Wenn Sie unter Linux zwei Dateien mit ähnlichem Text vergleichen müssen, kann die Verwendung des diff-Befehls Ihre Aufgabe erheblich erleichtern. Der Befehl vergleicht zwei Dateien, um Änderungen vorzuschlagen, die die Dateien identisch machen würden. Großartig, um die zusätzliche geschweifte Klammer zu finden, die Ihren neu aktualisierten Code beschädigt hat.
Die Verwendung des diff-Befehls ist sehr einfach. Hier ist die Syntax:
diff [options] file1 file2Aber seine Ausgabe zu verstehen, ist eine andere Sache. Keine Sorge, ich erkläre die Ausgabe, damit Sie zwei Dateien vergleichen und den Unterschied zwischen ihnen verstehen können.
Diff-Befehl in Linux verstehen
Sie benötigen ein paar Dateien, um loszulegen. Ich habe mit einem Zufallswortgenerator eine Liste erstellt.
Ich habe die Liste zu zwei verschiedenen Dateien hinzugefügt und dann die Liste geändert durch:
- Listenreihenfolge ändern
- Buchstaben hinzufügen
- Fall wechseln
Ich habe diese ähnlichen Dateien als 1.txt und 2.txt gespeichert. So sehen sie aus, bevor Sie etwas tun.
Ich schlage vor, dass Sie beim Lesen dem Tutorial folgen, also erstellen Sie bitte neue Dateien und fügen Sie ihnen den folgenden Inhalt hinzu.
Inhalt von 1.txt :
Spinnennetz
Medaillon
Akustik
Erweiterung
aufnehmen
Inhalt von 2.txt:
Spinnennetz
MEDAILLON
Akustik
Aufzeichnungen
Erweiterung
Beispiel 1:Diff ohne Optionen
Mal sehen, was passiert, wenn Sie diff ausführen Befehl ohne Optionen.
christopher:~$ diff 1.txt 2.txt
2c2
< locket
---
> LOCKET
3a4
> records
5d5
< recordVerwirrt? Du bist nicht allein. Die Ausgabe ist nicht gerade menschenfreundlich. Um zu verstehen, was vor sich geht, müssen Sie mehr darüber wissen, wie diff funktioniert.
Es kann hilfreich sein zu wissen, dass nach Abschluss der Analyse file2 [in der Syntax] wird als Referenzdokument behandelt, mit dem Sie versuchen, eine Übereinstimmung herzustellen. Man könnte also sagen, dass diff so funktioniert:
diff <file_to_edit> <file_as_reference>Das bedeutet auch, dass Sie abhängig von der Reihenfolge, in der Sie die Dateinamen platzieren, unterschiedliche Ausgaben erhalten.
Auf die Reihenfolge kommt es an
Ein Beispiel dafür, wie sich die Ausgabe je nach Dateireihenfolge unterscheidet:
christopher:~$ diff 1.txt 2.txt
2c2
< locket
---
> LOCKET
3a4
> records
5d5
< record
christopher:~$ diff 2.txt 1.txt
2c2
< LOCKET
---
> locket
4d3
< records
5a5
> recordWichtige Symbole in der diff-Befehlsausgabe
Anhand der folgenden Tabelle als Referenz können Sie besser verstehen, was in Ihrem Terminal vor sich geht.
| Symbol | Bedeutung |
|---|---|
| A | Hinzufügen |
| C | Ändern |
| D | Löschen |
| # | Zeilennummern |
| – – – | Trennt Dateien in der Ausgabe |
| < | Datei 1 |
| > | Datei 2 |
Schauen wir uns noch einmal die Ausgabe des diff-Befehls an:
christopher:~$ diff 1.txt 2.txt
2c2
< locket
---
> LOCKET
3a4
> records
5d5
< recordErklärung der diff-Befehlsausgabe
Sehen wir uns den ersten Unterschied in der Ausgabe an:
| Ausgabezeile | Erklärung |
|---|---|
| 2c2 | Zeile 2 von Datei 1, CHANGE mit Zeile 2 von Datei 2. |
| Ändern Sie „locket“ in „LOCKET“, um mit Datei 2.txt übereinzustimmen |
Schauen wir uns den nächsten Teil der Ausgabe an:
| Ausgabezeile | Erklärung |
|---|---|
| 3a4 | Fügen Sie nach Zeile 3 von Datei 1 Zeile 4 von Datei 2 hinzu. |
| > Datensätze | Das bedeutet, „Einträge“ hinzuzufügen, um die vierte Zeile in Datei 1 zu erstellen. Damit Datei 1.txt mit Datei 2.txt übereinstimmt |
Ähnlich:
| Ausgabezeile | Erklärung |
|---|---|
5d5 | Löschen Sie den Text „record“ aus der 5. Zeile von Datei 1. Damit Datei 1.txt mit Datei 2.txt übereinstimmt | |
In den Befehl ist keine Rechtschreibprüfung oder Wörterbuchfunktion integriert. Es erkennt „record“ und „records“ nicht als verwandt. Sein einziges Ziel ist es, die beiden Dateien perfekt aufeinander abzustimmen.
