Hadoop hat zwei Kernkomponenten, nämlich HDFS und GARN . HDFS dient zum Speichern der Daten , GARN dient der Verarbeitung der Daten . HDFS ist Hadoop Distributed File System , es hat Namenode als Master Service und Datenknoten als Sklavendienst .
Namensknoten ist die kritische Komponente von Hadoop das die Metadaten von Daten speichert, die in HDFS gespeichert sind . Wenn der Namenode ausfällt, ist der gesamte Cluster nicht mehr zugänglich, es ist der Single Point of Failure (SPOF ). Die Produktionsumgebung wird also über Namenode High Availability verfügen um den Produktionsausfall zu vermeiden, wenn ein Namenode aus verschiedenen Gründen wie Maschinenabsturz, geplante Wartungsaktivitäten usw. ausfällt.
Hadoop 2.x bietet die Möglichkeit, zwei Namenodes zu haben , einer wird Aktiver Namenode sein und ein weiterer wird Standby Namenode sein .
- Aktiver Namenode – Es verwaltet alle Client-Operationen.
- Standby-Namenode – Es ist redundant zu Active Namenode . Wenn Active NN geht aus, dann Standby NN übernimmt die gesamte Verantwortung von Active NN .
Aktivieren von Namenode High Availability erfordert Tierpfleger was für automatisches Failover obligatorisch ist. ZKFC (Zookeeper-Failover-Controller ) ist ein Tierpfleger Client, der verwendet wird, um den Status von Namenode zu verwalten .
Anforderungen
- Best Practices für die Bereitstellung von Hadoop Server auf CentOS/RHEL 7 – Teil 1
- Einrichten von Hadoop-Voraussetzungen und Sicherheitshärtung – Teil 2
- So installieren und konfigurieren Sie den Cloudera Manager auf CentOS/RHEL 7 – Teil 3
- Installieren von CDH und Konfigurieren von Dienstplatzierungen unter CentOS/RHEL 7 – Teil 4
In diesem Artikel werden wir Namenode High Availability aktivieren im Cloudera Manager .
