Einführung
MySQL ist eine beliebte Open-Source-Datenbankanwendung, die Daten auf sinnvolle und leicht zugängliche Weise speichert und strukturiert. Bei großen Anwendungen kann die schiere Menge an Daten zu Performance-Problemen führen.
Dieser Leitfaden enthält mehrere Tuning-Tipps zur Verbesserung der Leistung einer MySQL-Datenbank .

Voraussetzungen
- Ein Linux-System mit installiertem und ausgeführtem MySQL, Centos oder Ubuntu
- Eine vorhandene Datenbank
- Administratoranmeldeinformationen für das Betriebssystem und die Datenbank
System-MySQL-Leistungsoptimierung
Auf Systemebene passen Sie Hardware- und Softwareoptionen an, um die MySQL-Leistung zu verbessern.
1. Gleichen Sie die vier Haupthardwareressourcen aus

Speicher
Nehmen Sie sich einen Moment Zeit, um Ihren Speicher zu bewerten. Wenn Sie herkömmliche Festplattenlaufwerke (HDD) verwenden, können Sie zur Leistungssteigerung auf Solid-State-Laufwerke (SSD) upgraden.
Verwenden Sie ein Tool wie iotop oder sar aus dem sysstat Paket zur Überwachung Ihrer Festplatten-Eingabe-/Ausgaberaten. Wenn die Festplattennutzung viel höher ist als die Nutzung anderer Ressourcen, sollten Sie mehr Speicher hinzufügen oder auf schnelleren Speicher upgraden.
Prozessor
Prozessoren gelten normalerweise als Maß dafür, wie schnell Ihr System ist. Verwenden Sie die Linux-Oberseite Befehl für eine Aufschlüsselung, wie Ihre Ressourcen verwendet werden. Achten Sie auf die MySQL-Prozesse und den Prozentsatz der Prozessorauslastung, die sie benötigen.
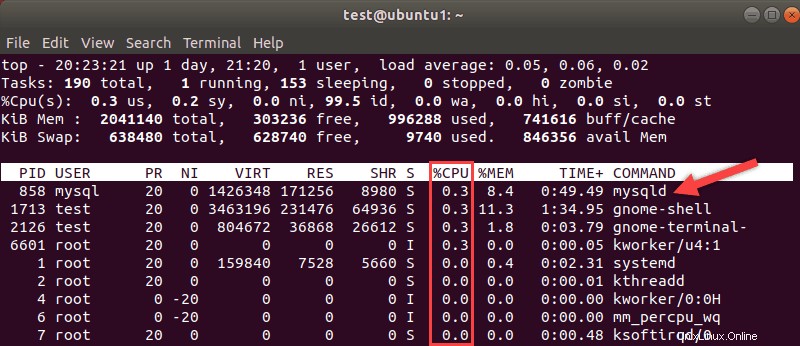
Das Upgrade von Prozessoren ist teurer, aber wenn Ihre CPU einen Engpass darstellt, ist möglicherweise ein Upgrade erforderlich.
Erinnerung
Arbeitsspeicher stellt die Gesamtmenge an RAM in Ihrem MySQL-Datenbankspeicherserver dar. Sie können den Speicher-Cache anpassen (dazu später mehr), um die Leistung zu verbessern . Wenn Sie nicht über genügend Arbeitsspeicher verfügen oder der vorhandene Arbeitsspeicher nicht optimiert ist, können Sie Ihre Leistung beeinträchtigen, anstatt sie zu verbessern.
Wenn Ihrem Server wie bei anderen Engpässen ständig der Arbeitsspeicher ausgeht, können Sie ein Upgrade durchführen, indem Sie mehr hinzufügen. Wenn Ihnen der Arbeitsspeicher ausgeht, speichert Ihr Server den Datenspeicher (wie eine Festplatte) zwischen, um als Arbeitsspeicher zu fungieren. Datenbank-Caching verlangsamt Ihre Leistung.
