Einführung
MySQL ist eine Datenbankanwendung, die Daten in Zeilen und Spalten verschiedener Tabellen speichert, um Duplikate zu vermeiden. Es können doppelte Werte auftreten, die die Leistung von MySQL beeinträchtigen können.
Diese Anleitung zeigt Ihnen, wie Sie doppelte Werte in einer MySQL-Datenbank finden .

Voraussetzungen
- Eine vorhandene Installation von MySQL
- Root-Benutzerkonto-Anmeldeinformationen für MySQL
- Ein Befehlszeilen-/Terminalfenster
Einrichten einer Beispieltabelle (optional)
Dieser Schritt hilft Ihnen, eine Beispieltabelle zu erstellen, mit der Sie arbeiten können. Wenn Sie bereits eine Datenbank haben, an der Sie arbeiten können, fahren Sie mit dem nächsten Abschnitt fort.
Öffnen Sie ein Terminalfenster und wechseln Sie zur MySQL-Shell:
mysql –u root –pVorhandene Datenbanken auflisten:
SHOW databases;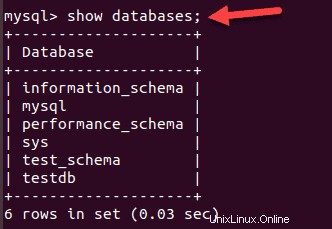
Erstellen Sie eine neue Datenbank, die noch nicht existiert:
CREATE database sampledb;Wählen Sie die soeben erstellte Tabelle aus:
USE sampledb;Erstellen Sie eine neue Tabelle mit den folgenden Feldern:
CREATE TABLE dbtable (
id INT PRIMARY KEY AUTO_INCREMENT,
date_x VARCHAR(10) NOT NULL,
system_x VARCHAR(50) NOT NULL,
test VARCHAR(50) NOT NULL
);Zeilen in die Tabelle einfügen:
INSERT INTO dbtable (date_x,system_x,test)
VALUES ('01/03/2020','system1','hard_drive'),
('01/04/2020','system2','memory'),
('01/10/2020','system2','processor'),
('01/14/2020','system3','hard drive'),
('01/10/2020','system2','processor'),
('01/20/2020','system4','hard drive'),
('01/24/2020','system5','memory'),
('01/29/2020','system6','hard drive'),
('02/02/2020','system7','motherboard'),
('02/04/2020','system8','graphics card'),
('02/02/2020','system7','motherboard'),
('02/08/2020','system9','hard drive');Führen Sie die folgende SQL-Abfrage aus:
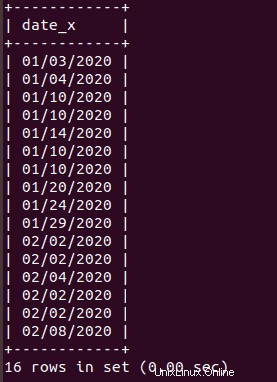
SELECT * FROM dbtable
ORDER BY date_x;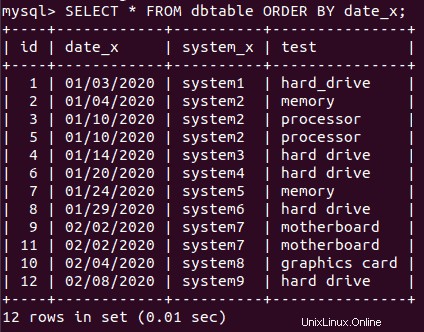
Duplikate in MySQL finden
Doppelte Werte in einer einzelnen Spalte finden
Verwenden Sie GROUP BY Funktion, um alle identischen Einträge in einer Spalte zu identifizieren. Folgen Sie mit einem COUNT() HAVING Funktion, um alle Gruppen mit mehr als einem Eintrag aufzulisten.
SELECT
test,
COUNT(test)
FROM
dbtable
GROUP BY test
HAVING COUNT(test) > 1;
Doppelte Werte in mehreren Spalten finden
Möglicherweise möchten Sie exakte Duplikate mit denselben Informationen in allen drei Spalten auflisten.
SELECT
date_x, COUNT(date_x),
system_x, COUNT(system_x),
test, COUNT(test)
FROM
dbtable
GROUP BY
date_x,
system_x,
test
HAVING COUNT(date_x)>1
AND COUNT(system_x)>1
AND COUNT(test)>1;

Diese Abfrage funktioniert durch Auswählen und Testen der >1 Zustand in allen drei Spalten. Das Ergebnis ist, dass nur Zeilen mit doppelten Werten in der Ausgabe zurückgegeben werden.
Mit INNER JOIN nach Duplikaten in mehreren Tabellen suchen
Verwenden Sie die INNER JOIN-Funktion, um Duplikate zu finden, die in mehreren Tabellen vorhanden sind.
Beispielsyntax für einen INNER JOIN Funktion sieht so aus:
SELECT column_name
FROM table1
INNER JOIN table2
ON table1.column_name = table2.column name;
Um dieses Beispiel zu testen, benötigen Sie eine zweite Tabelle, die einige Informationen enthält, die aus der sampledb dupliziert wurden Tabelle, die wir oben erstellt haben.
SELECT dbtable.date_x
FROM dbtable
INNER JOIN new_table
ON dbtable.date_x = new_table.date_x;
Dadurch werden alle doppelten Daten angezeigt, die zwischen den vorhandenen Daten und der neuen_Tabelle vorhanden sind .