Schritt 1:Installation von Zookeeper
1. Melden Sie sich bei Cloudera Manager an .
http://Your-IP:7180/cmf/home
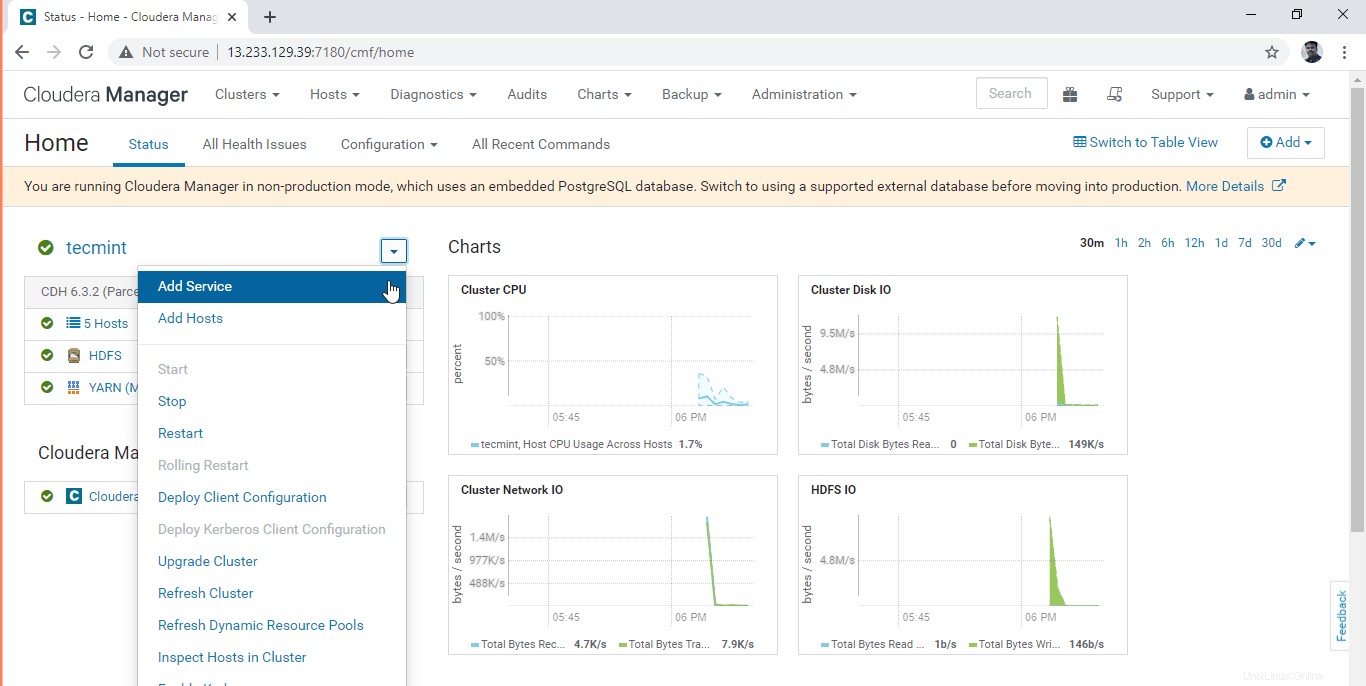
2. Im Cluster (tecmint ) Aktionsaufforderung, wählen Sie „Dienst hinzufügen “.
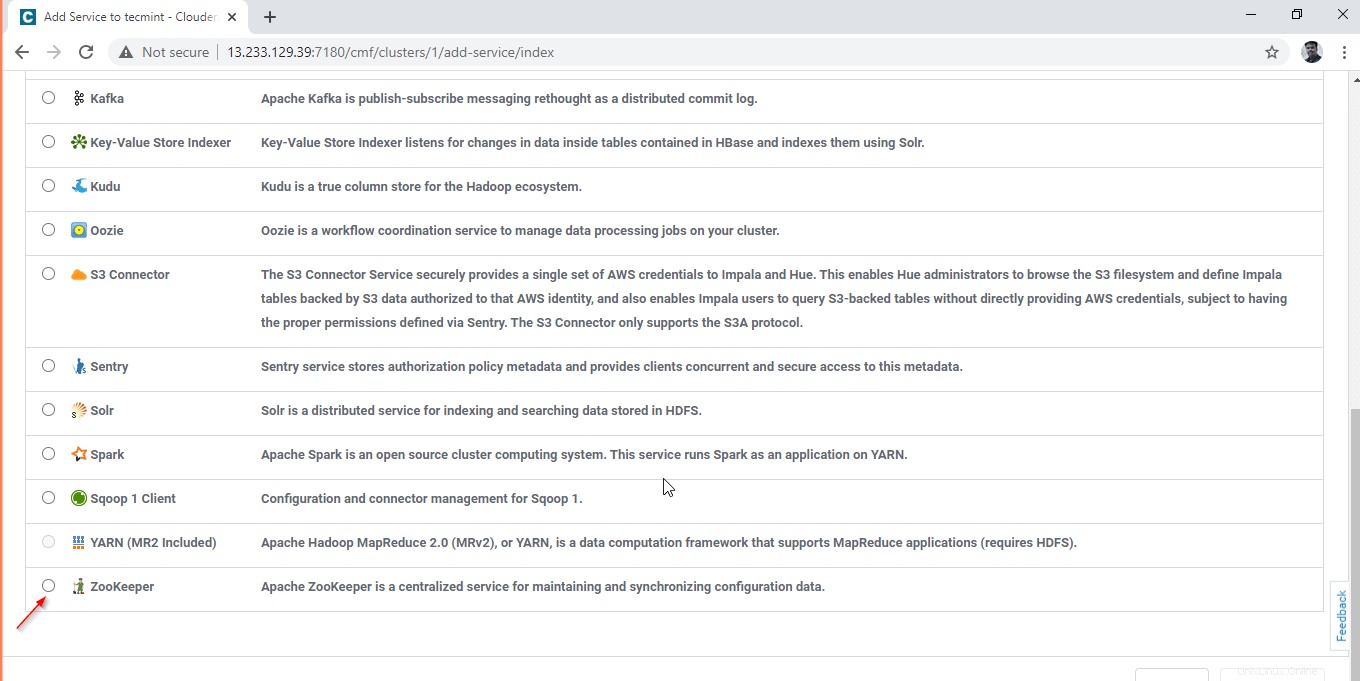
3. Wählen Sie den Dienst „Zookeeper“ aus “.
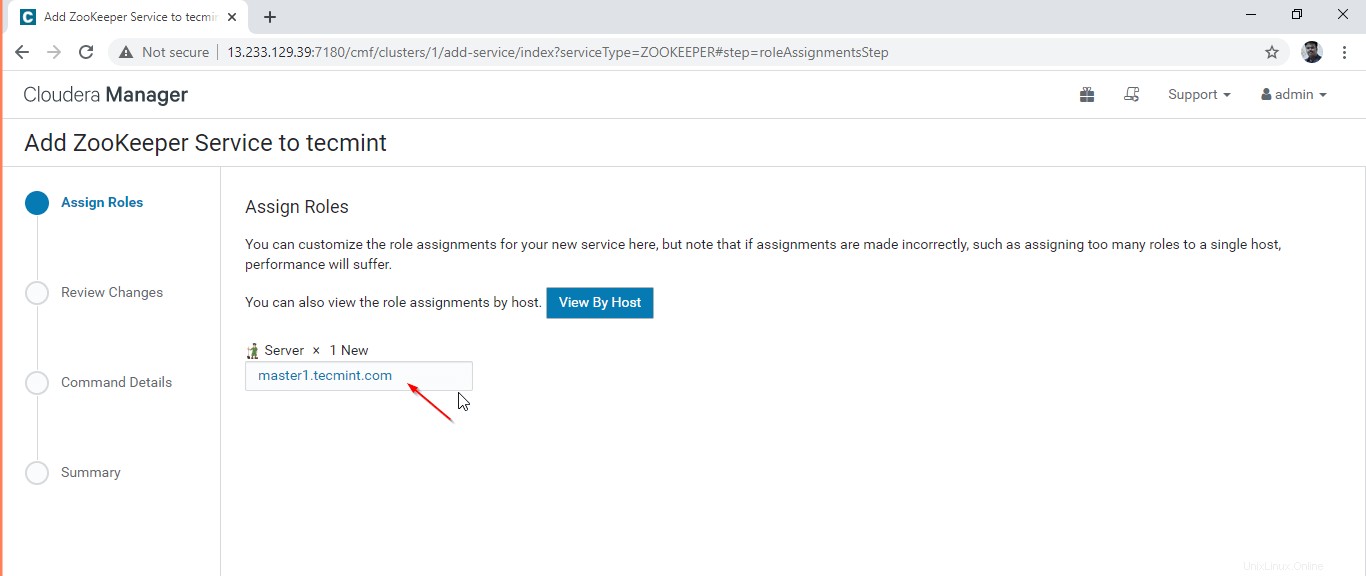
4. Wählen Sie die Server aus, auf denen wir Zookeeper haben werden installiert.
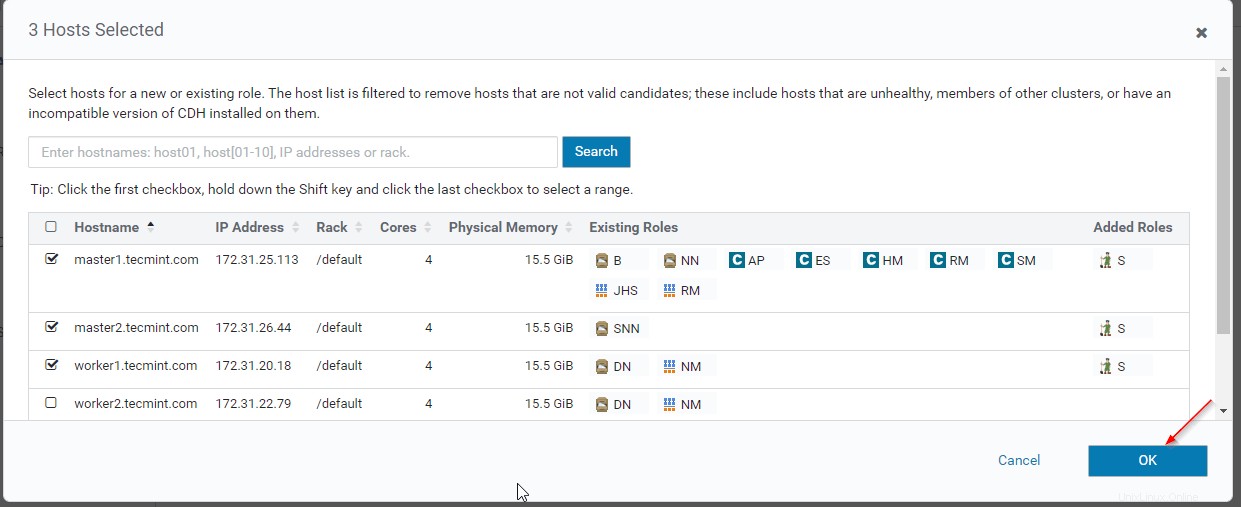
5. Wir werden 3 Tierpfleger haben Tierpflegerkollegium zu bilden . Wählen Sie die Server wie unten beschrieben aus.
6. Konfigurieren Sie den Zookeeper Eigenschaften, hier haben wir die Standardeigenschaften. In Echtzeit müssen Sie separate Verzeichnisse/Einhängepunkte zum Speichern von Zookeeper haben Daten. In Teil-1 haben wir die Speicherkonfiguration für jeden Dienst erläutert. Klicken Sie auf „weiter“. ’, um fortzufahren.
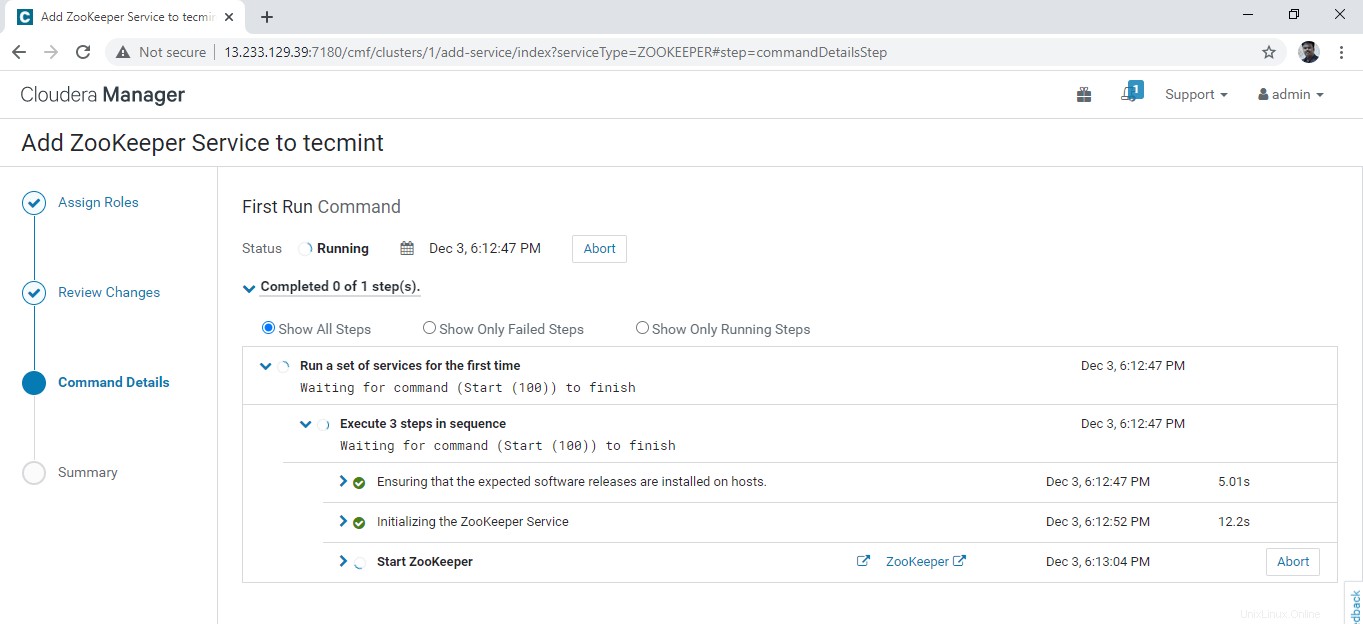
7. Die Installation beginnt, sobald Zookeeper installiert ist Wird gestartet. Sie können die Hintergrundvorgänge hier anzeigen.
