Einführung
Dieses Tutorial ist der erste einer Reihe von Artikeln, die sich auf Kubernetes und das Konzept der Containerbereitstellung konzentrieren. Kubernetes ist ein Tool zur Verwaltung von Clustern containerisierter Anwendungen. In der Computertechnik wird dieser Vorgang oft als Orchestrierung bezeichnet .
Die Analogie mit einem Musikorchester ist in vielerlei Hinsicht passend. Ähnlich wie ein Dirigent koordiniert Kubernetes viele Microservices, die zusammen eine nützliche Anwendung bilden. Kubernetes überwacht den Cluster automatisch und kontinuierlich und nimmt Anpassungen an seinen Komponenten vor.
Das Verständnis der Kubernetes-Architektur ist entscheidend für die Bereitstellung und Wartung containerisierter Anwendungen.
Was ist Kubernetes?
Kubernetes oder k8s Kurz gesagt, ist ein System zur Automatisierung der Anwendungsbereitstellung. Moderne Anwendungen sind über Clouds, virtuelle Maschinen und Server verteilt. Die manuelle Verwaltung von Apps ist keine praktikable Option mehr.
K8s verwandelt virtuelle und physische Maschinen in eine einheitliche API-Oberfläche. Ein Entwickler kann dann die Kubernetes-API verwenden, um containerisierte Anwendungen bereitzustellen, zu skalieren und zu verwalten.
Seine Architektur bietet auch einen flexiblen Rahmen für verteilte Systeme. K8s orchestriert automatisch Skalierung und Failover für Ihre Anwendungen und stellt Bereitstellungsmuster bereit.
Es hilft bei der Verwaltung von Containern, die die Anwendungen ausführen, und stellt sicher, dass es in einer Produktionsumgebung keine Ausfallzeiten gibt. Wenn zum Beispiel ein Container ausfällt, nimmt automatisch ein anderer Container seinen Platz ein, ohne dass der Endbenutzer es jemals bemerkt.
Kubernetes ist nicht nur ein Orchestrierungssystem. Es ist eine Reihe unabhängiger, miteinander verbundener Kontrollprozesse. Seine Aufgabe ist es, kontinuierlich am Ist-Zustand zu arbeiten und die Prozesse in die gewünschte Richtung zu lenken.
Lesen Sie unseren Artikel Was ist Kubernetes, wenn Sie mehr über Container-Orchestrierung erfahren möchten.
Kubernetes-Architektur und -Komponenten
Kubernetes hat eine dezentrale Architektur, die Aufgaben nicht sequenziell bearbeitet. Es funktioniert auf der Grundlage eines deklarativen Modells und implementiert das Konzept eines „gewünschten Zustands“. .“ Diese Schritte veranschaulichen den grundlegenden Kubernetes-Prozess:
- Ein Administrator erstellt und platziert den gewünschten Status einer Anwendung in einer Manifestdatei.
- Die Datei wird dem Kubernetes-API-Server über eine CLI oder UI bereitgestellt. Das standardmäßige Befehlszeilentool von Kubernetes heißt kubectl . Falls Sie eine umfassende Liste von kubectl-Befehlen benötigen, sehen Sie sich unser Kubectl-Spickzettel an.
- Kubernetes speichert die Datei (den gewünschten Zustand einer Anwendung) in einer Datenbank namens Key-Value Store (etcd) .
- Kubernetes implementiert dann den gewünschten Zustand in allen relevanten Anwendungen innerhalb des Clusters.
- Kubernetes überwacht kontinuierlich die Elemente des Clusters, um sicherzustellen, dass der aktuelle Zustand der Anwendung nicht vom gewünschten Zustand abweicht.
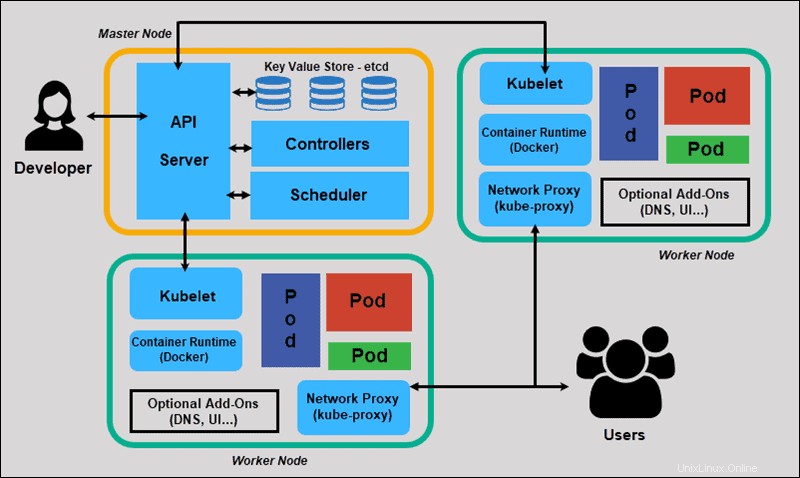
Wir werden nun die einzelnen Komponenten eines standardmäßigen Kubernetes-Clusters untersuchen, um den Prozess genauer zu verstehen.
