ELK-Stack wird als Elasticsearch-, Logstash- und Kibana-Stack abgekürzt, ein Open-Source-Analytics-Stack mit vollem Funktionsumfang hilft bei der Analyse beliebiger Maschinendaten. Es wird als Alternative zu anderer kommerzieller Datenanalysesoftware wie Splunk verwendet.
Ich hoffe, Sie benötigen keine Einführung in den ELK-Stack, wenn Sie ihn noch benötigen. Ich habe viele Tutorials zur Konfiguration des ELK-Stacks auf Linux-Betriebssystemen geschrieben.
Sie können den folgenden Tutorials folgen, um zu verstehen, was ELK ist,
- So installieren Sie den ELK-Stack unter Ubuntu 16.04
- So installieren Sie den ELK-Stack auf CentOS 7 / RHEL 7
In diesem Tutorial werden wir sehen, wie man den ELK-Stack auf dem Docker-Container ausführt, anstatt ihn auf dem Host-Betriebssystem zu installieren.
Wir können den ELK-Stack entweder mit Docker Native CLI oder Docker Compose ausführen.
Voraussetzungen:
Alles, was Sie brauchen, ist der neueste Docker, der auf Ihrem System installiert ist. Stellen Sie sicher, dass die Docker-Version 1.6 und höher ist, aber einige Bilder, z. Elasticsearch wird offiziell nur von Docker-Version 1.12.1
unterstützt- So installieren Sie Docker unter Ubuntu 16.04 / 15.10 / 14.04
- So richten Sie Docker unter CentOS 7 / RHEL 7 ein
- So installieren Sie Docker auf Fedora 24 / 23
Wie installiere ich Docker auf openSUSE
Die Docker-Images, die wir hier verwenden, sind die offiziellen Images von Elastic
Elasticsearch:
Zu Beginn werden wir einen Elastisearch-Container ausführen. Das Elasticsearch-Image ist mit einem Volume unter /usr/share/elasticsearch/data konfiguriert um die persistenten Indexdaten zu behalten. Verwenden Sie also diesen Pfad, wenn Sie die Daten auf einem gemounteten Volume speichern möchten, das /esdata. ist
Erstellen Sie ein /esdata Verzeichnis auf dem Docker-Host.
mkdir /esdata
Führen Sie den folgenden Befehl aus, um den Elasticsearch-Docker-Container zu erstellen. Der Hostpfad steht immer zuerst in der Befehlszeile und die :, dann Behälterinnenvolumen.
docker run -d --name elasticsearch -p 9200:9200 -p 9300:9300 -v /esdata:/usr/share/elasticsearch/data elasticsearch
Verwenden Sie die CURL, um die Antwort von Elasticsearch zu erhalten.
curl -X GET http://localhost:9200
{
"name" : "Red Skull",
"cluster_name" : "elasticsearch",
"version" : {
"number" : "2.3.5",
"build_hash" : "90f439ff60a3c0f497f91663701e64ccd01edbb4",
"build_timestamp" : "2016-07-27T10:36:52Z",
"build_snapshot" : false,
"lucene_version" : "5.5.0"
},
"tagline" : "You Know, for Search"
} Logstash:
Sobald Elasticsearch eingerichtet ist und ausgeführt wird, können wir nun den Logstash-Container ausführen. Bevor Sie den Logstash-Container starten, erstellen Sie eine Konfigurationsdatei, um die Protokolle von den Beats zu erhalten.
Erstellen Sie das Verzeichnis und die Konfigurationsdatei auf dem Docker-Host.
mkdir /logstash vi /logstash/logstash.conf
Die folgende Konfigurationsdatei soll die Protokolle mit dem Protokolltyp „syslog erhalten “ auf Port „5044 „und sie zur Indizierung an Elasticsearch senden.
input {
beats {
port => 5044
}
}
filter {
if [type] == "syslog" {
grok {
match => { "message" => "%{SYSLOGLINE}" }
}
date {
match => [ "timestamp", "MMM d HH:mm:ss", "MMM dd HH:mm:ss" ]
}
}
}
output {
elasticsearch {
hosts => ["elasticsearch:9200"]
index => "%{[@metadata][beat]}-%{+YYYY.MM.dd}"
}
stdout {
codec => rubydebug
}
} Wenn Sie in der obigen Konfigurationsdatei den Ausgabeabschnitt sehen; Der Elasticsearch-Host ist als elasticsearch:9200 definiert . Sie denken vielleicht, wie Logstash diesen Host auflöst, um Protokolle zu senden, machen Sie sich keine Sorgen; Docker-Verknüpfung (–link ) kümmert sich darum.
cd /logstash/
Erstellen Sie einen Logstash-Container, indem Sie den folgenden Befehl ausführen.
