Einige Unternehmen können es nicht zulassen, dass ihre Dienste heruntergefahren werden. Im Falle eines Serverausfalls kann es bei einem Mobilfunkbetreiber zu Ausfallzeiten des Abrechnungssystems kommen, die zu einem Verbindungsverlust für alle seine Clients führen. Das Eingeständnis der möglichen Auswirkungen solcher Situationen führt zu der Idee, immer einen Plan B zu haben.
In diesem Artikel beleuchten wir verschiedene Arten des Schutzes vor Serverausfällen sowie Architekturen, die für die Bereitstellung von VMmanager Cloud verwendet werden, einem Kontrollpanel zum Aufbau eines Hochverfügbarkeitsclusters.

Vorwort
Die Terminologie im Bereich der Clustertoleranz ist von Website zu Website unterschiedlich. Um zu vermeiden, dass verschiedene Begriffe und Definitionen vermischt werden, lassen Sie uns diejenigen skizzieren, die in dem jeweiligen Artikel verwendet werden:
- Fehlertoleranz (FT) ist die Fähigkeit eines Systems, seinen Betrieb nach dem Ausfall einer seiner Komponenten fortzusetzen.
- Cluster ist eine Gruppe von Servern (Clusterknoten), die über Kommunikationskanäle verbunden sind.
- Fault Tolerant Cluster (FTC) ist ein Cluster, bei dem der Ausfall eines Servers nicht zur vollständigen Nichtverfügbarkeit des gesamten Clusters führt. Funktionen des ausgefallenen Knotens werden automatisch zwischen den verbleibenden Knoten neu zugewiesen.
- Continuous Availability (CA) bedeutet, dass ein Benutzer den Dienst ohne Zeitüberschreitungen nutzen kann. Es spielt keine Rolle, wie lange es her ist, dass der Knoten ausgefallen ist.
- Hohe Verfügbarkeit (HA) bedeutet, dass ein Benutzer Dienstzeitüberschreitungen erleben kann, falls einer der Knoten ausfällt; Das System wird jedoch automatisch mit minimaler Ausfallzeit wiederhergestellt.
- CA-Cluster ist ein Continuous-Availability-Cluster.
- HA-Cluster ist ein Hochverfügbarkeitscluster.
Lassen Sie es erforderlich sein, einen Cluster bereitzustellen, der aus 10 Knoten besteht, wobei virtuelle Maschinen auf jedem Knoten ausgeführt werden. Ziel ist es, virtuelle Maschinen nach dem Serverausfall zu schützen. Dual-CPU-Server werden verwendet, um die Berechnungsdichte von Racks zu maximieren.
Auf den ersten Blick ist die attraktivste Option für ein Unternehmen die Bereitstellung eines Continuous-Availability-Clusters, wenn ein Dienst noch bereitgestellt wird, nachdem die Ausrüstung ausgefallen ist. Kontinuierliche Verfügbarkeit ist in der Tat ein Muss, wenn Sie den Betrieb eines Abrechnungssystems aufrechterhalten oder einen kontinuierlichen Produktionsprozess automatisieren müssen. Dieser Ansatz hat jedoch auch seine Fallen und Fallstricke, die im Folgenden behandelt werden.
Ständige Verfügbarkeit
Die Kontinuität eines Dienstes ist nur möglich, wenn eine exakte Kopie einer physischen oder virtuellen Maschine mit diesem Dienst erstellt wird, die jederzeit verfügbar ist. Ein solches Redundanzmodell wird 2N genannt. Das Erstellen einer Kopie des Servers nach dem Ausfall des Geräts würde einige Zeit in Anspruch nehmen und zu einer Dienstzeitüberschreitung führen. Außerdem wäre es in diesem Fall nicht möglich, den RAM-Dump des ausgefallenen Servers abzurufen, was bedeutet, dass alle darin enthaltenen Informationen weg wären.
Es gibt zwei Methoden zur Bereitstellung von CA:auf einer Hardware- und einer Softwareebene. Konzentrieren wir uns genauer auf jeden von ihnen.