Was ist ein Master-Knoten in der Kubernetes-Architektur?
Der Kubernetes-Master (Master-Knoten) erhält Eingaben von einer CLI (Command-Line Interface) oder UI (User Interface) über eine API. Dies sind die Befehle, die Sie Kubernetes bereitstellen.
Sie definieren Pods, Replikatsätze und Dienste, die Kubernetes verwalten soll. Zum Beispiel, welches Container-Image verwendet werden soll, welche Ports verfügbar gemacht werden sollen und wie viele Pod-Replikate ausgeführt werden sollen.
Sie geben auch die Parameter des gewünschten Zustands für die Anwendung(en) an, die in diesem Cluster ausgeführt werden.
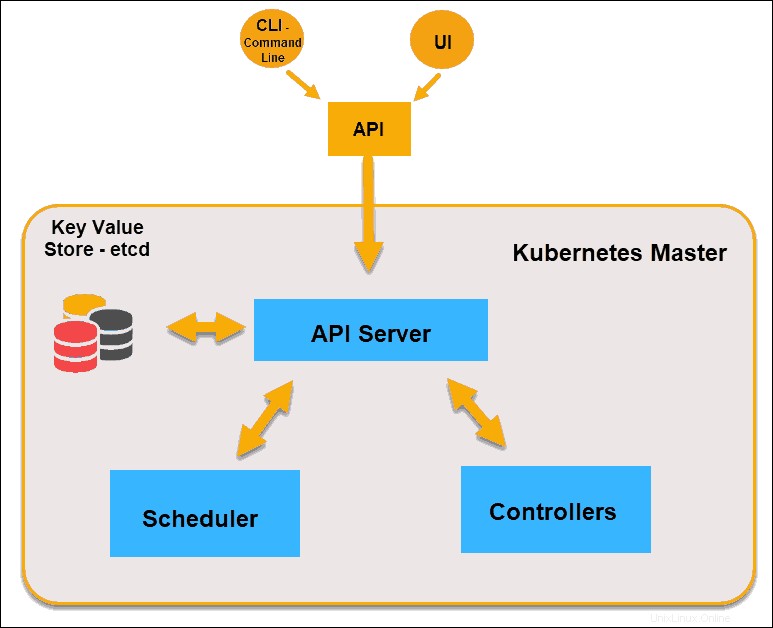
Kubernetes-Masterknoten
API-Server
Der API-Server ist das Front-End der Steuerungsebene und die einzige Komponente in der Steuerungsebene, mit der wir direkt interagieren. Interne Systemkomponenten sowie externe Benutzerkomponenten kommunizieren alle über dieselbe API.
Schlüsselwertspeicher (usw.)
Der Key-Value Store, auch etcd genannt , ist eine Datenbank, die Kubernetes verwendet, um alle Clusterdaten zu sichern. Es speichert die gesamte Konfiguration und den Status des Clusters. Der Master-Knoten fragt etcd ab zum Abrufen von Parametern für den Zustand der Knoten, Pods und Container.
Verantwortlicher
Die Rolle des Controllers ist es, den gewünschten Zustand vom API-Server zu erhalten. Es überprüft den aktuellen Status der Knoten, die es steuern soll, und stellt fest, ob es Unterschiede gibt, und behebt sie, falls vorhanden.
Scheduler
Ein Scheduler sucht nach neuen Anfragen, die vom API-Server kommen, und weist sie fehlerfreien Knoten zu. Es stuft die Qualität der Knoten ein und stellt Pods auf dem am besten geeigneten Knoten bereit. Wenn es keine geeigneten Knoten gibt, werden die Pods in einen ausstehenden Zustand versetzt, bis ein solcher Knoten erscheint.
Was ist der Worker-Knoten in der Kubernetes-Architektur?
Worker-Knoten hören auf den API-Server auf neue Arbeitszuweisungen; Sie führen die Arbeitsaufträge aus und melden die Ergebnisse dann an den Kubernetes-Master-Knoten zurück.
