Einführung
Datenbankdenormalisierung ist eine Technik zur Verbesserung der Datenzugriffsleistung. Wenn eine Datenbank normalisiert ist und Methoden wie die Indizierung nicht ausreichen, dient die Denormalisierung als eine der letzten Optionen, um den Datenabruf zu beschleunigen.
In diesem Artikel wird erklärt, was Datenbank-Denormalisierung ist und welche verschiedenen Techniken verwendet werden, um eine Datenbank zu beschleunigen.

Was ist Datenbank-Denormalisierung?
Datenbankdenormalisierung ist der Prozess der systematischen Kombination von Daten, um schnell Informationen zu erhalten. Der Prozess bringt Beziehungen auf niedrigere Normalformen herunter, wodurch die Gesamtintegrität der Daten verringert wird.
Andererseits steigen die Datenabrufleistungen. Anstatt mehrere kostspielige JOINs für zahlreiche Tabellen durchzuführen, hilft die Datenbanknormalisierung dabei, Informationen zusammenzubringen, die häufig oder logisch kombiniert sind.
Datenbankanomalien treten aufgrund von niedrigeren Normalformen auf. Das Problem der Redundanzen findet eine Lösung, indem Beschränkungen auf Softwareebene hinzugefügt werden, wenn Daten in eine Datenbank eingegeben werden.
Datenbanknormalisierung vs. Denormalisierung
Datenbanknormalisierung und -denormalisierung sind zwei verschiedene Möglichkeiten, die Struktur einer Datenbank zu ändern. Die Tabelle beschreibt die Hauptunterschiede zwischen den beiden Methoden:
| Normalisierung | Denormalisierung | |
|---|---|---|
| Funktionalität | Entfernt redundante Informationen und verbessert die Datenänderungsgeschwindigkeit. | Kombiniert mehrere Informationen in einer Einheit und verbessert die Datenabrufgeschwindigkeit. |
| Fokus | Bereinigung der Datenbank, um Redundanzen zu entfernen. | Redundanzen für schnellere Abfrageausführung eingeführt. |
| Speicher | Optimierte und verbesserte allgemeine Leistung. | Speicherineffizienz aufgrund von Redundanzen. |
| Integrität | Das Entfernen von Datenbankanomalien verbessert die Datenbankintegrität. | Keine aufrechterhaltene Datenintegrität. Es liegen Datenbankanomalien vor. |
| Anwendungsfall | Datenbanken, in denen Einfügungs-, Aktualisierungs- und Löschänderungen häufig vorkommen und Verknüpfungen nicht teuer sind. | Datenbanken, die häufig abgefragt werden, wie z. B. Data Warehouses. |
| Verarbeitungstyp | Online-Transaktionsverarbeitung – OLTP | Analytische Online-Verarbeitung – OLAP |
Die Datenbanknormalisierung führt eine nicht normalisierte Datenbank durch normale Formen, um die Datenstruktur zu verbessern. Andererseits beginnt die Denormalisierung mit einer normalisierten Datenbank und kombiniert Daten für eine schnellere Ausführung häufig verwendeter Abfragen.
Warum und wann sollten Sie eine Datenbank denormalisieren?
Die Denormalisierung von Datenbanken ist eine praktikable Technik, wenn die Geschwindigkeit des Datenabrufs ein wesentlicher Faktor ist. Das Verfahren ändert jedoch die gesamte Datenbankstruktur. Die Denormalisierung ist in den folgenden Szenarien hilfreich:
- Verbesserung der Abfrageleistung. Das Zusammenstellen von Informationen fügt Redundanzen hinzu. Allerdings verringert sich die Anzahl der JOINs, was die Abfrageleistung erhöht.
- Komfortable Verwaltung . Eine normalisierte Datenbank ist aufgrund der hohen Granularität schwer zu verwalten. Anstatt Werte zu berechnen oder sie nach Bedarf zu verbinden, hilft die Denormalisierung dabei, leicht verfügbare Daten bereitzustellen.
- Beschleunigte Berichterstellung . Analytische Daten erfordern zeitnah eine Menge Berechnungen. Eine denormalisierte Datenbank zum Generieren von Berichten ist eine perfekte Lösung, um schnell analytische Informationen bereitzustellen.
Wenn eine Datenbank eine geringe Leistung aufweist, ist die Denormalisierung nicht immer der richtige Weg. Da der Prozess die Datenbankstruktur verändert, besteht die Gefahr, dass bestehende Funktionalitäten zusammenbrechen.