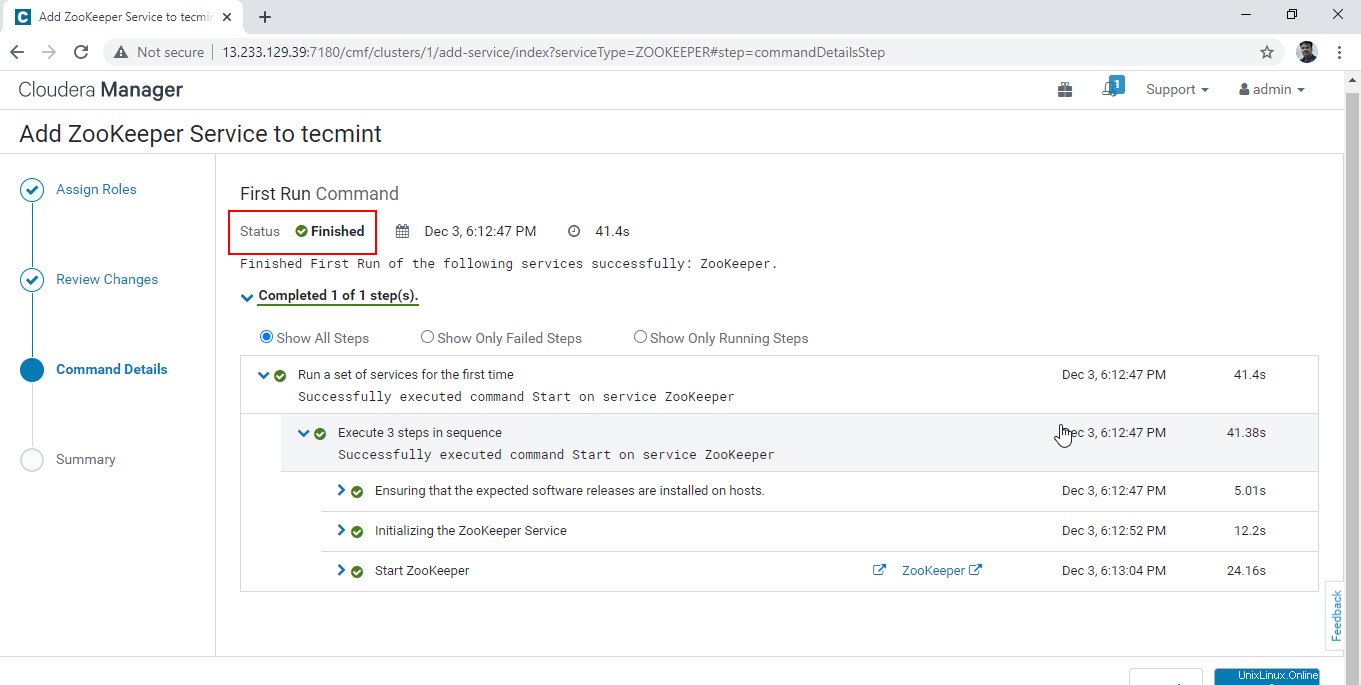
8. Nach erfolgreichem Abschluss des obigen Schritts lautet der Status „Fertig ’.
9. Nun, Tierpfleger wurde erfolgreich installiert und konfiguriert. Klicken Sie auf „Fertig stellen ’.
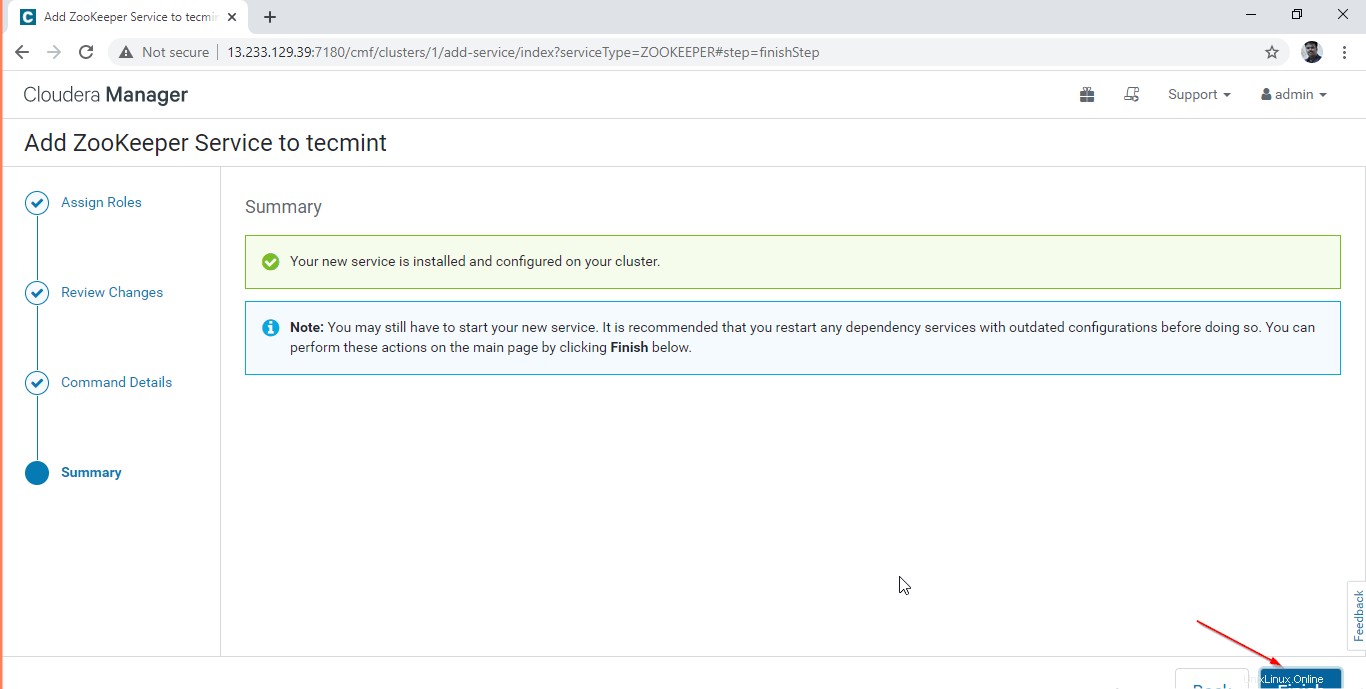
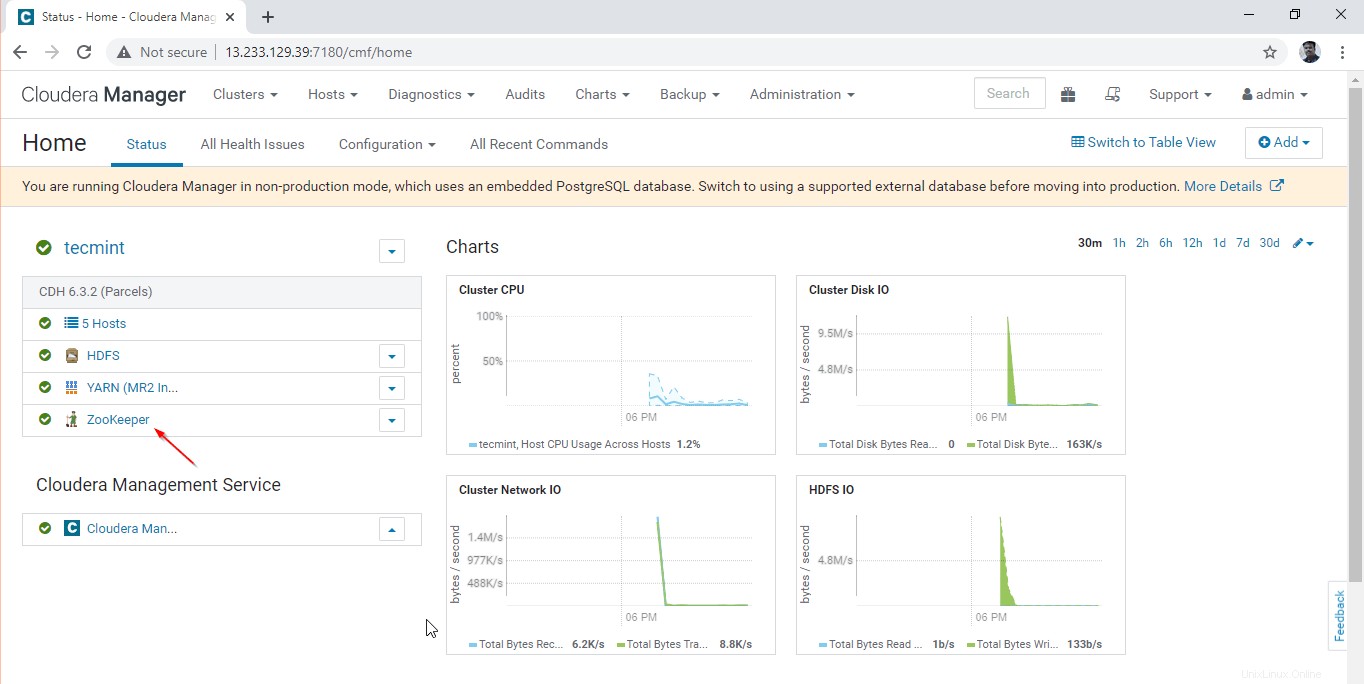
10. Sie können den Tierpfleger anzeigen Dienst auf dem Cloudera Manager Dashboard.
