Wenn Sie nach einer Echtzeit-Datenanalyseplattform suchen, ist Apache Druid laut Jack Wallen schwer zu schlagen. Erfahren Sie, wie Sie dieses Tool zum Laufen bringen und dann Beispieldaten laden.
Apache Druid ist eine Echtzeit-Analytics-Datenbank, die entwickelt wurde, um schnelle Slice-and-Dice-Analytics für riesige Datensätze zu erstellen. Sie können Apache Druid ganz einfach von einer Desktop-Version von Linux – oder einem Linux-Server mit einer GUI – ausführen und dann Daten laden, um mit dem Parsen zu beginnen.
Apache Druid enthält Funktionen wie:
- Spaltenorientierte Speicherung
- Native Suchindizes
- Streaming und Batch-Ingest
- Flexible Schemas
- Zeitoptimierte Partitionierung
- SQL-Unterstützung
- Horizontale Skalierbarkeit
- Einfache Bedienung
Apache Druid ist eine großartige Option für Anwendungsfälle, die Echtzeitaufnahme, schnelle Abfragen und hohe Verfügbarkeit erfordern.
Ich werde Sie durch den Prozess führen, Apache Druid unter Pop!_OS Linux zum Laufen zu bringen (obwohl es auf jeder Linux-Distribution ausgeführt werden kann) und Ihnen dann zeigen, wie Sie Beispieldaten laden.
Was Sie brauchen
Das einzige, was Sie brauchen, damit dies funktioniert, ist eine laufende Linux-Instanz mit einer Desktop-Umgebung und einem Benutzer mit sudo-Berechtigungen.
Das ist es. Lassen Sie uns etwas Datenbankmagie machen.
So installieren Sie Java 8
Im Moment unterstützt Apache Druid nur Java 8, daher müssen wir sicherstellen, dass es installiert und als Standard festgelegt ist. Um Java 8 auf einer Ubuntu-basierten Desktop-Distribution zu installieren, melden Sie sich am Computer an, öffnen Sie ein Terminalfenster und geben Sie den Befehl ein:
sudo apt install openjdk-8-jdk -y
Nachdem die Installation abgeschlossen ist, müssen Sie Java 8 als Standard festlegen. Tun Sie dies mit dem Befehl:
sudo update-alternatives --config java
Sie sollten eine Liste aller Java-Versionen sehen, die derzeit auf dem Computer installiert sind. Stellen Sie sicher, dass Sie die Nummer auswählen, die Java 8 entspricht.
Ein Wort zu Apache Druid-Diensten
Was wir starten werden, ist eine Mikroinstanz von Apache Druid, die 4 CPUs und 16 GB RAM benötigt. Es gibt 6 verschiedene Dienstkonfigurationen für Apache Druid, und zwar:
- Nano-Quickstart:1 CPU, 4GB RAM
- Mikro-Quickstart:4 CPU, 16GB RAM
- Klein:8 CPU, 64 GB RAM
- Mittel:16 CPU, 128 GB RAM
- Groß:32 CPU, 256 GB RAM
- X-Large:64 CPU, 512 GB RAM
Abhängig von der Größe Ihrer Daten und Anforderungen. Wenn Sie auf riesige Datenmengen stoßen, wird empfohlen, Apache Druid als Cluster bereitzustellen. Da wir Apache Druid jedoch gerade erst kennenlernen, ist die Mikroinstanz in Ordnung.
Pflichtlektüre für Entwickler
Wie man Apache Druid herunterlädt und entpackt
Wenn Java installiert ist, ist es an der Zeit, Apache Druid herunterzuladen und zu entpacken. Zurück im Terminalfenster laden Sie die neueste Version mit dem Befehl herunter (stellen Sie sicher, dass Sie auf der Apache Druid-Downloadseite nachsehen, ob dies die neueste Version ist) mit dem Befehl:
wget https://dlcdn.apache.org/druid/0.22.1/apache-druid-0.22.1-bin.tar.gz
Entpacken Sie die heruntergeladene Datei mit:
tar xvfz apache-druid-0.22.1-bin.tar.gz
Wechseln Sie in das neu erstellte Verzeichnis mit:
cd apache-druid-0.22.1
Starten Sie den Dienst mit:
./bin/start-micro-quickstart
Der Apache Druid-Dienst sollte problemlos gestartet werden. Beachten Sie, dass Sie Ihr Terminal nicht zurückerhalten, während der Dienst läuft, bis Sie ihn mit STRG + C abbrechen.
Zugriff auf die Apache Druid-Konsole
Öffnen Sie auf demselben Computer, auf dem Apache Druid ausgeführt wird, einen Webbrowser und verweisen Sie ihn auf http://localhost:8888 . Leider ist Apache Druid so eingerichtet, dass Sie es nicht von einem Remote-Rechner aus erreichen können, weshalb wir es auf einem Desktop-Rechner installieren.
Die Apache Druid-Konsole wird Sie begrüßen (Abbildung A ).
