Einführung
Datenbanken sind eine organisierte Sammlung zusammenhängender Datensätze. Datenbankverwaltungssysteme verwalten und manipulieren Informationen innerhalb einer Datenbank.
Es gibt viele verschiedene Ansätze zum Speichern und Modellieren von Daten, was zu verschiedenen Arten von Datenbanken führt.
Dieser Artikel bietet einen detaillierten Überblick über die verschiedenen verfügbaren Datenbanktypen.

Datenbanktypen
Es gibt viele verschiedene Ansätze zur Analyse der verschiedenen verfügbaren Datenbanktypen. Die folgende Tabelle gibt einen allgemeinen Überblick über die verschiedenen derzeit verfügbaren Typen:
| Basierend auf | Datenbanktypen |
|---|---|
| Modell | Relational Nicht relational (NoSQL) Objektorientiert |
| Standort | Zentralisiert Verteilt |
| Design | Betrieb (OLTP) Analytisch (OLAP) |
| Hosting | Lokal Wolke |
| Verarbeitung Macht | Persönlich Kommerziell |
Die verschiedenen Datenbanktypen werden kombiniert, um eine spezifische Umgebung zu schaffen. Beispielsweise beschreibt eine nicht-relationale verteilte kommerzielle Datenbank jeweils das Modell, den Ort und die Verarbeitung der Datenbank.
Datenbankmodelltypen
Die drei allgemeinen Datenbanktypen, die auf dem Modell basieren, sind:
1. Relationale Datenbank
2. Nicht relationale Datenbank (NoSQL)
3. Objektorientierte Datenbank
Der Unterschied zwischen den Modellen besteht darin, wie die Informationen in der Datenbank aussehen. Folglich hat jeder Modelltyp ein anderes Verwaltungssystem und andere Datenbeziehungen.
Relationale Datenbank
Die relationale Datenbank model ist der am weitesten verbreitete und zugleich älteste Datenbanktyp. Die drei entscheidenden Komponenten einer relationalen Datenbank sind:
- Tabellen . Ein Entitätstyp mit Beziehungen.
- Zeilen . Datensätze oder Instanzen eines Entitätstyps.
- Spalten . Wertattribute von Instanzen.
Eine relationale Datenbank stellt als Antwort auf eine Abfrage eine Reihe von Datenzeilen bereit . Eine Abfragesprache, am häufigsten die Structured Query Language oder SQL , hilft beim Erstellen dieser Datenansichten.
Relationale Datenbankfunktionen
Die Hauptmerkmale einer relationalen Datenbank sind:
- ACID-konform . Die Datenbank trainiert die Integrität neu, während sie Transaktionen durchführt.
- Bereich der Datentypen . Bietet die Möglichkeit, beliebige Daten zu speichern und komplexe Abfragen durchzuführen.
- Kooperation . Mehrere Benutzer können auf die Datenbank zugreifen und am selben Projekt arbeiten.
- Sicher . Der Zugriff ist durch Benutzerberechtigungen eingeschränkt oder eingeschränkt.
- Stabil . Relationale Datenbanken sind gut verstanden und dokumentiert.
Wofür werden relationale Datenbanken verwendet?
Relationale Datenbanken sind der am häufigsten implementierte Datenbanktyp. Es gibt viele Anwendungsfälle, darunter einige:
- Online-Transaktionssysteme . Die Datenbank unterstützt viele Benutzer sowie häufige Abfragen, die bei Online-Transaktionen erforderlich sind.
- IoT . Relationale Datenbanken sind leichtgewichtig und haben die Rechenleistung, die für Edge-Computing benötigt wird.
- Data Warehouses . Die kritische Komponente der Data-Warehouse-Architektur ist der Speicher. Relationale Datenbanken lassen sich leicht integrieren und für massive Abfragen aus mehreren Quellen optimieren.
Beliebteste relationale Datenbanken
Es gibt unzählige kommerzielle sowie Open-Source-Datenbanken. Die zehn beliebtesten relationalen Datenbanken sind:
1. Orakel
2. MySQL
3. Microsoft SQL-Server
4. PostgreSQL
5. IBM Db2
6. SQLite
7. Microsoft Access
8. MariaDB
9. Bienenstock
10. Microsoft Azure SQL-Datenbank
Nicht relationale Datenbank (NoSQL-Datenbank)
Eine nicht relationale Datenbank , oder NoSQL ("Not Only SQL"), ist ein Datenbanktyp, der Daten anders modelliert und speichert als relationale Datenbanken. Anstelle von Tabellen modellieren nicht-relationale Datenbanken Beziehungen zwischen Daten auf alternative Weise.