Schritt 2:Hochverfügbarkeit von Namenode aktivieren
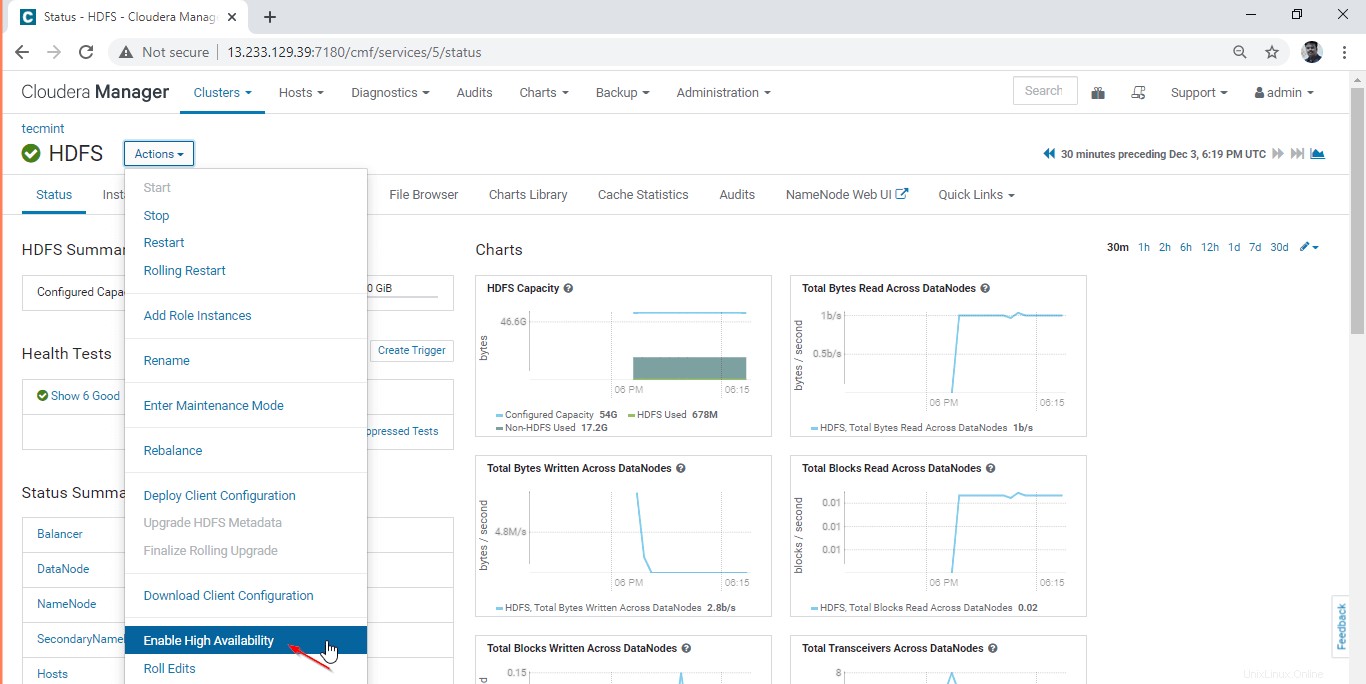
11. Gehen Sie zu Cloudera Manager –> HDFS –> Aktionen –> Hochverfügbarkeit aktivieren .
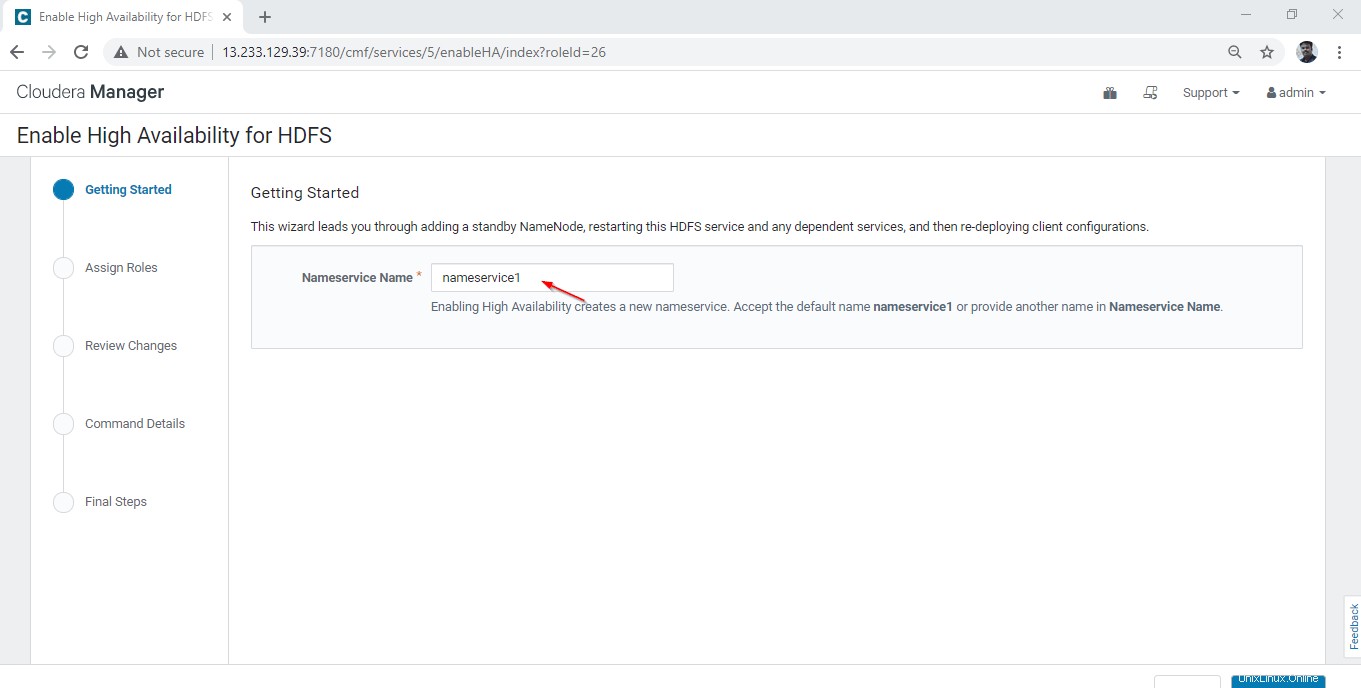
12. Geben Sie den Nameservice-Namen ein als „nameservice1 ” – Dies ist ein gemeinsamer Namespace für aktive und Standby-Namenode.