Die Hardware-Methode stellt einen Doppelserver dar, bei dem alle Komponenten dupliziert sind und Berechnungen gleichzeitig und unabhängig voneinander ausgeführt werden. Die Synchronisierung wird durch die Verwendung eines dedizierten Knotens erreicht, der die von beiden Teilen kommenden Ergebnisse überprüft. Wenn der Knoten eine Diskrepanz erkennt, versucht er, das Problem zu definieren und Fehler zu beheben. Kann der Fehler nicht behoben werden, schaltet das System das ausgefallene Modul ab.
Stratus, ein Hersteller von CA-Servern, garantiert, dass die Gesamtausfallzeit des Systems 32 Sekunden pro Jahr nicht überschreitet. Solche Ergebnisse können durch die Verwendung der speziellen Ausrüstung erzielt werden. Laut Stratus-Vertretern belaufen sich die Kosten für einen CA-Server mit zwei CPUs für jedes synchronisierte Modul je nach Spezifikation auf rund 160.000 US-Dollar. Der erweiterte Preis für den gesamten CA-Cluster würde in diesem Fall 1.600.000 $ betragen.
Die Softwaremethode
Das beliebteste Software-Tool für die Bereitstellung eines Continuous-Availability-Clusters zum Zeitpunkt des Artikels ist VMware vSphere. Die kontinuierliche Verfügbarkeitstechnologie dieses Produkts wird als Fehlertoleranz bezeichnet.
Im Gegensatz zur Hardwaremethode hat diese Technologie bestimmte Anforderungen, wie z. B. die folgenden:
- CPU auf dem physischen Host:
- Intel mit Sandy-Bridge-Architektur (oder neuer). Avoton wird nicht unterstützt.
- AMD Bulldozer (oder neuer).
- Maschinen mit Fehlertoleranz müssen mit geringer Latenz an ein 10-GB-Netzwerk angeschlossen werden. VMware empfiehlt dringend die Verwendung eines dedizierten Netzwerks.
- Nicht mehr als 4 virtuelle CPUs pro VM.
- Nicht mehr als 8 virtuelle CPUs pro physischem Host.
- Nicht mehr als 4 virtuelle Maschinen pro physischem Host.
- Snapshots virtueller Maschinen sind nicht verfügbar.
- Speicher vMotion ist nicht verfügbar.
Die vollständige Liste der Einschränkungen und Inkompatibilitäten finden Sie in der offiziellen Dokumentation.
Die vSphere-Lizenzierung basiert auf physischen CPUs. Der Preis beginnt bei 1750 $ pro Lizenz + 550 $ für Jahresabonnement und Support. Die Automatisierung der Clusterverwaltung erfordert auch VMware vCenter Server, das über 8000 US-Dollar kostet. Das 2N-Modell wird verwendet, um kontinuierliche Verfügbarkeit bereitzustellen, daher müssen 10 replizierte Server mit Lizenzen für jeden von ihnen erworben werden, um einen Cluster mit 10 Knoten mit virtuellen Maschinen aufzubauen.
Die Gesamtkosten der Software würden 2[Anzahl der CPUs pro Server]*(10[Anzahl der Knoten mit virtuellen Maschinen]+10[Anzahl der replizierten Knoten])*(1750+550)[Lizenzkosten pro CPU]+8000 betragen [Kosten für VMware vCenter Server] =100.000 US-Dollar. Alle Preise sind gerundet.
In diesem Artikel werden keine spezifischen Knotenkonfigurationen beschrieben, da sich die Serverkomponenten immer je nach Zweck des Clusters unterscheiden. Eine Netzwerkausstattung wird ebenfalls nicht beschrieben, da sie in jedem Fall identisch sein sollte. Dieser Artikel konzentriert sich auf die Komponenten, die definitiv variieren würden, nämlich die Lizenzkosten.
Es ist auch wichtig, die Produkte zu erwähnen, die nicht mehr entwickelt und unterstützt werden.
Das Produkt namens Remus basiert auf der Xen-Virtualisierung. Es ist eine kostenlose Open-Source-Lösung, die die Mikro-Snapshot-Technologie verwendet. Leider wurde die Dokumentation lange nicht aktualisiert:Die Installationsanleitung enthält Anweisungen für Ubuntu 12.10, dessen Lebensende 2014 angekündigt wurde. Selbst die Google-Suche hat keine Firma gefunden, die Remus für ihren Betrieb verwendet.