Einen Bezugspunkt zu haben ist ein wichtiges Konzept beim Ändern der Datenbankstruktur. Letztendlich dient die Datenbanknormalisierung als letzter Ausweg statt einer schnellen Lösung.
Denormalisierungstechniken
Je nach Anwendungsfall werden verschiedene Datenbank-Denormalisierungstechniken verwendet. Jede Methode hat einen geeigneten Einsatzort, Vor- und Nachteile.
Pre-Joining-Tische
Vorverknüpfte Tabellen speichern die häufig verwendeten Informationen zusammen in einer Tabelle. Der Prozess ist praktisch, wenn:
- Abfragen werden häufig gemeinsam für die Tabellen ausgeführt.
- Der Join-Vorgang ist kostspielig.
Die Methode erzeugt massive Redundanzen, daher ist es wichtig, eine minimale Anzahl von Spalten zu verwenden und die Informationen regelmäßig zu aktualisieren.
Beispiel für Pre-Joining-Tabellen
Ein Geschäft speichert die Informationen über Artikel und die Kategorien, zu denen die Artikel gehören. Der Fremdschlüssel dient als Referenz auf den Artikeltyp. Durch das Vorverknüpfen der Tabellen wird der Kategoriename zur Artikeltabelle hinzugefügt.
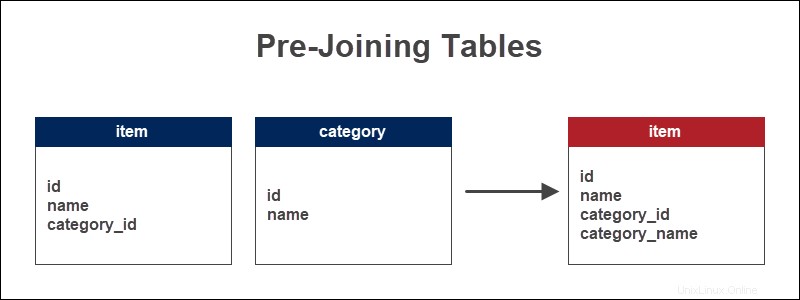
Durch das direkte Hinzufügen des Kategorienamens zur Artikeltabelle können die Artikel schnell nach Kategorie angezeigt werden. Bei längeren Abfragen spart diese Methode Zeit und reduziert die Anzahl der JOINs.
Gespiegelte Tabellen
Eine gespiegelte Tabelle ist eine Kopie einer vorhandenen Tabelle. Die Tabelle ist entweder:
- Eine teilweise Kopie.
- Eine vollständige Kopie.
Ziel ist es, die Daten aus dem Original in eine neue Tabelle zu reproduzieren. Das Erstellen von Duplikaten ist eine gute Technik zum Erstellen einer Sicherung, um den Anfangszustand der Datenbank zu erhalten.
Beispiel für gespiegelte Tabellen
Das Spiegeln von Tabellen ist eine häufig verwendete Methode zur Aufbereitung von Daten in Entscheidungsunterstützungssystemen. Da die Abfragen normalerweise über viele Datenpunkte aggregiert werden, würde die Aufgabe die Systemleistung erheblich verringern.
Entscheidungsunterstützungssysteme profitieren stark von der Verwendung gespiegelter Tabellen. Das Anwenden von Transaktionen auf die Originaltabelle wird nicht unterbrochen, während anspruchsvolle Berichte auf der Duplikattabelle ausgeführt werden.
Tischaufteilung
Das Aufteilen von Tabellen impliziert das Aufteilen normalisierter Tabellen in zwei oder mehr Relationen. Das Teilen von Tabellen geschieht in zwei Dimensionen:
- Horizontal . Tabellen werden mithilfe von
UNIONin Zeilenteilmengen aufgeteilt Betreiber. - Vertikal . Tabellen werden mithilfe des
INNER JOINin Spaltenuntergruppen aufgeteilt Betreiber.
Das Ziel der Methode besteht darin, Tabellen für eine schnellere und bequemere Datenverarbeitung in kleinere Einheiten aufzuteilen. Wenn die Datenbank auch die Originaltabelle enthält, wird diese Methode als Sonderfall von gespiegelten Tabellen angesehen.