Wo,
–link Elasticsearch-Containername:Hostname-in-Konfigurationsdatei
docker run -d --name logstash -p 5044:5044 --link elasticsearch:elasticsearch -v "$PWD":/logstash logstash -f /logstash/logstash.conf
Kibana:
Der Kibana-Container erfordert keine Konfiguration, Sie müssen lediglich den Kibana-Docker-Container mit dem Elasticsearch-Container verknüpfen.
docker run --name kibana --link elasticsearch:elasticsearch -p 5601:5601 -d kibana
Überprüfen:
Benutzer docker ps Befehl, um zu prüfen, ob alle Container laufen oder nicht.
docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 824dc7ee3c9f kibana "/docker-entrypoint.s" About an hour ago Up About an hour 0.0.0.0:5601->5601/tcp kibana 4fa8a72c96a2 logstash "/docker-entrypoint.s" About an hour ago Up About an hour 0.0.0.0:5044->5044/tcp logstash 4ea93b1d838b elasticsearch "/docker-entrypoint.s" About an hour ago Up About an hour 0.0.0.0:9200->9200/tcp, 0.0.0.0:9300->9300/tcp elasticsearch
Installieren und Konfigurieren von Beats:
Beats werden gesammelt und an Logstash gesendet. Installation und Konfiguration von Beats liegen außerhalb des Geltungsbereichs.
- So installieren und konfigurieren Sie Filebeat unter Ubuntu / Debian
- So installieren und konfigurieren Sie Filebeat unter CentOS 7 / RHEL 7
Auf die Kibana-Oberfläche zugreifen:
Wenn alle Container wie erwartet betriebsbereit sind und ausgeführt werden, rufen Sie die folgende URL auf, um auf die Weboberfläche zuzugreifen.
http://deine-ip-adresse:5601/Richten Sie einen Schlagindex ein, um mit der Suche nach Daten mit Kibana zu beginnen.
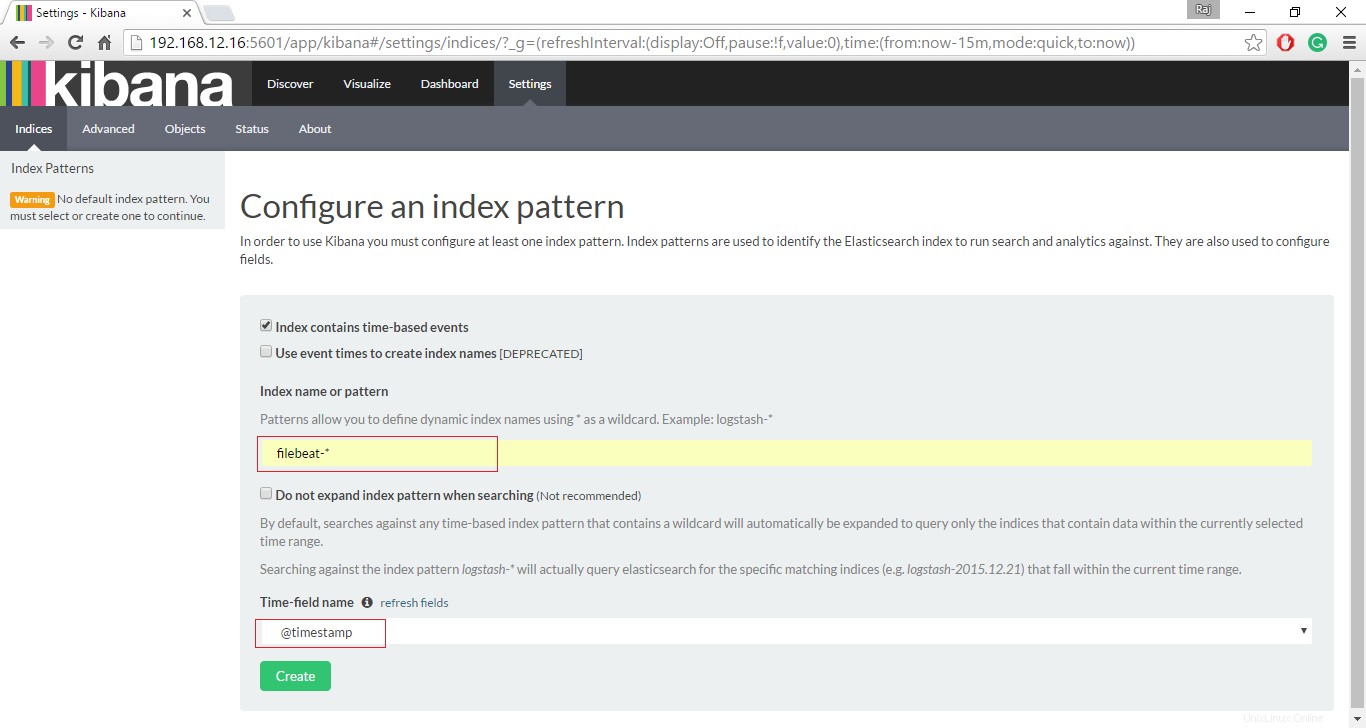
Klicken Sie auf Entdecken, um mit der Suche nach den neuesten Protokollen von Filebeat zu beginnen.