Es wurden Versuche unternommen, QEMU zu modifizieren, um Continuous Availability-Cluster auf dieser Technologie aufzubauen. Es gibt zwei Projekte, die ihre Arbeit in diese Richtung angekündigt haben.
Das erste ist Kemari, ein Open-Source-Produkt unter der Leitung von Yoshiaki Tamura. Dieses Projekt sollte eine Live-QEMU-Migration verwenden. Der letzte Commit wurde im Februar 2011 durchgeführt, was darauf hindeutet, dass die Entwicklung einen Stillstand erreicht hat und nicht fortgesetzt wird.
Das zweite Produkt ist Micro Checkpointing, ein von Michael Hines gegründetes Open-Source-Projekt. Im Änderungsprotokoll des letzten Jahres wurden keine Aktivitäten gefunden, die dem Kemari-Projekt ähneln.
Diese Fakten lassen den Schluss zu, dass es bis heute einfach keine Möglichkeit für Continuous Availability auf KVM-Virtualisierung gibt.
Trotz aller Vorteile von Continuous-Availability-Systemen gibt es viele Hindernisse auf dem Weg zur Bereitstellung und zum Betrieb solcher Lösungen. Dennoch kann in einigen Fällen eine Fehlertoleranz erforderlich sein, jedoch ohne die Notwendigkeit, kontinuierlich verfügbar zu sein. Solche Szenarien ermöglichen die Verwendung von Clustern mit hoher Verfügbarkeit.
Hohe Verfügbarkeit
Ein Hochverfügbarkeitscluster bietet Fehlertoleranz, indem es automatisch erkennt, ob Hardware ausgefallen ist, und anschließend den Dienst auf dem verfügbaren Knoten startet.
Hochverfügbarkeit unterstützt keine Synchronisierung von CPUs, die auf Knoten gestartet werden, und erlaubt nicht immer die Synchronisierung lokaler Festplatten. Vor diesem Hintergrund wird empfohlen, von Knoten verwendete Laufwerke in einem separaten unabhängigen Speicher wie dem Netzwerkspeicher zu platzieren.
Der Grund ist klar:Der Knoten kann nach seinem Ausfall nicht erreicht werden, und Informationen von seinem Speichergerät können nicht abgerufen werden. Das Datenspeichersystem sollte auch fehlertolerant sein, da sonst keine Möglichkeit für Hochverfügbarkeit besteht. Folglich besteht der Hochverfügbarkeitscluster aus zwei Unterclustern:
- Rechencluster bestehend aus Knoten mit virtuellen Maschinen
- Speichercluster mit Festplatten, die von Rechenknoten verwendet werden.
Derzeit gibt es folgende Lösungen zur Implementierung von Hochverfügbarkeits-Clustern mit virtuellen Maschinen auf Cluster-Knoten:
- Heartbeat, Version 1.? mit DRBD;
- Herzschrittmacher;
- VMware vSphere;
- Proxmox VE;
- XenServer;
- OpenStack;
- oVirt;
- Red Hat Enterprise Virtualisierung;
- Windows Server Failover Clustering mit Hyper-V-Serverrolle;
- VMmanager-Cloud.
Werfen wir einen genaueren Blick auf VMmanager Cloud.
VMmanager-Cloud
VMmanager Cloud ist ein Produkt, das die Bereitstellung von Hochverfügbarkeitsclustern ermöglicht und die QEMU-KVM-Virtualisierung verwendet. Diese Technologie wurde ausgewählt, weil sie aktiv entwickelt und unterstützt wird und es ermöglicht, jedes Betriebssystem auf einer virtuellen Maschine zu installieren. Das Produkt verwendet Corosync, um die Verfügbarkeit des Clusters zu erkennen. Wenn einer der Server ausfällt, verteilt VMmanager seine virtuellen Maschinen nacheinander auf die verbleibenden Knoten.
In vereinfachter Form funktioniert dieser Mechanismus wie folgt:
- Das System identifiziert den Cluster-Knoten mit der niedrigsten Anzahl virtueller Maschinen.