Netzwerk
Es ist wichtig, den Netzwerkverkehr zu überwachen, um sicherzustellen, dass Sie über eine ausreichende Infrastruktur verfügen, um die Last zu bewältigen.
Eine Überlastung Ihres Netzwerks kann zu Latenz, verlorenen Paketen und sogar Serverausfällen führen. Stellen Sie sicher, dass Sie über genügend Netzwerkbandbreite verfügen, um Ihren normalen Datenbankverkehr zu bewältigen.
2. Verwenden Sie InnoDB, nicht MyISAM
MyISAM ist ein älterer Datenbankstil, der für einige MySQL-Datenbanken verwendet wird. Es ist ein weniger effizientes Datenbankdesign. Die neuere InnoDB unterstützt erweiterte Funktionen und verfügt über integrierte Optimierungsmechanismen.
InnoDB verwendet einen geclusterten Index und speichert Daten in Seiten, die in aufeinanderfolgenden physischen Blöcken gespeichert werden. Wenn ein Wert für eine Seite zu groß ist, verschiebt InnoDB ihn an einen anderen Ort und indiziert dann den Wert. Diese Funktion trägt dazu bei, dass relevante Daten am gleichen Ort auf dem Speichergerät bleiben, was bedeutet, dass die physische Festplatte weniger Zeit benötigt, um auf die Daten zuzugreifen.
3. Verwenden Sie die neueste Version von MySQL
Die Verwendung der neuesten Version ist für ältere und Legacy-Datenbanken nicht immer möglich. Aber wann immer möglich, sollten Sie die verwendete MySQL-Version überprüfen und auf die neueste aktualisieren.
Ein Teil der laufenden Entwicklung umfasst Leistungssteigerungen. Einige gängige Leistungsanpassungen können durch neuere Versionen von MySQL obsolet werden. Im Allgemeinen ist es immer besser, die native MySQL-Leistungsverbesserung gegenüber Skript- und Konfigurationsdateien zu verwenden.
Software-MySQL-Leistungsoptimierung
Die SQL-Leistungsoptimierung ist der Prozess der Maximierung der Abfragegeschwindigkeit in einer relationalen Datenbank. Die Aufgabe umfasst normalerweise mehrere Tools und Techniken.
Diese Methoden beinhalten:
- Optimieren der MySQL-Konfigurationsdateien.
- Effizientere Datenbankabfragen schreiben.
- Strukturierung der Datenbank, um Daten effizienter abzurufen.
4. Erwägen Sie die Verwendung eines Tools zur automatischen Leistungsverbesserung
Wie bei der meisten Software funktionieren nicht alle Tools mit allen Versionen von MySQL. Wir werden drei Dienstprogramme untersuchen, um Ihre MySQL-Datenbank zu bewerten, und Änderungen zur Leistungsverbesserung empfehlen.
Der erste ist Tuning-Primer. Dieses Tool ist etwas älter und wurde für MySQL 5.5 – 5.7 entwickelt. Es kann Ihre Datenbank analysieren und Einstellungen zur Verbesserung der Leistung vorschlagen. Beispielsweise kann es vorschlagen, dass Sie query_cache_size erhöhen Parameter, wenn Sie den Eindruck haben, dass Ihr System Abfragen nicht schnell genug verarbeiten kann, um den Cache leer zu halten.
