Einführung
MySQL-String-Funktionen ermöglichen es Benutzern, Datenstrings zu manipulieren oder Informationen über einen String abzufragen, der von SELECT zurückgegeben wird Abfrage.
In diesem Artikel erfahren Sie, wie Sie MySQL-String-Funktionen verwenden.

Voraussetzungen
- MySQL Server und MySQL Shell installiert
- Ein MySQL-Benutzerkonto mit Root-Rechten
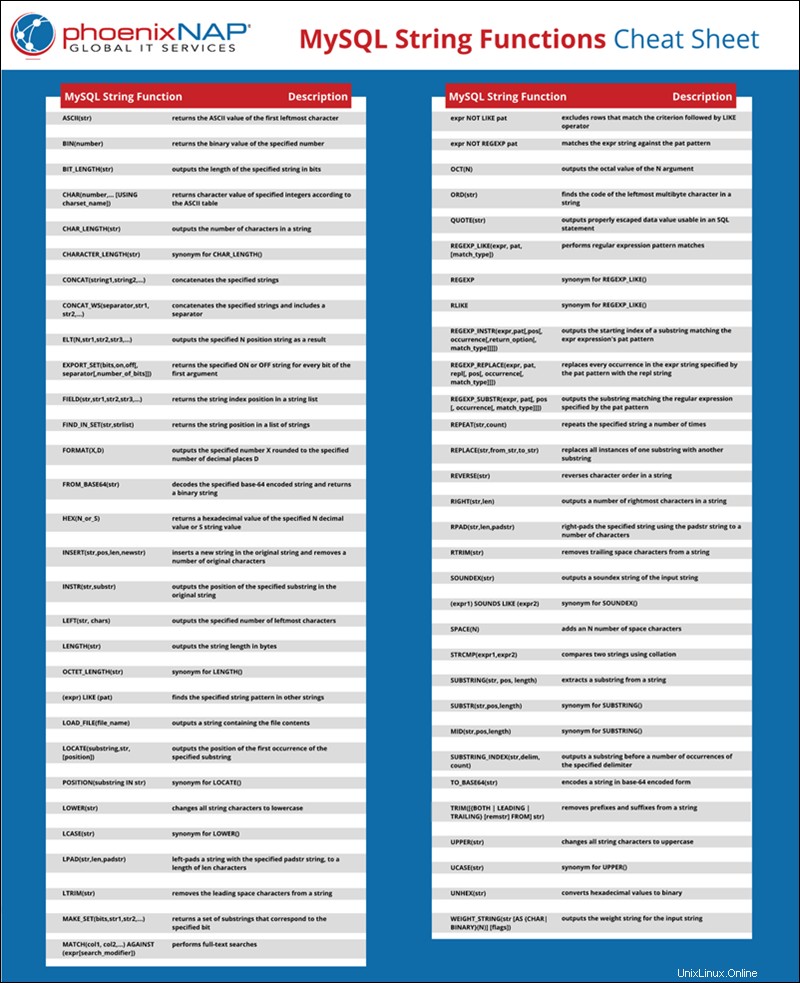
Spickzettel für MySQL-String-Funktionen
Jede Zeichenfolgenfunktion wird im folgenden Artikel erklärt und veranschaulicht. Wenn es für Sie bequemer ist, können Sie das Spickzettel-PDF speichern, indem Sie auf MySQL-String-Funktionen-Spickzettel herunterladen klicken verlinken.
Cheat Sheet für MySQL-String-Funktionen herunterladen
ASCII()
Die Syntax für ASCII() Funktion ist:
ASCII('str')
Das ASCII() string gibt den (numerischen) ASCII-Wert des Zeichens ganz links des angegebenen str zurück Schnur. Die Funktion gibt 0 zurück, wenn kein str vorhanden ist angegeben. Gibt NULL zurück wenn str ist NULL .
Verwenden Sie ASCII() für Zeichen mit numerischen Werten von 0 bis 255.
Zum Beispiel:

In diesem Beispiel das ASCII() Funktion gibt den numerischen Wert von p zurück , das am weitesten links stehende Zeichen des angegebenen str Zeichenfolge.
BIN()
Die Syntax für BIN() Funktion ist:
BIN(number)
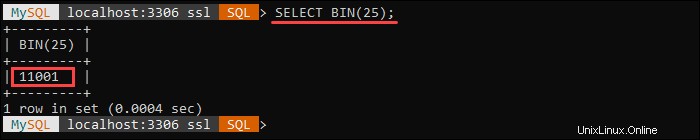
Der BIN() Funktion gibt einen Binärwert der angegebenen number zurück Argument, wobei die number ist ein BIGINTEGER Anzahl. Gibt NULL zurück wenn die number Argument ist NULL .
Die folgende Abfrage gibt beispielsweise eine binäre Darstellung der Zahl 25 zurück:
BIT_LENGTH()
Die Syntax für BIT_LENGTH() Funktion ist:
BIT_LENGTH('str')
Die Funktion gibt die Länge des angegebenen str aus Zeichenfolge in Bits.
Die folgende Abfrage gibt beispielsweise die Bitlänge des angegebenen „Beispiel“ zurück ' Zeichenkette:

CHAR()
Die Syntax für CHAR() Funktion ist:
CHAR(number,... [USING charset_name])
CHAR() interpretiert jede angegebene number Argument als Integer und gibt eine binäre Zeichenkette aus der ASCII-Tabelle aus. Die Funktion überspringt NULL Werte.
Zum Beispiel:

Wenn Sie eine andere als eine binäre Ausgabe erzeugen möchten, verwenden Sie das optionale USING -Klausel und geben Sie den gewünschten Zeichensatz an. MySQL gibt eine Warnung aus, wenn die Ergebniszeichenfolge für den angegebenen Zeichensatz nicht zulässig ist.
CHAR_LENGTH(), d.h. CHARACTER_LENGTH()
Die Syntax für CHAR_LENGTH Funktion ist:
CHAR_LENGTH(str)
Die Funktion gibt die Länge des angegebenen str aus Zeichenfolge, gemessen in Zeichen.
CHAR_LENGTH() behandelt ein Multibyte-Zeichen als einzelnes Zeichen, was bedeutet, dass eine Zeichenfolge mit vier 2-Byte-Zeichen als Ergebnis 4 zurückgibt, während LENGTH() gibt 8 zurück.
Zum Beispiel:

CHARACTER_LENGTH() ist ein Synonym für CHAR_LENGTH() .
CONCAT()
Der CONCAT() Funktion verkettet zwei oder mehr angegebene Zeichenfolgen. Die Syntax lautet:
CONCAT(string1,string2,...)
Der CONCAT -Funktion konvertiert alle Argumente vor dem Verketten in den String-Typ. Wenn alle Argumente nicht-binäre Zeichenfolgen sind, ist das Ergebnis eine nicht-binäre Zeichenfolge. Andererseits führt das Verketten von binären Strings zu einem binären String. Ein numerisches Argument wird in seine äquivalente nichtbinäre Zeichenkettenform umgewandelt.
Wenn eines der angegebenen Argumente NULL ist , CONCAT() gibt NULL zurück als Ergebnis.
Zum Beispiel:

Die Funktion fügt die angegebenen Zeichenfolgen zu einer zusammen, in diesem Fall „phoenixNAP '.
CONCAT_WS()
Die Syntax für CONCAT_WS() ist:
CONCAT_WS(separator,str1,str2,...)
CONCAT_WS() ist eine spezielle Form von CONCAT() die zwei oder mehr Ausdrücke zusammenfügt und ein Trennzeichen enthält. Das Trennzeichen trennt die Zeichenfolgen, die Sie verketten möchten. Wenn das Trennzeichen NULL ist , ist das Ergebnis NULL .
Zum Beispiel:

In diesem Beispiel ist das Trennzeichen ein Leerzeichen, das die angegebenen Zeichenfolgen in der Ausgabe trennt.
ELT()
Die Syntax für ELT() Funktion ist:
ELT(N,str1,str2,str3,...)
Das N argument definiert, welcher der angegebenen Strings als Ergebnis zurückgegeben werden soll. ELT() gibt NULL zurück wenn N ist kleiner als 1 oder größer als die Anzahl der angegebenen Zeichenfolgen.
Zum Beispiel:

EXPORT_SET()
Die Syntax für EXPORT_SET() ist:
EXPORT_SET(bits,on,off[,separator[,number_of_bits]])
Der EXPORT_SET() Funktion gibt ein ON zurück oder OFF string für jedes Bit des ersten Arguments, Prüfung von rechts nach links. Das Argument ist eine ganze Zahl, aber die Funktion wandelt es in Bits um.
Wenn das Bit 1 ist, gibt die Funktion ON zurück Schnur. Wenn das Bit 0 ist, gibt die Funktion OFF zurück . EXPORT_SET() platziert ein Trennzeichen zwischen den Rückgabewerten. Das Standardtrennzeichen ist ein Komma, aber Sie können als viertes Argument ein anderes angeben.
Die Strings werden dem Ausgabeergebnis von links nach rechts hinzugefügt, getrennt durch den Trennstring. Die number_of_bits Das Argument gibt an, wie viele Bits untersucht werden sollen.
Zum Beispiel:

Erklärung:
1. Nach der Konvertierung steht das erste Argument 5 für 00000101.
2. Von rechts nach links prüfend, ist das erste Bit 1, also gibt die Funktion 'Ja zurück ' Argument (das ON Schnur). Das zweite Bit ist 0, also gibt die Funktion 'Nein zurück ' (die OFF Schnur). Für das dritte Bit wird 'Yes zurückgegeben .' Für alle verbleibenden Bits (Nullen) wird 'Nein zurückgegeben .'
3. Das vierte Argument '- ' wird im Rückgabeergebnis als Trennzeichen angegeben.
FELD()
Die Syntax für FIELD() Syntax ist:
FIELD(str,str1,str2,str3,...)
Die Funktion gibt die Indexposition einer Zeichenfolge in einer Zeichenfolgenliste zurück. Wenn es keinen solchen String gibt, ist die Ausgabe 0. Wenn der String NULL ist , gibt die Funktion 0 zurück. Das FIELD() Bei der Funktion wird die Groß-/Kleinschreibung nicht beachtet.
Zum Beispiel:

Die Funktion gibt 6 zurück, das ist die Position der Zeichenfolge 'f ' in der Liste.
FIND_IN_SET()
Die Syntax für FIND_IN_SET() Funktion ist:
FIND_IN_SET(str,strlist)Die Funktion gibt die Position einer Zeichenfolge in einer Liste von Zeichenfolgen zurück. Bei mehreren Stringinstanzen gibt die Ausgabe nur die erste Position des angegebenen Strings zurück.
Zum Beispiel:

FORMAT()
Die Syntax für FORMAT() Funktion ist:
FORMAT(X,D)
Die Funktion gibt die angegebene Zahl X aus in einem Format wie '#,###,###.##', gerundet auf die angegebene Anzahl von Dezimalstellen D . Das Ergebnis hat keinen Dezimalpunkt, wenn D ist 0.
Benutzer können das Gebietsschema auch nach dem D angeben Argument, das die Ausgabe beeinflusst.
Zum Beispiel:

Die Ausgabe rundet die Zahl auf 3 Dezimalstellen, und das deutsche Gebietsschema verursacht einen . Symbol zur Bezeichnung von Tausendern und , Zeichen für Brüche.
FROM_BASE64()
Die Syntax für FROM_BASE64() Funktion ist:
FROM_BASE64(str)
Die Funktion decodiert die angegebene Base-64-codierte Zeichenfolge und gibt das Ergebnis als binäre Zeichenfolge zurück. Wenn das Argument NULL ist oder eine ungültige Base-64-Zeichenfolge, ist das Ergebnis NULL .
FROM_BASE64() ist das Gegenteil von TO_BASE64() als TO_BASE64() codiert eine Abfrage in base64.
Zum Beispiel:
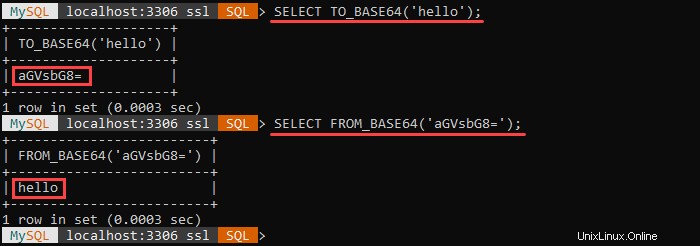
Die erste Abfrage codiert die angegebene Zeichenfolge in base64. Die zweite Abfrage decodiert die base64-codierte Zeichenfolge und gibt den ursprünglichen Wert zurück.
HEX()
Die Syntax für HEX() Funktion ist:
HEX(N_or_S)
Die Funktion gibt eine Zeichenfolgendarstellung eines Hexadezimalwerts des angegebenen N zurück Dezimalwert oder S Zeichenfolgenwert.
Wenn das Argument eine string ist , HEX wandelt jedes Zeichen in zwei Hexadezimalziffern um. Andererseits, wenn das Argument eine decimal ist , ist die Ausgabe eine hexadezimale Zeichenfolgendarstellung des Arguments und behandelt es als BIGINTEGER Nummer.
Das HEX() Zeichenfolgenfunktion entspricht der mathematischen Funktion CONV(N,10,16) .
Zum Beispiel:

Die Ausgabe gibt den Hexadezimalwert der angegebenen Zeichenfolge zurück.
EINFÜGEN()
Die Syntax für INSERT() Funktion ist:
INSERT(str,pos,len,newstr)
Die Funktion fügt einen newstr ein Zeichenfolge innerhalb von str Zeichenfolge und entfernt die len Anzahl der Originalzeichen, beginnend bei pos Position.
Wenn die pos Das Argument liegt nicht innerhalb der ursprünglichen Zeichenfolgenlänge, INSERT() gibt den ursprünglichen String zurück.
Wenn die len Argument ist nicht innerhalb der Länge des Rests der Zeichenfolge, INSERT() ersetzt den Rest der Zeichenfolge aus pos Position.
Wenn ein Argument NULL ist , INSERT() gibt NULL zurück .
Zum Beispiel:

Die Ausgabe ist die Originalzeichenfolge, wobei die neue Zeichenfolge an Position 5 eingefügt wird, wobei keine ursprünglichen Zeichen entfernt werden.
INSTR()
Die Syntax für INSTR() Funktion ist:
INSTR(str,substr)
Die Funktion gibt die Position des ersten Auftretens von substr aus Teilstring im ursprünglichen str Zeichenfolge.
Die Funktion funktioniert genauso wie LOCATE() , außer dass die Reihenfolge der Argumente umgekehrt ist.
Zum Beispiel:

Die Ausgabe gibt die Position des Teilstrings an - Position 8.
LINKS()
Die Syntax für LEFT() Funktion ist:
LEFT('str', chars)
Die Funktion gibt die Anzahl der Zeichen ganz links chars aus aus dem angegebenen str Zeichenfolge.
Wenn ein Argument NULL ist , ist die Ausgabe ebenfalls NULL .
Zum Beispiel:

LENGTH(), also OCTET_LENGTH()
Die Syntax für LENGTH() Funktion ist:
LENGTH(str)
Die Funktion gibt den str aus Zeichenfolgenlänge in Byte. Multibyte-Zeichen zählen als mehrere Bytes.
Zum Beispiel:

Die OCTET_LENGTH() Funktion ist ein Synonym für LENGTH() .
WIE
Die Syntax für LIKE Funktion ist:
expr LIKE patDie Funktion führt einen Mustervergleich durch, indem sie das angegebene Zeichenfolgenmuster in anderen Zeichenfolgen findet.
LIKE unterstützt Platzhalter:
%-Entspricht einer beliebigen Anzahl von Zeichen, sogar null._- Entspricht genau einem Zeichen.
LIKE gibt 1 (wahr) oder 0 (falsch) zurück. Wenn der expr Ausdruck oder pat Muster ist NULL , ist die Ausgabe ebenfalls NULL .
Zum Beispiel:
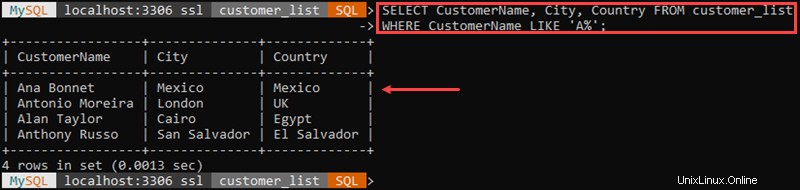
In diesem Beispiel haben wir alle Kunden abgerufen, deren Name mit „A beginnt '.
LOAD_FILE()
Die Syntax für LOAD_FILE() Funktion ist:
LOAD_FILE(file_name)Die Funktion liest die Datei und gibt einen String aus, der den Dateiinhalt enthält. Die Voraussetzungen für diese Funktion sind:
- Die Datei auf dem Serverhost haben.
- Angabe des vollständigen Dateipfads anstelle des file_name-Arguments.
- Das FILE-Privileg haben .
Der Server muss in der Lage sein, die Datei zu lesen, und ihre Größe muss kleiner sein als max_allowed_packet Byte. Wenn die secure_file_priv Systemvariable ein nicht leerer Verzeichnisname ist, platzieren Sie die Datei in diesem Verzeichnis.
Wenn die Datei nicht existiert oder die Funktion sie aus einem der oben genannten Gründe nicht lesen kann, ist die Ausgabe NULL .
Zum Beispiel:

LOCATE(), also POSITION()
Die Syntax für LOCATE() Funktion ist:
LOCATE(substring,str,[position])
Die Funktion gibt die Position des ersten Vorkommens des angegebenen substring aus -Argument innerhalb von str Schnur. Die position Das Argument ist optional und wird verwendet, um anzugeben, von welchem \u200b\u200bstr Zeichenfolgenposition, um die Suche zu starten. Weglassen der position Argument beginnt die Suche von Anfang an.
Wenn der substring befindet sich nicht in str Zeichenfolge, LOCATE() gibt 0 zurück. Wenn irgendein Argument NULL ist , gibt die Funktion NULL zurück .
Zum Beispiel:

Die POSITION(substring IN str) Funktion ist ein Synonym für LOCATE(substr,str) .
LOWER(), also LCASE()
Die Syntax für LOWER() Funktion ist:
LOWER(str)
Die Funktion ändert alle Zeichen des angegebenen str string in Kleinbuchstaben und gibt das Ergebnis aus. Die verwendete Standardzeichensatzzuordnung ist utf8mb4. LOWER() ist Multibyte-sicher.
Zum Beispiel:

Das LCASE() Funktion ist ein Synonym für LOWER() .
LPAD()
Die Syntax für LPAD() Funktion ist:
LPAD(str,len,padstr)
Die Funktion gibt den angegebenen str aus Zeichenfolge, links aufgefüllt mit padstr string, auf eine Länge von len Figuren. Die Funktion kürzt die Ausgabe auf len Zeichen, wenn die str argument ist länger als len .
LPAD() ist Multibyte-sicher.
Zum Beispiel:

In diesem Beispiel das LPAD() Die Funktion füllt das angegebene Argument links mit dem angegebenen padstr auf , bis zu 10 Zeichen.
LTRIM()
Die Syntax für LTRIM() Funktion ist:
LTRIM(str)
Die Funktion gibt den angegebenen str aus Zeichenfolge ohne die führenden Leerzeichen.
Zum Beispiel:

MAKE_SET()
Die Syntax für MAKE_SET() Funktion ist:
MAKE_SET(bits,str1,str2,...)
Die Funktion gibt einen gesetzten Wert aus, d. h. einen String, der die angegebenen Teilstrings mit dem entsprechenden Bit enthält, das in den bits angegeben ist Argument.
Der str1 Argument entspricht Bit 0, str2 entspricht Bit 1 usw. Wenn eines der Argumente NULL ist , sie erscheinen nicht im Ergebnis.
Zum Beispiel:

In diesem Beispiel ist das erste Bit 1, also 001. Die Ziffer ganz rechts ist 1, also gibt die Funktion 'phoenix zurück .' Das zweite Bit ist 2, also 010, die mittlere Zahl ist 1, also gibt die Funktion 'NAP zurück ,' und vervollständigt damit die Ausgabe.
MATCH()
Die Syntax für MATCH() Funktion ist:
MATCH(col1, col2,…) AGAINST(expr[search_modifier])
Die Funktion ermöglicht es Benutzern, Volltextsuchen durchzuführen, indem sie eine Liste von Spalten angeben, die durch Kommas getrennt sind. Geben Sie anstelle von expr eine Zeichenfolge ein, nach der Sie suchen möchten Argument.
Der search_modifier Das Argument ist optional und gibt den Suchtyp an. Die akzeptierten Werte sind:
IN NATURAL LANGUAGE MODE(Standard)IN NATURAL LANGUAGE MODE WITH QUERY EXPANSIONIN BOOLEAN MODEWITH QUERY EXPANSION
Zum Beispiel:
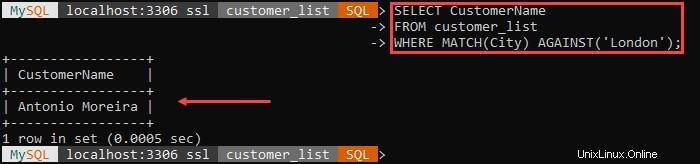
NICHT MÖGEN
Die Syntax für NOT LIKE Funktion ist:
expr NOT LIKE pat [ESCAPE 'escape_char']
NOT LIKE ist eine Negation von LIKE , was bedeutet, dass es unter den gleichen Bedingungen wie LIKE arbeitet und verwendet dieselben Platzhalter.
Zum Beispiel:
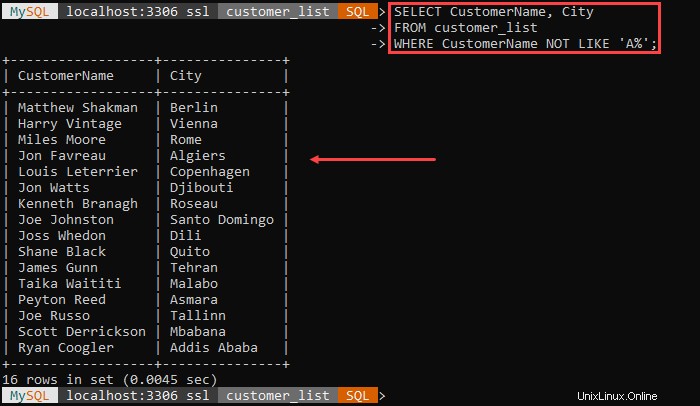
Die Ausgabe listet alle Kunden und ihre Stadt auf, mit Ausnahme der Kunden, deren Name mit 'A beginnt .'
NICHT REGEXP
Die Syntax für NOT REGEXP Funktion ist:
expr NOT REGEXP pat
Die Funktion führt einen Musterabgleich des expr durch Zeichenfolge gegen pat Muster. Das Muster kann ein erweiterter regulärer Ausdruck sein.
NOT REGEXP ist eine Negation von REGEXP .
Wenn der expr -Argument stimmt mit pat überein Argument, ist die Ausgabe 1. Andernfalls ist die Ausgabe 0. Wenn eines der Argumente NULL ist , ist die Ausgabe NULL .
Zum Beispiel:
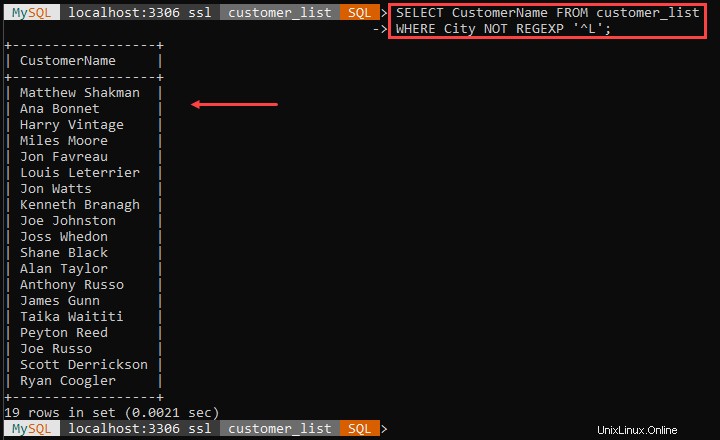
Das obige Beispiel gibt alle Kunden aus, die nicht in Städten leben, die mit L beginnen. Das '^ ' Zeichen markiert den Beginn des Städtenamens.
OKT()
Die Syntax für das OCT() Funktion ist:
OCT(N)
Die Funktion gibt den Oktalwert des angegebenen N aus Argument, wobei N ist ein BIGINTEGER Anzahl. Wenn N ist NULL , gibt die Funktion NULL zurück .
Zum Beispiel:

ORD()
Die Syntax für ORD() Funktion ist:
ORD(str)
Die Funktion findet den Code des am weitesten links stehenden Multibyte-Zeichens in einer Zeichenfolge. Wenn das Zeichen ganz links kein Multibyte ist, ORD() gibt den ASCII-Wert des Zeichens zurück.
Die Funktion berechnet den Zeichencode aus den numerischen Werten ihrer konstituierenden Bytes. Die für diese Operation verwendete Formel lautet:
(1. Byte-Code) + (2. Byte-Code * 256) + (3. Byte-Code * 256^2) ...
Zum Beispiel:

QUOTE()
Die Syntax für QUOTE() Funktion ist:
QUOTE(str)Die Funktion gibt eine Zeichenfolge aus, die einen ordnungsgemäß maskierten Datenwert darstellt, der in einer SQL-Anweisung verwendet werden kann. Die Zeichenfolge wird in einfache Anführungszeichen eingeschlossen und enthält einen umgekehrten Schrägstrich (\ ) vor jedem Backslash (\ ), einfaches Anführungszeichen (' ), ASCII NUL , und Strg+Z .
Wenn die str Argument ist NULL , ist die Ausgabe NULL .
Zum Beispiel:
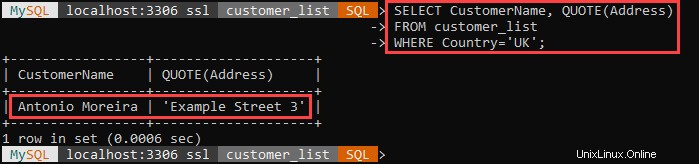
Das obige Beispiel wählt alle Kunden aus, die in Großbritannien leben, und schließt ihre Adressen in einfache Anführungszeichen ein.
REGEXP_LIKE(), REGEXP, RLIKE
Die Syntax für REGEXP_LIKE() Funktion ist:
REGEXP_LIKE(expr, pat, [match_type])
Die Funktion gibt 1 aus, wenn expr string stimmt mit dem anstelle von pat angegebenen Ausdruck überein Streit. Andernfalls ist die Ausgabe 0. Wenn der expr oder pat Argument ist NULL , ist der Ausgabewert NULL .
Der match_type Das Argument ist optional und stellt eine Zeichenfolge dar, die eines oder alle der folgenden Flags enthalten kann, die den übereinstimmenden Typ angeben:
- Groß-/Kleinschreibung beachten (
c). Behandeln Sie die Argumente als binäre Zeichenfolgen mit Berücksichtigung der Groß-/Kleinschreibung, wenn eines der Argumente eine binäre Zeichenfolge ist. DascFlag bedeutet, dass Groß- und Kleinschreibung berücksichtigt wird, auch wenniFlag ist ebenfalls angegeben. - Abgleich ohne Berücksichtigung der Groß-/Kleinschreibung (
i). Behandeln Sie die Argumente ohne Berücksichtigung der Groß-/Kleinschreibung. - Mehrzeiliger Modus (
m). Zeilenabschlusszeichen innerhalb der Zeichenfolge erkennen. Die Standardeinstellung ist, Zeilenabschlusszeichen nur am Anfang und am Ende des Zeichenfolgenausdrucks abzugleichen. - Die . Zeichen stimmt mit Zeilenabschlusszeichen überein (
n). Wird verwendet, um . zu ändern (Punkt) Zeichen, um Zeilenabschlusszeichen abzugleichen. Standardmäßig . Matching stoppt am Ende einer Zeile. - Nur-Unix-Zeilenenden (
u). Reine Unix-Zeilenenden, die nur das Zeilenumbruchzeichen durch die Übereinstimmungsoperatoren ., ^ und $ erkennen.
Wenn innerhalb von match_type widersprüchliche Flags angegeben sind , der ganz rechte hat Vorrang.
REGEXP und RLIKE sind Synonyme für REGEXP_LIKE() .
Zum Beispiel:

In diesem Beispiel kann der reguläre Ausdruck ein beliebiges Zeichen anstelle des Punktes angeben, sodass die Funktion eine 1 ausgibt, um eine Übereinstimmung anzuzeigen.
REGEXP_INSTR()
Die Syntax für REGEXP_INSTR() Funktion ist:
REGEXP_INSTR(expr, pat[, pos[, occurrence[, return_option[, match_type]]]])
Die Funktion gibt den Anfangsindex einer Teilzeichenfolge aus, die mit expr übereinstimmt pat des Ausdrucks Muster. Wenn es keine Übereinstimmung gibt, ist die Ausgabe 0. Wenn eines der Argumente NULL ist , ist die Ausgabe NULL . Zeichenindizes beginnen bei 1.
Die optionalen Argumente sind:
pos- Geben Sie die Position inexpran wo die Suche beginnen soll. Wenn weggelassen, ist der Standardwert 1.occurrence- Geben Sie an, nach welchem Vorkommen einer Übereinstimmung gesucht werden soll. Wenn weggelassen, ist der Standardwert 1.return_option- Welcher Positionstyp zurückgegeben werden soll. Wenn auf 0 gesetzt,REGEXP_INSTR()gibt die erste Zeichenposition des übereinstimmenden Teilstrings zurück. Wenn auf 1 gesetzt,REGEXP_INSTR()gibt die Position nach dem übereinstimmenden Teilstring zurück. Wenn weggelassen, ist der Standardwert 0.match_type- Gibt an, wie abgeglichen werden soll. Das Argument ist dasselbe wie inREGEXP_LIKE()und nimmt dieselben Flaggen.
Zum Beispiel:

In diesem Beispiel gibt es eine Übereinstimmung und die Teilzeichenfolge beginnt an Position 1.
REGEXP_REPLACE()
Die Syntax für REGEXP_REPLACE() Funktion ist:
REGEXP_REPLACE(expr, pat, repl[, pos[, occurrence[, match_type]]])
Die Funktion ersetzt jedes Vorkommen im expr Zeichenfolge, die durch pat angegeben wird Muster mit repl Zeichenfolge und gibt die resultierende Zeichenfolge aus. Wenn es eine Übereinstimmung gibt, ist die Ausgabe die gesamte Zeichenfolge mit den Ersetzungen. Wenn es keine Übereinstimmung gibt, ist die Ausgabe der ursprüngliche expr Schnur. Wenn ein Argument NULL ist , ist die Ausgabe NULL .
Das optionale REGEXP_REPLACE() Argumente sind:
pos- Die Position inexprwo die Suche beginnen soll. Wenn weggelassen, ist der Standardwert 1.occurrence- Welches Übereinstimmungsvorkommen ersetzt werden soll. Wenn weggelassen, ist der Standardwert 0 und ersetzt alle Vorkommen.match_type- Gibt an, wie abgeglichen werden soll. Das Argument ist dasselbe wie inREGEXP_LIKE()und nimmt dieselben Flaggen.
Zum Beispiel:

REGEXP_SUBSTR()
Die Syntax für REGEXP_SUBSTR() Funktion ist:
REGEXP_SUBSTR(expr, pat[, pos[, occurrence[, match_type]]])
Die Funktion gibt den Teilstring von expr aus Zeichenfolge, die mit dem durch pat angegebenen regulären Ausdruck übereinstimmt Muster. Wenn es keine Übereinstimmung gibt, ist das Ergebnis NULL . Wenn ein Argument NULL ist , ist die Ausgabe NULL .
Die optionalen Argumente sind:
pos- Die Position inexprwo die Suche beginnen soll. Wenn weggelassen, ist der Standardwert 1.occurrence- Welches Übereinstimmungsvorkommen ersetzt werden soll. Wenn weggelassen, ist der Standardwert 1.match_type- Gibt an, wie abgeglichen werden soll. Das Argument ist dasselbe wie inREGEXP_LIKE()und nimmt dieselben Flaggen.
Zum Beispiel:

In diesem Beispiel gibt das Ergebnis die übereinstimmende Teilzeichenfolge aus dem angegebenen expr aus Zeichenfolge.
REPEAT()
Die Syntax für REPEAT() Funktion ist:
REPEAT(str,count)
Die Funktion gibt einen String aus, der str wiederholt Zeichenfolge count mal. Wenn die count argument kleiner als 1 ist, gibt die Funktion einen leeren String aus. Wenn eines der Argumente NULL ist , ist das Ergebnis NULL .
Zum Beispiel:

Im obigen Beispiel gibt die Funktion einen String aus, der aus der Datei „Work ' Zeichenfolge sechsmal wiederholt.
REPLACE()
Die Syntax für REPLACE() Funktion ist:
REPLACE(str,from_str,to_str)
Die Funktion ersetzt alle Instanzen von from_str innerhalb der str Zeichenfolge mit dem angegebenen to_str Schnur. Die Funktion unterscheidet zwischen Groß- und Kleinschreibung und ist multibytesicher.
Zum Beispiel:

UMKEHR()
Die Syntax für REVERSE() Funktion ist:
REVERSE(str)
Die Funktion gibt den str aus Zeichenfolge mit umgekehrter Zeichenreihenfolge. REVERSE() ist eine Multibyte-sichere Funktion.
Zum Beispiel:

RECHTS()
Die Syntax für RIGHT() Funktion ist:
RIGHT(str,len)
Die Funktion gibt die ganz rechte len aus Anzahl der Zeichen aus str Schnur. Wenn ein Argument NULL ist , ist das Ergebnis NULL . RIGHT() ist eine Multibyte-sichere Funktion.
Zum Beispiel:

RPAD()
Die Syntax für RPAD() Funktion ist:
RPAD(str,len,padstr)
Die Funktion gibt den angegebenen str aus Zeichenfolge, rechts aufgefüllt mit padstr string, auf eine Länge von len Figuren. Die str Argument ist länger als len verkürzt die Ausgabe auf len Zeichen.
RPAD() ist Multibyte-sicher.
Zum Beispiel:

RTRIM()
Die Syntax für RTRIM() Funktion ist:
RTRIM(str)
Die Funktion gibt den str aus Zeichenfolge ohne die abschließenden Leerzeichen. Das RTRIM() Funktion ist Multibyte-sicher.
Zum Beispiel:

SOUNDEX(), d.h. KLINGT WIE
Die Syntax für SOUNDEX() Funktion ist:
SOUNDEX(str)
Die Funktion gibt einen Soundex-String aus, also eine phonetische Darstellung der Eingabe str Schnur. Der SOUNDEX() function allows users to compare English words that are spelled differently but sound alike.
SOUNDEX() ignores all non-alphabetic characters in the input string and treats all characters outside the A-Z range as vowels.
Wichtig: The SOUNDEX() function works well only with strings in English. Results are unreliable for strings in other languages and for strings that use multibyte character sets, including utf-8.
Zum Beispiel:

The (expr1) SOUNDS LIKE (expr2) function is the same as SOUNDEX(expr1) = SOUNDEX(expr2) .
SPACE()
The syntax for the SPACE() function is:
SPACE(N)
The function outputs a string consisting of N number of space characters.
Zum Beispiel:

STRCMP()
The syntax for the STRCMP() function is:
STRCMP(expr1,expr2)The function compares the two expressions and outputs:
0- If the two expressions are the same.-1- If the first expression is smaller than the second depending on the current sort order.1- If the second expression is smaller than the first one.
Zum Beispiel:

In this example, the output is 1 because the second argument is smaller than the first one.
SUBSTRING(), i.e., SUBSTR(), MID()
The syntax for the SUBSTRING() function is:
SUBSTRING(str, pos, length)oder:
SUBSTRING(str FROM pos FOR length)The function extracts a substring from a string, starting at a specified position.
The length argument is optional and used to return a substring length characters long from the str string, starting at pos position.
The pos argument specifies from which position to extract the substring. If pos is a positive number, the function extracts a substring from the beginning of the string. If pos is a negative number, the function extracts a substring from the end of the string.
Zum Beispiel:

MID(str,pos,length) and SUBSTR() are synonyms for SUBSTRING(str,pos,length) .
SUBSTRING_INDEX()
The syntax for the SUBSTRING_INDEX() function is:
SUBSTRING_INDEX(str,delim,count)
The function outputs a substring from the str string before a specified count number of delim delimiter occurs.
If the count argument is positive, the function outputs everything left of the final delimiter, counting from the left side.
If the count argument is negative, the function outputs everything right of the final delimiter, counting from the right side.
SUBSTRING_INDEX() searches for the delimiter in a case-sensitive fashion, and it is multibyte safe.
Zum Beispiel:
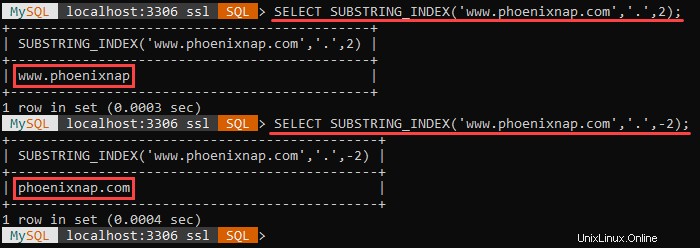
The example above shows the different outputs when the count argument is positive and negative.
TO_BASE64()
The syntax for the TO_BASE64() function is:
TO_BASE64(str)The function encodes a string argument to a base-64 encoded form and returns the result. If the argument isn't a string, the function converts it to a string before base-64 encoding.
If the argument is NULL , the result is NULL .
TO_BASE64() is the reverse of FROM_BASE64() .
Zum Beispiel:

The output is a base-64 encoded string.
TRIM()
The syntax for the TRIM() function is:
TRIM([{BOTH | LEADING | TRAILING} [remstr] FROM] str)
The function removes all remstr prefixes and suffixes from the specified str string and outputs the result.
Unless specifying the BOTH, LEADING ,or TRAILING specifiers, the function assumes BOTH .
The remstr argument is optional, and omitting it removes the space characters from the string.
TRIM() is multibyte safe.
Zum Beispiel:

In this example, the function removes the specified leading prefix from the string.
UPPER(), i.e., UCASE()
The syntax for the UPPER() function is:
UPPER(str)
The function changes all characters of the specified str string to uppercase and outputs the result. The default character set mapping it uses is utf8mb4. UPPER() is multibyte safe.
Zum Beispiel:

The UCASE() function is a synonym for UPPER() .
UNHEX()
The syntax for the UNHEX() function is:
UNHEX(str)The function interprets each pair of characters in a string argument as a hexadecimal number and converts it to the byte represented by the number. The output is a binary result.
If the str argument contains non-hexadecimal digits, the output is NULL . A NULL output can also occur if the argument is a BINARY Spalte.
UNHEX() is the opposite of HEX() . However, you shouldn't use UNHEX() to inverse the HEX() result of numeric arguments. Instead, use the mathematical function CONV(HEX(N),16,10) .
Zum Beispiel:

WEIGHT_STRING()
The syntax for the WEIGHT_STRING() function is:
WEIGHT_STRING(str [AS {CHAR|BINARY}(N)] [flags])str- The input string argument.AS- Optional clause, permits casting the input string to a binary or non-binary string, and to a specific length.flags- Optional argument, currently unused.
The function outputs the weight string for the input str Schnur. The output value represents the string's sorting and comparison value.
If used, the AS BINARY(N) argument measures the length in bytes rather than characters, and right-pads with 0x00 bytes to the specified length.
On the other hand, the AS CHAR(N) argument measures the characters' length and right-pads with spaces to the specified length.
N has a minimum value of 1. If N is less than the input string length, the string is truncated without issuing a warning.
If the input string is a non-binary value (CHAR , VARCHAR , or TEXT ) , the output contains the collation weights for the string. If the input string is a binary value (BINARY , VARBINARY , or BLOB ), the output is the same as the input string because the weight for each byte in a binary string is the byte value.
If the input string is NULL , the output is NULL .
Important:WEIGHT_STRING() is a debugging function intended for internal use and collation testing and debugging. Its behavior is subject to change between different MySQL versions.
Zum Beispiel:

In this example, we used HEX() to display the output because HEX() can display binary results containing nonprinting values in a printable form.