- Es prüft, ob genügend RAM vorhanden ist, um die Maschine zu finden.
- Wenn auf einem Knoten genügend Speicher für die entsprechende Maschine vorhanden ist, erstellt VMmanager auf diesem Knoten eine neue virtuelle Maschine.
- Wenn nicht genügend Arbeitsspeicher vorhanden ist, prüft das System die anderen Knoten mit weiteren virtuellen Maschinen.
Das Testen einiger Hardwarekonfigurationen und Anfragen vieler aktueller VMmanager Cloud-Benutzer ergab, dass es normalerweise 45–90 Sekunden dauert, um den Betrieb aller VMs vom ausgefallenen Knoten zu verteilen und wiederherzustellen, abhängig von der Geräteleistung.
Es wird empfohlen, einen oder wenige Nodes als Absicherung gegen Notsituationen zu dedizieren und im laufenden Betrieb keine VMs auf diesen Nodes einzusetzen. Es minimiert die Wahrscheinlichkeit fehlender Ressourcen auf den Live-Cluster-Knoten zum Hinzufügen virtueller Maschinen vom ausgefallenen Knoten. Falls nur ein Backup-Knoten verwendet wird, wird dieses Sicherheitsmodell N+1 genannt.
VMmanager Cloud unterstützt die folgenden Speichertypen:Dateisystem, LVM, Netzwerk-LVM, iSCSI und Ceph [insbesondere RBD (RADOS Block Device), eine der Ceph-Implementierungen]. Die letzten drei werden für Hochverfügbarkeit verwendet.
Eine lebenslange Lizenz für zehn betriebsbereite Knoten und einen Backup-Knoten kostet 3520 € oder 3865 $ bis heute (eine Lizenz kostet 320 € pro Knoten, unabhängig von der CPU-Nummer). Die Lizenz beinhaltet ein Jahr kostenlose Updates; Ab dem zweiten Jahr werden Updates pro Abonnementmodell zum Preis von 880 € pro Jahr für das gesamte Cluster bereitgestellt.
Sehen wir uns an, wie VMmanager Cloud bereits für die Bereitstellung von Hochverfügbarkeitsclustern verwendet wurde.
ErstesByte
FirstByte begann im Februar 2016 mit der Bereitstellung von Cloud-Hosting. Ursprünglich basierte ihr Cluster auf OpenStack; Der Mangel an Spezialisten für dieses System in Bezug auf Verfügbarkeit und Kosten veranlasste sie jedoch, nach einer alternativen Lösung zu suchen. Das neue System zum Aufbau eines Hochverfügbarkeitsclusters sollte die folgenden Anforderungen erfüllen:
- Möglichkeit zur Bereitstellung virtueller KVM-Maschinen.
- Integration mit Ceph.
- Integration mit einem Abrechnungssystem zum Anbieten der bestehenden Dienste.
- Erschwingliche Lizenzkosten.
- Unterstützung durch den Softwareentwickler.
VMmanager Cloud erfüllt alle Anforderungen.
Besonderheiten des FirstByte-Clusters:
- Die Datenübertragung basiert auf Ethernet-Technologie und Cisco-Geräten.
- Routing wird mit Cisco ASR9001 durchgeführt. Der Cluster verwendet etwa 50000 IPv6-Adressen.
- Die Verbindungsgeschwindigkeit zwischen Rechenknoten und Switches beträgt 10 Gbit/s.
- Die Datenübertragungsgeschwindigkeit zwischen Switches und Speicherknoten beträgt 20 Gbit/s, mit zwei kombinierten Kanälen mit jeweils 10 Gbit/s.
- Eine separate 20-Gbit/s-Verbindung wird zwischen Racks mit Speicherknoten für die Replikation verwendet.
- SAS-Festplatten in Kombination mit SSDs sind auf allen Speicherknoten installiert.
- Speichertyp ist RBD.