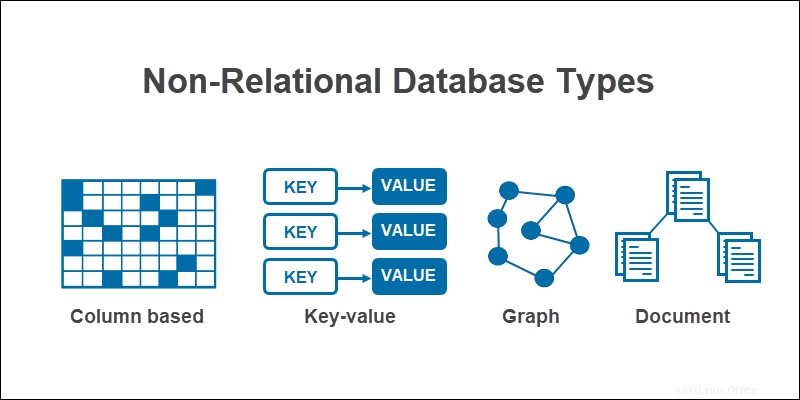
Die 4 NoSQL-Datenbanktypen sind:
- Dokument
- Schlüsselwert
- Spaltenbasiert
- Grafik
Nicht relationale Datenbankfunktionen
Die Hauptmerkmale von nicht-relationalen Datenbanken sind:
- Flexibel . Der Umgang mit strukturierten, halbstrukturierten und unstrukturierten Daten ist mit nicht-relationalen Datenbanktypen ein Kinderspiel.
- Skalierbar und reaktionsschnell . Riesiger Datenspeicher lässt sich gut mit On-Demand-Servern skalieren und bietet schnelle Antworten auf Abfragen.
- Keine Ausfallzeit. Hohe Verfügbarkeit für minimale Ausfallzeiten durch Datenreplikation nahezu in Echtzeit.
- Cloud-kompatibel . Die Skalierbarkeit einer Cloud-Computing-Architektur fügt sich perfekt in nicht-relationale Datenbanken ein.
- Mehrere Datenstrukturen . Es stehen verschiedene Informationstypen sowie Datenbankformate mit mehreren Modellen zur Verfügung.
Wofür werden nicht-relationale Datenbanken verwendet?
Nicht relationale Datenbanken funktionieren am besten mit variablen Datenstrukturen und riesigen Datenmengen. Einige Anwendungsfälle umfassen:
- Echtzeitsysteme . Eine nicht-relationale Datenbank kombiniert die operativen und analytischen Datenbanksysteme in einem. Unabhängig davon, ob Sie Betriebsdaten in Hadoop einspeisen oder Analyseergebnisse aus Hadoop bereitstellen, nicht relationale Datenbanken bieten die agile Echtzeiterfahrung.
- Personalisierte Erfahrung . Die elastische Skalierung bewältigt die enormen Datenmengen, die für jede individuelle Erfahrung benötigt werden.
- Betrugserkennung . Hohe Leistung ist bei der Betrugserkennung von entscheidender Bedeutung. Nicht-relationale Datenbanken sind reaktionsschnell und erfüllen zuverlässig die Anforderungen von Finanzsystemen mit geringer Latenz.
Beliebteste nicht-relationale Datenbanken
Die zehn beliebtesten nicht-relationalen Datenbanken sind:
1. MongoDB
2. Redis
3. Kassandra
4. HBase
5. Neo4j
6. Oracle NoSQL
7. RavenDB
8. Riak
9. OrientDB
10. CouchDB
Objektdatenbank
Eine Objektdatenbank stellt in ähnlicher Weise Daten für Objekte in der objektorientierten Programmierung dar. Die kritischen Komponenten einer objektorientierten Datenbank sind:
- Objekte . Die Grundbausteine zum Speichern von Informationen.
- Klassen. Das Schema oder die Blaupause für ein Objekt.
- Methoden . Strukturiertes Verhalten einer Klasse.
- Hinweise. Greifen Sie auf Elemente einer Datenbank zu und stellen Sie Beziehungen zwischen Objekten her.
Objektdatenbanken kombinieren objektorientierte Programmierkonzepte mit Datenbankfähigkeiten.
Objektdatenbankfunktionen
Die Hauptmerkmale von Objektdatenbanken sind:
- ACID-Transaktionen . Alle Transaktionen sind aufgrund der ACID-Konformität ohne widersprüchliche Änderungen abgeschlossen.
- Transparente Persistenz . Objektdatenbanken lassen sich nahtlos in objektorientierte Programmiersprachen integrieren.
