Awk ist eine Skriptsprache, die zum Verarbeiten oder Analysieren von Textdateien verwendet wird. Oder wir können sagen, dass der Befehl awk hauptsächlich zum Gruppieren von Daten basierend auf einer Spalte oder einem Feld oder auf einer Reihe von Spalten verwendet wird. Hauptsächlich wird es verwendet, um Daten auf nützliche Weise zu melden. Es verwendet auch Begin- und End-Blöcke, um die Daten zu verarbeiten.
AWK steht für „Aho, Weinberger und Kernighan“
In diesem Tutorial lernen wir den awk-Befehl anhand praktischer Beispiele kennen.
Syntax von awk
# awk ‘Muster {Aktion}’ Eingabedatei> Ausgabedatei
Nehmen wir eine Eingabedatei mit den folgenden Daten
$ cat awk_file Name,Marks,Max Marks Ram,200,1000 Shyam,500,1000 Ghyansham,1000 Abharam,800,1000 Hari,600,1000 Ram,400,1000
Lassen Sie uns nun tief in praktische Beispiele für den awk-Befehl eintauchen.
1) Alle Zeilen aus einer Datei drucken
Standardmäßig druckt awk alle Zeilen einer Datei. Um also jede Zeile der oben erstellten Datei zu drucken, verwenden Sie den folgenden Befehl:
$ awk '{print;}' awk_file
Name,Marks,Max Marks
Ram,200,1000
Shyam,500,1000
Ghyansham,1000
Abharam,800,1000
Hari,600,1000
Ram,400,1000 Hinweis: Im awk-Befehl wird ‘{print;}’ verwendet, um alle Felder zusammen mit ihren Werten auszudrucken.
2) Nur bestimmte Felder wie 2. und 3. drucken
Im awk-Befehl verwenden wir das Symbol $ (Dollar), gefolgt von der Feldnummer, um Feldwerte zu drucken. Im folgenden Beispiel drucken wir Feld 2 (d. h. Marks) und Feld 3 (d. h. Max Marks)
$ awk -F "," '{print $2, $3;}' awk_file
Marks Max Marks
200 1000
500 1000
1000
800 1000
600 1000
400 1000 Im obigen Befehl haben wir die Option -F „,“ verwendet, die angibt, dass das Komma (,) das Feldtrennzeichen in der Datei ist.
3) Drucken Sie die Linien, die dem Muster entsprechen
Ich möchte die Zeilen drucken, die das Wort „Hari &Ram“ enthalten, run
$ awk '/Hari|Ram/' awk_file Ram,200,1000 Hari,600,1000 Ram,400,1000
4) Wie finden wir eindeutige Werte in der ersten Spalte von name
Um eindeutige Werte aus der ersten Spalte zu drucken, führen Sie den folgenden awk-Befehl
aus$ awk -F, '{a[$1];}END{for (i in a)print i;}' awk_file
Abharam
Hari
Name
Ghyansham
Ram
Shyam 5) So finden Sie die Summe der Dateneingabe in einer bestimmten Spalte
Im awk-Befehl ist es auch möglich, einige arithmetische Operationen basierend auf der Suche durchzuführen, die Syntax ist unten gezeigt
$ awk -F, ‘$1==”Element1″{x+=$2;}END{print x}’ awk_file
Im folgenden Beispiel suchen wir nach Ram und fügen dann Werte des zweiten Felds für das Wort Ram hinzu.
$ awk -F, '$1=="Ram"{x+=$2;}END{print x}' awk_file
600 6) So finden Sie die Summe aller Zahlen in einer Spalte
Im awk-Befehl können wir auch die Summe aller Zahlen in einer Spalte einer Datei berechnen. Im folgenden Beispiel berechnen wir die Summe aller Zahlen der 2. und 3. Spalte.
$ awk -F"," '{x+=$2}END{print x}' awk_file
3500
$ awk -F"," '{x+=$3}END{print x}' awk_file
5000 7) So finden Sie die Summe einzelner Gruppendatensätze
Wenn wir beispielsweise die erste Spalte betrachten, können wir die Summierung für die erste Spalte basierend auf den Elementen durchführen
$ awk -F, '{a[$1]+=$2;}END{for(i in a)print i", "a[i];}' awk_file
Abharam, 800
Hari, 600
Name, 0
Ghyansham, 1000
Ram, 600
Shyam, 500 8) Ermitteln Sie die Summe aller Einträge bestimmter Spalten und hängen Sie sie an das Ende der Datei an
Wie wir bereits besprochen haben, kann der awk-Befehl die Summe aller Zahlen einer Spalte berechnen. Um also die Summe von Spalte 2 und Spalte 3 am Ende der Datei anzuhängen, führen Sie
aus$ awk -F"," '{x+=$2;y+=$3;print}END{print "Total,"x,y}' awk_file
Name,Marks,Max Marks
Ram,200,1000
Shyam,500,1000
Ghyansham,1000
Abharam,800,1000
Hari,600,1000
Ram,400,1000
Total,3500 5000 9) So ermitteln Sie die Anzahl der Einträge für jede Spalte basierend auf der ersten Spalte
$ awk -F, '{a[$1]++;}END{for (i in a)print i, a[i];}' awk_file
Abharam 1
Hari 1
Name 1
Ghyansham 1
Ram 2
Shyam 1 10) So drucken Sie nur den ersten Datensatz jeder Gruppe
Um nur den ersten jeder Gruppe zu drucken, führen Sie den folgenden awk-Befehl
aus$ awk -F, '!a[$1]++' awk_file Name,Marks,Max Marks Ram,200,1000 Shyam,500,1000 Ghyansham,1000 Abharam,800,1000 Hari,600,1000
AWK-Startblock
Die Syntax für den BEGIN-Block ist
$ awk ‘BEGIN{awk-Initialisierungscode}{tatsächlicher AWK-Code}’ Dateiname
Lassen Sie uns eine Datendatei mit den folgenden Inhalten erstellen
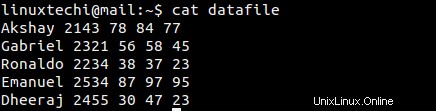
11) So füllen Sie die einzelnen Spaltennamen zusammen mit den entsprechenden Daten aus
$ awk 'BEGIN{print "Names\ttotal\tPPT\tDoc\txls"}{printf "%-s\t%d\t%d\t%d\t%d\n", $1,$2,$3,$4,$5}' datafile

12) So ändern Sie das Feldtrennzeichen
Wie wir sehen können, ist Leerzeichen das Feldtrennzeichen in der Datendatei, im folgenden Beispiel ändern wir das Feldtrennzeichen von Leerzeichen in „|“
$ awk 'BEGIN{OFS="|"}{print $1,$2,$3,$4,$5}' datafile

Das ist alles aus diesem Tutorial, ich hoffe, Sie fanden es informativ. Bitte teilen Sie Ihr Feedback und Ihre Fragen im Kommentarbereich unten.