
In diesem Tutorial zeigen wir Ihnen, wie Sie Apache Hadoop auf Ubuntu 20.04 LTS installieren. Für diejenigen unter Ihnen, die es nicht wussten, Apache Hadoop ist ein Open-Source-Framework, das für verteilte Speicherung verwendet wird sowie die verteilte Verarbeitung von Big Data auf Clustern von Computern, die auf handelsüblicher Hardware ausgeführt werden.Anstatt sich auf Hardware zu verlassen, um Hochverfügbarkeit bereitzustellen, ist die Bibliothek selbst darauf ausgelegt, Fehler auf der Anwendungsebene zu erkennen und zu handhaben und so einen hochverfügbaren Dienst bereitzustellen auf einem Cluster von Computern, von denen jeder fehleranfällig sein kann.
Dieser Artikel geht davon aus, dass Sie zumindest über Grundkenntnisse in Linux verfügen, wissen, wie man die Shell verwendet, und vor allem, dass Sie Ihre Website auf Ihrem eigenen VPS hosten. Die Installation ist recht einfach und setzt Sie voraus im Root-Konto ausgeführt werden, wenn nicht, müssen Sie möglicherweise 'sudo hinzufügen ‘ zu den Befehlen, um Root-Rechte zu erhalten. Ich zeige Ihnen Schritt für Schritt die Installation von Flask auf Ubuntu 20.04 (Focal Fossa). Sie können denselben Anweisungen für Ubuntu 18.04, 16.04 und jede andere Debian-basierte Distribution wie Linux Mint folgen.
Voraussetzungen
- Ein Server, auf dem eines der folgenden Betriebssysteme ausgeführt wird:Ubuntu 20.04, 18.04, 16.04 und jede andere Debian-basierte Distribution wie Linux Mint.
- Es wird empfohlen, dass Sie eine neue Betriebssysteminstallation verwenden, um potenziellen Problemen vorzubeugen.
- SSH-Zugriff auf den Server (oder öffnen Sie einfach das Terminal, wenn Sie sich auf einem Desktop befinden).
- Ein
non-root sudo useroder Zugriff auf denroot user. Wir empfehlen, alsnon-root sudo userzu agieren , da Sie Ihr System beschädigen können, wenn Sie als Root nicht aufpassen.
Installieren Sie Apache Hadoop auf Ubuntu 20.04 LTS Focal Fossa
Schritt 1. Stellen Sie zunächst sicher, dass alle Ihre Systempakete auf dem neuesten Stand sind, indem Sie den folgenden apt ausführen Befehle im Terminal.
sudo apt update sudo apt upgrade
Schritt 2. Java installieren.
Um Hadoop auszuführen, muss Java 8 auf Ihrem Computer installiert sein. Verwenden Sie dazu den folgenden Befehl:
sudo apt install default-jdk default-jre
Nach der Installation können Sie die installierte Version von Java mit dem folgenden Befehl überprüfen:
java -version
Schritt 3. Hadoop-Benutzer erstellen.
Erstellen Sie zuerst einen neuen Benutzer namens Hadoop mit dem folgenden Befehl:
sudo addgroup hadoopgroup sudo adduser —ingroup hadoopgroup hadoopuser
Melden Sie sich als Nächstes mit einem Hadoop-Benutzer an und generieren Sie mit dem folgenden Befehl ein SSH-Schlüsselpaar:
su - hadoopuser ssh-keygen -t rsa cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys chmod 0600 ~/.ssh/authorized_keys
Verifizieren Sie danach das passwortlose SSH mit dem folgenden Befehl:
ssh localhost
Sobald Sie sich ohne Passwort angemeldet haben, können Sie mit dem nächsten Schritt fortfahren.
Schritt 4. Installieren von Apache Hadoop auf Ubuntu 20.04.
