beschädigen!
parallel --dryrun "rm rf {}"GNU Parallel Beispiel Nr. 1:Dateien aus dem Web herunterladen
Für diese Aufgabe laden Sie eine Liste mit Dateien von verschiedenen URLs im Internet herunter. Diese URLs könnten beispielsweise Webseiten darstellen, die Sie speichern möchten, Bilder oder sogar eine Liste von Dateien von einem FTP-Server.
Für dieses Beispiel laden Sie eine Liste der Archivpakete (und der SIG-Dateien) vom FTP-Server von GNU Parallel herunter.
1. Erstellen Sie eine Datei namens download_items.txt, Holen Sie sich einige Download-Links von der offiziellen Download-Site und fügen Sie sie getrennt durch eine neue Zeile zur Datei hinzu.
https://ftp.gnu.org/gnu/parallel/parallel-20120122.tar.bz2
https://ftp.gnu.org/gnu/parallel/parallel-20120122.tar.bz2.sig
https://ftp.gnu.org/gnu/parallel/parallel-20120222.tar.bz2
https://ftp.gnu.org/gnu/parallel/parallel-20120222.tar.bz2.sigSie könnten etwas Zeit sparen, indem Sie Pythons Beautiful Soup-Bibliothek verwenden, um alle Links von der Download-Seite zu entfernen.
2. Lesen Sie alle URLs aus der download_items.txt Datei und übergebe sie an Parallel, das wget aufruft und übergeben Sie jede URL.
cat download_items.txt | parallel wget {}Vergessen Sie diesen
{}nicht in einem parallelen Befehl ist ein Platzhalter für die Eingabezeichenfolge!
3. Vielleicht müssen Sie die Anzahl der Threads kontrollieren, die GNU Parallel gleichzeitig verwendet. Fügen Sie in diesem Fall den --jobs hinzu oder -j Parameter für den Befehl. Der --jobs Der Parameter begrenzt die Anzahl der Threads, die gleichzeitig ausgeführt werden können, auf die von Ihnen angegebene Anzahl.
Um beispielsweise Parallel auf das gleichzeitige Herunterladen von fünf URLs zu beschränken, würde der Befehl wie folgt aussehen:
#!/bin/bash
cat download_items.txt | parallel --jobs 5 wget {}Der
--jobsDer Parameter im obigen Befehl kann angepasst werden, um eine beliebige Anzahl von Dateien herunterzuladen, solange der Computer, auf dem Sie laufen, über so viele CPUs verfügt, um sie zu verarbeiten.
4. Um die Wirkung des --jobs zu demonstrieren Parameter, passen Sie jetzt die Jobanzahl an und führen Sie time aus Befehl, um zu messen, wie lange jeder Lauf dauert.
time cat download_items.txt | parallel --jobs 5 wget {}
time cat download_items.txt | parallel --jobs 10 wget {}GNU Parallel Beispiel #2:Archivpakete entpacken
Nachdem Sie nun alle diese Archivdateien aus dem vorherigen Beispiel heruntergeladen haben, müssen Sie sie jetzt aus dem Archiv entfernen.
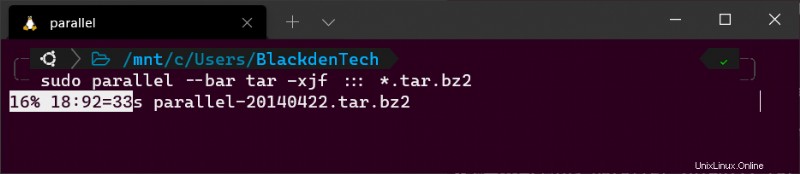
Führen Sie im selben Verzeichnis wie die Archivpakete den folgenden parallelen Befehl aus. Beachten Sie die Verwendung des Platzhalters (* ). Da dieses Verzeichnis beide Archivpakete und enthält der SIG-Dateien müssen Sie Parallel anweisen, nur .tar.bz2 zu verarbeiten Dateien.
sudo parallel tar -xjf ::: *.tar.bz2
Bonus! Wenn Sie GNU parallel interaktiv verwenden (nicht in einem Skript), fügen Sie den --bar hinzu Flag, damit Parallel Ihnen einen Fortschrittsbalken anzeigt, während die Aufgabe ausgeführt wird.
GNU Parallel Beispiel #3:Dateien entfernen
Wenn Sie die Beispiele eins und zwei befolgt haben, sollten jetzt viele Ordner in Ihrem Arbeitsverzeichnis Platz beanspruchen. Entfernen wir also alle diese Dateien parallel!
Zum Entfernen aller Ordner, die mit parallel- beginnen Listen Sie mit Parallel alle Ordner mit ls -d auf und leiten Sie jeden dieser Ordnerpfade an Parallel weiter, indem Sie rm -rf aufrufen in jedem Ordner, wie unten gezeigt.
Denken Sie an den
--dryrunFlagge!
ls -d parallel-*/ | parallel "rm -rf {}"Fazit
Jetzt können Sie Aufgaben mit Bash automatisieren und sich viel Zeit sparen. Was Sie mit dieser Zeit anfangen, bleibt Ihnen überlassen. Ob Zeitersparnis bedeutet, die Arbeit etwas früher zu verlassen oder einen anderen ATA-Blogbeitrag zu lesen, es ist Zeit für Sie.
Denken Sie jetzt an all die langlaufenden Skripts in Ihrer Umgebung. Welche können Sie mit Parallel beschleunigen?