Das zweite Tuning-Tool, das für die meisten modernen SQL-Datenbanken nützlich ist, ist MySQLTuner. Dieses Skript (mysqltuner.pl ) ist in Perl geschrieben. Wie tuning-primer analysiert es Ihre Datenbankkonfiguration und sucht nach Engpässen und Ineffizienzen. Die Ausgabe zeigt Metriken und Empfehlungen:
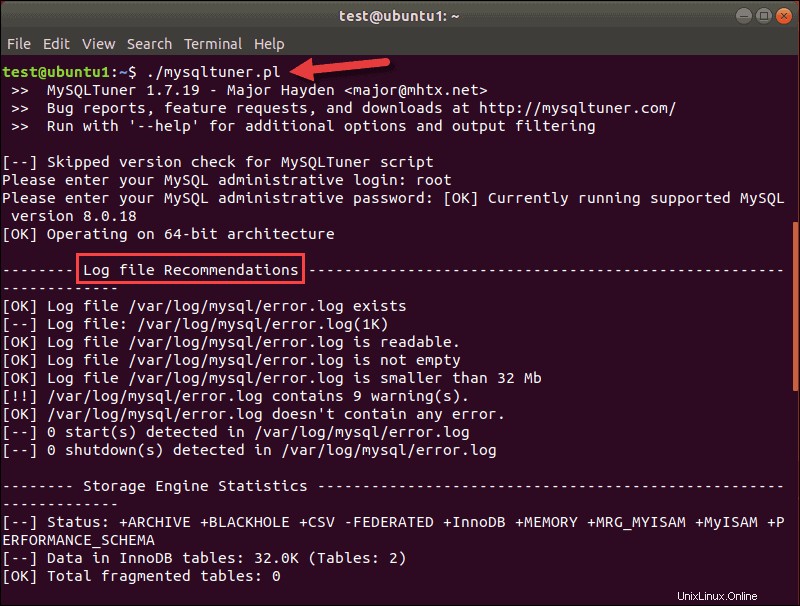
Oben in der Ausgabe sehen Sie die Version des MySQLTuner-Tools und Ihrer Datenbank.
Das Skript funktioniert mit MySQL 8.x. Empfehlungen für Protokolldateien sind die ersten auf der Liste, aber wenn Sie nach unten scrollen, können Sie allgemeine Empfehlungen zur Verbesserung der MySQL-Leistung sehen.
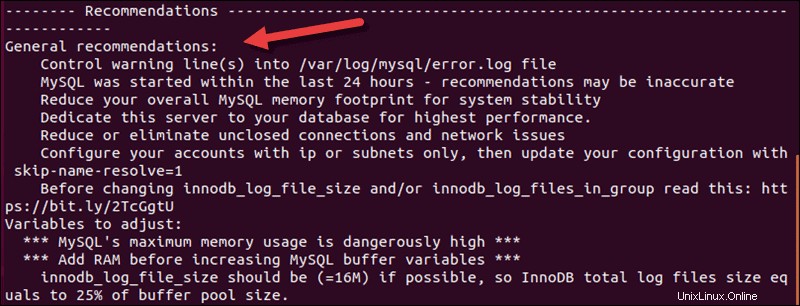
Das dritte Dienstprogramm, das Sie möglicherweise bereits haben, ist der phpMyAdmin Advisor . Wie die beiden anderen Dienstprogramme wertet es Ihre Datenbank aus und empfiehlt Anpassungen. Wenn Sie phpMyAdmin bereits verwenden, ist der Advisor ein hilfreiches Tool, das Sie innerhalb der GUI verwenden können.
5. Suchanfragen optimieren
Eine Abfrage ist eine codierte Anforderung, die Datenbank nach Daten zu durchsuchen, die einem bestimmten Wert entsprechen. Es gibt einige Abfrageoperatoren, deren Ausführung naturgemäß sehr lange dauert. SQL-Leistungsoptimierungstechniken helfen bei der Optimierung von Abfragen für bessere Laufzeiten.
Das Erkennen von Abfragen mit schlechter Ausführungszeit ist eine der Hauptaufgaben der Leistungsoptimierung. Häufig implementierte Abfragen für große Datasets sind langsam und belegen Datenbanken. Die Tabellen stehen daher für keine anderen Aufgaben zur Verfügung.
Beispielsweise erfordert eine OLTP-Datenbank schnelle Transaktionen und eine effektive Abfrageverarbeitung. Das Ausführen einer ineffizienten Abfrage blockiert die Verwendung der Datenbank und hält Informationsaktualisierungen auf.