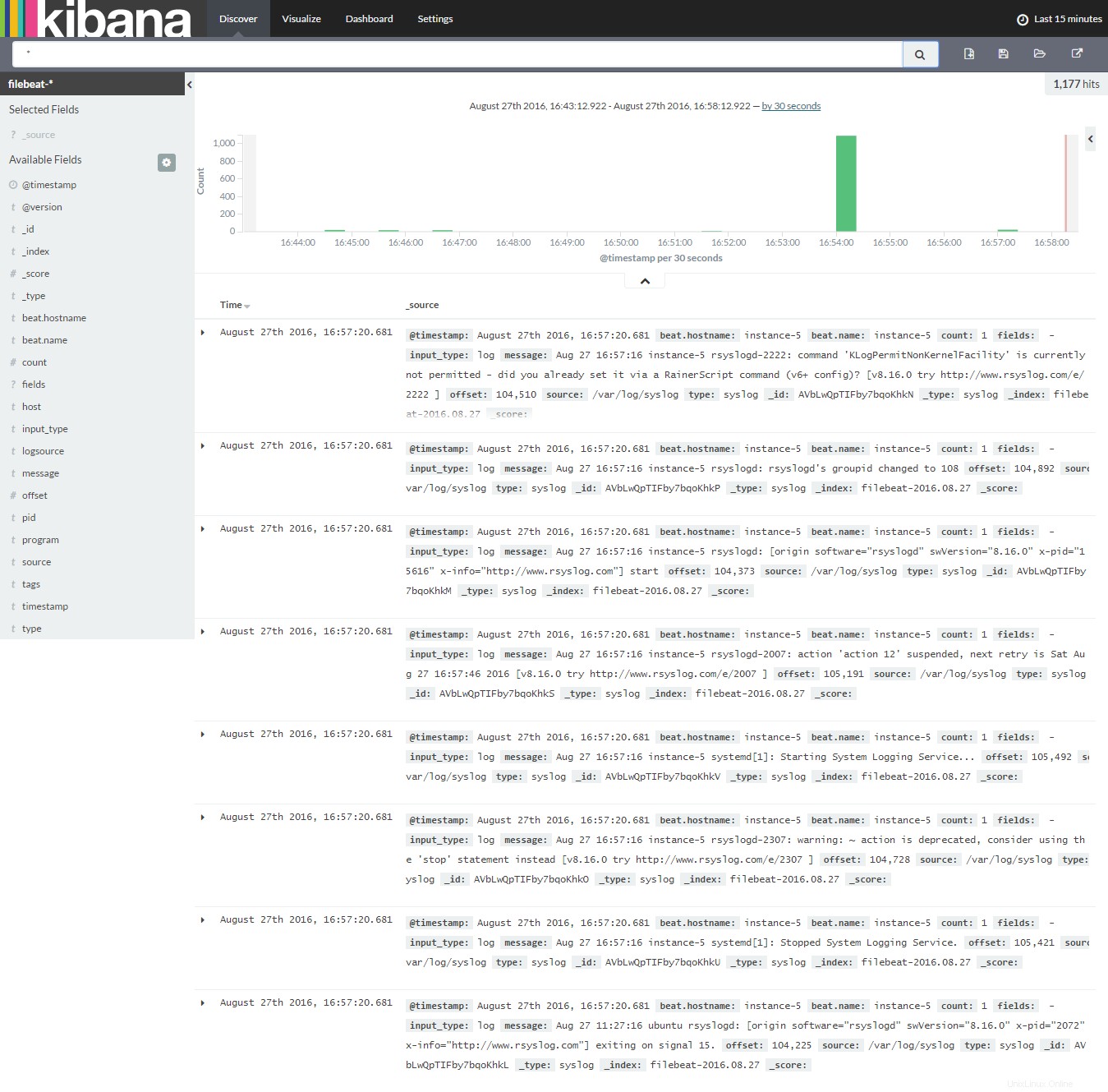
Das ist vorerst alles.