13. Wählen Sie den Zweiten Namensknoten aus wo wir den Standby Namenode haben werden .
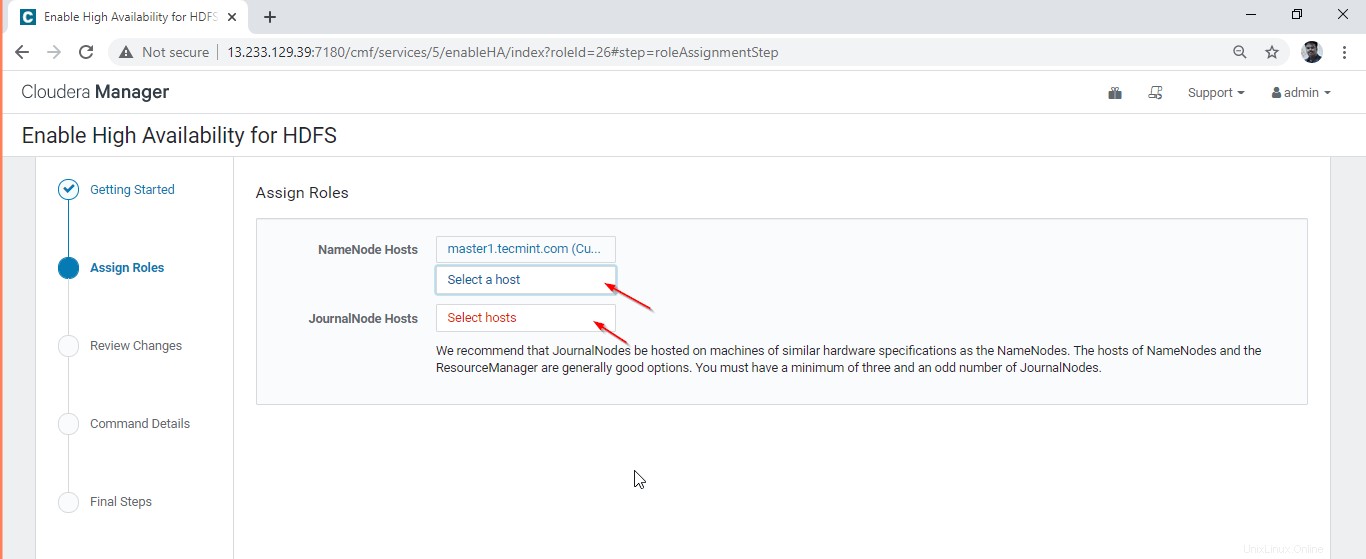
14. Hier wählen wir master2.tecmint.com aus für Standby Namenode .
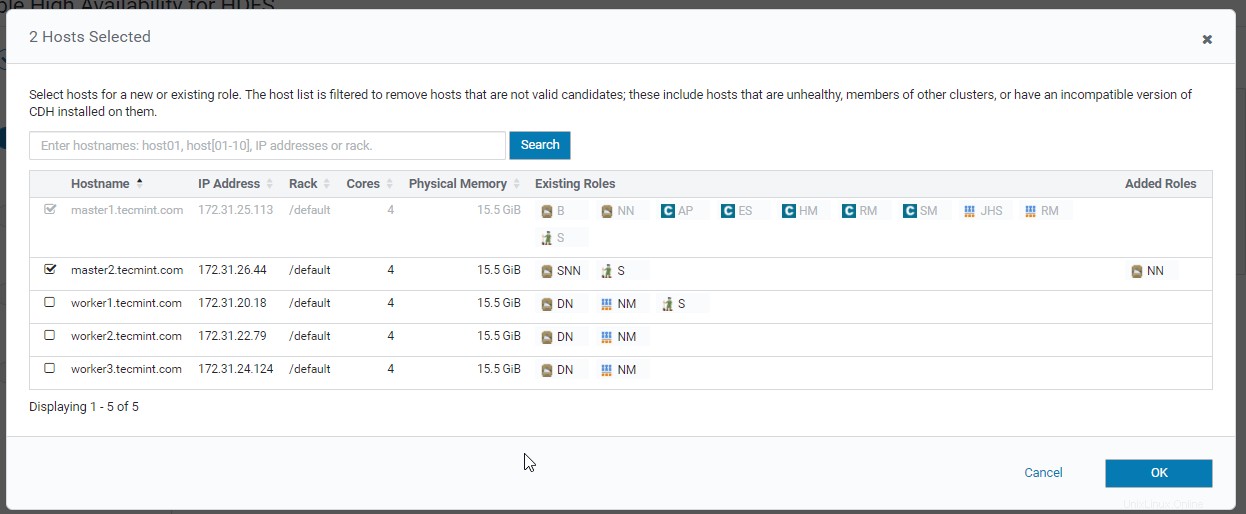
15. Wählen Sie das Journal aus Knoten, dies sind obligatorische Dienste zum Synchronisieren von Aktiv und Standby Namenode .