Abbildung A
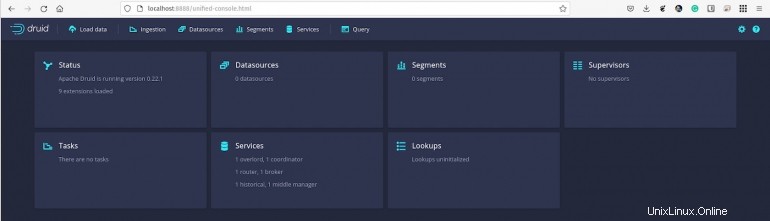
So laden Sie Daten
Wir werden ein vordefiniertes Datenbeispiel laden, das sich im Quickstart/Tutorial/Verzeichnis befindet. Das Beispiel heißt wikiticker-2015-09-12-sampled.json.gz.
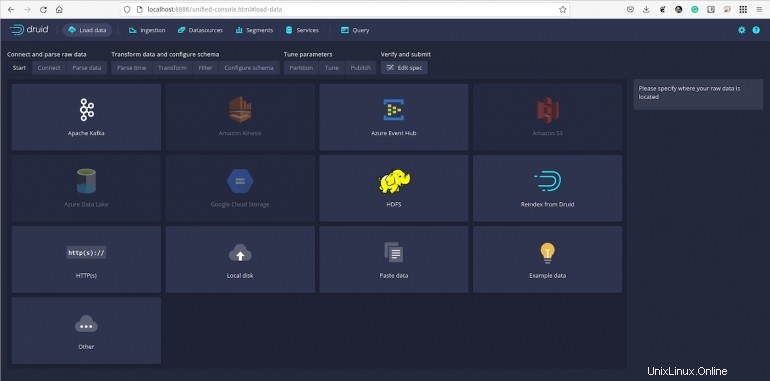
Abbildung B
Klicken Sie auf Daten verbinden (auf der rechten Seite des Fensters) und dann in der resultierenden Seitenleiste (Abbildung C ), geben Sie quickstart/tutorial ein als Basisverzeichnis und wikiticker-2015-09-12-sampled.json.gz im Abschnitt Dateifilter.
Abbildung C
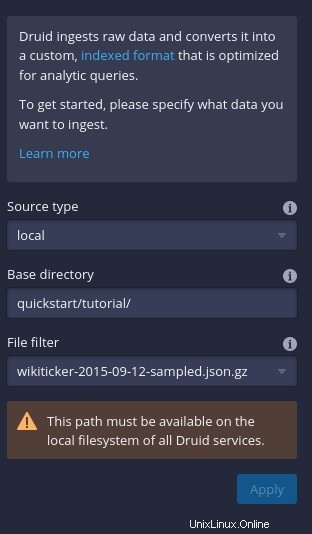
Klicken Sie auf Übernehmen und Sie sollten eine ziemlich große Datenmenge im Hauptfenster sehen (Abbildung D ).
Abbildung D
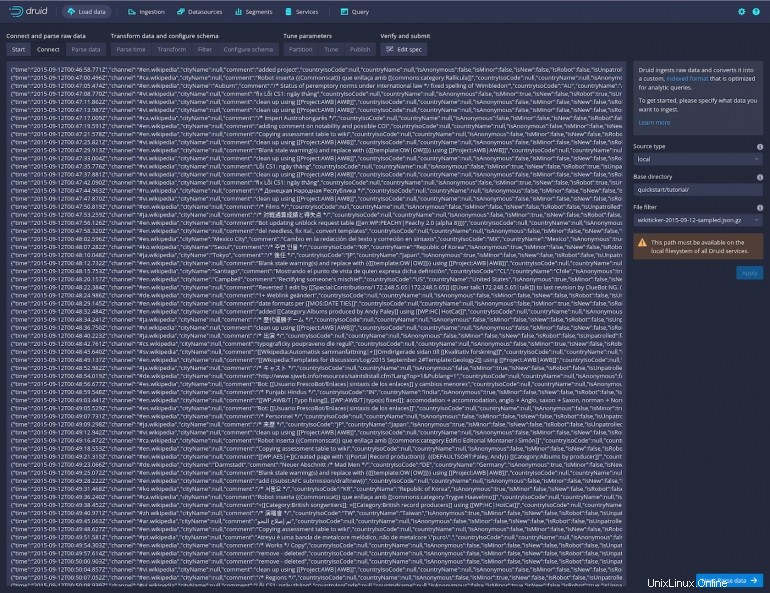
Klicken Sie unten rechts auf Weiter:Daten parsen und Sie erhalten eine Auflistung der Daten in einem besser lesbaren Format (Abbildung E ).