Beispiele für Tabellenaufteilung
Die Anwendungsbeispiele hängen von den Kriterien der Tabellenaufteilung ab. Die häufigsten Gründe für das Teilen von Tabellen sind:
- Verwaltung . Ein Tisch für jede Branche statt ein Tisch für ein ganzes Unternehmen.
- Räumlich . Ein Tisch für jede Region statt ein Tisch für das ganze Land.
- Zeitbasiert . Eine Tabelle für jeden Monat statt einer Tabelle für ein ganzes Jahr.
- Physisch . Eine Tabelle für jeden Standort statt einer Tabelle für alle Standorte.
- Verfahrensweise . Eine Tabelle für jeden Schritt in einer Aufgabe statt einer Tabelle für einen ganzen Job.
Speichern ableitbarer Werte
Das Speichern häufig ausgeführter Berechnungen lohnt sich in Situationen, in denen:
- Der abgeleitete Wert wird häufig verwendet.
- Die Quellwerte ändern sich nicht.
Durch das direkte Speichern ableitbarer Daten wird sichergestellt, dass Berechnungen bereits beim Generieren eines Berichts durchgeführt werden, und es entfällt die Notwendigkeit, die Quellwerte für jede Abfrage nachzuschlagen.
Beispiel für das Speichern ableitbarer Werte
Wenn wir eine Datenbanktabelle haben, die Informationen über Personen enthält, ist das Alter einer Person ein berechneter Wert, der auf ihrem Geburtsdatum basiert. Leiten Sie das Alter ab, indem Sie mithilfe der MySQL-Datumsfunktion CURDATE() den Unterschied zwischen dem aktuellen Datum ermitteln und das Geburtsdatum.
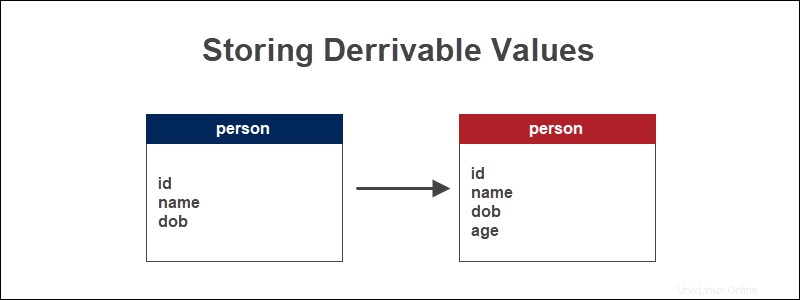
Das Alter ist eine wesentliche Information bei der Analyse von demografischen Informationen. Der Quellwert, also das Geburtsdatum, ändert sich nicht.
Hierarchietabellen
Eine Hierarchietabelle ist eine baumartige Struktur mit einer Eins-zu-Viele-Beziehung. Eine Elterntabelle hat viele Kinder. Die Kinder haben jedoch nur eine Elterntabelle. Hierarchietabellen werden in Fällen verwendet, in denen:
- Die Struktur der Daten ist hierarchisch.
- Die übergeordneten Tabellen sind statisch und unveränderlich.
Fest codierte Werte
Hartcodierte Werte entfernen einen Verweis auf eine häufig verwendete Entität. Verwenden Sie diese Methode in Situationen, in denen:
- Die Werte gelten als statisch.
- Die Anzahl der Werte ist gering.
Anstatt eine kleine Nachschlagetabelle zu verwenden, werden die Werte direkt in der Anwendung fest codiert. Der Prozess vermeidet auch das Ausführen von Verknüpfungen in der Nachschlagetabelle.
Beispiel für hartcodierte Werte
Eine Tabelle mit Informationen über Personen könnte eine kleine Nachschlagetabelle verwenden, um Informationen über das Geschlecht von Personen zu speichern. Da die Informationen in der Nachschlagetabelle eine begrenzte Anzahl von Werten haben, sollten Sie die Daten direkt in die Personentabelle hartcodieren.
Hartcodierte Werte machen eine Nachschlagetabelle und die JOIN-Operation mit dieser Tabelle überflüssig. Alle Änderungen, die in der Nachschlagetabelle vorgenommen werden, oder die Aufzeichnung neuer Werte erfordern das Hinzufügen einer Prüfbedingung.
Speichern von Details mit Master
Die Haupttabelle enthält die Hauptinformationstabelle, während andere Tabellen spezifische Details enthalten. Speichern Sie die Details mit der Haupttabelle, wenn:
- Ein detaillierter Überblick über die Stammtabelle ist unerlässlich.
