Einführung
Elasticsearch ist eine skalierbare Echtzeit-Suchmaschine, die in Clustern bereitgestellt wird. In Kombination mit der Kubernetes-Orchestrierung ist Elasticsearch einfach zu konfigurieren, zu verwalten und zu skalieren.
Durch die standardmäßige Bereitstellung eines Elasticsearch-Clusters werden drei Pods erstellt. Jeder Pod erfüllt alle drei Funktionen:Master, Daten und Client. Die Best Practice wäre jedoch, mehrere dedizierte Elasticsearch-Pods für jede Rolle manuell bereitzustellen.
In diesem Artikel wird erläutert, wie Sie Elasticsearch auf Kubernetes auf sieben Pods manuell und mithilfe eines vorgefertigten Helm-Diagramms bereitstellen.

Voraussetzungen
- Ein Kubernetes-Cluster (wir haben Minikube verwendet).
- Der Helm-Paketmanager.
- Das kubectl-Befehlszeilentool.
- Zugriff auf die Befehlszeile oder das Terminal.
So stellen Sie Elasticsearch manuell auf Kubernetes bereit
Die Best Practice ist die Verwendung von sieben Pods im Elasticsearch-Cluster:
- Drei Master-Pods zum Verwalten des Clusters.
- Zwei Datenpods zum Speichern von Daten und Verarbeiten von Abfragen.
- Zwei Client- (oder koordinierende) Pods zum Leiten des Datenverkehrs.
Das manuelle Bereitstellen von Elasticsearch auf Kubernetes mit sieben dedizierten Pods ist ein einfacher Prozess, der das Festlegen von Helm-Werten nach Rolle erfordert.
Schritt 1:Kubernetes einrichten
1. Der Cluster erfordert erhebliche Ressourcen. Stellen Sie die Minikube-CPUs auf mindestens 4 und den Arbeitsspeicher auf 8192 MB ein:
minikube config set cpus 4
minikube config set memory 8192
2. Öffnen Sie das Terminal und starten Sie Minikube mit den folgenden Parametern:
minikube start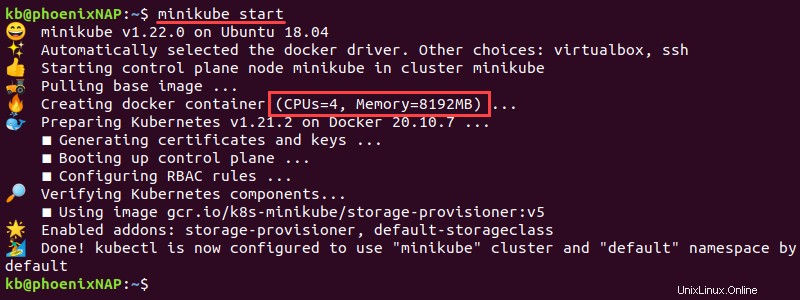
Die Instanz startet mit dem konfigurierten Arbeitsspeicher und den CPUs.
3. Minikube benötigt eine values.yaml Datei zum Ausführen von Elasticsearch. Laden Sie die Datei herunter mit:
curl -O https://raw.githubusercontent.com/elastic/helm-charts/master/elasticsearch/examples/minikube/values.yaml
Die Datei enthält Informationen, die im nächsten Schritt für alle drei Pod-Konfigurationen verwendet werden.
Schritt 2:Werte nach Pod-Rolle einrichten
1. Kopieren Sie den Inhalt der values.yaml Datei mit dem cp Befehl in drei verschiedene Pod-Konfigurationsdateien:
cp values.yaml master.yaml
cp values.yaml data.yaml
cp values.yaml client.yaml
2. Suchen Sie mit ls nach den vier YAML-Dateien Befehl:
ls -l *.yaml3. Öffnen Sie die master.yaml Datei mit einem Texteditor und fügen Sie am Anfang folgende Konfiguration hinzu:
# master.yaml
---
clusterName: "elasticsearch"
nodeGroup: "master"
roles:
master: "true"
ingest: "false"
data: "false"
replicas: 3
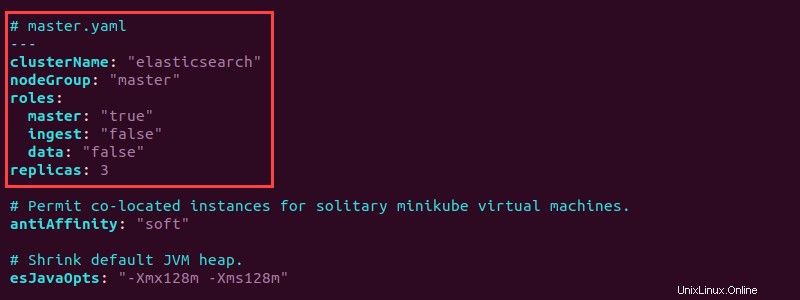
Die Konfiguration legt die Knotengruppe auf Master fest in der elastischen Suche Cluster und setzt die Master-Rolle auf "true" . Zusätzlich die master.yaml erstellt drei Replikate des Master-Knotens.