Wenn Ihre Umgebung auf automatisierte Abfragen wie Trigger angewiesen ist, können sich diese auf die Leistung auswirken. Überprüfen und beenden Sie MySQL-Prozesse, die sich mit der Zeit häufen können.
6. Verwenden Sie gegebenenfalls Indizes
Viele Datenbankabfragen verwenden eine ähnliche Struktur wie diese:
SELECT … WHEREDiese Abfragen umfassen das Auswerten, Filtern und Abrufen von Ergebnissen. Sie können diese umstrukturieren, indem Sie eine kleine Gruppe von Indizes für die zugehörigen Tabellen hinzufügen. Die Abfrage kann an den Index gerichtet werden, um die Abfrage zu beschleunigen.
7. Funktionen in Prädikaten
Vermeiden Sie die Verwendung einer Funktion im Prädikat einer Abfrage. Zum Beispiel:
SELECT * FROM MYTABLE WHERE UPPER(COL1)='123'Copy
Der UPPER Notation erstellt eine Funktion, die während des SELECT ausgeführt werden muss Betrieb. Dies verdoppelt die Arbeit der Abfrage und sollte möglichst vermieden werden.
8. Vermeiden Sie % Wildcard in einem Prädikat
Beim Durchsuchen von Textdaten helfen Platzhalter bei einer breiteren Suche. Zum Beispiel, um alle Namen auszuwählen, die mit ch beginnen , erstellen Sie einen Index für die Namensspalte und führen Sie Folgendes aus:
SELECT * FROM person WHERE name LIKE "ch%"Die Abfrage scannt die Indizes, was die Abfragekosten niedrig macht:

Wenn Sie jedoch am Anfang eine Suche nach Namen mit Platzhaltern durchführen, erhöhen sich die Abfragekosten erheblich, da ein Index-Scan nicht auf die Enden von Zeichenfolgen angewendet wird:
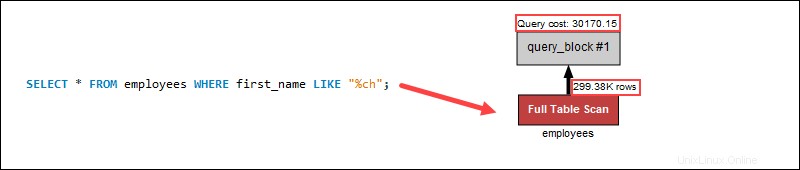
Ein Platzhalter am Anfang einer Suche wendet keine Indizierung an. Stattdessen durchsucht ein vollständiger Tabellenscan jede Zeile einzeln, wodurch die Abfragekosten im Prozess steigen. In der Beispielabfrage trägt die Verwendung eines Platzhalters am Ende dazu bei, die Abfragekosten zu reduzieren, da weniger Tabellenzeilen durchlaufen werden.
Eine Möglichkeit, die Enden von Zeichenfolgen zu suchen, besteht darin, die Zeichenfolge umzukehren, die umgekehrten Zeichenfolgen zu indizieren und die Anfangszeichen zu betrachten. Wenn Sie den Platzhalter am Ende platzieren, wird jetzt nach dem Anfang der umgekehrten Zeichenfolge gesucht, wodurch die Suche effizienter wird.
9. Spalten in SELECT-Funktion angeben
Ein häufig verwendeter Ausdruck für analytische und explorative Abfragen ist SELECT * . Wenn Sie mehr auswählen, als Sie benötigen, führt dies zu unnötigem Leistungsverlust und Redundanz. Wenn Sie die benötigten Spalten angeben, muss Ihre Abfrage keine irrelevanten Spalten scannen.
Wenn alle Spalten benötigt werden, gibt es keine andere Möglichkeit. Die meisten Geschäftsanforderungen benötigen jedoch nicht alle Spalten, die in einem Dataset verfügbar sind. Erwägen Sie stattdessen die Auswahl bestimmter Spalten.