Nun laden wir die neueste stabile Version von Apache Hadoop herunter, zum Zeitpunkt des Schreibens dieses Artikels ist es Version 3.3.0:
su - hadoop wget https://downloads.apache.org/hadoop/common/hadoop-3.3.0/hadoop-3.3.0.tar.gz tar -xvzf hadoop-3.3.0.tar.gz
Als nächstes verschieben Sie das extrahierte Verzeichnis nach /usr/local/ :
sudo mv hadoop-3.3.0 /usr/local/hadoop sudo mkdir /usr/local/hadoop/logs
Wir ändern den Besitz des Hadoop-Verzeichnisses auf Hadoop:
sudo chown -R hadoop:hadoop /usr/local/hadoop
Schritt 5. Konfigurieren Sie Apache Hadoop.
Einrichten der Umgebungsvariablen. Bearbeiten Sie ~/.bashrc die Datei und hängen Sie die folgenden Werte am Ende der Datei an:
nano ~/.bashrc
Fügen Sie die folgenden Zeilen hinzu:
export HADOOP_HOME=/usr/local/hadoop export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
Umgebungsvariablen auf die aktuell laufende Sitzung anwenden:
source ~/.bashrc
Als nächstes müssen Sie Java-Umgebungsvariablen in hadoop-env.sh definieren So konfigurieren Sie YARN-, HDFS-, MapReduce- und Hadoop-bezogene Projekteinstellungen:
sudo nano $HADOOP_HOME/etc/hadoop/hadoop-env.sh
Fügen Sie die folgenden Zeilen hinzu:
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64 export HADOOP_CLASSPATH+=" $HADOOP_HOME/lib/*.jar"
Sie können jetzt die Hadoop-Version mit dem folgenden Befehl überprüfen:
hadoop version
Schritt 6. Konfigurieren Sie core-site.xml Datei.
Öffnen Sie die core-site.xml Datei in einem Texteditor:
sudo nano $HADOOP_HOME/etc/hadoop/core-site.xml
Fügen Sie die folgenden Zeilen hinzu:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://0.0.0.0:9000</value>
<description>The default file system URI</description>
</property>
</configuration>
Schritt 7. Konfigurieren Sie hdfs-site.xml Datei.
Verwenden Sie den folgenden Befehl, um die hdfs-site.xml zu öffnen Datei zum Bearbeiten:
sudo nano $HADOOP_HOME/etc/hadoop/hdfs-site.xml
Fügen Sie die folgenden Zeilen hinzu:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hdfs/datanode</value>
</property>
</configuration>
Schritt 8. Konfigurieren Sie mapred-site.xml Datei.
Verwenden Sie den folgenden Befehl, um auf die mapred-site.xml zuzugreifen Datei:
sudo nano $HADOOP_HOME/etc/hadoop/mapred-site.xml
Fügen Sie die folgenden Zeilen hinzu:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
Schritt 9. Konfigurieren Sie yarn-site.xml Datei.
Öffnen Sie die yarn-site.xml Datei in einem Texteditor:
sudo nano $HADOOP_HOME/etc/hadoop/yarn-site.xml
Fügen Sie die folgenden Zeilen hinzu:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration> Schritt 10. HDFS NameNode formatieren.
Nun melden wir uns mit einem Hadoop-Benutzer an und formatieren den HDFS NameNode mit folgendem Befehl:
su - hadoop hdfs namenode -format
Schritt 11. Starten Sie den Hadoop-Cluster.
Starten Sie nun den NameNode und den DataNode mit folgendem Befehl:
start-dfs.sh
Starten Sie dann die YARN-Ressourcen- und Knotenmanager:
start-yarn.sh
Sie sollten die Ausgabe beobachten, um sicherzustellen, dass versucht wird, Datanode nacheinander auf Slave-Knoten zu starten. Um zu überprüfen, ob alle Dienste ordnungsgemäß gestartet wurden, verwenden Sie 'jps ‘Befehl:
jps
Schritt 12. Zugriff auf Apache Hadoop.
