Hier gibt es kein Problem mit Ungenauigkeit oder Zuverlässigkeit, Sie vergleichen nur zwei verschiedene Zahlen:logische Größe vs. physische Größe.
Hier ist die Illustration von Wikipedia für Dateien mit geringer Dichte:
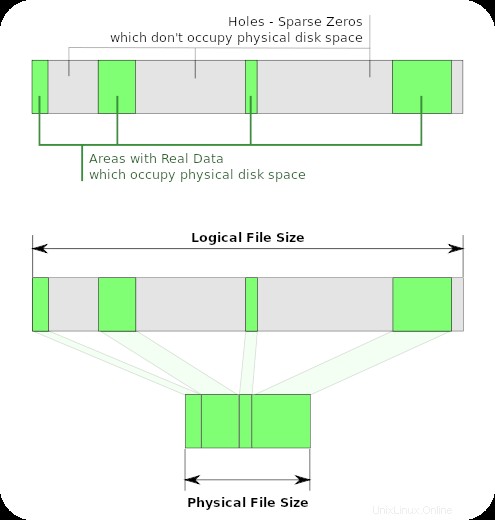
ls zeigt die grau+grünen Bereiche, die logische Länge der Datei. du (ohne --apparent-size ) zeigt nur die grünen Bereiche, da diese den Platz einnehmen.
Sie können eine Sparse-Datei mit dd count=0 bs=1M seek=100 of=myfile erstellen .
ls zeigt 100 MiB an, weil die Datei so lang ist:
$ ls -lh myfile
-rw-r----- 1 me me 100M Jul 15 10:57 myfile
du zeigt 0, weil ihm so viele Daten zugewiesen sind:
$ du myfile
0 myfile
ls -l --block-size=M
gibt Ihnen eine lange Formatliste (erforderlich, um die Dateigröße tatsächlich zu sehen) und rundet Dateigrößen auf den nächsten MiB auf .
Wenn Sie MB möchten (10^6 Byte) statt MiB (2^20 Byte) Einheiten, verwenden Sie --block-size=MB stattdessen.
Wenn Sie die M nicht möchten Suffix an die Dateigröße angehängt, können Sie so etwas wie --block-size=1M verwenden . Danke Stéphane Chazelas für diesen Vorschlag.
Dies ist in der Manpage für ls beschrieben; man ls und suchen Sie nach SIZE . Es erlaubt andere Einheiten als MB/MiB auch, und wie es aussieht (ich habe das nicht ausprobiert) auch beliebige Blockgrößen (so dass Sie die Dateigröße als Anzahl von 412-Byte-Blöcken sehen können, wenn Sie möchten).
Beachten Sie, dass --block-size parameter ist eine GNU-Erweiterung über dem ls der Open Group , daher funktioniert dies möglicherweise nicht, wenn Sie kein GNU-Userland haben (was bei den meisten Linux-Installationen der Fall ist). Das ls von GNU Coreutils 8.5 unterstützt --block-size wie oben beschrieben.
Es gibt verschiedene Begriffe der Dateigröße, wie in der Antwort dieses anderen Typen und der Wikipage-Abbildung zu Sparse-Dateien erläutert.
Möglicherweise möchten Sie jedoch sowohl die Befehle ls(1) als auch stat(1) verwenden.
Wenn Sie in C programmieren, sollten Sie die Systemaufrufe stat(2) &lseek(2) verwenden.
Siehe auch die Referenzen in dieser Antwort.