Zusammenfassend vermeiden Sie die Verwendung von:
SELECT * FROM tableVersuchen Sie stattdessen:
SELECT column1, column2 FROM table10. Verwenden Sie ORDER BY angemessen
Der ORDER BY Ausdruck sortiert Ergebnisse nach der angegebenen Spalte. Es kann verwendet werden, um nach zwei Spalten gleichzeitig zu sortieren. Diese sollten in der gleichen Reihenfolge sortiert werden, aufsteigend oder absteigend.
Wenn Sie versuchen, verschiedene Spalten in unterschiedlicher Reihenfolge zu sortieren, wird die Leistung beeinträchtigt. Sie können dies mit einem Index kombinieren, um die Sortierung zu beschleunigen.
11. GROUP BY statt SELECT DISTINCT
Die SELECT DISTINCT -Abfrage ist praktisch, wenn Sie versuchen, doppelte Werte loszuwerden. Die Anweisung erfordert jedoch eine große Menge an Rechenleistung.
Vermeiden Sie nach Möglichkeit die Verwendung von SELECT DISTINCT , da es sehr ineffizient und manchmal verwirrend ist. Wenn beispielsweise eine Tabelle Informationen über Kunden mit der folgenden Struktur auflistet:
| id | Name | Nachname | Adresse | Stadt | Zustand | zip |
|---|---|---|---|---|---|---|
| 0 | Johannes | Smith | Blumenstraße 652 | Los Angeles | CA | 90017 |
| 1 | Johannes | Smith | 1215 Ocean Boulevard | Los Angeles | CA | 90802 |
| 2 | Martha | Matthäus | 3104 Pico-Boulevard | Los Angeles | CA | 90019 |
| 3 | Martha | Jones | 2712 Venice Boulevard | Los Angeles | CA | 90019 |
Das Ausführen der folgenden Abfrage gibt vier Ergebnisse zurück:
SELECT DISTINCT name, address FROM person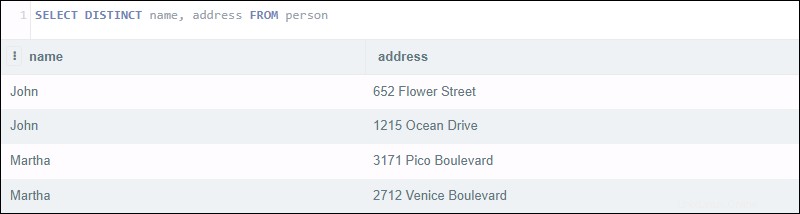
Die Anweisung scheint eine Liste eindeutiger Namen zusammen mit ihrer Adresse zurückzugeben. Stattdessen betrachtet die Abfrage beide die Namens- und Adressspalte. Obwohl es zwei Kundenpaare mit demselben Namen gibt, sind ihre Adressen unterschiedlich.
Um doppelte Namen herauszufiltern und die Adressen zurückzugeben, versuchen Sie es mit GROUP BY Aussage:
SELECT name, address FROM person GROUP BY name
Das Ergebnis gibt den ersten eindeutigen Namen zusammen mit der Adresse zurück, wodurch die Anweisung weniger zweideutig wird. Um nach eindeutigen Adressen zu gruppieren, verwenden Sie GROUP BY Der Parameter würde sich einfach in eine Adresse ändern und das gleiche Ergebnis wie DISTINCT zurückgeben Anweisung schneller.
Zusammenfassend vermeiden Sie die Verwendung von:
SELECT DISTINCT column1, column2 FROM tableVersuchen Sie es stattdessen mit:
SELECT column1, column2 FROM table GROUP BY column112. JOIN, WO, UNION, DISTINCT
Versuchen Sie, wann immer möglich, einen inneren Join zu verwenden. Ein äußerer Join betrachtet zusätzliche Daten außerhalb der angegebenen Spalten. Das ist in Ordnung, wenn Sie diese Daten benötigen, aber es ist eine Verschwendung von Leistung, Daten einzuschließen, die nicht benötigt werden.