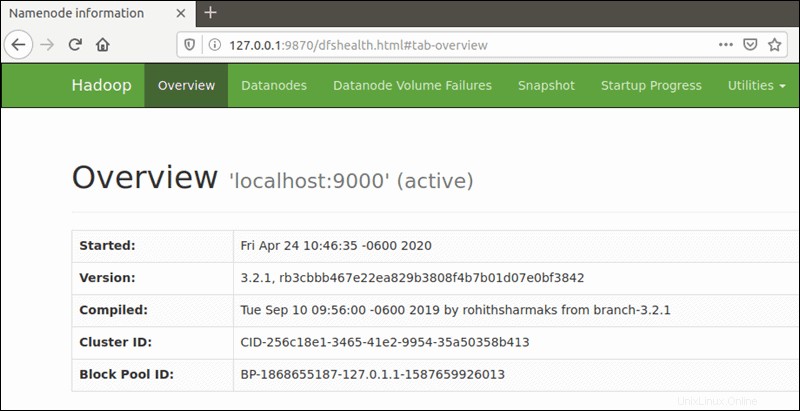
Die standardmäßige Portnummer 9870 ermöglicht Ihnen den Zugriff auf die Hadoop NameNode-Benutzeroberfläche:
http://your-server-ip:9870
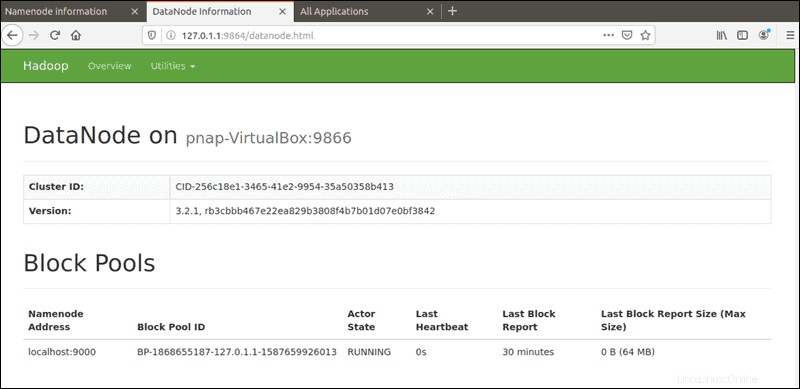
Der Standardport 9864 wird verwendet, um direkt von Ihrem Browser aus auf einzelne DataNodes zuzugreifen:
http://your-server-ip:9864
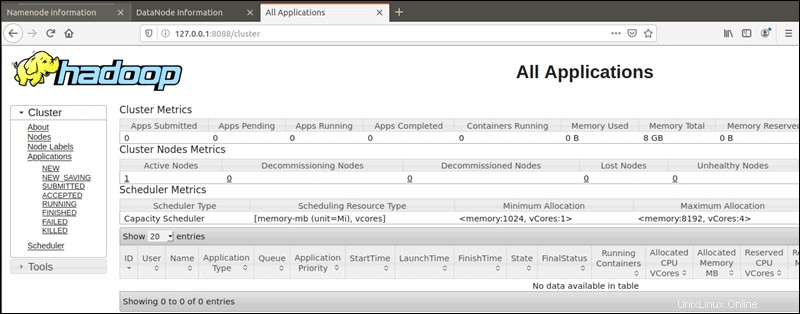
Der YARN-Ressourcenmanager ist über Port 8088 erreichbar:
http://your-server-ip:8088
Herzlichen Glückwunsch! Sie haben Hadoop erfolgreich installiert. Vielen Dank, dass Sie dieses Tutorial zur Installation von Apache Hadoop auf Ihrem Ubuntu 20.04 LTS Focal Fossa-System verwendet haben. Für zusätzliche Hilfe oder nützliche Informationen empfehlen wir Ihnen, die offizielle Apache Hadoop-Website.