Die vollständige master.yaml sieht wie folgt aus:
# master.yaml
---
clusterName: "elasticsearch"
nodeGroup: "master"
roles:
master: "true"
ingest: "false"
data: "false"
replicas: 3
# Permit co-located instances for solitary minikube virtual machines.
antiAffinity: "soft
# Shrink default JVM heap.
esJavaOpts: "-Xmx128m -Xms128m"
# Allocate smaller chunks of memory per pod.
resources:
requests:
cpu: "100m"
memory: "512M"
limits:
cpu: "1000m"
memory: "512M"
# Request smaller persistent volumes.
volumeClaimTemplate:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "standard"
resources:
requests:
storage: 100M
4. Speichern Sie die Datei und schließen Sie sie.
5. Öffnen Sie die data.yaml Datei und fügen Sie oben die folgenden Informationen hinzu, um die Datenpods zu konfigurieren:
# data.yaml
---
clusterName: "elasticsearch"
nodeGroup: "data"
roles:
master: "false"
ingest: "true"
data: "true"
replicas: 2
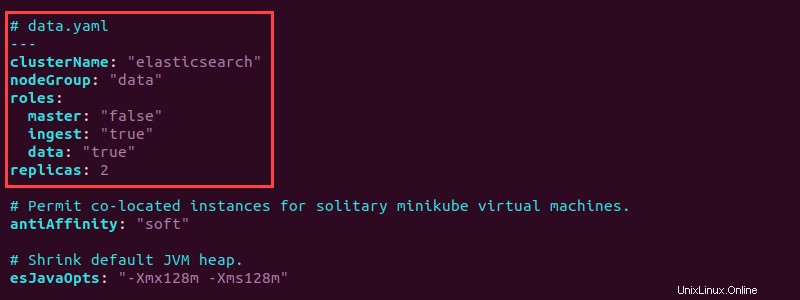
Das Setup erstellt zwei Data-Pod-Replikate. Setzen Sie sowohl die Daten- als auch die Aufnahmerolle auf "true" . Speichern Sie die Datei und schließen Sie sie.
6. Öffnen Sie die client.yaml Datei und fügen Sie oben die folgenden Konfigurationsinformationen hinzu:
# client.yaml
---
clusterName: "elasticsearch"
nodeGroup: "client"
roles:
master: "false"
ingest: "false"
data: "false"
replicas: 2
service:
type: "LoadBalancer"
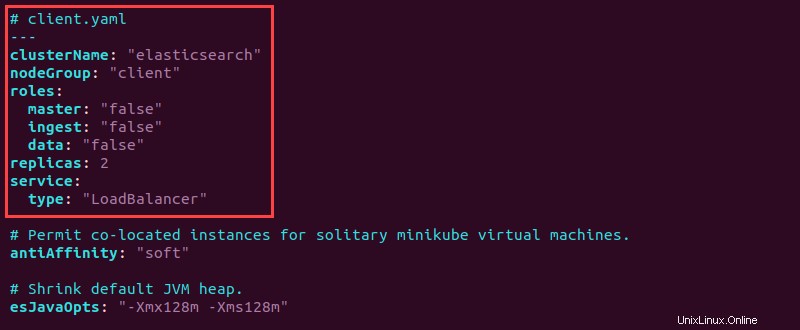
7. Speichern Sie die Datei und schließen Sie sie.
Der Client hat alle Rollen auf "false" gesetzt da der Client Dienstanfragen verarbeitet. Der Diensttyp wird als "LoadBalancer" bezeichnet Dienstanfragen gleichmäßig auf alle Knoten auszugleichen.
