Curl ist ein hervorragendes Tool zum Herunterladen von Dateien im Linux-Terminal.
Die übliche Syntax zum Herunterladen einer Datei mit demselben Namen wie die Originaldatei ist ziemlich einfach:
curl -O URL_of_the_fileDies funktioniert meistens. Sie werden jedoch feststellen, dass beim Herunterladen einer Datei von GitHub oder SourceForge manchmal nicht die richtige Datei abgerufen wird.
Zum Beispiel habe ich versucht, das Archinstall-Skript im tar gz-Format herunterzuladen. Die Dateien befinden sich auf der Release-Seite.
Wenn ich diesen Quellcode-Link in einem Browser öffne, bekomme ich den Quellcode im .tar.gz-Format.
Wenn ich jedoch das Terminal verwende, um dieselbe Datei mit dem curl-Befehl herunterzuladen, erhalte ich eine kleine Datei, die nicht im richtigen Archivformat vorliegt.
tar -zxvf v2.4.2.tar.gz
gzip: stdin: not in gzip format
tar: Child returned status 1
tar: Error is not recoverable: exiting now
Wenn ich den Dateibefehl ausführe, um den genauen Dateityp zu erfahren, sagt er mir, dass es sich um ein HTML-Dokument handelt.
file v2.4.2.tar.gz
v2.4.2.tar.gz: HTML document, ASCII text, with no line terminators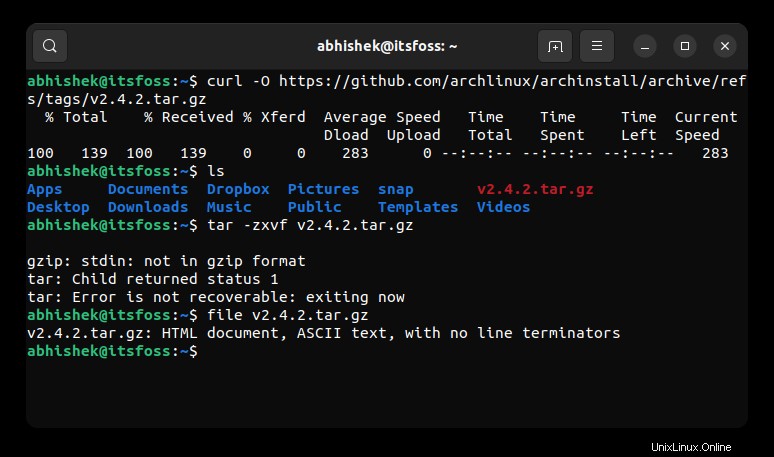
HTML-Dokument statt Archiv-Zip oder Tarball? Wo ist das Problem? Lassen Sie mich Ihnen die schnelle Lösung zeigen.
Richtiges Herunterladen der Archivdatei mit curl
Das Problem dabei ist, dass die URL, die Sie haben, auf die eigentliche Archivdatei umleitet. Dazu müssen Sie zusätzliche Optionen verwenden.
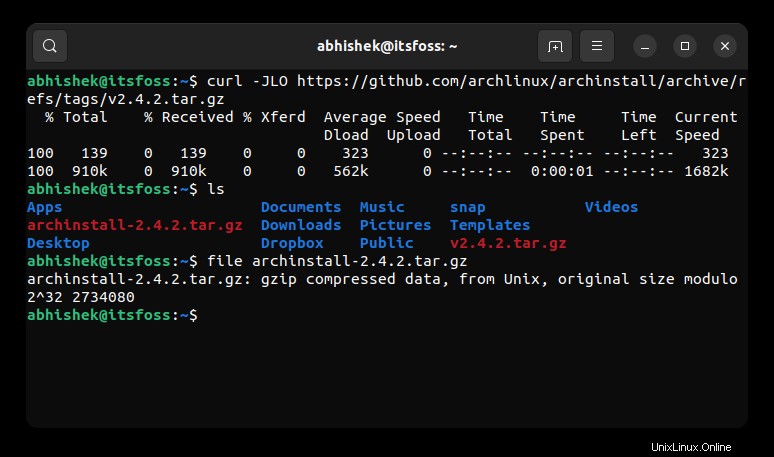
curl -JLO URL_of_the_fileDie Optionen können in beliebiger Reihenfolge sein. Es ist einfach einfacher, sich an J LO (Jennifer Lopez) zu erinnern.
Hier ist eine kurze Erklärung der Optionen basierend auf der Manpage des Curl-Befehls.
- J:Diese Option weist die Option -O, --remote-name an, den vom Server angegebenen Content-Disposition-Dateinamen zu verwenden, anstatt einen Dateinamen aus der URL zu extrahieren.
- L:Wenn der Server meldet, dass die angeforderte Seite an einen anderen Ort verschoben wurde (angezeigt durch einen Location:-Header und einen 3XX-Antwortcode), veranlasst diese Option curl, die Anforderung am neuen Ort zu wiederholen.
- O:Mit dieser Option müssen Sie den Ausgabedateinamen für den Download nicht angeben.
Wie Sie im Screenshot unten sehen können, konnte ich dieses Mal mit der Option curl -JLO die richtige Datei herunterladen.
Bonus-Tipp:Müssen Sie sich anmelden?
Dies funktioniert für die öffentlichen Dateien. Wenn Sie jedoch versuchen, Dateien von privaten Repositories oder GitLab herunterzuladen, wird möglicherweise eine Meldung über die Weiterleitung zur Anmeldeseite angezeigt.
<html><body>You are being <a href="https://gitlab.com/users/sign_in">redirected</a>.</body></html>
Geben Sie in solchen Fällen bitte das API-Token mit der Option -H an.
Ich hoffe, dieser kurze kleine Tipp hilft Ihnen dabei, Archivdateien mit Curl korrekt herunterzuladen. Lassen Sie mich wissen, wenn Sie immer noch Probleme mit Curl-Downloads haben.