- Komplexe und benutzerdefinierte Datentypen. Benutzerdefinierte Klassen ermöglichen sowohl benutzerdefinierte als auch komplexe Datentypen.
- Zugänglich. Daten lassen sich einfach speichern und abrufen.
- Einfachere Modellierung. Reale Probleme und Informationen sind enger mit Objekten verknüpft, was die Modellierung komplexer Probleme erleichtert.
Wofür werden Objektdatenbanken verwendet?
Objektdatenbanken funktionieren am besten mit komplexen Datentypen, bei denen eine Entität eine riesige Menge an Informationen enthält. Einige alltägliche Anwendungsfälle für diesen Datenbankmodelltyp sind:
- Hochleistungsanwendungen . Anwendungen, bei denen ein schneller Datenabruf entscheidend ist, um von Objektdatenbanken zu profitieren, da Daten unverändert gespeichert und abgerufen werden.
- Wissenschaftliche Zwecke . Sowohl wissenschaftliche Daten als auch Berechnungen sind komplex. Die Speicherung komplexer Informationen und der schnelle Abruf finden Anwendung in allen möglichen wissenschaftlichen Disziplinen.
- Komplexe Datenstrukturen . Aufgrund der permanenten Persistenz mit Objekten ist die Datenbankspeicherung und Erweiterung komplexer Daten zugänglich, sodass das Datenbankmodell nicht überarbeitet werden muss.
Beliebteste Objektdatenbanken
Derzeit sind die zehn beliebtesten Objektdatenbanken:
1. DB4o
2. Objektspeicher
3. Matisse
4. Edelstein/S
5. Objektdatenbank
6. Objektdatenbank++
7. Objektivität/DB
8. Versant
9. Letzte
10. Jade
Datenbanktypen basierend auf Standort
Datenbanktypen unterscheiden sich auch basierend auf dem physischen Speicherort.
Die zwei Gruppen basierend auf dem Standort sind:
1. Zentralisierte Datenbanken
2. Verteilte Datenbanken
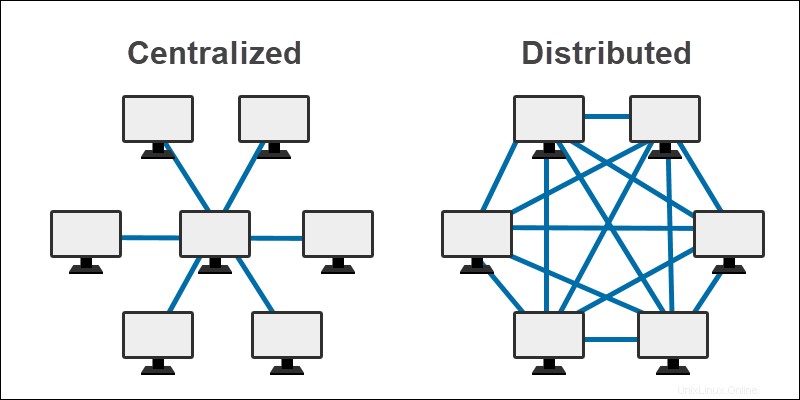
Zentrale Datenbank
Eine zentralisierte Datenbank wird an einem einzigen Ort gespeichert und verwaltet. Die Informationen sind über ein Netzwerk verfügbar. Der Endbenutzer hat über das Netzwerk Zugriff auf den zentralisierten Computer, auf dem sich die gespeicherten Informationen befinden.
Zentralisierte Datenbankfunktionen
Die Hauptmerkmale einer zentralisierten Datenbank sind:
- Datenintegrität . Die Aufbewahrung von Daten an einem Ort maximiert die Datenintegrität und reduziert Redundanzen. Die Genauigkeit und Zuverlässigkeit der Informationen wird verbessert.
- Sicherheit . Ein Single Point of Location bietet nur einen Zugriffspunkt, was zu einer erhöhten Datensicherheit führt.
- Endbenutzerfreundlich . Datenzugriff sowie Aktualisierungen sind mit einer zentralisierten Datenbank sofort möglich. Ein einziges Datenbankdesign sorgt für Einfachheit.
- Kostengünstig . Durch ein zentralisiertes System werden Arbeitsaufwand, Stromversorgung und Wartung auf ein Minimum reduziert. Die Datenbank ist administrativ einfacher zu pflegen.
- Datenerhaltung . Eine fehlertolerante Einrichtung durch Notfallwiederherstellungslösungen.
Wofür werden zentralisierte Datenbanken verwendet?