Das Systemlayout ist unten dargestellt:
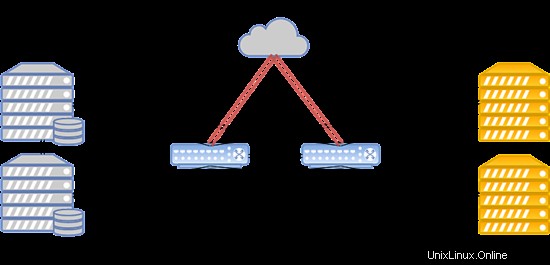
Eine solche Konfiguration eignet sich zum Hosten beliebter Websites, Spieleserver und Datenbanken mit überdurchschnittlicher Auslastung.
ErsterVDS
FirstVDS stellt die Dienste des fehlertoleranten Clusters bereit, das im September 2015 gestartet wurde.
VMmanager Cloud wurde aufgrund der folgenden Faktoren für diesen Cluster ausgewählt:
- Solide Erfahrung in der Verwendung von ISPsystem-Kontrollfeldern.
- Integration mit BILLmanager standardmäßig.
- Hochwertiger technischer Support.
- Integration mit Ceph.
Ihr Cluster hat die folgenden Merkmale:
- Die Datenübertragung basiert auf einem Infiniband-Netzwerk mit einer Verbindungsgeschwindigkeit von 56 Gbit/s;
- Das Infiniband-Netzwerk basiert auf Mellanox-Geräten;
- Speicherknoten haben SSD-Laufwerke;
- Speichertyp ist RBD.
Das System kann wie folgt aufgebaut sein:
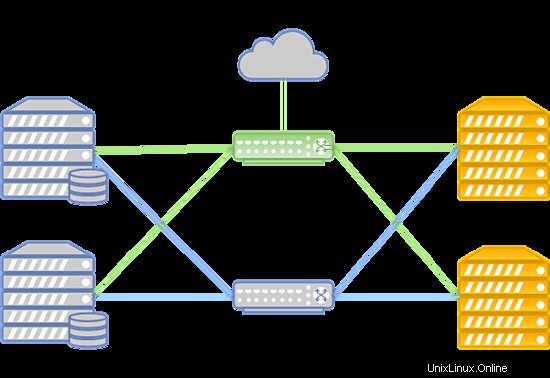
Im Falle eines Ausfalls des Infiniband-Netzwerks wird die Verbindung zwischen dem VM-Festplattenspeicher und den Rechenservern über das auf Juniper-Geräten bereitgestellte Ethernet-Netzwerk hergestellt. Die neue Verbindung wird automatisch aufgebaut.
Aufgrund der hohen Kommunikationsgeschwindigkeit mit dem Speicher eignet sich dieser Cluster perfekt für das Hosten von Websites mit ultrahohem Datenverkehr, Video- und Content-Streaming sowie Big Data.
Schlussfolgerung
Fassen wir die wichtigsten Ergebnisse des Artikels zusammen.
Das Continuous Availability-Cluster ist ein Muss, wenn jede Sekunde Ausfallzeit erhebliche Verluste mit sich bringt. Wenn ein Ausfall von 5 Minuten zulässig ist, während virtuelle Maschinen auf einem Backup-Knoten bereitgestellt werden, kann der High Availability-Cluster eine gute Option sein, um die Hardware- und Softwarekosten zu senken.
Es ist auch wichtig, daran zu erinnern, dass der einzige Weg, Fehlertoleranz zu erreichen, Übertreibung ist. Stellen Sie sicher, dass Sie Ihre Server, Datenkommunikationsgeräte und Verbindungen, Internet-Zugangskanäle und Stromversorgung replizieren. Replizieren Sie alles, was Sie können. Durch solche Maßnahmen können Engpässe und potenzielle Fehlerquellen beseitigt werden, die zu Ausfallzeiten des gesamten Systems führen können. Indem Sie die oben genannten Maßnahmen ergreifen, können Sie sicher sein, dass Sie einen fehlertoleranten Cluster haben, der gegen Ausfälle resistent ist.
Wenn Sie der Meinung sind, dass das Hochverfügbarkeitsmodell Ihren Anforderungen entspricht und VMmanager Cloud ein gutes Tool ist, um es zu realisieren, lesen Sie bitte das Installationshandbuch und die Dokumentation, um mehr über das System zu erfahren. ich wünsche Ihnen einen störungsfreien und kontinuierlichen Betrieb!