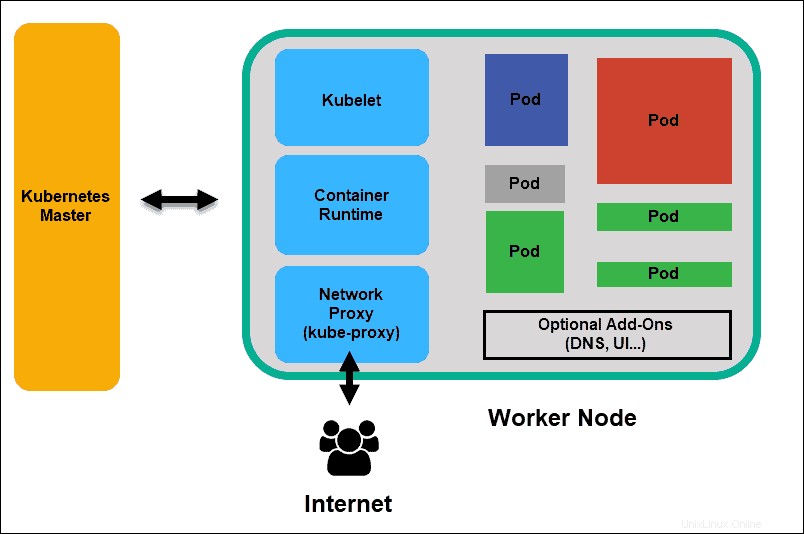
Kubernetes-Worker-Knoten
Kubelet
Das kubelet läuft auf jedem Knoten im Cluster. Es ist der Hauptagent von Kubernetes. Durch die Installation von Kubelet werden CPU, RAM und Speicher des Knotens Teil des breiteren Clusters. Er überwacht Aufgaben, die vom API-Server gesendet werden, führt die Aufgabe aus und meldet sich beim Master zurück. Es überwacht auch Pods und meldet an das Kontrollpanel zurück, wenn ein Pod nicht voll funktionsfähig ist. Basierend auf diesen Informationen kann der Master dann entscheiden, wie er Aufgaben und Ressourcen zuweist, um den gewünschten Zustand zu erreichen.
Containerlaufzeit
Die Containerlaufzeit ruft Images aus einer Container-Image-Registrierung ab und startet und stoppt Container. Diese Funktion wird normalerweise von einer Software oder einem Plugin eines Drittanbieters wie Docker ausgeführt.
Kube-Proxy
Der kube-proxy stellt sicher, dass jeder Knoten seine IP-Adresse erhält, implementiert lokale iptables und Regeln für Routing und Traffic-Lastenausgleich.
Pod
Ein Pod ist das kleinste Planungselement in Kubernetes. Ohne sie kann ein Container nicht Teil eines Clusters sein. Wenn Sie Ihre App skalieren müssen, können Sie dies nur tun, indem Sie Pods hinzufügen oder entfernen.
Der Pod dient als „Wrapper“ für einen einzelnen Container mit dem Anwendungscode. Basierend auf der Verfügbarkeit von Ressourcen plant der Master den Pod auf einem bestimmten Knoten und stimmt sich mit der Containerlaufzeit ab, um den Container zu starten.
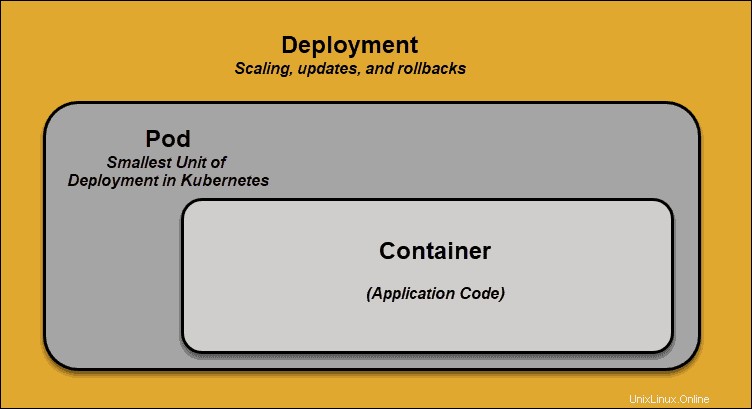
In Fällen, in denen Pods ihre Aufgaben unerwartet nicht erfüllen, versucht Kubernetes nicht, sie zu beheben. Stattdessen erstellt und startet er an seiner Stelle einen neuen Pod. Dieser neue Pod ist mit Ausnahme der DNS- und IP-Adresse eine Nachbildung. Diese Funktion hatte einen tiefgreifenden Einfluss darauf, wie Entwickler Anwendungen entwerfen.