Schritt 3:Elasticsearch-Pods nach Rolle bereitstellen
1. Fügen Sie das Helm-Repository hinzu:
helm repo add elastic https://helm.elastic.co
2. Verwenden Sie helm install Befehl dreimal, einmal für jede benutzerdefinierte YAML-Datei, die im vorherigen Schritt erstellt wurde:
helm install elasticsearch-multi-master elastic/elasticsearch -f ./master.yaml
helm install elasticsearch-multi-data elastic/elasticsearch -f ./data.yaml
helm install elasticsearch-multi-client elastic/elasticsearch -f ./client.yaml
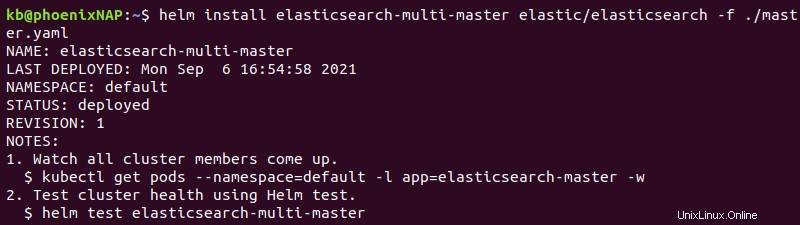
Die Ausgabe gibt die Bereitstellungsdetails aus.
3. Warten Sie, bis Cluster-Mitglieder bereitgestellt werden. Verwenden Sie den folgenden Befehl, um den Fortschritt zu überprüfen und den Abschluss zu bestätigen:
kubectl get pods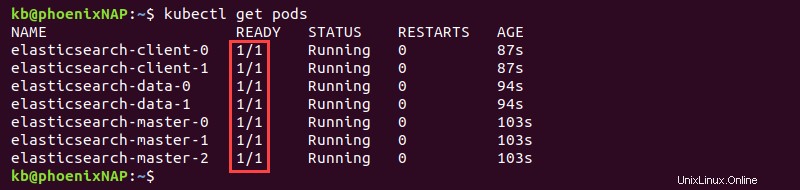
Die Ausgabe zeigt BEREIT Spalte mit den Werten 1/1 sobald die Bereitstellung für alle sieben Pods abgeschlossen ist.
Schritt 4:Verbindung testen
1. Um lokal auf Elasticsearch zuzugreifen, leiten Sie Port 9200 weiter mit kubectl Befehl:
kubectl port-forward service/elasticsearch-master
Der Befehl leitet die Verbindung weiter und hält sie offen. Lassen Sie das Terminalfenster laufen und fahren Sie mit dem nächsten Schritt fort.
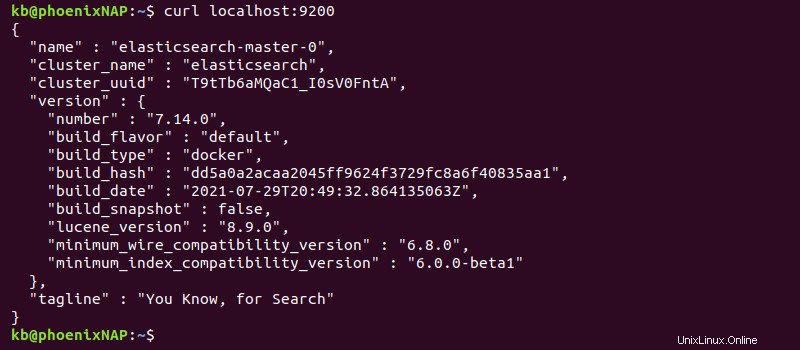
2. Testen Sie in einem anderen Terminal-Tab die Verbindung mit:
curl localhost:9200Die Ausgabe gibt die Bereitstellungsinformationen aus.
Greifen Sie alternativ auf localhost:9200 zu aus dem Browser.
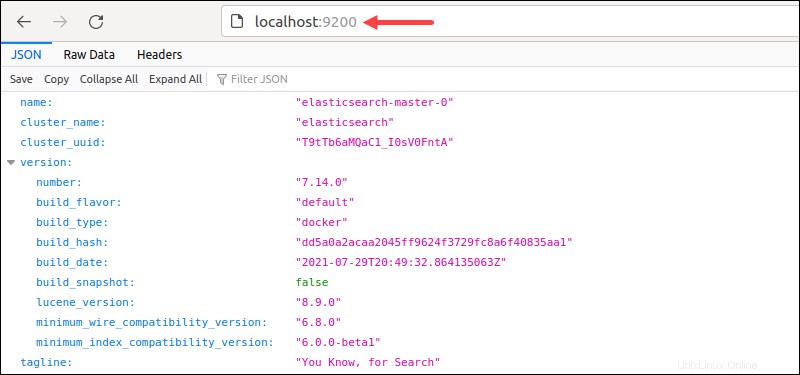
Die Ausgabe zeigt die Clusterdetails im JSON-Format, was darauf hinweist, dass die Bereitstellung erfolgreich war.