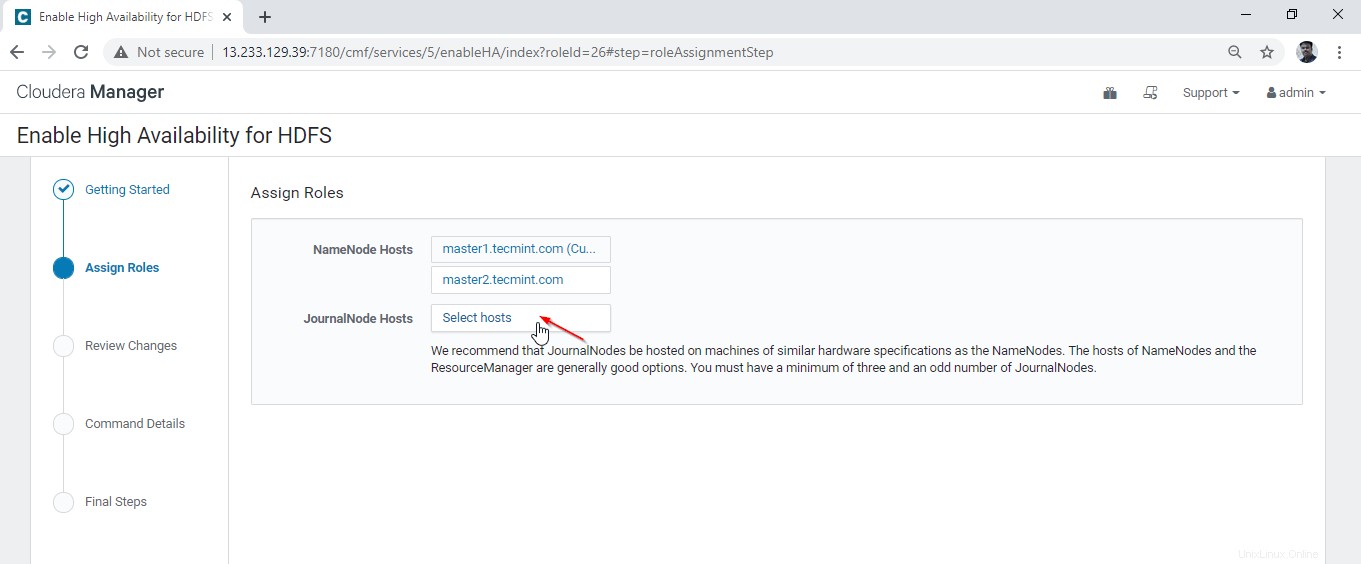
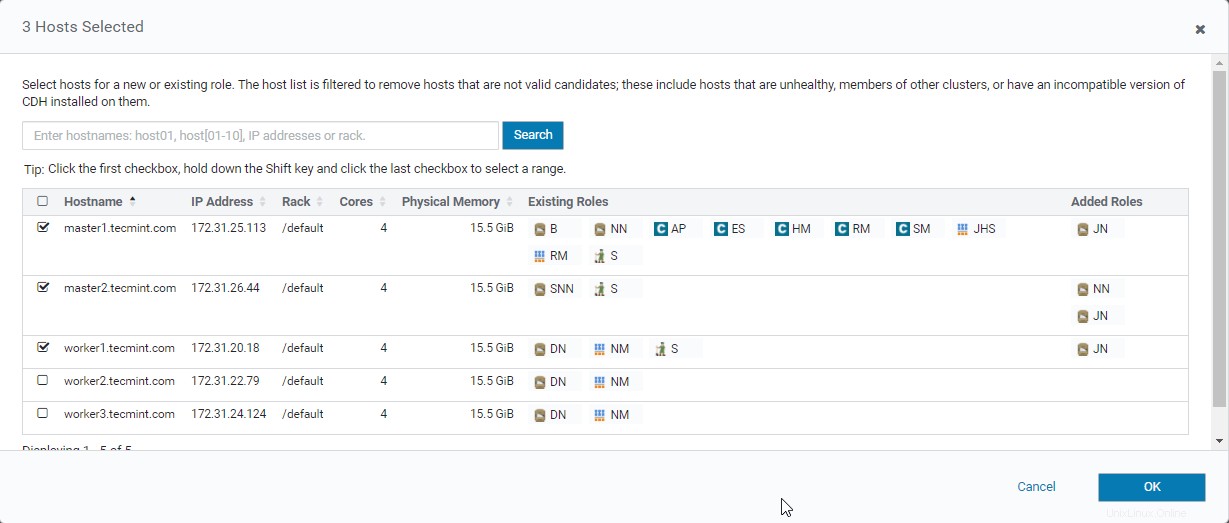
16. Wir machen Quorum Journal indem Sie das Tagebuch platzieren Knoten in 3 Servern wie unten erwähnt. Wählen Sie 3 Server aus und klicken Sie auf „OK“.
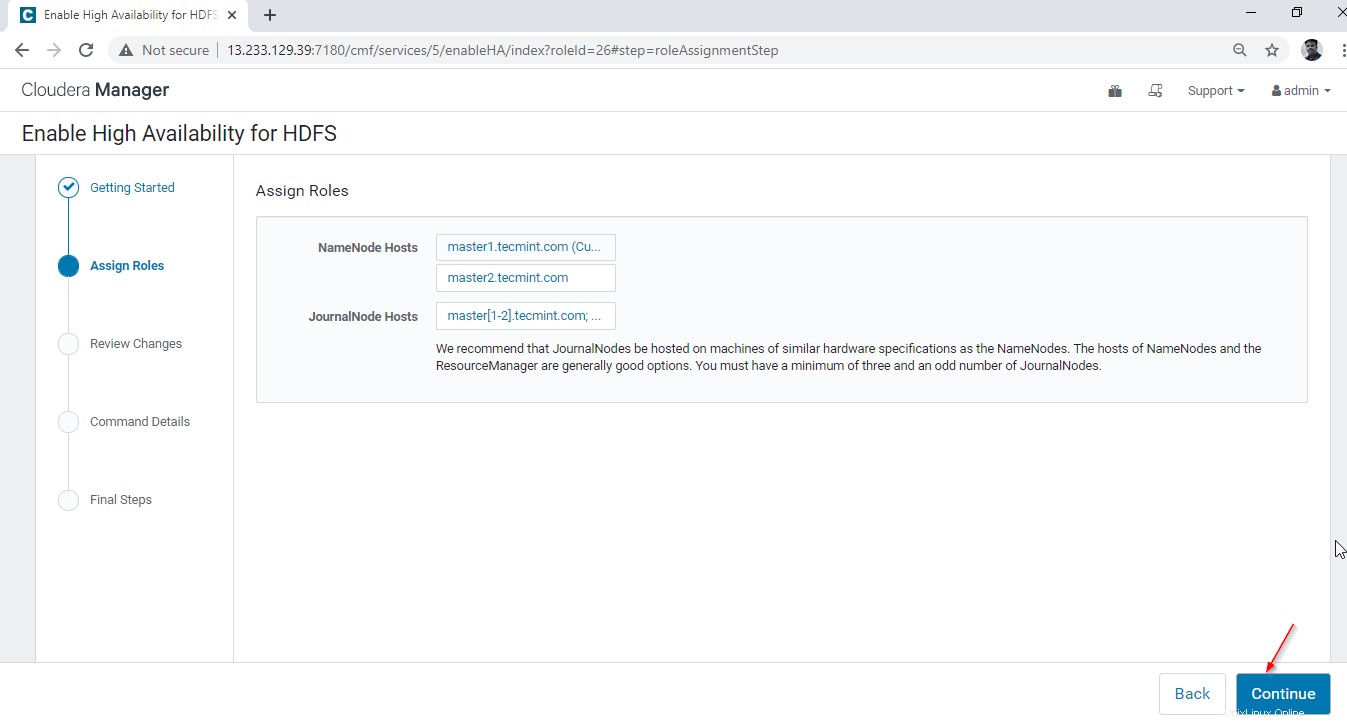
17. Klicken Sie auf „Weiter“. ’, um fortzufahren.
18. Geben Sie den Journalknoten ein Verzeichnispfad. Wir müssen nur den Pfad angeben, während die Installation dieses Verzeichnis automatisch vom Dienst selbst erstellt wird. Wir erwähnen als ‘/jn’ . Klicken Sie auf „Weiter“. ’, um fortzufahren.