Aufgrund der Flexibilität der Kubernetes-Architektur müssen Anwendungen nicht mehr an eine bestimmte Instanz eines Pods gebunden sein. Stattdessen müssen Anwendungen so gestaltet werden, dass ein völlig neuer Pod, der irgendwo innerhalb des Clusters erstellt wird, nahtlos an seine Stelle treten kann. Um diesen Prozess zu unterstützen, verwendet Kubernetes Dienste .
Kubernetes-Dienste
Pods sind nicht konstant. Eine der besten Funktionen von Kubernetes ist, dass nicht funktionierende Pods automatisch durch neue ersetzt werden.
Diese neuen Pods haben jedoch einen anderen Satz von IPs. Dies kann zu Verarbeitungsproblemen und IP-Abwanderung führen, da die IPs nicht mehr übereinstimmen. Unbeaufsichtigt würde diese Eigenschaft Pods höchst unzuverlässig machen.
Dienste werden eingeführt, um zuverlässige Netzwerke bereitzustellen, indem stabile IP-Adressen und DNS-Namen in die instabile Welt der Pods gebracht werden.
Durch die Steuerung des zum Pod ein- und ausgehenden Datenverkehrs stellt ein Kubernetes-Dienst einen stabilen Netzwerkendpunkt bereit – eine feste IP, DNS und einen Port. Über einen Dienst kann jeder Pod hinzugefügt oder entfernt werden, ohne befürchten zu müssen, dass sich grundlegende Netzwerkinformationen in irgendeiner Weise ändern.
Wie funktionieren Kubernetes-Dienste?
Pods werden Diensten durch Schlüssel/Wert-Paare zugeordnet, die als Labels bezeichnet werden und Selektoren . Ein Dienst erkennt automatisch einen neuen Pod mit Labels, die dem Selektor entsprechen.
Dieser Prozess fügt dem Dienst nahtlos neue Pods hinzu und entfernt gleichzeitig beendete Pods aus dem Cluster.
Zum Beispiel, wenn der gewünschte Zustand drei Replikate eines Pods enthält und ein Knoten, auf dem ein Replikat ausgeführt wird, schlägt fehl , wird der aktuelle Zustand auf zwei Pods reduziert. Kubernetes-Beobachter, dass der gewünschte Zustand drei Pods sind. Es wird dann ein neues Replikat geplant den Platz des ausgefallenen Pods einzunehmen und weist ihn einem anderen Knoten im Cluster zu.
Das Gleiche würde beim Aktualisieren oder Skalieren der Anwendung durch Hinzufügen oder Entfernen von Pods gelten. Sobald wir den gewünschten Zustand aktualisiert haben, bemerkt Kubernetes die Diskrepanz und fügt Pods hinzu oder entfernt sie, um mit der Manifestdatei übereinzustimmen. Das Kubernetes Control Panel zeichnet, implementiert und führt Hintergrundabgleichsschleifen aus, die kontinuierlich prüfen, ob die Umgebung benutzerdefinierten Anforderungen entspricht.
Was ist Containerbereitstellung?
Um vollständig zu verstehen, wie und was Kubernetes orchestriert, müssen wir uns mit dem Konzept der Containerbereitstellung befassen .
Traditionelle Bereitstellung
Anfänglich stellten Entwickler Anwendungen auf einzelnen physischen Servern bereit. Diese Art der Bereitstellung brachte mehrere Herausforderungen mit sich. Die gemeinsame Nutzung physischer Ressourcen bedeutete, dass eine Anwendung den größten Teil der Verarbeitungsleistung beanspruchen konnte, wodurch die Leistung anderer Anwendungen auf demselben Computer eingeschränkt wurde.
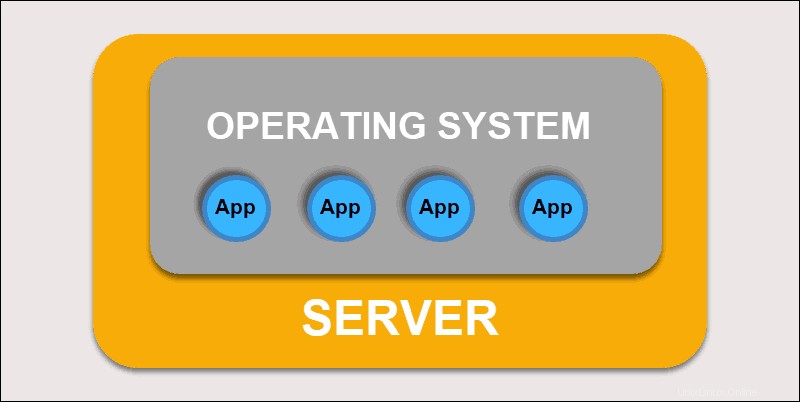
Herkömmliche Bereitstellung
Die Erweiterung der Hardwarekapazität dauert lange, was wiederum die Kosten erhöht. Um Hardwareeinschränkungen zu beheben, begannen Unternehmen mit der Virtualisierung physischer Maschinen.