Die Vorteile einer zentralisierten Datenbank machen sich am deutlichsten bei großen Institutionen bemerkbar. Einige Anwendungsfälle umfassen:
- Unternehmensführung . Große Organisationen nutzen zentrale Datenbanken, um einen besseren Überblick über alle Informationen zu erhalten.
- Regierungsdaten . Zentralisierte Datenbanken sind in Regierungsorganisationen weit verbreitet. Ein Zugangspunkt sorgt für Datensicherheit.
- Schulen und Universitäten . Bildungseinrichtungen nutzen zentralisierte Datenbanken. Die Wartung ist kostengünstig und die Informationen bleiben korrekt.
Verteilte Datenbank
Verteilte Datenbanken speichern Informationen über verschiedene physische Standorte hinweg. Die Datenbank befindet sich auf mehreren CPUs an einem einzigen Standort oder ist über verschiedene Standorte verteilt. Aufgrund der Verbindungen zwischen den verteilten Datenbanken erscheinen die Informationen für Endbenutzer als eine einzige Datenbank.
Verteilte Datenbankfunktionen
Die aufregendsten Merkmale einer verteilten Datenbank sind:
- Standortunabhängigkeit . Der physische Standort der Datenbank erstreckt sich über mehrere Standorte.
- Abfrageverarbeitung Verteilung. Eine komplexe Abfrage teilt sich in mehrere Standorte auf, wodurch die Aufgaben auf verschiedene CPUs verteilt werden, wodurch Engpässe reduziert werden.
- Verteilte Transaktionen . Mehrere Speicherorte bieten eine verteilte Wiederherstellungsmethode. Commit-Protokolle existieren bei zahlreichen Transaktionen.
- Netzwerkverknüpfung . Die verteilten Datenbanken sind über ein Netzwerk miteinander verbunden, in dem die Kommunikation zwischen den Speichern sowie mit den Endbenutzern stattfindet.
- Nahtlose Integration . Obwohl nicht physisch verbunden, verbinden sich verteilte Datenbankteile zu einer logischen Datenbank.
Wofür werden verteilte Datenbanken verwendet?
Verteilte Datenbanken funktionieren am besten in Umgebungen mit vielen Sektoren, in denen Unternehmen die verfügbaren Informationen einschränken sollten, um Redundanzen zu reduzieren. Einige Beispiele sind:
- Große Unternehmen. Die meisten Unternehmensbereiche benötigen keine vollständige Datenübersicht. Verteilte Datenbanken helfen, die Redundanz von Daten mit einzelnen Abteilungen zu reduzieren.
- Globale Unternehmen. Aufgrund der Standortunabhängigkeit passt dieser Datenbanktyp gut zu Unternehmen mit mehreren Standorten.
Datenbanktypen basierend auf Design
Die Gestaltung des Speichers hängt vom Unternehmensziel ab. Es gibt zwei Hauptansätze für das Datenbankdesign basierend auf der Funktion:
1. Operative (transaktionale) Datenbank
2. Analytische Datenbank
Obwohl die Datenbanken einem anderen Zweck dienen, entsteht durch die Integration der beiden zusammen ein Data-Warehouse-System.
Betriebsdatenbank
Eine Betriebsdatenbank verwaltet und steuert die grundlegenden Vorgänge innerhalb eines Unternehmens. Die Datenbank ist als Online-Transaktionsverarbeitung oder OLTP-Datenbank bekannt. Die Daten werden direkt von der Quelle in Echtzeit gesammelt und bieten einen Überblick über die täglichen Transaktionen.
Operationelle Datenbankfunktionen
Operative Datenbanken haben die folgenden Merkmale:
- ACID-konform . Die Wahrung der Genauigkeit und Integrität jeder Transaktion ist für die Datenorganisation erforderlich.
- Schnelle Bearbeitung . Operative Datenbanken erfordern eine schnelle Verarbeitung aufgrund Tausender gleichzeitiger Anfragen.
- Kleiner Speicher . Transaktionsinformationen werden nur vorübergehend gespeichert. Daher dienen operative Datenbanken als Sprungbrett, bevor die Daten archiviert werden.
- Regelmäßige Backups. Das Sammeln und Speichern von Daten erfordert ständige Sicherungen, was die Einhaltung gesetzlicher Vorschriften zu einem wesentlichen Faktor macht.
Analytische Datenbank
Analytische Datenbanken bieten eine einheitliche Ansicht aller Daten, die in einem Unternehmen verfügbar sind. Ein vollständiger Überblick über Informationen innerhalb einer Datenbank ist für die Planung, Berichterstattung und Entscheidungsfindung unerlässlich. Die Datenbank ist als OLAP-Datenbank (Online Analytical Processing) bekannt.