Abbildung E
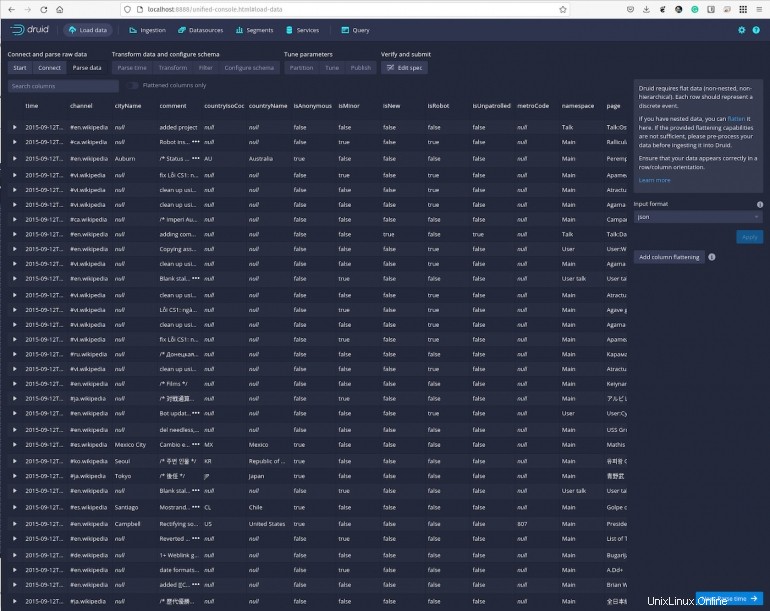
Klicken Sie auf Weiter:Parse Time und Sie können die Daten mit bestimmten Zeitstempeln anzeigen (Abbildung F ).
Abbildung F
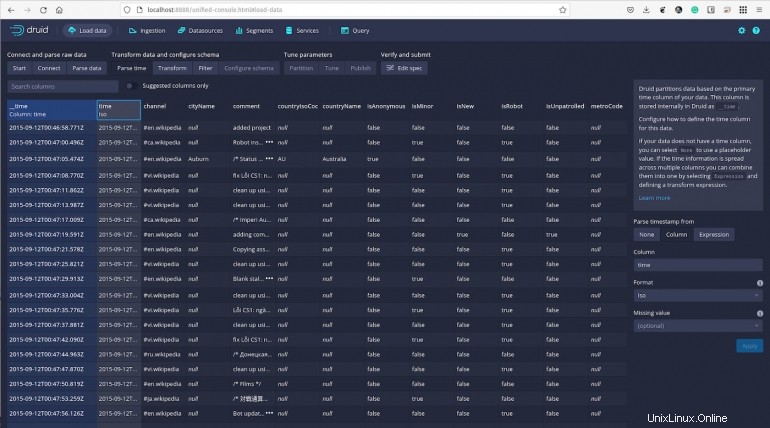
Klicken Sie auf Weiter:Transformieren und Sie können dann zeilenweise Transformationen der Spaltenwerte durchführen, um entweder neue Spalten zu erstellen oder bereits vorhandene zu ändern.
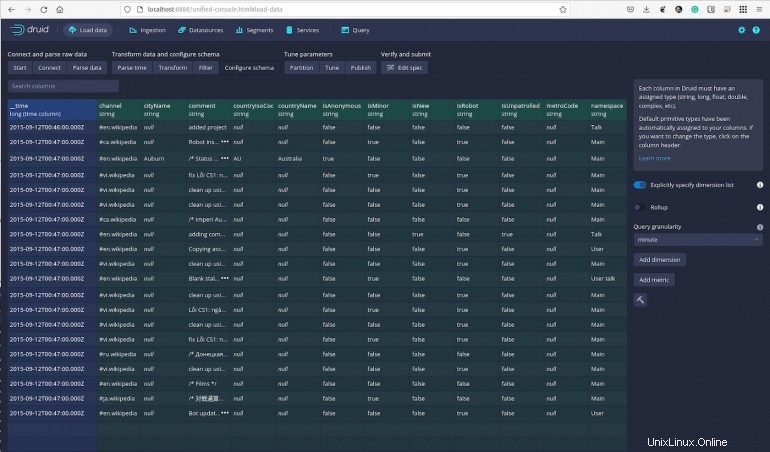
Klicken Sie sich weiter durch die Daten, und Sie können jederzeit Abfragen ausführen und Daten nach Bedarf filtern. Im Abschnitt Schema konfigurieren (Abbildung G ) können Sie sogar die Granularität Ihrer Abfragen festlegen und Dimensionen und Messwerte hinzufügen.
Abbildung G
Und das sind so ziemlich die Grundlagen von Apache Druid. Obwohl wir nur die Oberfläche dessen, was diese leistungsstarke Datenanalyseplattform leisten kann, überflogen haben, sollten Sie in der Lage sein, ein ziemlich gutes Gefühl dafür zu bekommen, wie sie funktioniert, indem Sie mit den Beispieldaten herumspielen.
Wenn Sie mit der Arbeit fertig sind, gehen Sie zurück zum Terminalfenster und stoppen Sie den Apache Druid-Dienst mit STRG + C.