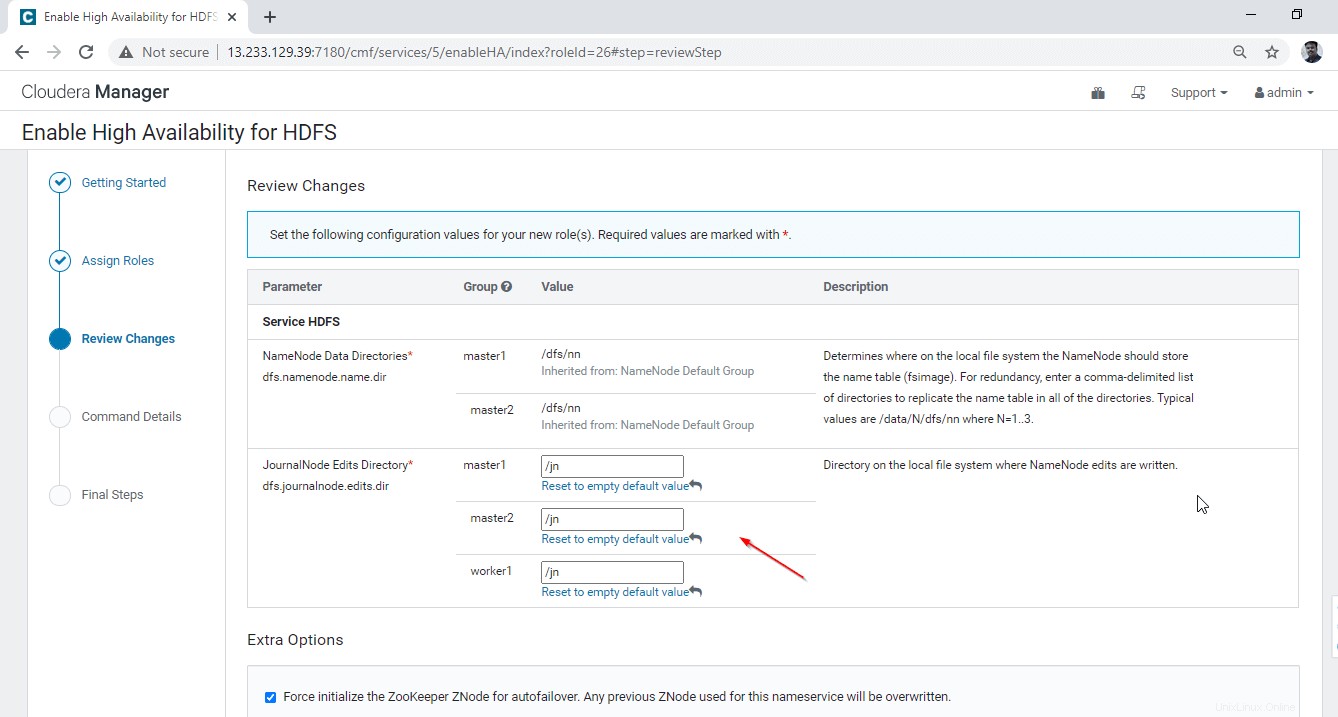
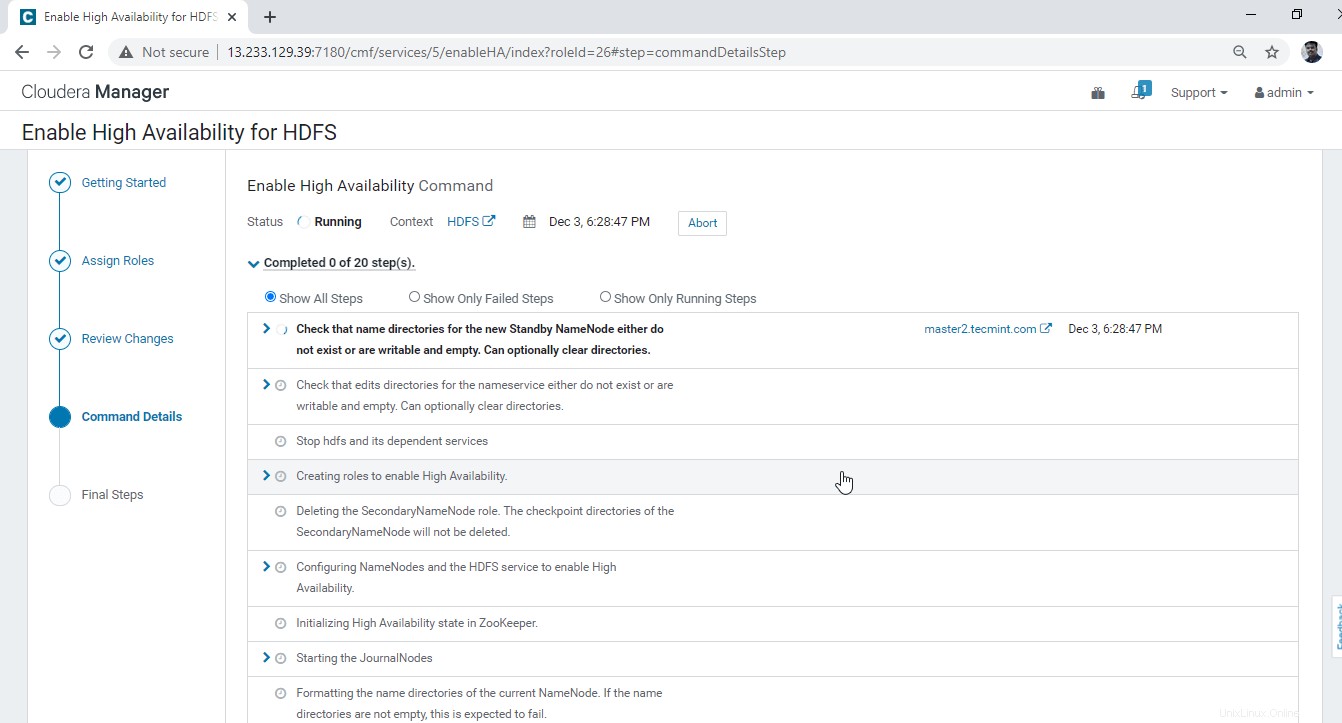
19. Es beginnt damit, die Hochverfügbarkeit zu aktivieren .
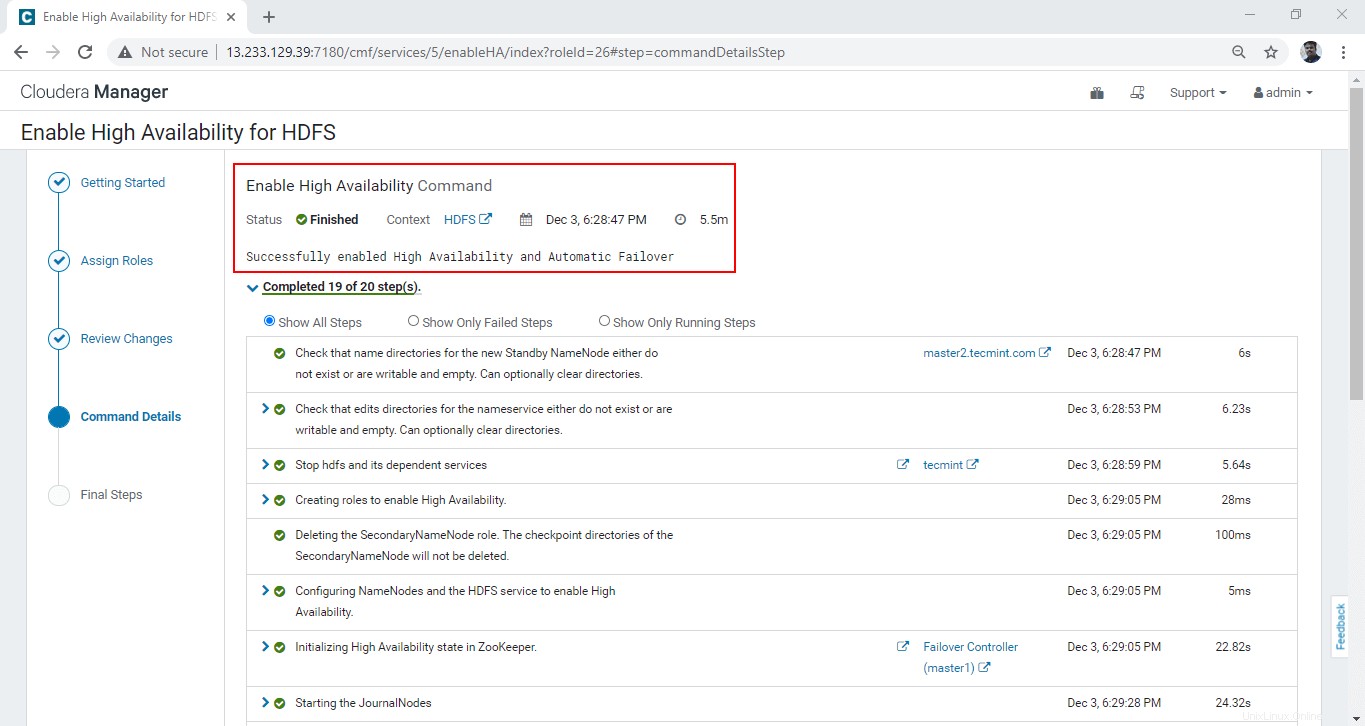
20. Sobald alle Hintergrundprozesse abgeschlossen sind, erhalten wir "Fertig". ’ Status.
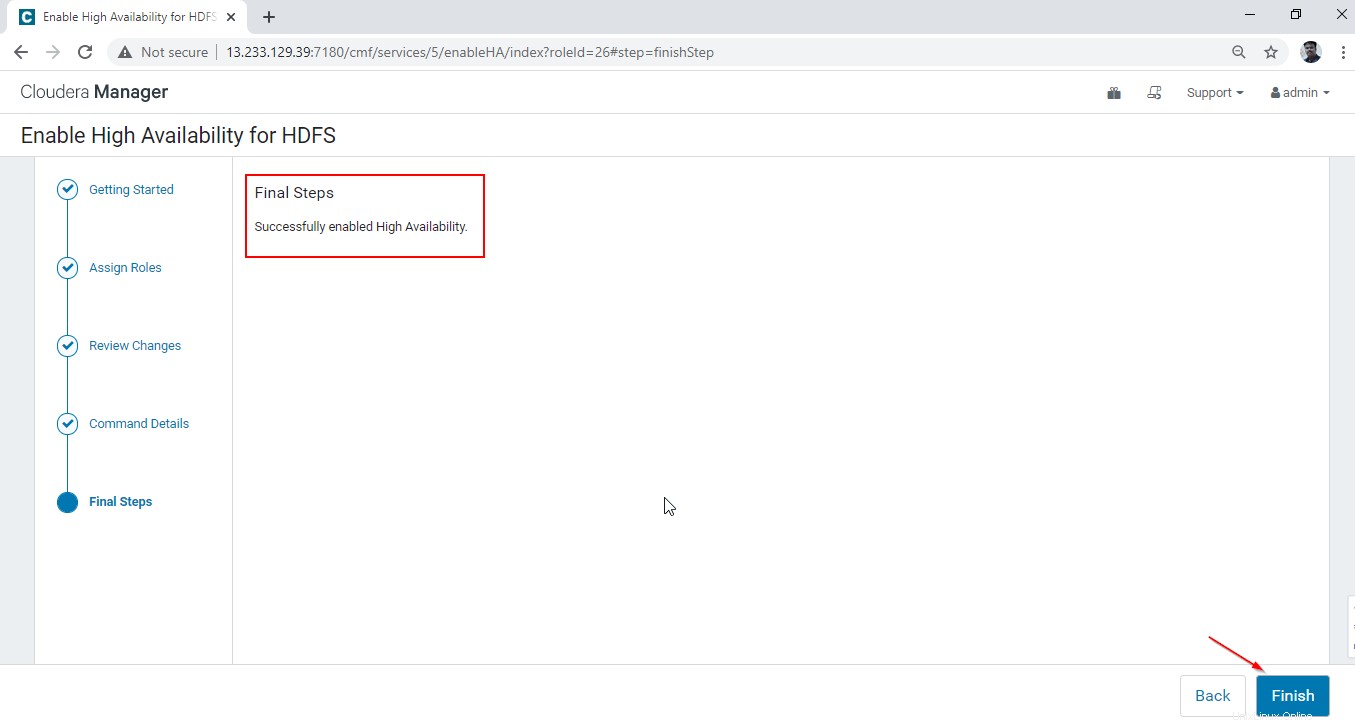
21. Schließlich erhalten wir eine Benachrichtigung „Hochverfügbarkeit erfolgreich aktiviert ’. Klicken Sie auf „Fertig stellen ’.
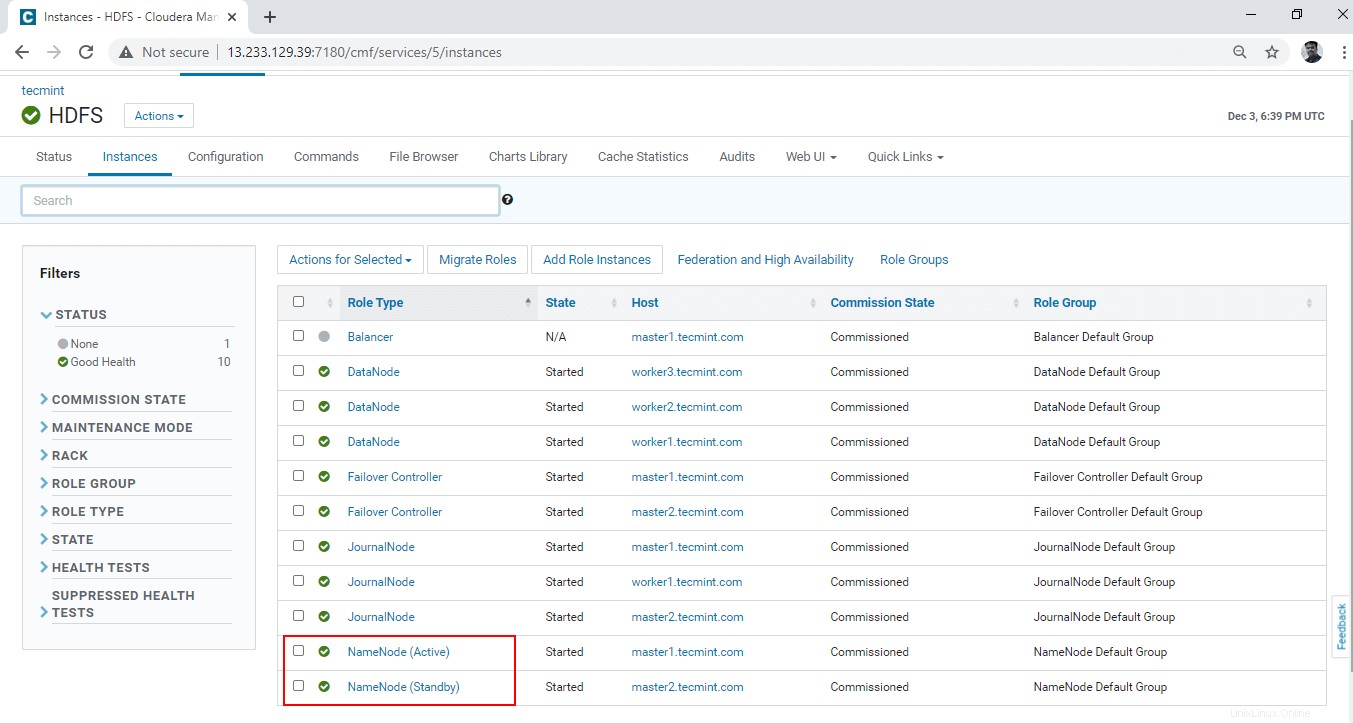
22. Bestätigen Sie Aktiv und Standby Namenode indem Sie zu Cloudera Manager gehen –> HDFS –> Instanzen .
23. Hier können Sie zwei Namenodes markieren , befindet sich einer im Bereich „Aktiv“. ’ Zustand und ein anderer befindet sich im ’Standby ’ Zustand.
Schlussfolgerung
In diesem Artikel haben wir den Prozess Schritt für Schritt durchlaufen, um Namenode High Availability zu aktivieren . Es wird dringend empfohlen, über Namenode High Availability zu verfügen in allen Clustern in einer Echtzeitumgebung. Bitte posten Sie Ihre Zweifel, wenn Sie bei diesem Vorgang auf einen Fehler stoßen. Wir werden Ressourcenmanager-Hochverfügbarkeit sehen im nächsten Artikel.