Wenn man sich die Ausgabe ansieht, ist es immer noch ziemlich schwer zu übersetzen. Es ist unwahrscheinlich, dass Sie viel Zeit sparen würden.
Glücklicherweise gibt es Optionen, die hinzugefügt werden können, um die Dinge für Menschen lesbarer zu machen. Sehen wir uns ein paar verschiedene Beispiele an, die dieselbe Liste verwenden.
Beispiel 2:Vergleich im „Copied“-Kontext mit -c
Die Kontextoption bietet eine visuellere Darstellung der standardmäßig angezeigten programmatischeren Informationen. Fahren wir mit unserem Beispieltext fort.
Wichtigere Symbole in der diff-Befehlsausgabe
| Symbol | Bedeutung |
|---|---|
| + | Hinzufügen |
| ! | Ändern |
| – | Löschen |
| *** | Datei 1 |
| – – – | Datei 2 |
christopher:~$ diff -c 1.txt 2.txt
*** 1.txt 2019-10-20 12:05:09.244673327 -0400
--- 2.txt 2019-10-20 12:11More:31.382547316 -0400
***************
*** 1,5 ****
cobweb
! locket
acoustics
expansion
- record
--- 1,5 ----
cobweb
! LOCKET
acoustics
+ records
expansionEs ist viel einfacher zu verstehen, wenn Sie die Informationen auf diese Weise sehen. Anstelle der alphanumerischen Ausgabe hilft Ihnen der neue Symbolsatz, die Unterschiede zwischen den beiden Dateien schnell zu erkennen.
Die Ausgabe zeigt zuerst die erste Datei, d.h. 1.txt und ihre Zeile von 1 bis 5. Es besagt, dass es eine leichte Änderung in (einem Teil von) Zeile 2 der Datei 1.txt und (einem Teil von) Zeile 2 von Datei 2 gibt .txt.
Es zeigt auch an, dass Zeile Nummer 5 von Datei 1 in der zweiten Datei gelöscht wurde (-).
— 1,5 —- gibt den Beginn der zweiten Datei an und besagt, dass Zeile 2 gegenüber Zeile 2 von Datei 1 geringfügig geändert wurde. Es zeigt auch an, dass Zeile 4 in der zweiten Datei hinzugefügt wurde (+) und es keine Entsprechung gibt Zeile in Datei 1.
Beispiel 3:Diff im „Unified“-Kontext mit -u
Diese Option bietet eine ähnliche Ausgabe wie das kopierte Kontextformat. Anstatt die beiden Dateien separat anzuzeigen, werden sie zusammengeführt.
christopher:~$ diff 1.txt 2.txt -u
--- 1.txt 2019-10-20 12:05:09.244673327 -0400
+++ 2.txt 2019-10-20 12:11:31.382547316 -0400
@@ -1,5 +1,5 @@
cobweb
-locket
+LOCKET
acoustics
+records
expansion
-record
Wie Sie sehen können, verwendet es die gleichen Symbole wie zuvor, aber anstelle des Änderungssymbols schlägt es Änderungen vor, die mit leicht lesbarem + vorgenommen werden sollen oder - Symbole. Hier empfiehlt es sich, Zeile 2 aus 1.txt zu entfernen und ersetzen Sie sie durch Zeile 2 aus 2.txt .
Für die Zukunft wird außerdem vorgeschlagen, dass Sie Datensätze hinzufügen hinter Zeile mit Akustik und Zeile record löschen nach der Zeile mit der Erweiterung.
All diese Änderungen werden für die erste Datei im diff-Befehl vorgeschlagen. Dies ist ein weiteres Szenario, bei dem es hilfreich ist, sich daran zu erinnern, dass das Diff-Programm die zweite aufgeführte Datei als „Original“ oder Grundlage für Korrekturen verwendet.