Analytische Datenbankfunktionen
Die Merkmale einer analytischen Datenbank sind:
- Verteilt Arbeitsbelastung. Die Daten stammen aus verschiedenen Betriebssystemen, die über Knoten verteilt sind.
- Mehrdimensional. Unternehmensinformationen gewinnen an Dimensionalität durch Datenaggregation und komplexe Abfragen über Datenbanken hinweg.
- Abfrageleistung. Die Datendenormalisierung verbessert die Abfrageleistung für zeitintensive Aktionen.
- Horizontale Skalierbarkeit. Analytische Datenbanken müssen entsprechend den wachsenden Anforderungen eines Unternehmens skaliert werden.
Datenbanktypen basierend auf dem Hosting
Es gibt mehrere Hosting-Optionen für Datenbanken. Die zwei Orte, an denen sich ein Informationssystem befindet, sind:
1. Lokale Datenbanken
2. Cloud-Datenbanken
Der bemerkenswerte Unterschied zwischen den beiden Optionen ist die Verfügbarkeit von Ressourcen, wenn die Datenbankbereitstellung erfolgt. Weitere Informationen zum Vergleich der beiden Ansätze finden Sie in unserem Artikel:On-Premise vs. Cloud:Welches ist das Richtige für Ihr Unternehmen?
Lokale Datenbank
Eine lokale Datenbank befindet sich im Haus. Die gesamte für den Support benötigte Software, Infrastruktur und Administration ist lokal. Bei großen Unternehmen wächst der Speicher zu einem lokalen Rechenzentrum.
Lokale Datenbankfunktionen
Die bemerkenswerten Funktionen von lokalen Datenbanken sind:
- Sicherheit . Aufgrund der internen Infrastruktur sind lokale Datenbanken die beste Lösung zum Speichern sensibler Informationen.
- Kontrolle . Das Unternehmen hat die vollständige Kontrolle über die verfügbaren Informationen und bietet ein hohes Maß an Regulierung und Datenschutz für die Daten.
- Konformität . Regulatorische Kontrollen wie die HIPAA-Compliance erfordern es, jederzeit den Standort sensibler Daten zu kennen.
Cloud-Datenbank
Eine Cloud-Datenbank ist eine Hosting-Lösung eines Drittanbieters. Die Pay-as-go-Lösung stellt die Datenbank als Service bereit, sodass kein physisches Rechenzentrum eingerichtet werden muss. Der agile Ansatz minimiert die Anfangsinvestitionen, die zum Erwerb von Speicherplatz erforderlich sind, und erweitert sich schnell, wenn mehr Ressourcen benötigt werden.
Cloud-Datenbankfunktionen
Die besten Eigenschaften einer Cloud-Datenbank sind:
- Skalierbarkeit . Cloud-Datenbanken sind flexibel. Das Erhöhen oder Verringern von Ressourcen geht dank Virtualisierung schnell.
- Verwaltungsflexibilität . Der Anbieter verwaltet diesen Datenbanktyp, was wiederum die vom Client benötigte Verwaltung minimiert. Es gibt jedoch auch Möglichkeiten, die Wartung auszulagern.
- Kosten . Mit einer Cloud-Datenbank zahlen Sie nur für das, was Sie brauchen. Die Kosten für Investitionen in technisches Personal sowie für die Wartung werden minimiert.
Datenbanktypen basierend auf Verarbeitungsleistung
Die Datenbankverarbeitung hängt vom Geschäftsmodell ab. Die Wahl der falschen Ebene eines Datenbanksystems wirkt sich auf den Arbeitsablauf einer Organisation und eines Teams aus. Die meisten Datenbankanbieter bieten mehrere Lösungen für die Datenbankverarbeitung an. Die beiden wichtigsten sind:
1. Persönliche Datenbank
2. Handelsdatenbank
Unternehmen nutzen je nach Anwendungsfall die Leistungsfähigkeit beider.
Persönliche Datenbank
Persönliche Datenbanken haben Einzelbenutzerzugriff und werden auf Maschinen mit geringer bis mittlerer Leistung verarbeitet. Einfachere Datenbankanwendungen profitieren von diesem Datenbanktyp aufgrund der geringen Kosten und Wartung.
Handelsdatenbank
Eine kommerzielle Datenbank hat mehrere Benutzer mit unterschiedlichen Berechtigungen sowie zahlreiche Anwendungen auf leistungsstarken Maschinen. Hochverfügbare kommerzielle Datenbanken sind kostspielig und erfordern ständige Wartung sowie Support.