Einführung
In der Hive-Terminologie sind externe Tabellen Tabellen, die nicht mit Hive verwaltet werden. Ihr Zweck besteht darin, den Import von Daten aus einer externen Datei in den Metastore zu erleichtern.
Die externen Tabellendaten werden extern gespeichert, während der Hive-Metastore nur das Metadatenschema enthält. Folglich wirkt sich das Löschen einer externen Tabelle nicht auf die Daten aus.
In diesem Tutorial erfahren Sie, wie Sie eine externe Tabelle in Hive erstellen, abfragen und löschen.

Voraussetzungen
- Ubuntu 18.04 LTS oder höher
- Zugriff auf die Befehlszeile mit sudo-Berechtigungen
- Apache Hadoop installiert und ausgeführt
- Apache Hive installiert und ausgeführt
Hinweis: Dieses Tutorial verwendet Ubuntu 20.04. Hive funktioniert jedoch auf allen Betriebssystemen gleich. Das bedeutet, dass der Prozess des Erstellens, Abfragens und Löschens externer Tabellen auf Hive unter Windows, Mac OS, anderen Linux-Distributionen usw. angewendet werden kann.
Erstellen einer externen Tabelle in Hive – Erklärung der Syntax
Beim Erstellen einer externen Tabelle in Hive müssen Sie die folgenden Informationen angeben:
- Name der Tabelle – Die
create external tableBefehl erstellt die Tabelle. Existiert bereits eine gleichnamige Tabelle im System, führt dies zu einem Fehler. Um dies zu vermeiden, fügen Sieif not existshinzu zur Aussage. Bei Tabellennamen wird die Groß- und Kleinschreibung nicht beachtet. - Spaltennamen und -typen – Genau wie Tabellennamen wird bei Spaltennamen zwischen Groß- und Kleinschreibung unterschieden. Spaltentypen sind Werte wie
int,char,stringusw. - Zeilenformat – Zeilen verwenden native oder benutzerdefinierte SerDe-Formate (Serializer/Deserializer). Natives SerDe wird verwendet, wenn das Zeilenformat nicht definiert oder als getrennt angegeben ist.
- Feldabschlusszeichen – Dies ist ein
charTypzeichen, das Tabellenwerte in einer Zeile trennt. - Speicherformat – Sie können Speicherformate wie Textdatei, Sequenzdatei, JSON-Datei usw. angeben
- Standort – Dies ist der HDFS-Verzeichnisspeicherort der Datei, die die Tabellendaten enthält.
Die korrekte Syntax zum Bereitstellen dieser Informationen an Hive lautet:
create external table if not exists [external-table-name] (
[column1-name] [column1-type], [column2-name] [column2-type], …)
comment '[comment]'
row format [format-type]
fields terminated by '[termination-character]'
stored as [storage-type]
location '[location]';Externe Hive-Tabelle erstellen – Beispiel
Als praktisches Beispiel zeigt Ihnen dieses Tutorial, wie Sie Daten aus einer CSV-Datei in eine externe Tabelle importieren.
Schritt 1:Bereiten Sie die Datendatei vor
1. Erstellen Sie eine CSV-Datei mit dem Titel „countries.csv“:
sudo nano countries.csv2. Schreiben Sie für jedes Land in der Liste eine Zeilennummer, den Namen des Landes, seine Hauptstadt und seine Einwohnerzahl in Millionen:
1,USA,Washington,328
2,France,Paris,67
3,Spain,Madrid,47
4,Russia,Moscow,145
5,Indonesia,Jakarta,267
6,Nigeria,Abuja,196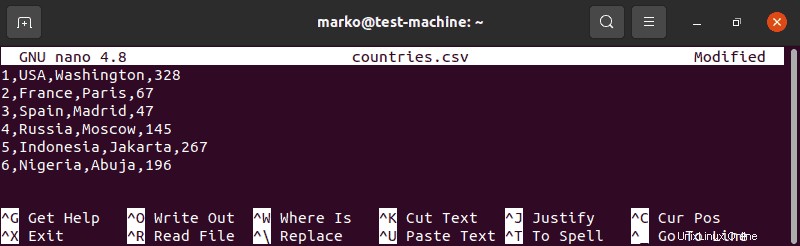
3. Speichern Sie die Datei und notieren Sie sich ihren Speicherort.
Schritt 2:Datei in HDFS importieren
1. Erstellen Sie ein HDFS-Verzeichnis. Sie verwenden dieses Verzeichnis als HDFS-Speicherort für die von Ihnen erstellte Datei.
hdfs dfs -mkdir [hdfs-directory-name]2. Importieren Sie die CSV-Datei in HDFS:
hdfs dfs -put [original-file-location] [hdfs-directory-name]
3. Verwenden Sie -ls Befehl, um zu überprüfen, ob sich die Datei im HDFS-Ordner befindet:
hdfs dfs -ls [hdfs-directory-name]
Die Ausgabe zeigt alle Dateien an, die sich derzeit im Verzeichnis befinden.
Hinweis: Weitere Informationen zu HDFS finden Sie unter Was ist HDFS? Handbuch für verteilte Hadoop-Dateisysteme.
Schritt 3:Erstellen Sie eine externe Tabelle
1. Nachdem Sie die Datendatei in HDFS importiert haben, starten Sie Hive und verwenden Sie die oben erläuterte Syntax, um eine externe Tabelle zu erstellen.
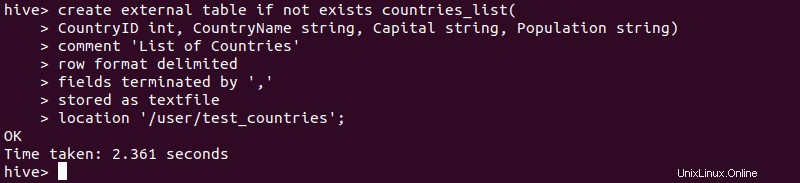
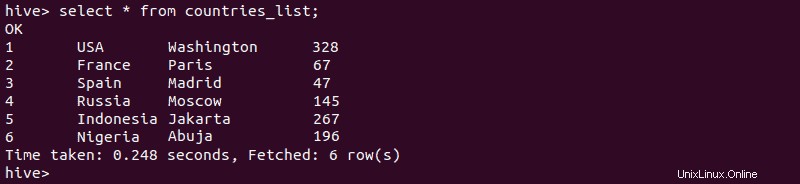
2. Geben Sie Folgendes ein, um zu überprüfen, ob die Erstellung der externen Tabelle erfolgreich war:
select * from [external-table-name];Die Ausgabe sollte die Daten aus der CSV-Datei auflisten, die Sie in die Tabelle importiert haben:
3. Wenn Sie eine verwaltete Tabelle mit den Daten einer externen Tabelle erstellen möchten, geben Sie Folgendes ein:
create table if not exists [managed-table-name](
[column1-name] [column1-type], [column2-name] [var2-name], …)
comment '[comment]';
4. Importieren Sie als Nächstes die Daten aus der externen Tabelle:
insert overwrite table [managed-table-name] select * from [external-table-name];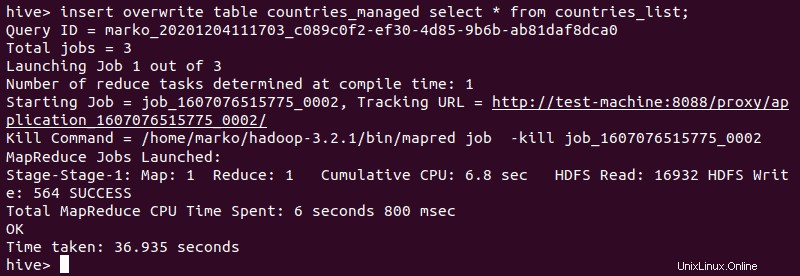
5. Überprüfen Sie, ob die Daten erfolgreich in die verwaltete Tabelle eingefügt wurden.
select * from [managed-table-name];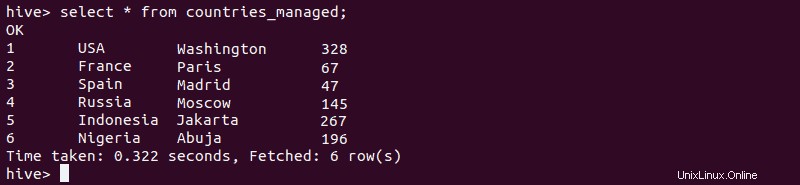
So fragen Sie eine externe Hive-Tabelle ab
Um alle in einer Tabelle gespeicherten Daten anzuzeigen, verwenden Sie den select * from Befehl gefolgt vom Tabellennamen. Hive bietet eine umfangreiche Liste von Abfragebefehlen, mit denen Sie Ihre Suche eingrenzen und die Daten nach Ihren Vorlieben sortieren können.
Beispielsweise können Sie das where verwenden Befehl nach select * from um eine Bedingung anzugeben:
select * from [table_name] where [condition];Hive gibt nur die Zeilen aus, die die in der Abfrage angegebene Bedingung erfüllen:

Anstelle des Sternchens Zeichen, das für „alle Daten“ steht, können Sie spezifischere Determinatoren verwenden. Ersetzen Sie das Sternchen durch einen Spaltennamen (z. B. CountryName , aus dem obigen Beispiel) zeigt Ihnen nur die Daten aus der ausgewählten Spalte.
Hier sind einige andere nützliche Abfragefunktionen und ihre Syntax:
| Funktion | Syntax |
|---|---|
| Fragen Sie eine Tabelle nach mehreren Bedingungen ab | select * from [table_name] where [condition1] and [condition2]; |
| Tabellendaten bestellen | select [column1_name], [column2_name] from [table_name] order by [column_name]; |
| Tabellendaten in absteigender Reihenfolge sortieren | select [column1_name], [column2_name] from [table_name] order by [column_name] desc; |
| Zeige die Zeilenanzahl | select count(*) from [table_name]; |
So löschen Sie eine externe Hive-Tabelle
1. Das Löschen einer externen Tabelle in Hive erfolgt mit demselben Befehl zum Löschen, der für verwaltete Tabellen verwendet wird:
drop table [table_name];Die Ausgabe bestätigt den Erfolg der Operation:

2. Die Abfrage der gelöschten Tabelle gibt einen Fehler zurück:

Die Daten aus der externen Tabelle verbleiben jedoch im System und können abgerufen werden, indem eine weitere externe Tabelle an derselben Stelle erstellt wird.