Verwenden von INNER JOIN ist der Standardansatz zum Verbinden von Tabellen. Die meisten Datenbank-Engines akzeptieren die Verwendung von WHERE auch. Beispielsweise geben die folgenden zwei Abfragen dasselbe Ergebnis aus:
SELECT * FROM table1 INNER JOIN table2 ON table1.id = table2.idVerglichen mit:
SELECT * FROM table1, table2 WHERE table1.id = table2.idTheoretisch haben sie auch die gleiche Laufzeit.
Die Wahl, ob JOIN verwendet werden soll oder WHERE Abfrage hängen von der Datenbank-Engine ab. Während die meisten Engines für beide Methoden die gleiche Laufzeit haben, läuft in manchen Datenbanksystemen eine schneller als die andere.
Die UNION und DISTINCT Befehle sind manchmal in Abfragen enthalten. Wie bei einem Outer Join ist es in Ordnung, diese Ausdrücke zu verwenden, wenn sie notwendig sind. Sie fügen jedoch zusätzliches Sortieren und Lesen der Datenbank hinzu. Wenn Sie sie nicht benötigen, ist es besser, einen effizienteren Ausdruck zu finden.
13. Verwenden Sie die EXPLAIN-Funktion
Moderne MySQL-Datenbanken enthalten ein EXPLAIN Funktion.
Anhängen von EXPLAIN Ausdruck am Anfang einer Abfrage liest und wertet die Abfrage aus. Wenn es ineffiziente Ausdrücke oder verwirrende Strukturen gibt, EXPLAIN kann Ihnen helfen, sie zu finden. Sie können dann die Formulierung Ihrer Abfrage anpassen, um unbeabsichtigte Tabellenscans oder andere Leistungseinbußen zu vermeiden.
14. MySQL-Serverkonfiguration
Diese Konfiguration beinhaltet Änderungen an Ihrer /etc/mysql/my.cnf Datei. Gehen Sie vorsichtig vor und nehmen Sie immer wieder kleine Änderungen vor.
query_cache_size – Gibt die Größe des Caches von MySQL-Abfragen an, die auf die Ausführung warten. Die Empfehlung ist, mit kleinen Werten um 10 MB zu beginnen und dann auf nicht mehr als 100-200 MB zu erhöhen. Bei zu vielen zwischengespeicherten Abfragen kann es zu einer Kaskade von Abfragen „Warten auf Cache-Sperre“ kommen. Wenn Ihre Abfragen immer wieder gesichert werden, ist ein besseres Verfahren die Verwendung von EXPLAIN um jede Abfrage auszuwerten und Wege zu finden, sie effizienter zu gestalten.
max_connection – Bezieht sich auf die Anzahl der erlaubten Verbindungen in die Datenbank. Wenn Sie Fehlermeldungen mit dem Hinweis „Zu viele Verbindungen, ” Es kann hilfreich sein, diesen Wert zu erhöhen.
innodb_buffer_pool_size – Diese Einstellung weist Systemspeicher als Datencache für Ihre Datenbank zu. Wenn Sie große Datenblöcke haben, erhöhen Sie diesen Wert. Beachten Sie den für die Ausführung anderer Systemressourcen erforderlichen Arbeitsspeicher.
innodb_io_capacity – Diese Variable legt die Rate für die Eingabe/Ausgabe von Ihrem Speichergerät fest. Dies hängt direkt mit dem Typ und der Geschwindigkeit Ihres Speicherlaufwerks zusammen. Eine HDD mit 5400 U/min hat eine viel geringere Kapazität als eine High-End-SSD oder Intel Optane. Sie können diesen Wert anpassen, um ihn besser an Ihre Hardware anzupassen.