So stellen Sie Elasticsearch mit sieben Pods mithilfe eines vorgefertigten Helm-Diagramms bereit
Ein vorgefertigtes Helm-Diagramm zum Bereitstellen von Elasticsearch auf sieben dedizierten Pods ist im Bitnami-Repository verfügbar. Durch die Installation des Diagramms auf diese Weise wird das manuelle Erstellen von Konfigurationsdateien vermieden.
Schritt 1:Kubernetes einrichten
1. Weisen Sie mindestens 4 CPUs und 8192 MB Arbeitsspeicher zu:
minikube config set cpus 4
minikube config set memory 8192
2. Minikube starten:
minikube startDie Minikube-Instanz startet mit der angegebenen Konfiguration.
Schritt 2:Fügen Sie das Bitnami-Repository hinzu und stellen Sie das Elasticsearch-Diagramm bereit
1. Fügen Sie das Bitnami-Helm-Repository hinzu mit:
helm repo add bitnami https://charts.bitnami.com/bitnami
2. Installieren Sie das Diagramm, indem Sie Folgendes ausführen:
helm install elasticsearch --set master.replicas=3,coordinating.service.type=LoadBalancer bitnami/elasticsearch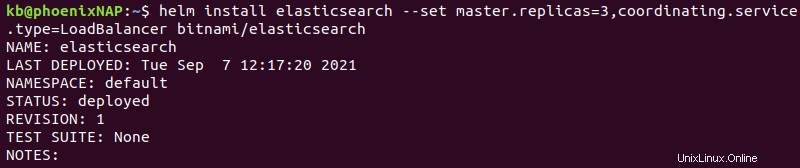
Der Befehl hat die folgenden Optionen:
- Elasticsearch wird unter dem Versionsnamen
elasticsearchinstalliert . master.replicas=3fügt dem Cluster drei Master-Replikate hinzu. Wir empfehlen, bei drei Masterknoten zu bleiben.coordinating.service.type=LoadBalancerstellt die Client-Knoten so ein, dass sie die Dienstanforderungen gleichmäßig auf alle Knoten verteilen.
3. Überwachen Sie die Bereitstellung mit:
kubectl get pods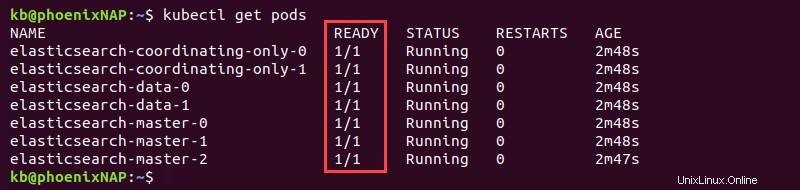
Die sieben Pods zeigen 1/1 in BEREIT Spalte, wenn Elasticsearch vollständig bereitgestellt wird.
Schritt 3:Verbindung testen
1. Leiten Sie die Verbindung an Port 9200 weiter :
kubectl port-forward svc/elasticsearch-master 9200Lassen Sie die Verbindung geöffnet und fahren Sie mit dem nächsten Schritt fort.
2. Überprüfen Sie in einem anderen Terminal-Tab die Verbindung mit:
curl localhost:9200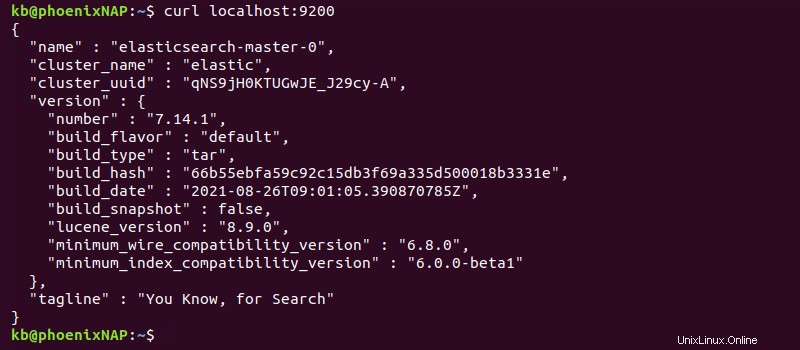
Greifen Sie alternativ über den Browser auf dieselbe Adresse zu, um die Bereitstellungsinformationen im JSON-Format anzuzeigen.