Virtualisierte Bereitstellung
Die virtualisierte Bereitstellung ermöglicht Ihnen die Erstellung isolierter virtueller Umgebungen, Virtual Machines (VM) , auf einem einzelnen physischen Server. Diese Lösung isoliert Anwendungen innerhalb einer VM, begrenzt die Ressourcennutzung und erhöht die Sicherheit. Eine Anwendung kann nicht mehr frei auf die von einer anderen Anwendung verarbeiteten Informationen zugreifen.
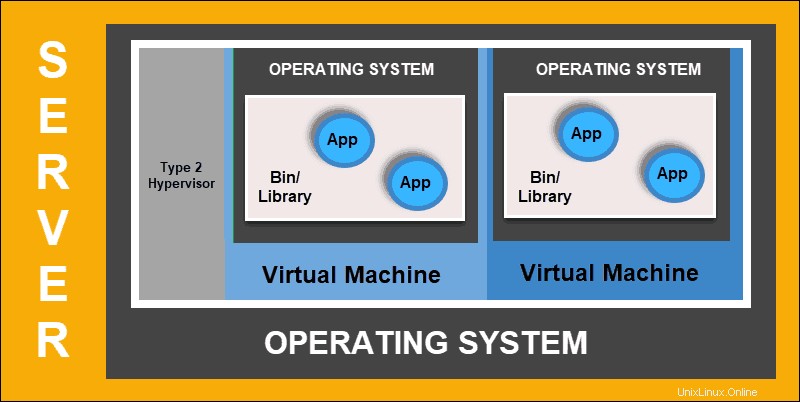
Virtualisierte Bereitstellung
Mit virtualisierten Bereitstellungen können Sie schnell skalieren und die Ressourcen eines einzelnen physischen Servers verteilen, nach Belieben aktualisieren und die Hardwarekosten unter Kontrolle halten. Jede VM hat ihr eigenes Betriebssystem und kann alle notwendigen Systeme auf der virtualisierten Hardware ausführen.
Container-Bereitstellung
Die Bereitstellung von Containern ist der nächste Schritt auf dem Weg zu einem flexibleren und effizienteren Modell. Ähnlich wie VMs verfügen Container über individuellen Arbeitsspeicher, Systemdateien und Verarbeitungsspeicher. Die strikte Isolation ist jedoch kein limitierender Faktor mehr.
Mehrere Anwendungen können jetzt dasselbe zugrunde liegende Betriebssystem verwenden. Diese Funktion macht Container viel effizienter als vollwertige VMs. Sie sind über Clouds, verschiedene Geräte und fast jede OS-Distribution hinweg portierbar.
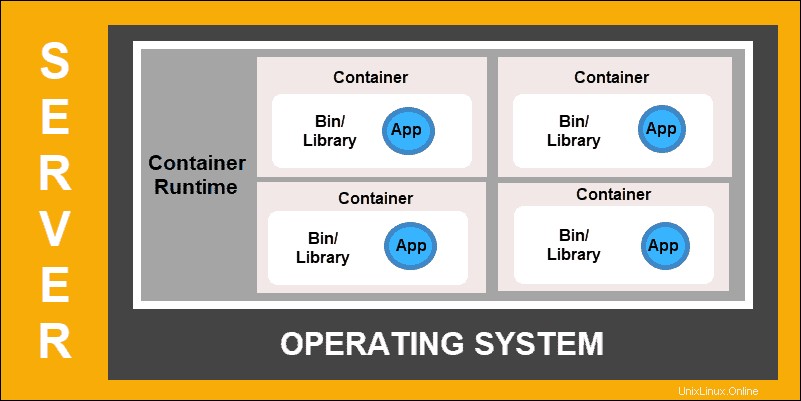
Container-Bereitstellung
Die Containerstruktur ermöglicht auch, dass Anwendungen als kleinere, unabhängige Teile ausgeführt werden. Diese Teile können dann dynamisch auf mehreren Maschinen bereitgestellt und verwaltet werden. Die aufwändige Struktur und die Segmentierung der Aufgaben sind zu komplex, um sie manuell zu verwalten.
Eine Automatisierungslösung wie Kubernetes ist erforderlich, um alle an diesem Prozess beteiligten beweglichen Teile effektiv zu verwalten.