- Analytische Berichte über die Haupttabelle sind häufig.
Bei der Datenauswahl ist es praktisch, alle Details mit der Master-Tabelle zu halten. Die Methode funktioniert am besten, wenn weniger Details vorhanden sind. Andernfalls verlangsamt sich der Datenabruf erheblich.
Beispiel zum Speichern von Details mit Master
Eine Haupttabelle mit Kundeninformationen speichert normalerweise spezifische Details über die Person in einer separaten Tabelle. Informationen über den jeweiligen Standort befinden sich beispielsweise normalerweise in einer Reihe kleinerer Tabellen.
Jeder Bericht, der den Standort des Kunden berücksichtigt, profitiert vom Hinzufügen der Standortdetails zur Haupttabelle.
Einzelnes Detail mit Master wiederholen
Bei Abfragen muss häufig nur ein einziges Detail zur Haupttabelle hinzugefügt werden, anstatt mehrere Werte vorab zu verknüpfen. Verwenden Sie diese Methode, wenn:
- JOINs sind für ein einzelnes Detail kostspielig.
- Die Stammtabelle benötigt die Informationen oft.
Das Hinzufügen eines einzelnen Details zu einer Haupttabelle ist am häufigsten, wenn die Datenbank historische Daten enthält. Die wiederholte Entität ist normalerweise die neueste Information.
Beispiel für Einzeldetail mit Master
Eine Geschäftsdatenbank verfügt normalerweise über eine Haupttabelle mit Informationen zu den verkauften Artikeln. Eine weitere Tabelle mit Angaben zu den historischen Preisveränderungen enthält auch die Informationen zum aktuellen Preis.
Da dieses einzelne Detail hilft, die aktuellen Artikelpreise zu analysieren, sind die neuesten Informationen über den Preis praktisch, um sie in der Haupttabelle zu wiederholen.
Jegliche Kostenänderungen müssen aus Konsistenzgründen ebenfalls in der Haupttabelle berücksichtigt und aktualisiert werden.
Kurzschlusstasten
In einer Datenbank mit drei oder mehr Tabellen verwandter Informationen überspringt die Short-Circuit Keys-Methode die mittlere(n) Tabelle(n) und „kurzschließt“ die Großeltern- und Enkeltabellen.
Verwenden Sie die Kurzschlusstechnik in Situationen, in denen:
- Eine Datenbank hat mehr als drei Master-Detail-Ebenen.
- Die Werte von Großeltern und Enkeln werden oft benötigt und die Elterninformationen sind nicht so wertvoll.
Wenn sich zwei Relationen über eine mittlere Tabelle beziehen, lassen Sie den JOIN der Zwischenrelation weg und verbinden Sie die erste und letzte Tabelle direkt.
Beispiel für Kurzschlusstasten
Ein Informationssystem könnte Informationen über Personen in einer Tabelle, ihre Adresse an einem anderen Ort und den geografischen Bereich dieser Adresse in einer dritten Tabelle speichern. Für einen demografischen Bericht ist die genaue Adresse keine entscheidende Information.
Der Aufenthaltsort einer Person ist jedoch für die Analyse wesentlich. Das Kurzschließen der Personentabelle mit dem Bereich lässt den JOIN auf der mittleren Tabelle weg.
Denormalisierungsvorteile
Die Vorteile der Datenbank-Denormalisierung sind:
- Geschwindigkeit . Da JOIN-Abfragen in einer normalisierten Datenbank kostspielig sind, ist das Abrufen von Daten schneller.
- Einfachheit . Das Abrufen von Daten ist aufgrund der geringeren Anzahl von Tabellen einfacher.
- Weniger Fehler . Das Arbeiten mit einer kleineren Anzahl von Tabellen bedeutet weniger Fehler beim Abrufen von Informationen aus einer Datenbank.
Nachteile der Denormalisierung
Die Nachteile beim Denormalisieren einer Datenbank zu beachten sind:
- Komplexität . Das Aktualisieren und Einfügen in eine Datenbank ist komplexer und kostspieliger.
- Inkonsistenz . Den richtigen Wert für eine Information zu finden, ist schwieriger, da die Daten schwer zu aktualisieren sind.
- Speicherung . Aufgrund von eingeführten Redundanzen ist erheblich mehr Speicherplatz erforderlich.