Um eine solche Liste zu vergleichen, finde ich persönlich diese Methode am einfachsten zu verwenden. Es gibt Ihnen eine klare Visualisierung des Textes, der geändert werden muss, um die Dateien identisch zu machen.
Beispiel 4:Vergleiche, aber ignoriere Fälle mit -i
Suchen mit Berücksichtigung der Groß- und Kleinschreibung sind die Standardeinstellung für diff, aber Sie können dies deaktivieren. Sehen wir uns an, was passiert, wenn Sie das tun.
christopher:~$ diff 1.txt 2.txt -i
3a4
> records
5d5
< recordWie Sie sehen können, werden „Medaillon“ und „LOCKET“ nicht mehr als vorgeschlagene Änderungen aufgeführt.
Beispiel 5:Diff mit –color
Sie können --color verwenden , um Änderungen in der Ausgabe des diff-Befehls hervorzuheben. Wenn der Befehl ausgeführt wird, werden Abschnitte der Ausgabe in verschiedenen Farben aus der Terminal-Palette gedruckt.
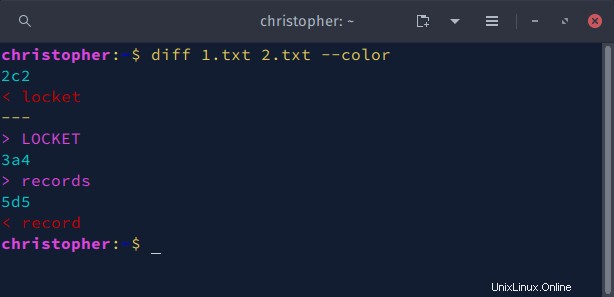
Beispiel 6:Schnellanalyse von Dateien mit den diff-Befehlsoptionen -s und -q
Es gibt ein paar einfache Möglichkeiten, um zu überprüfen, ob Dateien identisch sind oder nicht. Wenn Sie -s verwenden es wird Ihnen sagen, dass die Dateien identisch sind, oder es wird wie gewohnt diff ausgeführt.
Mit -q wird Ihnen nur sagen, dass die Dateien „unterschiedlich“ sind. Wenn dies nicht der Fall ist, erhalten Sie keine Ausgabe.
christopher:~$ diff 1.txt 1.txt -s
Files 1.txt and 1.txt are identical
christopher:~$ diff 1.txt 2.txt -q
Files 1.txt and 2.txt differBonus-Tipp:Verwendung des diff-Befehls in Linux mit großen Textdateien
Möglicherweise vergleichen Sie nicht immer so einfache Informationen. Möglicherweise müssen Sie große Textdateien durchsuchen und Unterschiede finden. Ich werde einige Methoden zur Behandlung dieser Art von Problemen erläutern.
Für dieses Beispiel habe ich zwei Dateien mit großen Textblöcken (lorem ipsum) erstellt. Jede Zeile hat Hunderte von Spalten. Dies erschwerte offensichtlich den Linienvergleich.
Wenn diff für eine Datei wie diese ausgeführt wird, erzeugt die Ausgabe riesige Textblöcke und die Symbole sind selbst mit Tools wie der kontextbezogenen Ausgabe schwer zu erkennen.
Um Platz zu sparen, habe ich einen Screenshot der Ausgabe gemacht, den Sie sich ansehen können.
Nicht sehr hilfreich, oder?
Sie können einige der gleichen Konzepte verwenden, um diese Art von Dateien zu analysieren. Sie werden nicht gut funktionieren, wenn die Datei nicht richtig formatiert ist. Einige große Textblöcke haben keine Zeilenumbrüche. Sie sind wahrscheinlich auf eine Datei wie diese gestoßen, bei der Sie „Wortumbruch“ aktivieren mussten, damit der gesamte Text innerhalb des zugewiesenen Bereichs angezeigt wird, ohne eine Bildlaufleiste zu verwenden. Der Grund dafür ist, dass einige Textformate Zeilenumbrüche nicht automatisch erstellen. So erhalten Sie die großen Textblöcke auf nur 2-3 Zeilen. Dafür gibt es eine ziemlich einfache Lösung.
Verwenden Sie fold, um Text in Zeilen umzubrechen
Dies ist das Linux-Handbuch, also haben wir natürlich eine Lösung für Sie und können ein Mini-Tutorial hineinstopfen. Hier finden Sie eine großartige Beschreibung zu Fold (Unix) und fmt (GNU). Ich gebe ein kurzes Beispiel, das jedoch ziemlich selbsterklärend sein sollte, um uns voranzubringen.
Der fold-Befehl wird verwendet, um Zeilen mit der Anzahl der Spalten zu brechen. Es kann angepasst werden, um Ihnen Optionen zu geben, wie diese neuen Zeilenumbrüche implementiert werden.
In diesem Beispiel werden Sie die Datei in eine standardisierte Breite aufteilen und das -s verwenden Möglichkeit. Dies weist das Programm an, NUR dort zu unterbrechen, wo es Leerzeichen gibt, nicht mitten im Text.
Verwenden Sie fold, um schnell Zeilenumbrüche einzufügen
fold -w 80 -s lorem.txt > lorem.txt
fold -w 80 -s lorem2.txt > lorem2.txtDa beide Dateien in 31 statt in 3 Zeilen aufgeteilt sind, können Sie sie viel effektiver vergleichen. Hier ist ein Beispiel für Ihre Ausgabe mit dem einheitlichen Kontextfilter.
christopher:~$ diff lorem.txt 2lorem.txt -u
--- lorem.txt 2019-10-27 09:39:07.298691695 -0400
+++ 2lorem.txt 2019-10-27 09:39:08.370704501 -0400
@@ -1,10 +1,10 @@
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Vivamus in tincidunt
sapien. Maecenas sagittis ex risus, in vehicula turpis imperdiet sed. Phasellus
placerat posuere maximus. In hac habitasse platea dictumst. Ut vel tristique
-eros, sit amet sodales nibh. Maecenas non nibh a nisi porttitor porta.
+eros, sit amet sodales nibh. Maecenas non nibh a nisi porttitor PORTA.
Suspendisse at mauris vitae sapien euismod tincidunt. Sed placerat finibus
blandit. Duis ornare ante at ipsum accumsan, nec bibendum nibh tincidunt.
-Nullam ut rhoncus risus. Phasellus est ex, tristique et semper eu,
+Nullam ut rhoncus risus. Phasellus est ex, tristique et semper eu, facilisis
vitae enim. Nam condimentum, purus nec semper efficitur, nisi quam vehicula
sem, eget finibus diam ipsum suscipit velit.
@@ -21,7 +21,7 @@
Maecenas lacinia cursus tristique. Nulla a hendrerit orci. Donec lobortis nisi
sed ante euismod lobortis. Nullam sit amet est nec nunc porttitor sollicitudin
-a ut orci. Ut euismod, ex at venenatis mattis, neque massa dignissim QUAM, at
+a ut orci. Ut euismod, ex at venenatis mattis, neque massa dignissim quam, at
interdum mi metus vel tellus. Fusce nec dui a risus posuere mattis at eu orci.
Proin purus sem, finibus eget viverra vel, porta pulvinar ex. In hac habitasse
platea dictumst. Nunc faucibus leo nec tristique porta. Phasellus luctus ipsumDiff mit –minimaler Ausgabe verwenden
Mit --minimal können Sie dies etwas lesbarer machen Schild. Dadurch werden größere Textdateien etwas besser lesbar. Schauen wir uns die Ausgabe an.
christopher:~$ diff lorem.txt 2lorem.txt --minimal
4c4
< eros, sit amet sodales nibh. Maecenas non nibh a nisi porttitor porta.
---
> eros, sit amet sodales nibh. Maecenas non nibh a nisi porttitor PORTA.
7c7
< Nullam ut rhoncus risus. Phasellus est ex, tristique et semper eu,
---
> Nullam ut rhoncus risus. Phasellus est ex, tristique et semper eu, facilisis
24c24
< a ut orci. Ut euismod, ex at venenatis mattis, neque massa dignissim QUAM, at
---
> a ut orci. Ut euismod, ex at venenatis mattis, neque massa dignissim quam, at Sie können jeden dieser Tipps kombinieren oder einige der anderen Optionen verwenden, die auf den man-Seiten von diff aufgeführt sind. Dies ist ein leistungsstarkes und benutzerfreundliches Software-Dienstprogramm.
Ich hoffe, Sie fanden diesen Artikel nützlich. Wenn Sie einen Tipp haben, vergessen Sie nicht, uns einen Kommentar zu hinterlassen und uns davon zu erzählen.